1, Spark overview
1.1 what is Spark
- Spark is a fast, universal and scalable big data analysis and calculation engine based on memory;
1.2 Spark && Hadoop
| SPark | Hadoop |
|---|---|
| 1.Scala development, fast, universal and extended big data analysis engine | 1. Java development, an open source framework for storing massive data on distributed server clusters and running distributed analysis applications |
| 2. Spark Core provides the most basic and core content of spark | 2. HDFS is based on GFS theory and stores data distributed |
| 3. Sparksql is a component used by Spark to operate structured data. Through Spark SQL, users have used SQL or HQL to query data | 3. MapReduce is based on Google MapReduce and distributed computing |
| 4. SparkStreaming is a component of the Spark platform that performs streaming computing for real-time data and provides rich API s for processing data streams | 5. Hbase is based on Bigtable and distributed database. It is good at real-time random reading and writing large-scale data sets |
- One time data calculation: when processing data, the framework will read data from the storage device, conduct logical operation, and then re store the processing results in the media.
1.3 Spark Or Hadoop
1.4 Spark core module
|Module | function|
|Spark core | spark core provides the most basic and core functions of spark. Other functional modules of spark are extended on the basis of spark core|
|Spark SQL||
2, Spark quick start
- Simple WordCount program
- Necessary environment:
- Install Scala plug-in in IDEA: Refer to this article
2.1 create Maven project
-
New project - > select the appropriate project JDK (JDK 1.8) - > next - > fill in the appropriate gav
-
Install the scala plug-in in settings - > plugins and Refer to this article
-
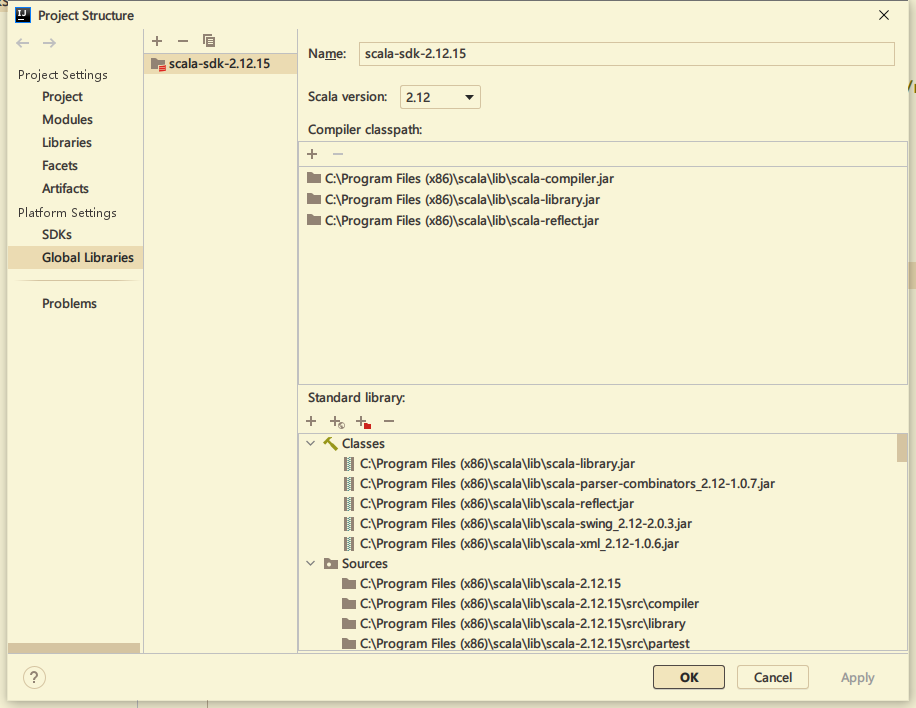
Add the sdk of scala in project structure - > Global libraries
-
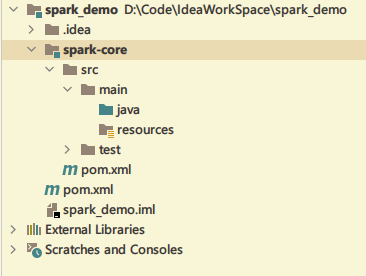
Create a new module in maven project to classify the project
-
Add Spark 3.0 dependency in pom file
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
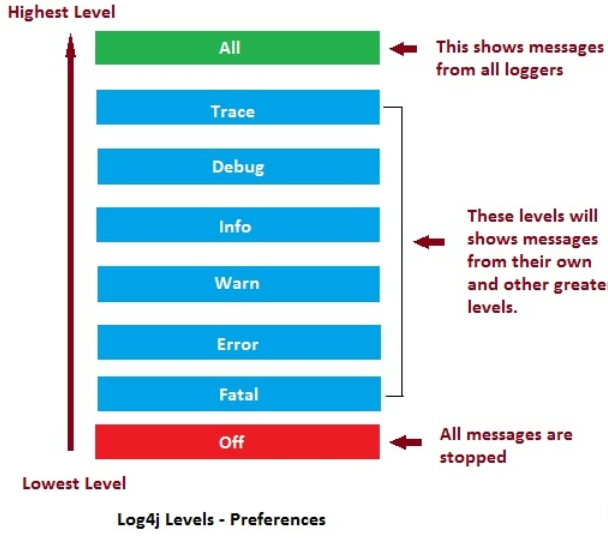
- Configure log4j to better track the program execution log, that is, create log4j in the resources directory of maven project Properties file and add the log configuration information as follows:
- Control log level Only ERROR is displayed
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd
HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,
the
# log level for this class is used to overwrite the root logger's log level, so
that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
2.2 Spark's WordCount
- Let's first write the wordcount process in Scala
If you are not familiar with Scala set functions, you can read the author's article: V -2. Full summary of common functions in scala set
object SparkWordCountDemo {
def main(args: Array[String]): Unit = {
/spark api operation
//2. Create the configuration object and set the necessary parameters
var conf = new SparkConf
conf.setMaster("local[*]") //Local mode
conf.setAppName("WordCountEasy")
//1. Create Spark context,
var sc: SparkContext = new SparkContext(conf)
