1, Definition
- A string is a finite sequence of characters from the alphabet Σ
- S = a0a1a2...an-1 ∈ ∑*
- Features: there are not many types of characters that make up a string, but the string length may be much larger than the character types
- term
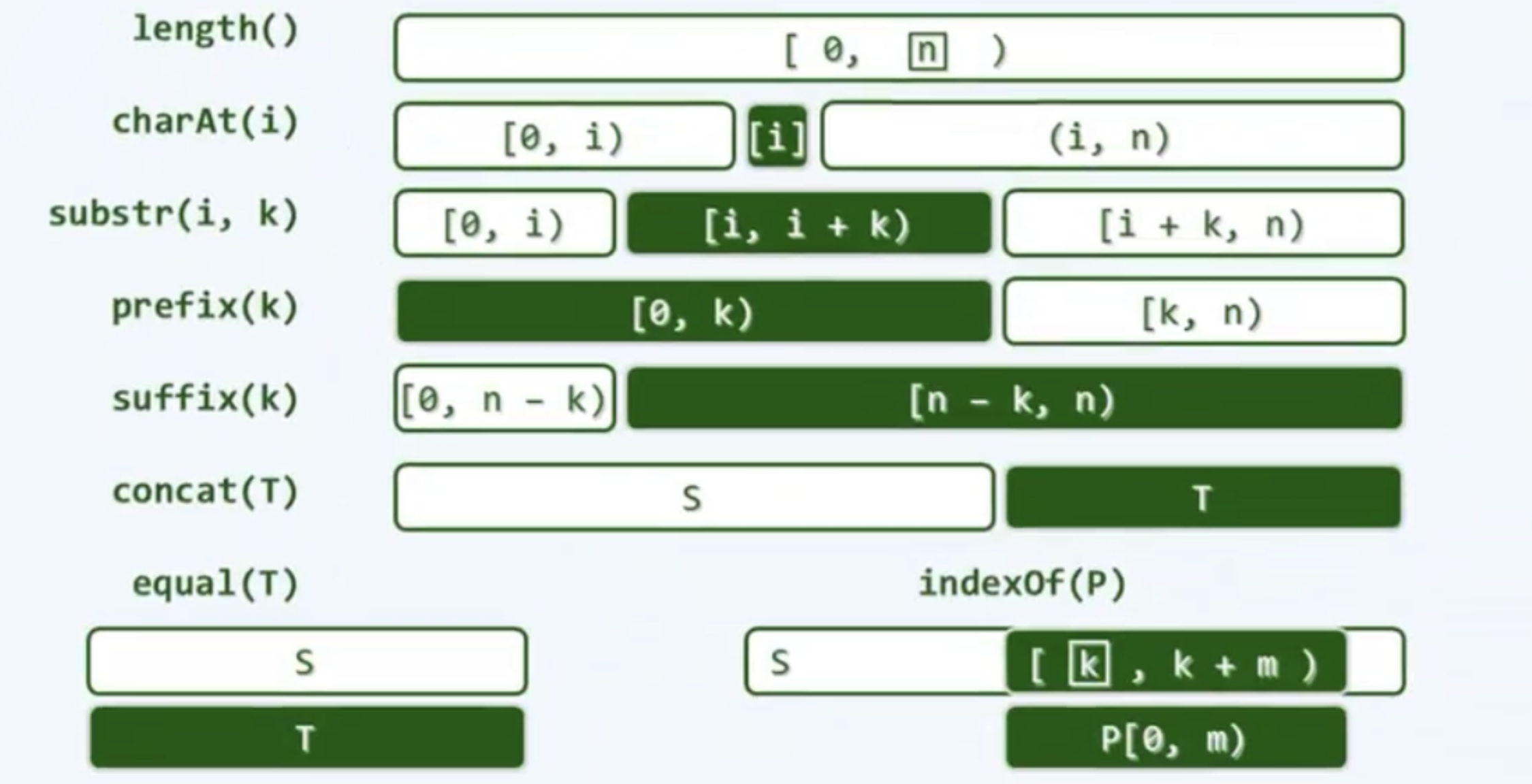
- Equal: if the length is equal and the corresponding characters are the same (S[i] = T[i]), then S[0, n) = T[0, m)
- String: k consecutive characters from S[i], i.e. s.sub (I, K) = S[i, I + k), 0 < = I < n, 0 < = K
- Prefix: the top k characters in S, i.e. S.prefix (k) = S.substr (0, K) = S [0, K), 0 < = k < = n
- Suffix: the last K characters in S, i.e. S.suffix (k) = S.substr (n - K, K) = S [n - K, n), 0 < = k < = n
- Contact: s.substr (I, K) = s.prefix (I + k) suffix(k)
- Empty string: S[0, n = 0), which is also the substring, prefix and suffix of the string
- Any string is also its own substring, prefix and suffix
- Substrings, prefixes and suffixes whose length is strictly less than the original string are also called true substrings, true prefixes and true suffixes
- ADT
2, String matching definition
- Given the text string T and the pattern string P, remember n = |T | and m = |P |, usually n > > M
- Increasing difficulty
- Detection: whether P appears
- location: where did it first appear
- counting: how many times
- enumeration: where do they appear
- Algorithm evaluation
- Random T, test the successful and failed matches respectively
- Success: in T, randomly take the substring with length m as P; Analysis average complexity
- Failure: random P; Statistical average complexity
3, Brute force string matching algorithm
- design
- Move the pattern string in character from left to right until a match is found at a certain position
- Version 1
int match(char* P, char* T){
size_t n = strlen(T), i = 0;
size_t m = strlen(P), j = 0;
while(j < m && i < n)//Compare the characters one by one from left to right. The value of j is equal to the number of successful matches that have been made in the current position. When j is equal to m, it indicates that the matching has been successful
