neo4j Chinese document - Getting Started Guide
Neo4j v4.4
permit: Knowledge sharing 4.0
neo4j
Neo4j is the world's leading graphics database. The architecture is designed to optimize the management, storage, and traversal of nodes and relationships. Graph database adopts attribute graph method, which is good for traversal performance and operation runtime.
**Cypher **
Cypher is Neo4j's graphics query language, which allows users to store and retrieve data from the graphics database. It is a declarative, SQL inspired language for describing visual patterns in graphics using ASCII art syntax. Syntax provides a visual and logical way to match patterns of nodes and relationships in a graph. Cypher aims to make it easy for everyone to learn, understand and use, and also integrates the powerful functions of other standard data access languages.
Contents of this guide
The Neo4j getting started guide covers the following areas:
- Start using Neo4j - how to get started with Neo4j.
- Figure database concept -Figure database concept Introduction.
- Cypher introduction - Introduction to graph query language Cypher.
Who should read this?
This guide is written for anyone who is exploring Neo4j and Cypher.
Start using Neo4j
There are many options on how to install Neo4j and how to start running Cypher queries.
1. Install Neo4j
The easiest way to set up an environment for developing applications using Neo4j and Cypher is to use Neo4j Desktop. from https://neo4j.com/download/ Download Neo4j Desktop and follow the installation instructions for your operating system.
For more options on how to get started with Neo4j and Cypher, see https://neo4j.com/try-neo4j/ .
2. Documentation
All official documents can be found in https://neo4j.com/docs/ get.
Here you can find the complete manual, for example:
- Cypher manual - this is Cypher's comprehensive manual.
- Operation manual - this manual describes how to deploy and maintain Neo4j.
The Cypher Refcard It is a valuable and accurate material for learning and writing Cypher
In addition, you can find more professional documentation, as well as API documentation and older Neo4j versions.
Figure database concept
Neo4j uses the attribute graph database model.
The graph data structure consists of nodes (discrete objects) that can be connected through relationships.
Example 1. Concept of graph structure.
A graph with three nodes (circles) and three relationships (arrows).
Neo4j attribute graph database model includes:
- Nodes describe the entities of the domain (discrete objects).
- Nodes can have zero or more labels to define (classify) what type of nodes they are.
- The relationship describes the connection between the source node and the target node.
- Relationships always have one direction (one direction).
- Relationships must have a type (a type) to define (classify) what type of relationship they are.
- Nodes and relationships can have attributes (key value pairs) that further describe them.
In mathematics, graph theory is the study of graphs. In graph theory: nodes are also called vertices or points. Relationships are also called edges, links, or lines.
1. Example diagram
The following example diagram introduces the basic concept of attribute diagram:
Example 2. Example diagram.
Example 3. Password.
To CREATE a sample diagram, use the Cypher clause CREATE.
CREATE (:Person:Actor {name: 'Tom Hanks', born: 1956})-[:ACTED_IN {roles: ['Forrest']}]->(:Movie {title: 'Forrest Gump'})<-[:DIRECTED]-(:Person {name: 'Robert Zemeckis', born: 1951})
2. Node
Node is used to represent the entity (discrete object) of the domain.
The simplest diagram is a single node that has no relationship. Consider the following figure, which consists of a single node.
Example 4. Node.
Node labels are:
- Person
- Actor
The properties are:
- name: Tom Hanks
- born: 1956
You can create nodes using Cypher queries:
CREATE (:Person:Actor {name: 'Tom Hanks', born: 1956})
3. Node label
Labels shape a domain by grouping (classifying) nodes into a set, where all nodes with a specific label belong to the same set.
For example, all nodes representing users can label users with labels. With it, you can let Neo4j perform operations only on your User nodes, such as finding all users with a given name.
Because labels can be added and removed at run time, they can also be used to mark the temporary state of a node. A Suspended tag can be used to indicate the Suspended bank account, and the Seasonal tag can indicate the current season of vegetables.
A node can have zero to multiple labels.
In this example diagram, the labels of nodes, Person, Actor, and Movie, are used to describe (classify) nodes. More labels can be added to represent different dimensions of data.
The following figure shows the use of multiple labels.
Example 5. Multiple labels.
4. Relationship
Relationships describe how connections between source and target nodes are related. Nodes may be related to themselves.
Relationship:
- Connect the source node and the target node.
- There is one direction (one direction).
- There must be a type (a type) to define (classify) what type of relationship it is.
- There can be attributes (key value pairs) to further describe the relationship.
Relationships organize nodes into structures, allowing diagrams to be similar to lists, trees, maps, or composite entities -- any of which can be combined into more complex, interrelated structures.
Example 6. Relationship.
Node type: ACTED_IN
The properties are:
- roles: ['Forrest']
- performance: 5
The roles property has an array value containing a single item ('Forrest ').
You can create relationships using Cypher queries:
CREATE ()-[:ACTED_IN {roles: ['Forrest'], performance: 5}]->()
You must create or reference source and target nodes to create a relationship.
Relationships always have directions. However, if the direction is not useful, it can be ignored. This means that there is no need to add duplicate relationships in the opposite direction unless the data model needs to be described correctly.
A node can have a relationship with itself. To express Tom Hanks KNOWS, he himself will be expressed as:
Example 7. Relationship with a single node.
5. Relationship type
A relationship must have only one relationship type.
