1. Purpose of document preparation
When data in Hive is synchronized to HBase, it is usually realized by creating a table mapping HBase in Hive and then insert ing it. When the amount of data is small, it is often acceptable. However, if it is mass data, in addition to the long synchronization time, it often affects the online HBase service, This is because the bottom layer is implemented by calling the put API of HBase. In order to improve the data writing of HBase, bulkload is generally considered, and bulkload actually has many options:
1. Write MapReduce/Spark Program to generate hfile file, and then load data through HBase command
2. Generate hfile through HBase's ImportTsv tool, and then load data through HBase command
3. bulkload by customizing Phoenix's StorageHandler
4. Use Hive to generate hfile file, and then load data through HBase command
This article mainly introduces how to use Hive in CDP. The following methods are relatively simple in CDH5 or CDH6, but there are some differences in CDP because Hive uses tez engine by default.
- Preconditions
1. The target HBase table must be newly created (that is, it cannot be imported into an existing table)
2. The target table can only have one Column Family
3. The target table cannot be sparse (that is, the structure of each row of data must be consistent)
- Test environment:
1.Redhat7.9
2. Use root user operation
3.CM is 7.4.4 and CDP is 7.1.7
4. Kerberos is not enabled in the cluster
2. Preparation
1. Enter Hive on Tez service and visit 'Hive site' The following configuration parameters are added to the 'Hive service advanced configuration code segment (safety valve)' of XML. If they are not added, some Hive parameters set later cannot be executed normally.
<property> <name>hive.security.authorization.sqlstd.confwhitelist.append</name> <value>tez.*|hive.strict.checks.*|hive.mapred.*|mapreduce.*|total.*|hfile.*</value> </property>
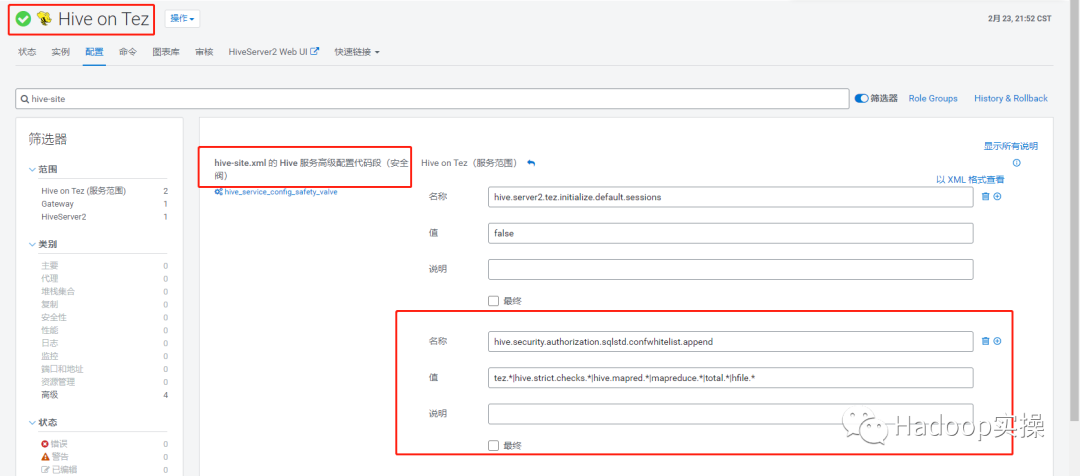
After saving the changes and returning to the CM home page, you will be prompted to restart the relevant services and redeploy the client configuration.
2. put some involved HBase jar packages into HDFS for later use. If you don't want to do this, you can also use Hive of Hive aux. jars. Path configuration. Add the jar package to this configuration.
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-common-2.2.3.7.1.7.0-551.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-server-2.2.3.7.1.7.0-551.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-client-2.2.3.7.1.7.0-551.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-protocol-2.2.3.7.1.7.0-551.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-mapreduce-2.2.3.7.1.7.0-551.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-shaded-mapreduce-2.2.3.7.1.7.0-551.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/htrace-core4-4.2.0-incubating.jar /tmp hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hive-hbase-handler-3.1.3000.7.1.7.0-551.jar /tmp