if(T[i] == P[j]) {i++; j++;}//If it matches, it moves to the next character
else {i -= j - 1; j = 0;}//Otherwise, T fallback and P reset
return i - j;//Returns the subscript position that matches successfully
}//n - m is the rightmost and last position where the pattern string can be aligned relative to the text string. When I-J > N-M, the upper caller of the algorithm can conclude that the matching fails
int match(char *P, char* T){
size_t n = strlen(T), i = 0;//Align P [i] with 0 [t]
size_t m = strlen(P), j = 0;//T[i+j] aligned with P[j]
for(i = 0; i < n - m + 1 ; i++){//T from the i th character, and
for( j = 0; j < m ; j++)//Compare the corresponding characters in P one by one
if(T[i + j] != P[j]) break;//In case of mismatch, P moves one character to the right as a whole and re compares
if(m <= j) break;//Matching substring found
}
return i;
}//i> = n-m-1, the matching fails, otherwise the matching succeeds, and the subscript of the first matching is returned
- Complexity
- Best case (match can be determined after only one round of comparison): comparison times m = O(m)
- Worst case (match to the last character of P in each round and repeat)
- Each cycle: comparison times = m - 1 (success) + 1 (failure) = m
- Number of cycles = n - m + 1
- Generally, there are m < < n
- Therefore, in general, the comparison times = m * (n - m + 1) = O(n * m)
- The smaller the alphabet, the higher the probability of the worst case. The algorithm can not deal with a large number of local matches, and the smaller the alphabet, the higher the possibility of local matches.
- The greater m, the worse the worst-case consequences.
- In the case of a large alphabet, linear efficiency can be achieved
4, KMP algorithm
- Brute force, why is it inefficient
- There are a large number of prefixes in the pattern string that can locally match the text string, and the computational cost of brute force algorithm is mainly consumed in these prefixes
- thinking
- If a position value is aligned, a necessary condition is that the first character corresponding to the substring should be the same as the first character of the pattern string.