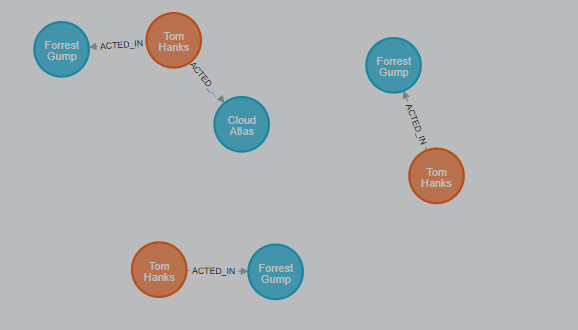
Here is an ACTED_IN relationship, with Tom Hanks node as the source node and Forrest Gump as the target node.
Example 8. Relationship type.
Observe that the Tom Hanks node has an outgoing relationship, while the Forrest Gump node has an incoming relationship.
6. Properties
Attributes are key value pairs used to store node and relational data.
Value part of property:
- It can accommodate different data types, such as number, string or boolean.
- You can save a homogeneous list (array) that contains, for example, strings, numbers, or boolean values.
Example 9. Numbers
CREATE (:Example {a: 1, b: 3.14})
- The attribute a has type 1 with integer value.
- The attribute b has a float value of type 3.14.
Example 10. String and Boolean
CREATE (:Example {c: 'This is an example string', d: true, e: false})
- The attribute c has the type 'This is an example string' with a string value of.
- The attribute d has a boolean value of type true.
- The property e has a boolean value of type false.
Example 11. List
CREATE (:Example {f: [1, 2, 3], g: [2.71, 3.14], h: ['abc', 'example'], i: [true, true, false]})
- The property f contains an array [1, 2, 3] with a value of.
- This attribute g contains an array with a value of [2.71, 3.14].
- The attribute h contains an array ['abc ',' example '] with a value of.
- The attribute i contains an array with a value of [true, true, false].
For a detailed description of the available data types, see Cypher manual → values and types.
7. Traversal and path
Traversal is a way for you to query a graph to find the answer to a question, for example, "what music does my friend like but I don't have it yet?" or "what Web services will be affected if this power supply is interrupted?".
Traversal graph refers to accessing nodes according to certain rules and relationships. In most cases, only a subset of the graph is accessed.
Example 12. Path matching.
In order to find out the movies played by Tom Hanks according to the micro sample database, the traversal will start from the Tom Hanks node and follow ACTED_IN is connected to any relationship between nodes. Finally, Forrest Gump obtains the result (see dotted line):
The traversal result can return 1 as a path with length:
The length of the shortest path is zero. It contains a node and has no relationship.
Example 13. Zero length path.
The length of a path that contains only a single node is 0.
Example 14. Path with length 1.
The length of the path containing a relationship is 1.
8. Architecture
Patterns in Neo4j refer to indexes and constraints.
Neo4j is usually described as schema optional, which means that there is no need to create indexes and constraints. You can create data -- nodes, relationships, and attributes -- without having to define a schema in advance. Indexes and constraints can be introduced as needed for performance or modeling benefits.
9. Index
Indexes are used to improve performance. To see how Using indexed For an example, see Use index . For detailed instructions on how to use indexes in Cypher, see Cypher manual → index.
10. Constraints
Constraints are used to ensure that data conforms to the rules of the domain. To see how Using constrained For an example, see Use constraints . For detailed instructions on how to use constraints in Cypher, see Cypher manual → constraints.
11. Naming convention
Node labels, relationship types, and attributes (key parts) are case sensitive. For example, this means that attributes are different from attribute name.
The following naming conventions are recommended:
| Graph entity | Recommended style | example |
|---|---|---|
| Node label | Hump case, starting with uppercase characters | :VehicleOwnerrather than:vehice_owner |
| Relationship type | Capitalize and separate words with underscores | :OWNS_VEHICLErather than:ownsVehicle |
| property | Hump lowercase, starting with lowercase characters | firstNamerather thanfirst_name |
For specific naming rules, please refer to Cypher manual → naming rules and recommendations.
Cypher introduction
This section will introduce you to the graph query language Cypher. It will help you start thinking about graphics and patterns, apply this knowledge to simple problems, and learn how to write Cypher statements.
For a complete reference to Cypher, see Cypher manual.
(1) , Patterns
Neo4j's attribute graph consists of nodes and relationships, any of which may have attributes. Nodes represent entities, such as concepts, events, places, and things. Relationships connect pairs of nodes.
However, nodes and relationships can be considered low-level building blocks. The real advantage of attribute graph is that it can encode the patterns connecting nodes and relationships. A single node or relationship usually encodes little information, but the patterns of nodes and relationships can encode arbitrarily complex ideas.
Neo4j's query language Cypher is strongly schema based. Specifically, patterns are used to match the desired graphical structure. Once the matching structure is found or created, neo4j can use it for further processing.
A simple pattern, with only one relationship, connects a pair of nodes (or, occasionally, a node to itself). For example, a person LIVES_IN is a city or a city is PART_OF a country.
Complex patterns, using multiple relationships, can express arbitrarily complex concepts and support a variety of interesting use cases. For example, we might want to match person lives_ Instances of in and Country. The following Cypher code combines two simple patterns into a slightly more complex pattern to perform this matching:
(:Person) -[:LIVES_IN]-> (:City) -[:PART_OF]-> (:Country)
Charts consisting of icons and arrows are often used to visualize graphics. Text notes provide labels, define attributes, and so on.