3. Prepare the data to be imported into HBase. First, create Hive appearance and insert the data.
create external table test_hbase
(
s1 string,
s2 string
)
row format delimited fields terminated by '#'
stored as textfile location '/tmp/test_hbase';
insert into test_hbase values('0000001','a'),('1000000','a'),('1000002','b'),('1000003','b'),('2000000','b'),('2000001','c'),('2000002','b'),('3000000','b'),('3100001','d'),('3100002','3'),('3100003','e'),('3100004','f'),('3100005','g'),('4000000','b'),('4000001','h'),('4100002','i'),('4000003','j');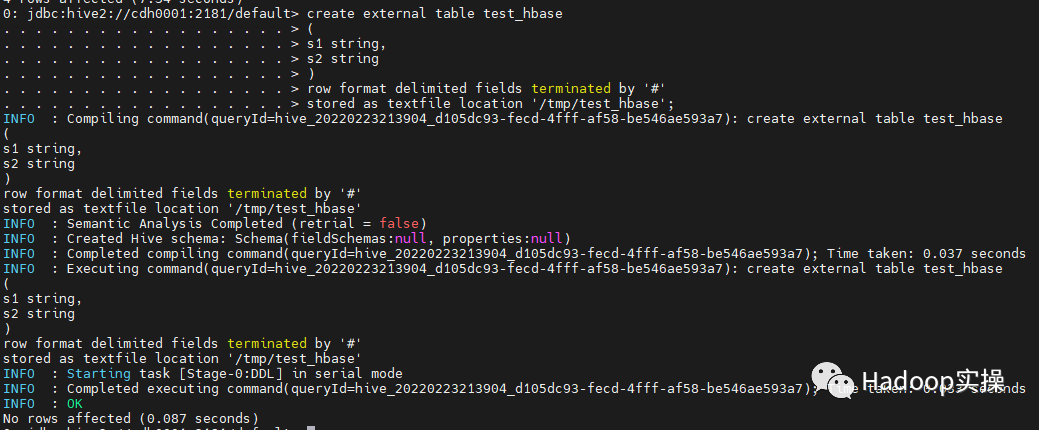

3. Generate partition key
When generating hfile files, we need to sort the data. In order to start multiple reduce tasks to sort the data in parallel, we need to use the partition key to divide the data into several ranges of the same size according to the rowkey field. Another advantage of this is that multiple hfile files will be generated. When hbase loads the file, it will be allocated to multiple regionserver nodes to achieve the effect of pre partition and improve the speed of subsequent data reading and writing.
First, we need to create a table to generate a data segmentation file:
create external table hb_range_keys (rowkey_range_start string) row format serde 'org.apache.hadoop.hive.serde2.binarysortable.BinarySortableSerDe' stored as inputformat 'org.apache.hadoop.mapred.TextInputFormat' outputformat 'org.apache.hadoop.hive.ql.io.HiveNullValueSequenceFileOutputFormat' location '/tmp/hbase_splits/region5'; --Specify the data storage directory, which will be used in the next steps
