Problem description
Recently, when I was doing my graduation project thesis and training CNN, I found one thing when I used NVIDIA SMI command to check the occupation rate of graphics card:
The video memory is occupied, but the GPU utilization rate is always 0% or beating frequently (figure from the network)
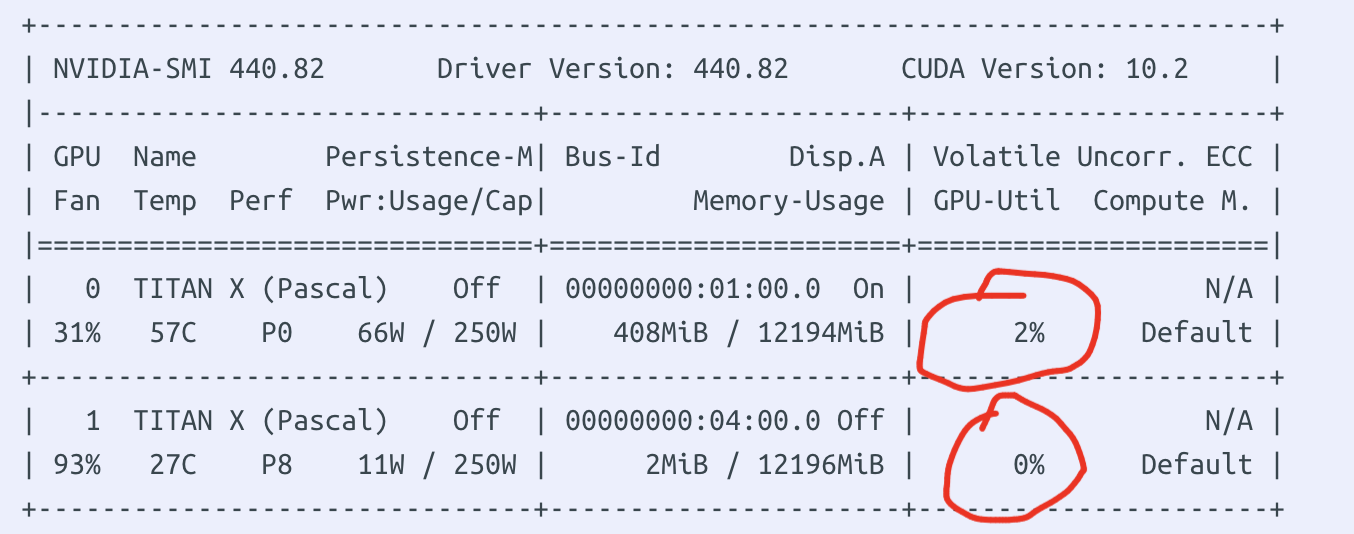
About 7000 of the 10000 images used in the data set were used for training, and the resnet-18 network was used to resize the image into a 112 * 112 gray-scale image, GPU-A4000. Train an epoch for about 30S
Solution of data loader
- Add num of dataloader_ num_ Number of workers (this function should be executed in the main function, otherwise an error will be reported). It is generally set to the same number of CPU cores (I saw this suggestion from the website renting GPU), but setting it too high is useless, but the performance is reduced. From 2, 4, 6 Such a gradual increase to see how much is appropriate
train_loader = data.DataLoader(dataset=train_dataset,
batch_size=512,
shuffle=False, num_workers=6)
2. Modify prefetch of dataloader_ Factor (a new feature of pytorch version 1.7 or above, which can be used in my Pytorch-1.8.1), default=2, indicating 2 * num_ The workers sample will be taken out in advance
train_loader = data.DataLoader(dataset=train_dataset,batch_size=512,
num_workers=6,prefetch_factor=4)
3. Set the persistent of the dataloader_ workers. If True, it means that the process will not be shut down after the dataset is used, and will be maintained all the time
train_loader = data.DataLoader(dataset=train_dataset,batch_size=512,
num_workers=6,prefetch_factor=4,
persistent_workers=True
)
The explanation of the above part may be different from the official document of pytorch. For details, see: https://pytorch.org/docs/stable/data.html
From the dataset itself
General data reading method
- Read annotation information from csv and other files. Take the classification task as an example: the path with pictures and the results to be classified. (img: / root/path / apple. jpg label:'apple')
- Read the picture with cv2, PIL and other libraries according to the annotated path. Take PIL reading as an example
from PIL import Image
Image.open(img_path).convert("L")
3. When using in the dataset, read the comment path and convert the label to a number
def __getitem__(self, index):
'Generates one sample of data'
img_path = according to index from csv File acquisition path
label = according to index from csv File acquisition label
X = Image.open(img_path).convert("L")
y = torch.tensor(label)
return X, y
=========="This is a very common usage. If it is OK to read with SSD, the speed of SSD is very fast. But!! The website hard disk I rent GPU is mechanical, which leads me to spend a lot of time on IO
However, there is one advantage of renting GPU websites -------- > large memory, so you can consider loading all pictures into memory first, and then directly mapping and reading, so as to solve the IO problem
resolvent
1. Read img according to csv_ Path, label information
2. Save the pictures and labels into a file. Here I save them into npy file
3. When initializing the dataset, read the npy file directly and load it into memory -------- -- > then get the data from the npy file
4. The shape of NPY file is a matrix with [1000, 2] 1000 rows and 2 columns
For each row of elements npy[i, 0], the first column represents img (note that it is img, not img_path), and npy[i, 1] the second column represents label
Some codes are as follows
ls = []
for line_index, line in df.iterrows():
img_path = line.path
val = line.cell_type_idx
img_path = line.path
# Reduction of gray processing method for reading pictures
temp_img = Image.open(img_path).convert("L")
temp_img = temp_img.resize([conf.IMAGE_WIDTH, conf.IMAGE_HEIGHT])
temp_img = np.array(temp_img)
# Deposit npy
ls.append([temp_img, val])
npy_file = np.array(ls)
np.save("/root/test.npy" (This parameter is what you want to save npy Place of documents), arr=npy_file (This parameter needs to be saved npy What is it?))