//3. Operation
//3.1 reading file data
val line: RDD[String] = sc.textFile("spark_demo_data/input")
/3.2 Divide the data in each row into spaces, Then each word is stored separately
val words: RDD[String] = line.flatMap(x => x.split(" ")) /// ? What kind of data is generated
/3.3 Group words. remember, Group name as key, Each group of elements value
val groupedWords: RDD[(String, Iterable[String])] = words.groupBy(words => words)
3.4 Convert word group to (word, words aggregate) => (wrods, String An iterator of) => (words, words.size)
val resRDD: RDD[(String, Int)] = groupedWords.map(x => (x._1, x._2.size))
3.5 Collect the conversion results to the console
val res: Array[(String, Int)] = resRDD.collect()
println("=====")
println(res.mkString("Array(",",",")"))
//sc.groupBy
//4. Close the connection
sc.stop()
}
}
- Now that we are learning spark, we should try to use Spark's aggregation calculation method 'reduceByKey'
object WordCount {
def main(args: Array[String]): Unit = {
//2. Create the profile object of Spark and set some necessary configurations
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("StandardWordCount")
//1. Create Spark context,
//2.1 pass in the configuration object to the context object
val sc = new SparkContext(conf)
//3. Read each line of the file
val line: RDD[String] = sc.textFile("spark_demo_data/input")
//4. Format each line, word segmentation
val words: RDD[String] = line.flatMap(_.split(" "))
//5. Mark each word with 1, i.e. (word, 1)
val wordsWithOne: RDD[(String, Int)] = words.map(x => (x, 1))
//6. Statute
val resRDD: RDD[(String, Int)] = wordsWithOne.reduceByKey(_ + _)
//7. Get the result from memory and output it
val resArray: Array[(String, Int)] = resRDD.collect()
println(resArray.mkString("Array(",",",")") + "\n")
//8. Close resource connection
sc.stop()
}
}
- Following the above idea, we can also use the advanced functions of Scala set to implement wordcount
package cn.cyy.spark.core.wordcountdemo.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//2. Create the profile object of Spark and set some necessary configurations
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("StandardWordCount")
//1. Create Spark context,
//2.1 pass in the configuration object to the context object
val sc = new SparkContext(conf)
//3. Read each line of the file
val line: RDD[String] = sc.textFile("spark_demo_data/input")
//4. Format each line, word segmentation
val words: RDD[String] = line.flatMap(_.split(" "))
//5. Mark each word with 1, i.e. (word, 1)
val wordsWithOne: RDD[(String, Int)] = words.map(x => (x, 1))
//5.1 grouping
val groupedWordWithOne: RDD[(String, Iterable[(String, Int)])] = wordsWithOne.groupBy(tuple => tuple._1)
//5.2 reduce first, then map
val resRDD: RDD[(String, Int)] = groupedWordWithOne.map {
case (word, list) => {
list.reduce(
(x, y) => {
(x._1, x._2 + y._2)
}
)
}
}
// //6. Statute
// val resRDD: RDD[(String, Int)] = wordsWithOne.reduceByKey(_ + _)
//7. Get the result from memory and output it
val resArray: Array[(String, Int)] = resRDD.collect()
println(resArray.mkString("Array(",",",")"))
//8. Close resource connection
sc.stop()
}
}