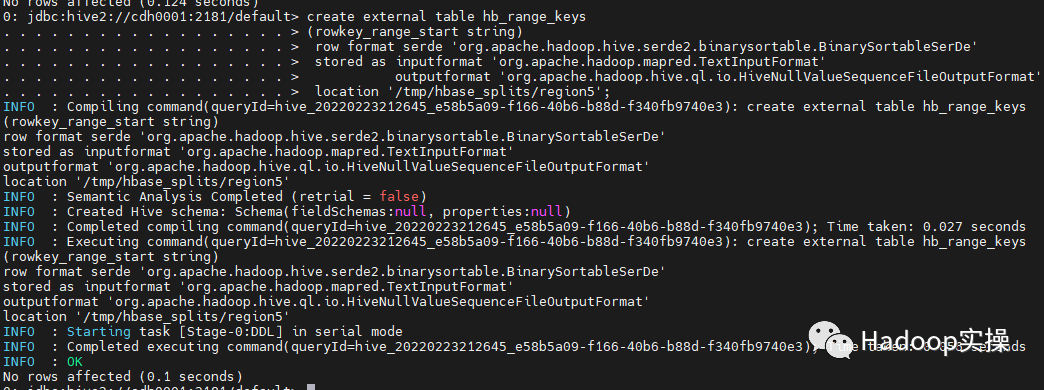
Next, you need to divide the data range according to the rowkey field:
The following is an example method given by hive's official document. By sorting 0.01% of the sample data, and then selecting each 910000 row of data, the data is divided into 12 copies. The assumption here is that the distribution in the sample matches the overall distribution in the table. If this is not the case, the generated partition key divides the data range unevenly, resulting in skew in parallel sorting
insert overwrite table hb_range_keys select transaction_id from (select transaction_id from transactions tablesample(bucket 1 out of 10000 on transaction_id) s order by transaction_id limit 10000000) x where (row_sequence() % 910000)=0 order by transaction_id limit 11;
Because Fayson didn't find the official data, we created several pieces of data (refer to the data inserted in Chapter 2) for testing, so we directly manually specify the partition key:
insert into hb_range_keys values('1000000'),('2000000'),('3000000'),('4000000');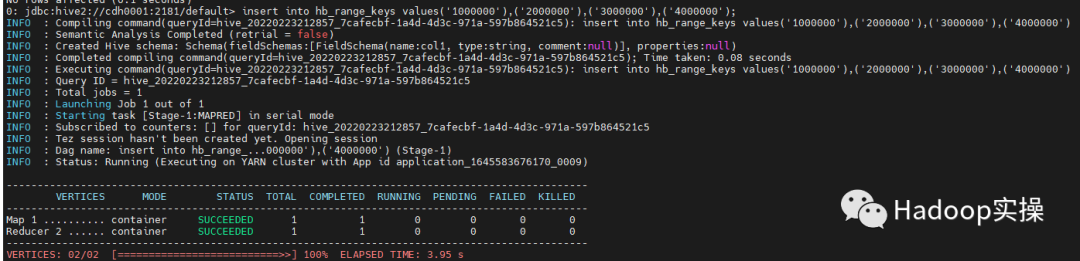
4. Generate hfile file
1. Create a table to generate and save hfile files. info in the path '/ tmp/hbsort1/info' is the column family name. Currently, only a single column family is supported
create external table hbsort(
row_key string,
column1 string
)
stored as
INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.hbase.HiveHFileOutputFormat'