1. Node syntax
Cypher uses a pair of parentheses to represent a node: (). This is reminiscent of a circle or rectangle with a circular end cap. The following are some node examples that provide details of different types and variables:
()
(matrix)
(:Movie)
(matrix:Movie)
(matrix:Movie {title: 'The Matrix'})
(matrix:Movie {title: 'The Matrix', released: 1997})
In its simplest form, () represents an anonymous, featureless node. If we want to reference this node elsewhere, we can add a variable, for example: (matrix). Variables are limited to a single statement. It may or may not have a different meaning in another statement.
This: the Movie schema declares the label of the node. This allows us to restrict the pattern so that it does not match, for example, the structure of the node with the Actor at that location.
For example, title, the attribute of a node is represented as a list of key value pairs, enclosed in a pair of braces, for example: {name: 'Keanu Reeves'}. Properties can be used to store information and / or limit patterns.
2. Relational grammar
Cypher uses a pair of dashes (- -) to indicate an undirected relationship. There is an arrow (< --, - >) at one end of the orientation relationship. Bracket expressions ([...]) can be used to add details. This may include variable, attribute, and type information:
-->
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ['Neo']}]->
The syntax and semantics in parenthesis pairs of relationships are very similar to those used between node parentheses. Role can define a variable (for example, role) for use elsewhere in the statement. The type of relationship (for example: ACTED_IN) is similar to the label of a node. Attributes (for example, roles) are identical to node attributes.
3. Pattern syntax
Combining the syntax of nodes and relationships, we can express patterns. The following may be a simple pattern (or fact) in this field:
(keanu:Person:Actor {name: 'Keanu Reeves'})-[role:ACTED_IN {roles: ['Neo']}]->(matrix:Movie {title: 'The Matrix'})
Equivalent to node label: acted_ The in schema declares the relationship type of the relationship. Variables (for example, role s) can be used elsewhere in the statement to refer to relationships.
Like node attributes, relationship attributes are represented in a pair of braces, such as the list of key / value pairs: {roles: ['Neo ']}. In this case, we use an array attribute roles for, which allows multiple roles to be specified. Properties can be used to store information and / or limit patterns.
4. Mode variables
To increase modularity and reduce duplication, Cypher allows patterns to be assigned to variables. This allows you to check the matching path for other expressions, etc.
acted_in = (:Person)-[:ACTED_IN]->(:Movie)
The acted_ The in variable will contain the connection between the two nodes and each path found or created. Paths with multiple functions, such as access details: nodes(path), relationships(path), and length(path).
5. Rules
Cypher statements usually have multiple clauses, and each clause performs a specific task, such as:
- Create and match patterns in diagrams
- Filter, project, sort, or page results
- Write some statements
By combining Cypher clauses, we can combine more complex statements to express what we want to know or create.
Model practice
1. Create data
We will first look at the clauses that allow us to create data.
To add data, we use only the patterns we already know. By providing a schema, we can specify which graphic structures, labels, and attributes we want to be part of the graph.
Obviously, the simplest clause is called CREATE. It will continue to CREATE the schema you specify directly.
For the pattern we see so far, it may be as follows:
Cypher
CREATE (:Movie {title: 'The Matrix', released: 1997})
If we execute this statement, Cypher will return the number of changes, adding 1 node, 1 label and 2 attributes in this example.
Created Nodes: 1 Added Labels: 1 Set Properties: 2 Rows: 0
When we start with an empty database, we now have a database containing a single node:
If we also want to RETURN the created data, we can add a RETURN clause that references the variables we assigned to the schema elements.
Cypher
CREATE (p:Person {name: 'Keanu Reeves', born: 1964})
RETURN p
This is what is returned:
Created Nodes: 1
Added Labels: 1
Set Properties: 2
Rows: 1
+----------------------------------------------+
| p |
+----------------------------------------------+
| (:Person {name: 'Keanu Reeves', born: 1964}) |
+----------------------------------------------+
If we want to CREATE multiple elements, we can separate the elements with commas (,) or use multiple CREATE statements.
Of course, we can also create more complex structures, such as acted_ The relationship between in and character information or DIRECTED director information.
Cypher
CREATE (a:Person {name: 'Tom Hanks', born: 1956})-[r:ACTED_IN {roles: ['Forrest']}]->(m:Movie {title: 'Forrest Gump', released: 1994})
CREATE (d:Person {name: 'Robert Zemeckis', born: 1951})-[:DIRECTED]->(m)
RETURN a, d, r, m
This is the chart we just updated:
In most cases, we want to connect new data to existing structures. This requires us to know how to find existing patterns in our graphic data, which we will study next.
2. Matching mode
Matching patterns is the task of MATCH statements. We pass the same type of pattern MATCH we have used so far to describe what we are looking for. It is similar to query by example, but our example also includes structure.
A MATCH statement will search for the pattern we specify and return one row for each successful pattern MATCH.
In order to find the data we have created so far, we can start looking for all the nodes labeled Movie.
Cypher
MATCH (m:Movie) RETURN m
The results are as follows:
This should show both The Matrix and Forrest Gump.
We can also find a specific person, such as kenu Reeves.
Cypher
MATCH (p:Person {name: 'Keanu Reeves'})
RETURN p
This query returns matching nodes:
It should be noted here that we only provide enough information to find nodes, and not all attributes are required. In most cases, you need to find key attributes, such as SSN, ISBN, email, login, geographic location, or product code.
