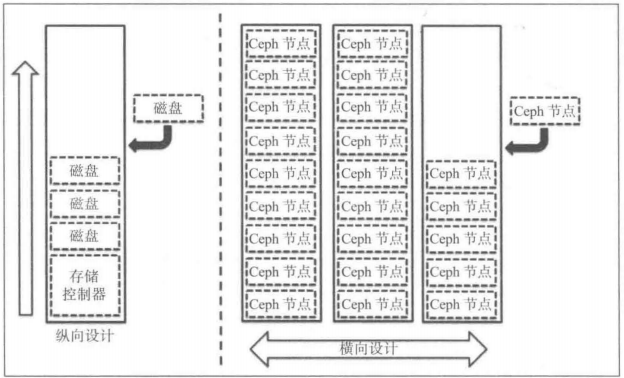
When the cluster capacity or computing resources reach a certain limit, the cluster needs to be expanded, which can be divided into two main operations:
1. Vertical expansion: adding disks to existing nodes will increase capacity and keep cluster computing performance unchanged;
2. Horizontal expansion: adding new nodes, including disk, memory and cpu resources, can improve the performance of expansion;
1. Avoid new nodes affecting performance and add identification bits in production environments
In production environments, data backfilling usually does not start immediately after new nodes join the ceph cluster, which can affect cluster performance.So we need to set some flags to accomplish this.
[root@node140 ~]##ceph osd set noin
[root@node140 ~]##ceph osd set nobackfill
When user access is off-peak, these flags are removed and the cluster begins to balance tasks.
[root@node140 ~]##ceph osd unset noin
[root@node140 ~]##ceph osd unset nobackfill
2. Install ceph on new node
(1)#Manual yum cluster deployment
[root@node143 ~]# yum -y install ceph ceph-radosgw
(2)#Check installed packages
[root@node143 ~]# rpm -qa | egrep -i "ceph|rados|rbd"
(3) #Check that ceph installs this version, requiring a unified version
[root@node143 ~]# ceph-v are all (nautilus version)
ceph version 14.2.2 (4f8fa0a0024755aae7d95567c63f11d6862d55be) nautilus (stable)
3. Adding Nodes to the ceph Cluster
ceph can be seamlessly extended to support adding osd and monitor nodes Online
(1) Health Clusters
[root@node140 ~]# ceph -s
cluster:
id: 58a12719-a5ed-4f95-b312-6efd6e34e558
health: HEALTH_OK
services:
mon: 2 daemons, quorum node140,node142 (age 8d)
mgr: admin(active, since 8d), standbys: node140
mds: cephfs:1 {0=node140=up:active} 1 up:standby
osd: 16 osds: 16 up (since 5m), 16 in (since 2w)
data:
pools: 5 pools, 768 pgs
objects: 2.65k objects, 9.9 GiB
usage: 47 GiB used, 8.7 TiB / 8.7 TiB avail
pgs: 768 active+clean(2) Current number of cluster nodes is 3
[root@node140 ~]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 8.71826 root default -2 3.26935 host node140 0 hdd 0.54489 osd.0 up 1.00000 1.00000 1 hdd 0.54489 osd.1 up 1.00000 1.00000 2 hdd 0.54489 osd.2 up 1.00000 1.00000 3 hdd 0.54489 osd.3 up 1.00000 1.00000 4 hdd 0.54489 osd.4 up 1.00000 1.00000 5 hdd 0.54489 osd.5 up 1.00000 1.00000 -3 3.26935 host node141 12 hdd 0.54489 osd.12 up 1.00000 1.00000 13 hdd 0.54489 osd.13 up 1.00000 1.00000 14 hdd 0.54489 osd.14 up 1.00000 1.00000 15 hdd 0.54489 osd.15 up 1.00000 1.00000 16 hdd 0.54489 osd.16 up 1.00000 1.00000 17 hdd 0.54489 osd.17 up 1.00000 1.00000 -4 2.17957 host node142 6 hdd 0.54489 osd.6 up 1.00000 1.00000 9 hdd 0.54489 osd.9 up 1.00000 1.00000 10 hdd 0.54489 osd.10 up 1.00000 1.00000 11 hdd 0.54489 osd.11 up 1.00000 1.00000