TBLPROPERTIES ('hfile.family.path' = '/tmp/hbsort/info');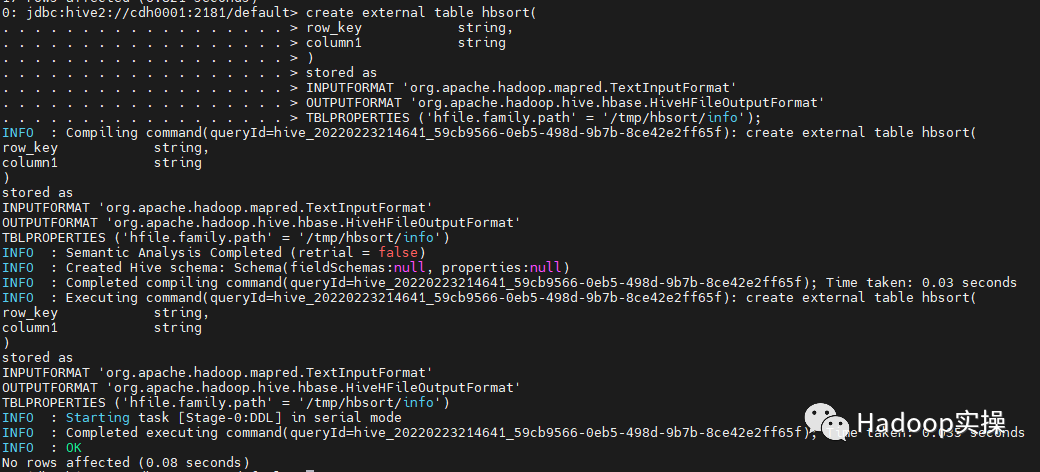
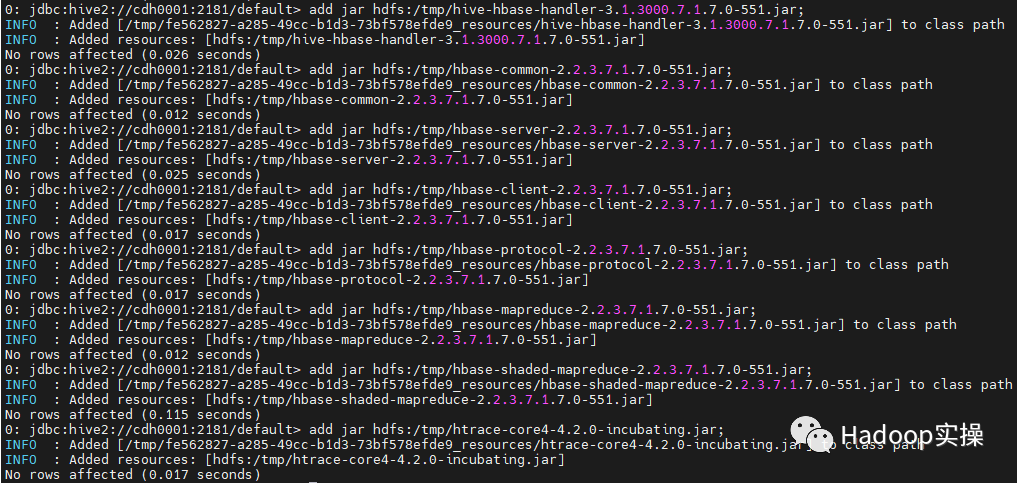
2. The next step is to prepare to generate hfile files. First, add jar packages in beeline, set relevant parameters, and set some Hive on Tez parameters:
--Add related jar package add jar hdfs:/tmp/hive-hbase-handler-3.1.3000.7.1.7.0-551.jar; add jar hdfs:/tmp/hbase-common-2.2.3.7.1.7.0-551.jar; add jar hdfs:/tmp/hbase-server-2.2.3.7.1.7.0-551.jar; add jar hdfs:/tmp/hbase-client-2.2.3.7.1.7.0-551.jar; add jar hdfs:/tmp/hbase-protocol-2.2.3.7.1.7.0-551.jar; add jar hdfs:/tmp/hbase-mapreduce-2.2.3.7.1.7.0-551.jar; add jar hdfs:/tmp/hbase-shaded-mapreduce-2.2.3.7.1.7.0-551.jar; add jar hdfs:/tmp/htrace-core4-4.2.0-incubating.jar; set mapred.reduce.tasks=5; --hb_range_keys Number of tables+1 set hive.mapred.partitioner=org.apache.hadoop.hive.ql.exec.tez.TezTotalOrderPartitioner; --Specify the partition key file address generated in the previous step set mapreduce.totalorderpartitioner.path=/tmp/hbase_splits/region5/000000_0; set total.order.partitioner.path=/tmp/hbase_splits/region5/000000_0; set hfile.compression=snappy;--appoint snappy compress

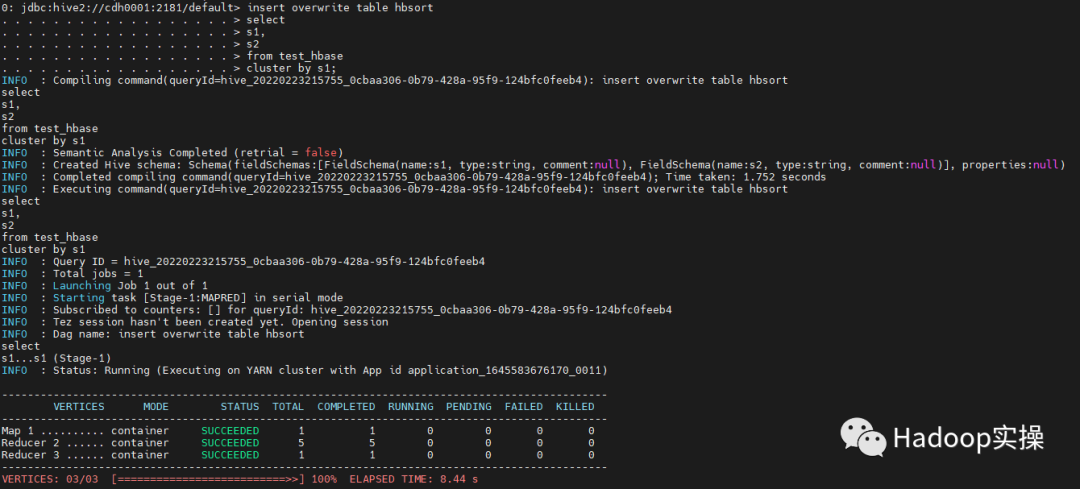
3. Write data into the table to generate hfile file:
insert overwrite table hbsort select s1, s2 from test_hbase cluster by s1;
5.Load data to HBase
1. First, change the group of the directory where hfile files are stored to the fayson user, which is used to execute the bulkload command of HBase.