We can also find more interesting connections, such as the name of the film played by Tom Hanks and his role.
Cypher
MATCH (p:Person {name: 'Tom Hanks'})-[r:ACTED_IN]->(m:Movie)
RETURN m.title, r.roles
Rows: 1 +------------------------------+ | m.title | r.roles | +------------------------------+ | 'Forrest Gump' | ['Forrest'] | +------------------------------+
In this case, we only return the attributes of the nodes and relationships we are interested in. You can access their identifier.property anywhere through the dot symbol.
Of course, this just lists his role as Forrest in Forrest Gump, because this is all the data we added.
Now we know enough to connect new nodes to existing nodes, and we can combine MATCH and CREATE additional structures into the diagram.
3. Attachment structure
To extend the graph with new information, we first match existing connection points, and then attach the newly created nodes to them through relationships. Adding Cloud Atlas as a new movie for Tom Hanks can be achieved as follows:
Cypher
MATCH (p:Person {name: 'Tom Hanks'})
CREATE (m:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (p)-[r:ACTED_IN {roles: ['Zachry']}]->(m)
RETURN p, r, m
The following is the structure in the database:
It is important to remember that we can assign variables to nodes and relationships and use them later, whether they are created or matched.
You can attach nodes and relationships in a single CREATE clause. It is helpful to separate them for readability.
One tricky aspect of MATCH and composition is that we get a row for each matched pattern. This causes create to execute subsequent statements once for each row. In many cases, this is exactly what you want. If this is not intentional, move the create statement to the previous MATCH, or use the method discussed later to change the cardinality of the query, or use the get or create semantics of the next clause: MERGE.
4. Completion mode
Whenever we obtain data from an external system or are uncertain whether some information already exists in the graph, we want to express repeatable (idempotent) update operations. MERGE has this function in Cypher. Its function is similar to the combination CREATE of MATCH or. It first checks whether the data exists before creating the data. Work with MERGE to define the schema you want to find or CREATE. In general, like MATCH, you only want to include the key attributes you want to find in the core schema. MERGE allows you to provide additional properties to set ON CREATE.
If we don't know whether our graphics already contain Cloud Atlas, we can merge them again.
Cypher
MERGE (m:Movie {title: 'Cloud Atlas'})
ON CREATE SET m.released = 2012
RETURN m
Created Nodes: 1
Added Labels: 1
Set Properties: 2
Rows: 1
+-------------------------------------------------+
| m |
+-------------------------------------------------+
| (:Movie {title: 'Cloud Atlas', released: 2012}) |
+-------------------------------------------------+
We will get the result in any two cases: either the existing data in the graph (possibly more than one row) or a newly created Movie node.
Where MERGE does not have clauses for any previously assigned variables that match the full pattern or create a full pattern. It never produces a partial mix of matching and creation in the pattern. To achieve partial matching / creation, ensure that defined variables are used for parts that should not be affected.
Therefore, the most important MERGE is to ensure that you cannot CREATE duplicate information or structures, but this requires first checking the cost of existing matches. Especially on large graphs, the cost of scanning a large number of labeled nodes to obtain specific attributes may be high. You can alleviate some of these problems by creating supporting indexes or constraints, which we will discuss later. But it's still not free, so whenever you don't CREATE duplicate data, use CREATE MERGE.
MERGE can also assert that a relationship is created only once. To do this, you must pass in two nodes from the previous pattern match.
Cypher
MATCH (m:Movie {title: 'Cloud Atlas'})
MATCH (p:Person {name: 'Tom Hanks'})
MERGE (p)-[r:ACTED_IN]->(m)
ON CREATE SET r.roles =['Zachry']
RETURN p, r, m
If the direction of the relationship is arbitrary, you can not use arrows. MERGE then checks the relationship in either direction and creates a new orientation relationship if no matching relationship is found.
MERGE provides an interesting feature if you choose to pass in only one node in the previous clause. Then it will only match in the direct neighborhood of the providing node of the given pattern. If it is not found, it will be created. This is very convenient for creating tree structures, for example.
Cypher
CREATE (y:Year {year: 2014})
MERGE (y)<-[:IN_YEAR]-(m10:Month {month: 10})
MERGE (y)<-[:IN_YEAR]-(m11:Month {month: 11})
RETURN y, m10, m11
This is the graphic structure created:
There is no global search for these two Month nodes; Search for them only in the context of the 2014 Year node.
Return correct results
1. Example diagram
First, we create some data for our example:
Cypher
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
This is the result diagram:
2. Filtering results
So far, we have matched the pattern in the graph AND always return all the results we find. Now we'll look at the options for filtering results, returning only a subset of the data we're interested in. These filter conditions are represented by the WHERE clause. This clause allows any number of Boolean expressions, predicates, AND combinations of AND, OR, XOR, AND NOT. The simplest predicate is comparison; Especially equal to (=).
Cypher
MATCH (m:Movie) WHERE m.title = 'The Matrix' RETURN m
Rows: 1
+------------------------------------------------+
| m |
+------------------------------------------------+
| (:Movie {title: 'The Matrix', released: 1997}) |
+------------------------------------------------+
The above query uses the WHERE clause, which is equivalent to this query. It contains conditions in pattern matching:
Cypher
MATCH (m:Movie {title: 'The Matrix'}) RETURN m
Other options include number comparison, matching regular expressions, and checking for the presence of values in the list.