(3) Cluster nodes copy configuration files and keys to the new node node143
[root@node143 ceph]# ls ceph.client.admin.keyring ceph.conf
(4) New nodes have access to the cluster
[root@node143 ceph]# ceph -s
cluster:
id: 58a12719-a5ed-4f95-b312-6efd6e34e558
health: HEALTH_OK
services:
mon: 2 daemons, quorum node140,node142 (age 8d)
mgr: admin(active, since 8d), standbys: node140
mds: cephfs:1 {0=node140=up:active} 1 up:standby
osd: 16 osds: 16 up (since 25m), 16 in (since 2w)
data:
pools: 5 pools, 768 pgs
objects: 2.65k objects, 9.9 GiB
usage: 47 GiB used, 8.7 TiB / 8.7 TiB avail
pgs: 768 active+clean(5) Prepare disks
[root@node143 ceph]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 557.9G 0 disk ├─sda1 8:1 0 200M 0 part /boot └─sda2 8:2 0 519.4G 0 part └─centos-root 253:0 0 519.4G 0 lvm / sdb 8:16 0 558.9G 0 disk sdc 8:32 0 558.9G 0 disk sdd 8:48 0 558.9G 0 disk sde 8:64 0 558.9G 0 disk sdf 8:80 0 558.9G 0 disk sdg 8:96 0 558.9G 0 disk
(6)#Mark as osd disk in GPT format
[root@node143 ]# parted /dev/sdc mklabel GPT [root@node143 ]# parted /dev/sdd mklabel GPT [root@node143 ]# parted /dev/sdf mklabel GPT [root@node143 ]#parted /dev/sdg mklabel GPT [root@node143 ]# parted /dev/sdb mklabel GPT [root@node143 ]# parted /dev/sde mklabel GPT
(7) #Format as xfs file system
[root@node143 ]# mkfs.xfs -f /dev/sdc [root@node143 ]# mkfs.xfs -f /dev/sdd [root@node143 ]# mkfs.xfs -f /dev/sdb [root@node143 ]# mkfs.xfs -f /dev/sdf [root@node143 ]# mkfs.xfs -f /dev/sdg [root@node143 ]# mkfs.xfs -f /dev/sde
(8) Create osd
[root@node143 ~]# ceph-volume lvm create --data /dev/sdb --> ceph-volume lvm activate successful for osd ID: 0 --> ceph-volume lvm create successful for: /dev/sdb [root@node143 ~]# ceph-volume lvm create --data /dev/sdc [root@node143 ~]# ceph-volume lvm create --data /dev/sdd [root@node143 ~]# ceph-volume lvm create --data /dev/sdf [root@node143 ~]# ceph-volume lvm create --data /dev/sdg [root@node143 ~]# ceph-volume lvm create --data /dev/sde
[root@node143 ~]# blkid /dev/mapper/centos-root: UUID="7616a088-d812-456b-8ae8-38d600eb9f8b" TYPE="xfs" /dev/sda2: UUID="6V8bFT-ylA6-bifK-gmob-ah3I-zZ4G-N7EYwD" TYPE="LVM2_member" /dev/sda1: UUID="eee4c9af-9f12-44d9-a386-535bde734678" TYPE="xfs" /dev/sdb: UUID="TcjeCg-YsBQ-RHbm-UNYT-UoQv-iLFs-f1st2X" TYPE="LVM2_member" /dev/sdd: UUID="aSLPmt-ohdJ-kG7W-JOB1-dzOD-D0zp-krWW5m" TYPE="LVM2_member" /dev/sdc: UUID="7ARhbT-S9sC-OdZw-kUCq-yp97-gSpY-hfoPFa" TYPE="LVM2_member" /dev/sdg: UUID="9MDhh1-bXIX-DwVf-RkIt-IUVm-fPEH-KSbsDd" TYPE="LVM2_member" /dev/sde: UUID="oc2gSZ-j3WO-pOUs-qJk6-ZZS0-R8V7-1vYaZv" TYPE="LVM2_member" /dev/sdf: UUID="jxQjNS-8xpV-Hc4p-d2Vd-1Q8O-U5Yp-j1Dn22" TYPE="LVM2_member"