- All information about the substring is obtained through the previous round of comparison. As long as this kind of information can be used, two optimization effects can be obtained
- On the one hand, it can greatly slide the mode string backward
- On the other hand, it can avoid a large number of repeated comparisons
- After each failure, which character in the pattern string should be realigned with the character in the text string that just failed
- next array
- After the first failure of T[i] and P[j] in this round of comparison, how to slide the pattern string backward, so as to equivalently align a new P[j] with the previous T[i], and start a new round of matching from this position
- P[j] can not only be determined in advance, but also depends only on the mode string, independent of the main string. At this time, the main string can be divided into four parts, namely, the prefix and suffix of the text string, the matched substring and the mismatched character. The prefix and suffix have no effect on the new P[j] character. On the surface, the substring has an effect on the matching, but in essence, the substring matches the pattern string, so it still depends on the pattern string.
- The replaced character depends not so much on the pattern string as on the previous P[j] replaced by it
- Construct query table next[0, m): replace j with next[j] after failure at any position P[j]
- It's not so much with a strong memory as with a full plan
//Implementation of KMP algorithm
int match(char *P, char *T){
int *next = buildNext(P);//Construct next table
int n = (int) strlen(T), i = 0;//Text string pointer
int m = (int) strlen(P), j = 0;//Mode string pointer
while(j < m && i < n)//Compare characters one by one from left to right
if(0 > j || T[i] == P[j]){//If match
//next[0] is - 1, which is equivalent to setting a sentry. This character does not actually exist, indicating a character matching all characters. In order to avoid matching failure at the first character, the prefix is an empty set, so set next[0] to - 1
i++; j++;//Hand in hand
}else//Otherwise, P moves right and T does not retreat
j = next[j];
delete[] next;//Release next table
return i - j;
}//KMP algorithm will replace the prefix at the time of mismatch with the new prefix with the length of next[j], and continue the next round of comparison from the position of the mismatch just now
- Self matching in KMP = fast shift right + avoid fallback
- With the help of necessary conditions
- Exclude alignment positions
- In the prefix P[0, j) of the pattern string P[j], the length of all matching true prefixes and true suffixes is the value of the next array
- Therefore, once the matching fails, take a T from N(P, j), align P[t] with T[i], and continue the comparison
- Construct next table
- The so-called next(j) is the length of the maximum self matching true prefix and true suffix in P[0, j)
- Therefore, next [J + 1] < = next [J] + 1, if and only if P [J] = = P [next [J]], take the equal sign
- The construction process of the next table is essentially the process of continuously matching the pattern string itself with itself
//Construction of next table
int * buildNext(char* P){//Construct the next [] table of pattern string P
size_t m = strlen(P), j = 0;//"Main" string pointer
int * N = new int[m];//next [] table
int t = N[0] = -1;//Mode string pointer (P[-1] wildcard)
while(j < m - 1)
if(0 > t || P[j] == P[t])//matching
N[++j] = ++t;
else//Mismatch
t = N[t];
return N;
}
- Complexity analysis
- The initial value of K is 0; At the end of the algorithm, there must be: k = 2 * I - J < = 2 (n - 1) - (- 1) = 2n - 1
- Delete the non iterative part of the algorithm that does not involve the actual calculation content, and focus on the main body of complexity, that is, loop

- Further improvement of KMP
- Semantics of next array value: next[3] = 2. Among the prefixes with length 3, there is a true prefix with length 2 that exactly matches the true suffix with the same length of 2, and this is also the longest match.
int * buildNext(char *p){
size_t m = strlen(P), j = 0;//"Main" string pointer
int * N = new int[m];//next table
int t = N[0] = -1;//Mode string pointer
while(j < m - 1)
if(0 > t || P[j] == P[t]){//matching
j++; t++; N[j] = P[j] != P[t] ? t : N[t];
//Only when the replaced character is different from the original character, the assignment continues in the original way
}else//
t = N[t];
return N;
}
- Comparison between KMP and brute force algorithm
- KMP has obvious advantages when the alphabet is small
- With the increase of alphabet scale, the efficiency of brute force algorithm will be greatly improved