WHERE the clauses in the following examples include regular expression matching, greater than comparison, and tests to see if a value exists in the list:
Cypher
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) WHERE p.name =~ 'K.+' OR m.released > 2000 OR 'Neo' IN r.roles RETURN p, r, m
Rows: 1
+-------------------------------------------------------------------------------------------------------------------------------+
| p | r | m |
+-------------------------------------------------------------------------------------------------------------------------------+
| (:Person {name: 'Tom Hanks', born: 1956}) | [:ACTED_IN {roles: ['Zachry']}] | (:Movie {title: 'Cloud Atlas', released: 2012}) |
+-------------------------------------------------------------------------------------------------------------------------------+
A high-level aspect is that patterns can be used as predicates. Where MATCH extends the number and shape of matching patterns, pattern predicates limit the current result set. It only allows paths that meet the specified pattern to pass through. As we can expect, using NOT only allows paths to pass those that do NOT conform to the specified pattern.
Cypher
MATCH (p:Person)-[:ACTED_IN]->(m) WHERE NOT (p)-[:DIRECTED]->() RETURN p, m
Rows: 2
+----------------------------------------------------------------------------------------------+
| p | m |
+----------------------------------------------------------------------------------------------+
| (:Person {name: 'Tom Hanks', born: 1956}) | (:Movie {title: 'Cloud Atlas', released: 2012}) |
| (:Person {name: 'Tom Hanks', born: 1956}) | (:Movie {title: 'Forrest Gump', released: 1994}) |
+----------------------------------------------------------------------------------------------+
The return figure is as follows:
Here, we find actors because they established ACTED_IN relationship, but then skipped those actors in any DIRECTED movie.
There are more advanced filtering methods, such as list predicates, which we will discuss later in this section.
3. Return results
So far, we have returned nodes, relationships, and paths directly through their variables. However, the RETURN clause can RETURN any number of expressions. But what is the expression in Cypher?
The simplest expression is a literal value. Examples of literal values include numbers, strings, arrays (for example:) [1,2,3] and mappings (for example:) {Name: 'Tom Hanks', born: 1964, movies: ['forrest Gump',...], count: 13}. Access point syntax can be used for any node, relationship or map attributes, such as n.name. You can use subscripts to retrieve individual elements or array slices, such as names[0] and movies[1..-1]. The evaluation of each function, such as length(array), toInteger('12 '), substring('2014-07-01', 0, 4) and coalesce(p.nickname, 'n/a'), is also an expression.
The predicate used in the WHERE clause counts as a Boolean expression.
Simple expressions can be combined and concatenated to form more complex expressions.
By default, the expression itself will be used as the label of the column. In many cases, you want to use expression AS alias. You can then use an alias to refer to the column.
Cypher
MATCH (p:Person)
RETURN
p,
p.name AS name,
toUpper(p.name),
coalesce(p.nickname, 'n/a') AS nickname,
{name: p.name, label: head(labels(p))} AS person
Rows: 3
+-------------------------------------------------------------------------------------------------------------------------------------------------+
| p | name | toUpper(p.name) | nickname | person |
+-------------------------------------------------------------------------------------------------------------------------------------------------+
| (:Person {name: 'Keanu Reeves', born: 1964}) | 'Keanu Reeves' | 'KEANU REEVES' | 'n/a' | {name: 'Keanu Reeves', label: 'Person'} |
| (:Person {name: 'Robert Zemeckis', born: 1951}) | 'Robert Zemeckis' | 'ROBERT ZEMECKIS' | 'n/a' | {name: 'Robert Zemeckis', label: 'Person'} |
| (:Person {name: 'Tom Hanks', born: 1956}) | 'Tom Hanks' | 'TOM HANKS' | 'n/a' | {name: 'Tom Hanks', label: 'Person'} |
+-------------------------------------------------------------------------------------------------------------------------------------------------+
If we want to display only unique results, we can use the distinct Tafter keyword RETURN:
Cypher
MATCH (n) RETURN DISTINCT labels(n) AS Labels
Rows: 2 +------------+ | Labels | +------------+ | ['Movie'] | | ['Person'] | +------------+
4. Summary information
In many cases, we want to aggregate or group the data we encounter when traversing the patterns in the graph. In Cypher, aggregation occurs in the clause where RETURN evaluates the final result. Many common aggregation functions are supported, such as count, sum, avg, min, and max, but there are also several.
You can calculate the number of people in the database in the following ways:
Cypher
MATCH (:Person) RETURN count(*) AS people
Rows: 1 +--------+ | people | +--------+ | 3 | +--------+
Note that values are skipped during NULL aggregation. To aggregate only unique values, use DISTINCT, for example: count(DISTINCT role).
Aggregation works implicitly in cypher. We specify the result columns to aggregate. Cypher will use all non aggregate columns as grouping keys.
Aggregation affects which data is still visible in the sort or later query section.
The following statement identifies how often actors and directors work together:
Cypher
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person) RETURN actor, director, count(*) AS collaborations
Rows: 1
+--------------------------------------------------------------------------------------------------------------+
| actor | director | collaborations |
+--------------------------------------------------------------------------------------------------------------+
| (:Person {name: 'Tom Hanks', born: 1956}) | (:Person {name: 'Robert Zemeckis', born: 1951}) | 1 |
+--------------------------------------------------------------------------------------------------------------+
5. Sorting and pagination
Sorting and paging after aggregation is a common count(x).
Use the ORDER BY expression [ASC|DESC] clause to sort. An expression can be any expression as long as it can be calculated from the returned information.