(9)#View Create osd
[root@node143 ~]# ceph-volume lvm list
[root@node143 ~]# lsblk
(10)#OSD will start automatically
[root@node143 ~]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 11.98761 root default -2 3.26935 host node140 0 hdd 0.54489 osd.0 up 1.00000 1.00000 1 hdd 0.54489 osd.1 up 1.00000 1.00000 2 hdd 0.54489 osd.2 up 1.00000 1.00000 3 hdd 0.54489 osd.3 up 1.00000 1.00000 4 hdd 0.54489 osd.4 up 1.00000 1.00000 5 hdd 0.54489 osd.5 up 1.00000 1.00000 -3 3.26935 host node141 12 hdd 0.54489 osd.12 up 1.00000 1.00000 13 hdd 0.54489 osd.13 up 1.00000 1.00000 14 hdd 0.54489 osd.14 up 1.00000 1.00000 15 hdd 0.54489 osd.15 up 1.00000 1.00000 16 hdd 0.54489 osd.16 up 1.00000 1.00000 17 hdd 0.54489 osd.17 up 1.00000 1.00000 -4 2.17957 host node142 6 hdd 0.54489 osd.6 up 1.00000 1.00000 9 hdd 0.54489 osd.9 up 1.00000 1.00000 10 hdd 0.54489 osd.10 up 1.00000 1.00000 11 hdd 0.54489 osd.11 up 1.00000 1.00000 -9 3.26935 host node143 7 hdd 0.54489 osd.7 up 1.00000 1.00000 8 hdd 0.54489 osd.8 up 1.00000 1.00000 18 hdd 0.54489 osd.18 up 0 1.00000 19 hdd 0.54489 osd.19 up 0 1.00000 20 hdd 0.54489 osd.20 up 0 1.00000 21 hdd 0.54489 osd.21 up 0 1.00000
====== osd.0 =======
Displays osd.num, which is used later.
[root@node143 ~]# systemctl enable ceph-osd@7 [root@node143 ~]# systemctl enable ceph-osd@8 [root@node143 ~]# systemctl enable ceph-osd@18 [root@node143 ~]# systemctl enable ceph-osd@19 [root@node143 ~]# systemctl enable ceph-osd@20 [root@node143 ~]# systemctl enable ceph-osd@21
(11) View clusters and expand successfully
[root@node143 ~]# ceph -s
cluster:
id: 58a12719-a5ed-4f95-b312-6efd6e34e558
health: HEALTH_WARN
noin,nobackfill flag(s) set
services:
mon: 2 daemons, quorum node140,node142 (age 8d)
mgr: admin(active, since 8d), standbys: node140
mds: cephfs:1 {0=node140=up:active} 1 up:standby
osd: 22 osds: 22 up (since 4m), 18 in (since 9m); 2 remapped pgs
flags noin,nobackfill
data:
pools: 5 pools, 768 pgs
objects: 2.65k objects, 9.9 GiB
usage: 54 GiB used, 12 TiB / 12 TiB avail
pgs: 766 active+clean
1 active+remapped+backfilling
1 active+remapped+backfill_wait(12) Remember to cancel the mark during rush hour
When user access is off-peak, these flags are removed and the cluster begins to balance tasks.
[root@node140 ~]##ceph osd unset noin
[root@node140 ~]##ceph osd unset nobackfill