In the dataset, this npy file is read during initialization
class MyDataset(data.Dataset):
'Characterizes a dataset for PyTorch'
def __init__(self, train_type):
'Initialization'
train_npy ="/root/test.npy"
train_npy = np.load(train_npy,allow_pickle=True)
self.df = train_npy
def __len__(self):
'Denotes the total number of samples'
return self.df.shape[0]
def __getitem__(self, index):
'Generates one sample of data'
X = self.df[index, 0]
X = np.array(X)
y = torch.tensor(int(self.df[index, 1]))
return X, y
Final effect
Originally an epoch:30s, now an epoch 5S (great progress)
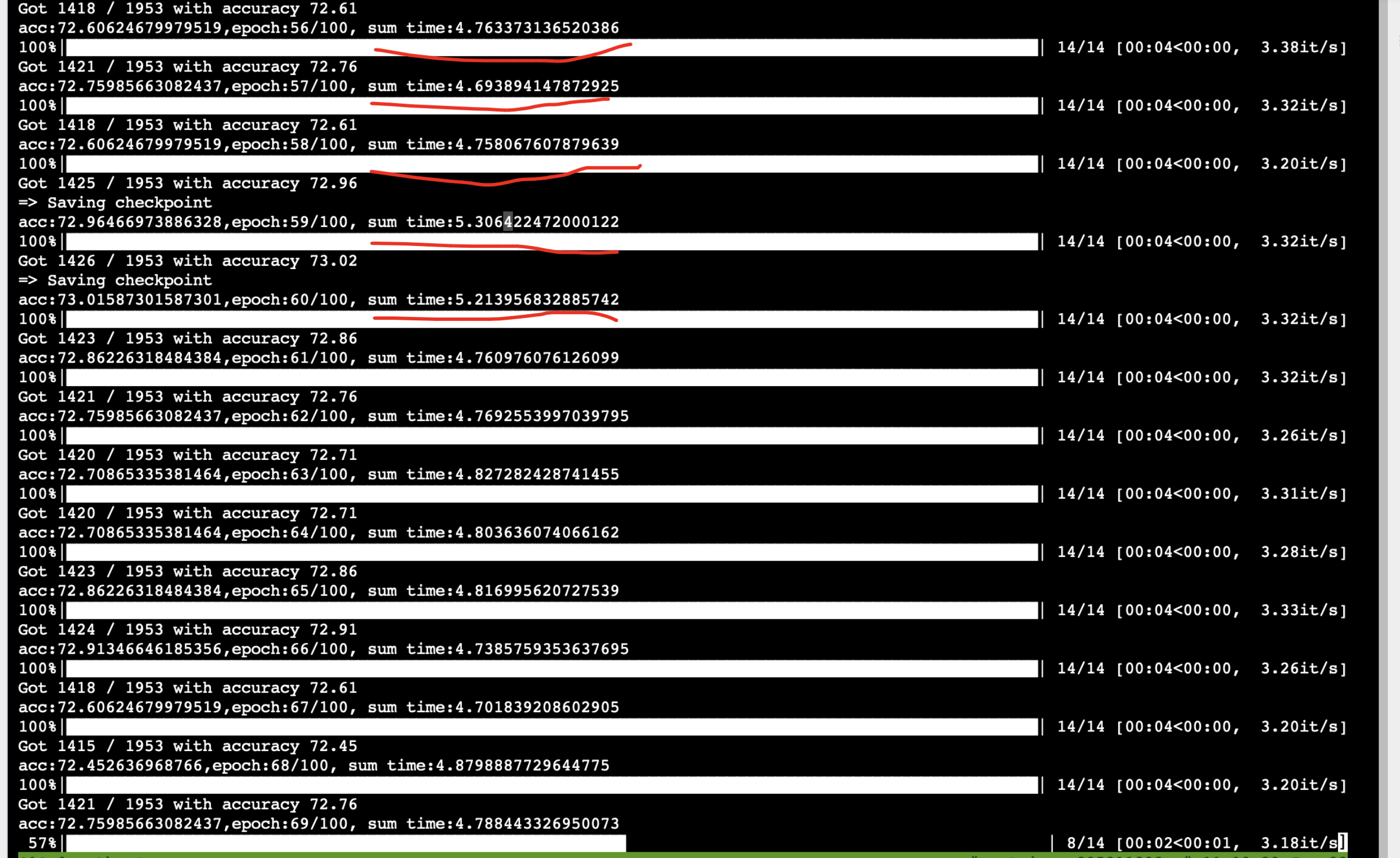
At the same time, GPU occupancy has also increased
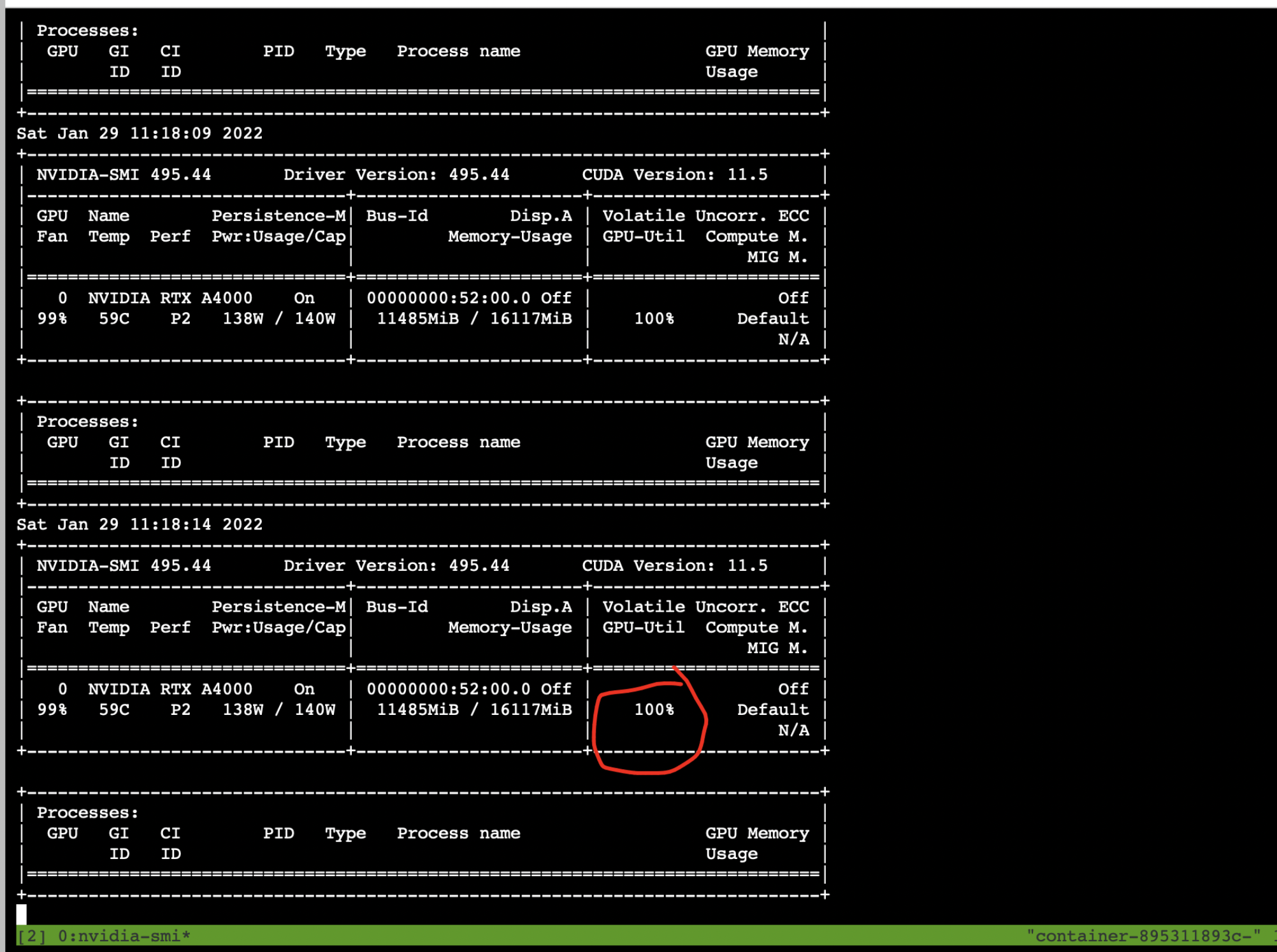
Finally, add a little trick
Let the NVIDIA SMI command of the remote server refresh the results automatically, so you don't have to enter the command to view the results manually every time
get into tmux etc. nvidia-smi -l