For example, if we return person.name, we can still ORDER BY person.age because both can be accessed from the person reference. We can't order things that haven't been returned. This is particularly important for aggregation and DISTINCT return values, as both eliminate the visibility of aggregated data.
Paging is done using the SKIP {offset}andLIMIT {count} clause.
A common pattern is to aggregate a count (score or frequency), sort by it, and then return only top-n entries.
For example, in order to find the most productive actors we can do:
Cypher
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) RETURN a, count(*) AS appearances ORDER BY appearances DESC LIMIT 10
Rows: 1
+---------------------------------------------------------+
| a | appearances |
+---------------------------------------------------------+
| (:Person {name: 'Tom Hanks', born: 1956}) | 2 |
+---------------------------------------------------------+
6. Collection and aggregation
A very useful aggregate function is collect(), which collects all aggregate values into a list. This is useful in many cases because no details are lost during aggregation.
collect() is very suitable for retrieving a typical parent-child structure, in which each row returns a core entity (parent, root or head) and all related information, which is located in collect(). This means that there is no need to repeat the parent information for each child row, and there is no need to run an n+1 statement to retrieve the parent row and its child rows respectively.
The following statement can be used to retrieve the actor list of each movie in our database:
Cypher
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person) RETURN m.title AS movie, collect(a.name) AS cast, count(*) AS actors
Rows: 2 +-----------------------------------------+ | movie | cast | actors | +-----------------------------------------+ | 'Forrest Gump' | ['Tom Hanks'] | 1 | | 'Cloud Atlas' | ['Tom Hanks'] | 1 | +-----------------------------------------+
The created list collect() can be used from clients using Cypher results or directly in statements with any list function or predicate.
Write complex statements
1. Example graph
We continue to use the same sample data as before:
Cypher
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
This is the result diagram:
2. UNION
If you want to merge the results of two statements with the same result structure, you can use. UNION [ALL]
For example, the following statement lists both actors and directors:
Cypher
MATCH (actor:Person)-[r:ACTED_IN]->(movie:Movie) RETURN actor.name AS name, type(r) AS type, movie.title AS title UNION MATCH (director:Person)-[r:DIRECTED]->(movie:Movie) RETURN director.name AS name, type(r) AS type, movie.title AS title
Rows: 3 +-------------------------------------------------+ | name | type | title | +-------------------------------------------------+ | 'Tom Hanks' | 'ACTED_IN' | 'Cloud Atlas' | | 'Tom Hanks' | 'ACTED_IN' | 'Forrest Gump' | | 'Robert Zemeckis' | 'DIRECTED' | 'Forrest Gump' | +-------------------------------------------------+
Note that in all clauses, the returned columns must be named the same way.
The above query is equivalent to this more compact query:
Cypher
MATCH (actor:Person)-[r:ACTED_IN|DIRECTED]->(movie:Movie) RETURN actor.name AS name, type(r) AS type, movie.title AS title
3. WITH
In Cypher, statement fragments can be linked together, similar to what is done in a data flow pipeline. Each fragment processes the output of the previous fragment, and the result can be fed to the next fragment. Only the columns declared in the clause are available in subsequent query sections. WITH
This clause is used to combine parts and declare which data flows from one part to another. Similar to clause. The difference is that the clause does not complete the query, but prepares input for the next part. Expressions, aggregations, sorting, and pagination are used in the same way as in clauses. The only difference is that all columns must have aliases. WITH``WITH``RETURN``WITH``RETURN
In the following example, we collect movies in which someone plays, and then filter out movies that appear in only one movie:
Cypher
MATCH (person:Person)-[:ACTED_IN]->(m:Movie) WITH person, count(*) AS appearances, collect(m.title) AS movies WHERE appearances > 1 RETURN person.name, appearances, movies
Rows: 1 +-------------------------------------------------------------+ | person.name | appearances | movies | +-------------------------------------------------------------+ | 'Tom Hanks' | 2 | ['Cloud Atlas', 'Forrest Gump'] | +-------------------------------------------------------------+
define mode
1. Example diagram
First, create some data for our example:
Cypher
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (robert:Person:Director {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person:Actor {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (robert)-[:DIRECTED]->(forrestGump)
This is the result diagram:
2. Use index
The main reason for using index in graph database is to find the starting point of graph traversal. Once the starting point is found, the traversal depends on the structure in the graph to achieve high performance.
You can add indexes at any time.
If there is data in the database, it will take some time for the index to go online.
The following query creates an index to speed up finding actors by name in the database:
Cypher
CREATE INDEX example_index_1 FOR (a:Actor) ON (a.name)
In most cases, you do not need to specify an index when querying data, because the appropriate index will be used automatically.
You can use index hints to specify which index to use in a particular query. This is one of several options for query tuning Cypher manual → query tuning It is described in detail in.
For example, the following query will automatically use example_index_1:
Cypher
MATCH (actor:Actor {name: 'Tom Hanks'})
RETURN actor
A composite index is an index of multiple attributes of all nodes with a specific label. For example, the following statement will create a composite index on all nodes marked with Actor and with both aname and abort attributes. Note that the node with Actor tag name "Keanu Reeves" does not have this born attribute. Therefore, the node is not added to the index.
Cypher
CREATE INDEX example_index_2 FOR (a:Actor) ON (a.name, a.born)
You can query the database SHOW INDEXES to find out which indexes are defined.