sudo -u hdfs hadoop fs -chown -R fayson:fayson /tmp/hbsort
2. Execute the bulkload command of HBase
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/hbsort test_bulk
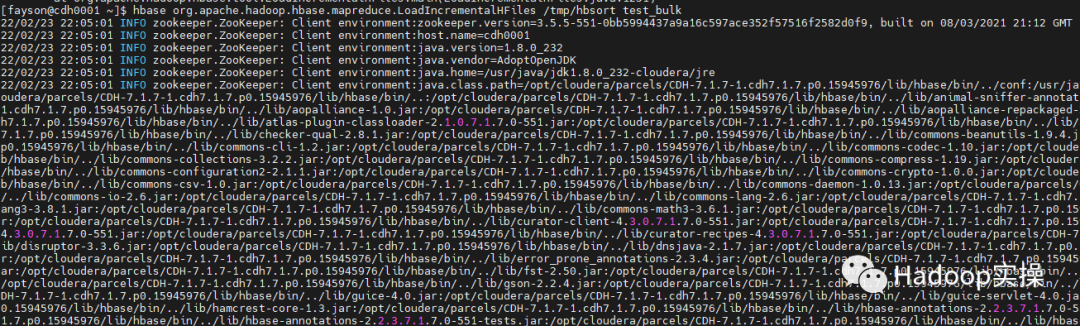

3. Use hbase shell to query that all data has been imported
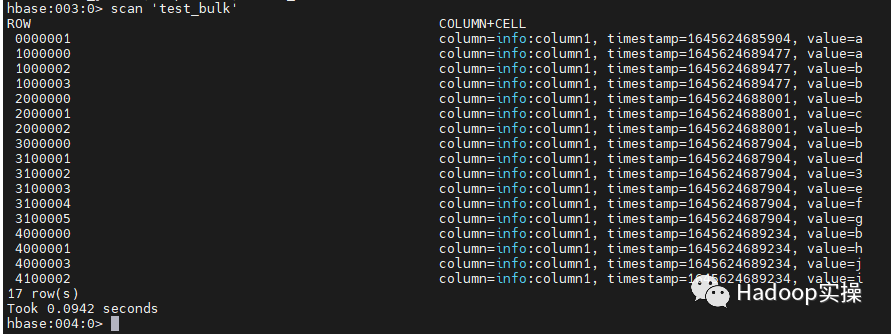
4. Enter the HBase Master page and confirm that the region is generated as expected and that the startkey and endkey are correct
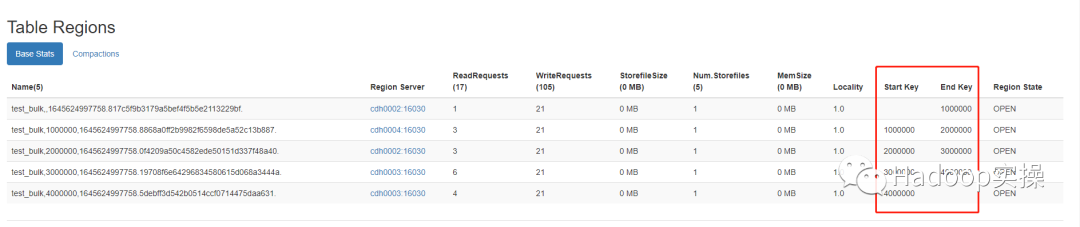
You can see that five region s, startkey, endkey and Hb, are generated correctly_ range_ The keys partition is consistent with the key table settings.
6. Frequently asked questions
1. Unlike CDH5/6, Hive in CDP uses tez engine by default, and some parameters of set are different. The consistency between CDH5/6 and Hive official website is as follows:
set mapred.reduce.tasks=12; set hive.mapred.partitioner=org.apache.hadoop.mapred.lib.TotalOrderPartitioner; set total.order.partitioner.path=/tmp/hb_range_key_list;
In CDP:
set mapred.reduce.tasks=5; set hive.mapred.partitioner=org.apache.hadoop.hive.ql.exec.tez.TezTotalOrderPartitioner; set mapreduce.totalorderpartitioner.path=/tmp/hbase_splits/region5/000000_0; set total.order.partitioner.path=/tmp/hbase_splits/region5/000000_0;
2. In order to set the above parameters in the beeline of CDP, the following parameters need to be added to the Hive on Tez service of CM:
<property> <name>hive.security.authorization.sqlstd.confwhitelist.append</name> <value>tez.*|hive.strict.checks.*|hive.mapred.*|mapreduce.*|total.*|hfile.*</value> </property>
3. The Hive internal table in CDP is the managed table of ACID by default, so it is recommended to create external tables for all Hive tables in this paper, otherwise they will not be supported.
4. If you find it troublesome to add various jar packages in beeline, you can permanently add these jars to Hive of Hive aux. jars. Path configuration.
5. Note that when executing the bulkload command of HBase in the last step, test is not allowed in HBase_ Bulk table, otherwise the number of region s cannot be generated as expected.
6. When executing the bulkload command of HBase, it is necessary to ensure that the user group of the directory where hfile is located is consistent with the user executing the bulkload command. fayson is used in this paper.
Reference documents:
https://cwiki.apache.org/confluence/display/Hive/HBaseBulkLoad#HBaseBulkLoad-AddnecessaryJARshttps://blog.csdn.net/songjifei/article/details/104706388https://blog.csdn.net/alinyua/article/details/109831892