Cypher
SHOW INDEXES YIELD name, labelsOrTypes, properties, type
Rows: 2 +----------------------------------------------------------------+ | name | labelsOrTypes | properties | type | +----------------------------------------------------------------+ | 'example_index_1' | ['Actor'] | ['name'] | 'BTREE' | | 'example_index_2' | ['Actor'] | ['name', 'born'] | 'BTREE' | +----------------------------------------------------------------+
stay Cypher Manual → Indexes Learn more about indexing.
3. Use constraints
Constraints are used to ensure that data conforms to the rules of the domain. For example:
If the label of a node is Actor and the attribute is name, the value name must be unique among all nodes with Actor label.
Example 1. Uniqueness constraint
This example shows how to create a constraint title for a node with a label Movie and attributes. The constraint specifies that the title property must be unique.
Adding a unique constraint implicitly adds the index of the property. If you remove the constraint but still need an index, you must explicitly create the index.
Cypher
CREATE CONSTRAINT constraint_example_1 FOR (movie:Movie) REQUIRE movie.title IS UNIQUE
The syntax in Neo4j 4.4 has changed. The old syntax is create constraint_ example_ 1 ON (movie:Movie) ASSERT movie.title IS UNIQUE Deprecated
You can add constraints to a database that already has data. This requires existing data to conform to the constraints being added.
You can query the database to find constraints defined using the SHOW CONSTRAINTSCypher syntax.
Example 2. Constraint query
This example shows a Cypher query that returns constraints that have been defined for the database.
Cypher
SHOW CONSTRAINTS YIELD id, name, type, entityType, labelsOrTypes, properties, ownedIndexId
Rows: 1 +-----------------------------------------------------------------------------------------------------+ | id | name | type | entityType | labelsOrTypes | properties | ownedIndexId | +-----------------------------------------------------------------------------------------------------+ | 4 | 'constraint_example_1' | 'UNIQUENESS' | 'NODE' | ['Movie'] | ['title'] | 3 | +-----------------------------------------------------------------------------------------------------+
The above constraints apply to all versions of neo4j. Neo4j enterprise has additional restrictions.
stay Cypher manual → in constraint Learn more about constraints.
Import data
This tutorial demonstrates how to import data LOAD CSV from a CSV file using a. CSV file.
Combining Cypher clauses load, CSV, merge, and CREATE, you can easily import data into Neo4j. LOAD CSV allows you to access and operate on data values.
For a complete description of LOAD CSV, see Cypher manual → LOAD CSV . For a complete list of Cypher clauses, see Cypher manual → clause.
1. Data file
In this tutorial, you will import data from the following CSV files:
- persons.csv
- movies.csv
- roles.csv
Contents of people.csv file:
persons.csv
Cypher
id,name 1,Charlie Sheen 2,Michael Douglas 3,Martin Sheen 4,Morgan Freeman
The persons.csv file contains two columns of id and name. Each line represents a person who has a unique id and a name.
Contents of movies.csv file:
movies.csv
Cypher
id,title,country,year 1,Wall Street,USA,1987 2,The American President,USA,1995 3,The Shawshank Redemption,USA,1994
The movies.csv file contains the columns id, title, country, and year. Each line represents a movie, which has a unique id, a title, a country origin, and a release year.
Contents of roles.csv file:
Role.csv
Cypher
personId,movieId,role 1,1,Bud Fox 4,1,Carl Fox 3,1,Gordon Gekko 4,2,A.J. MacInerney 3,2,President Andrew Shepherd 5,3,Ellis Boyd 'Red' Redding
The roles.csv file contains the columns personaid, movieId, and role. Each line represents a role id (from the persons.csv file) and a movie id (from the movies.csv file) of the relationship data with the person concerned.
2. Graph model
The following simple data model shows what the graphical model for this dataset might look like:
This is the result graph based on CSV file data:
3. Conditions precedent
This tutorial uses Linux or macOS tarball installation.
It assumes that your current working directory is the directory where tarball is installed, and the CSV file is placed in the default Import Directory.
For default directories for other installations, see Operation manual → file location . The import location can be accessed through Operation manual → dbms.directories.import Configure.
4. Prepare database
Before importing data, you should prepare the database to be used by creating indexes and constraints.
You should ensure that Person and Movie node IDs have unique attributes by creating constraints on them.
Creating a unique constraint also implicitly creates an index. Through the index id attribute, node lookup (for example, by MATCH) is much faster.
In addition, it is best to index the country name for quick lookup.
1. Start neo4j.
Shell
bin/neo4j start
The default user name is neo4j and password neo4j.
2. Create a constraint so that each Person node has a unique id attribute.
You create a constraint on the attributes of the Person node to ensure that the node with the Person tag will have a unique id attribute.
Using the Neo4j browser, run the following Cypher:
Cypher
CREATE CONSTRAINT personIdConstraint FOR (person:Person) REQUIRE person.id IS UNIQUE
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j "CREATE CONSTRAINT personIdConstraint FOR (person:Person) REQUIRE person.id IS UNIQUE"
3. Create a constraint so that each Movie node has a unique id attribute.
You create constraints on the attributes of the Movie node to ensure that nodes with Movie tags will have unique id attributes.
Using the Neo4j browser, run the following Cypher:
Cypher
CREATE CONSTRAINT movieIdConstraint FOR (movie:Movie) REQUIRE movie.id IS UNIQUE
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j "CREATE CONSTRAINT movieIdConstraint FOR (movie:Movie) REQUIRE movie.id IS UNIQUE"
4.Country creates a node index for the name attribute.
Create the index Country on the name attribute of the node to ensure fast lookup.
When using MERGE or MATCHwith to LOAD CSV, make sure that you have permission for the attributes you want to MERGE Indexes or Unique constraint . This ensures that queries are executed in a high-performance manner.
Using the Neo4j browser, run the following Cypher:
Cypher
CREATE INDEX FOR (c:Country) ON (c.name)
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j "CREATE INDEX FOR (c:Country) ON (c.name)"
5. LOAD CSV is used to import data
1. Load data from the * persons.csv * file.
You create a node id and name with a Person tag and attributes.
Using the Neo4j browser, run the following Cypher:
Cypher
LOAD CSV WITH HEADERS FROM "file:///persons.csv" AS csvLine
CREATE (p:Person {id: toInteger(csvLine.id), name: csvLine.name})
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j 'LOAD CSV WITH HEADERS FROM "file:///persons.csv" AS csvLine CREATE (p:Person {id:toInteger(csvLine.id), name:csvLine.name})'
Return
Added 4 nodes, Set 8 properties, Added 4 labels
LOAD CSV also supports accessing CSV files via HTTPS, HTTP, and FTP. See Password manual → LOAD CSV.
2. Load data from the * movies.csv * file.
You can use the Movie tag and the attributes id, title, and to create the node year.
You can also create nodes using the Country tag. Using MERGE avoids creating duplicate Country nodes when multiple movies have the same Country of origin.
The relationship ORIGIN with the type connects the Country node and the Movie node.
Using the Neo4j browser, run the following Cypher:
Cypher
LOAD CSV WITH HEADERS FROM "file:///movies.csv" AS csvLine
MERGE (country:Country {name: csvLine.country})
CREATE (movie:Movie {id: toInteger(csvLine.id), title: csvLine.title, year:toInteger(csvLine.year)})
CREATE (movie)-[:ORIGIN]->(country)
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j 'LOAD CSV WITH HEADERS FROM "file:///movies.csv" AS csvLine MERGE (country:Country {name:csvLine.country}) CREATE (movie:Movie {id:toInteger(csvLine.id), title:csvLine.title, year:toInteger(csvLine.year)}) CREATE (movie)-[:ORIGIN]->(country)'
Return
Added 4 nodes, Created 3 relationships, Set 10 properties, Added 4 labels
3. Load data from the * roles.csv * file
Importing data from the roles.csv file is to find the Person node and Movie node, and then create a relationship between them.
For large data files, it is to use LOAD CSV with the terms of USING PERIODIC COMMIT. This prompt tells Neo4j that the query may create too many transaction States, so it needs to be submitted regularly. For more information, see 4.4@cypher-manual:ROOT:query-tuning/using/index.adoc#query-using-periodic-commit-hint.
Using the Neo4j browser, run the following Cypher:
Cypher
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM "file:///roles.csv" AS csvLine
MATCH (person:Person {id: toInteger(csvLine.personId)}), (movie:Movie {id: toInteger(csvLine.movieId)})
CREATE (person)-[:ACTED_IN {role: csvLine.role}]->(movie)
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j 'USING PERIODIC COMMIT 500 LOAD CSV WITH HEADERS FROM "file:///roles.csv" AS csvLine MATCH (person:Person {id:toInteger(csvLine.personId)}), (movie:Movie {id:toInteger(csvLine.movieId)}) CREATE (person)-[:ACTED_IND {role:csvLine.role}]->(movie)'
Return
Created 5 relationships, Set 5 properties
6. Verify the imported data
Check the result dataset by finding all nodes with relationships.
Using the Neo4j browser, run the following Cypher:
Cypher
MATCH (n)-[r]->(m) RETURN n, r, m
Or use Neo4j Cypher Shell , run the command:
Shell
bin/cypher-shell --database=neo4j 'MATCH (n)-[r]->(m) RETURN n, r, m'
Return
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| n | r | m |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| (:Movie {id: 3, title: "The Shawshank Redemption", year: 1994}) | [:ORIGIN] | (:Country {name: "USA"}) |
| (:Movie {id: 2, title: "The American President", year: 1995}) | [:ORIGIN] | (:Country {name: "USA"}) |
| (:Movie {id: 1, title: "Wall Street", year: 1987}) | [:ORIGIN] | (:Country {name: "USA"}) |
| (:Person {name: "Morgan Freeman", id: 4}) | [:ACTED_IN {role: "Carl Fox"}] | (:Movie {id: 1, title: "Wall Street", year: 1987}) |
| (:Person {name: "Charlie Sheen", id: 1}) | [:ACTED_IN {role: "Bud Fox"}] | (:Movie {id: 1, title: "Wall Street", year: 1987}) |
| (:Person {name: "Martin Sheen", id: 3}) | [:ACTED_IN {role: "Gordon Gekko"}] | (:Movie {id: 1, title: "Wall Street", year: 1987}) |
| (:Person {name: "Martin Sheen", id: 3}) | [:ACTED_IN {role: "President Andrew Shepherd"}] | (:Movie {id: 2, title: "The American President", year: 1995}) |
| (:Person {name: "Morgan Freeman", id: 4}) | [:ACTED_IN {role: "A.J. MacInerney"}] | (:Movie {id: 2, title: "The American President", year: 1995}) |
+---------------------------------------------------------------------------------------------------------------