Tip: This is just a note
1, Introduction of linked list
1.1 first, let's talk about the defects of arrays: array elements must be consistent; Once the number of array elements is specified, it cannot be changed.
The 1.2 structure solves the first defect of the array, and the linked list solves the second defect of the array.
1.3 always remember that the linked list is used to solve the problem that the size of the array cannot be expanded.
2, Implementation of single linked list
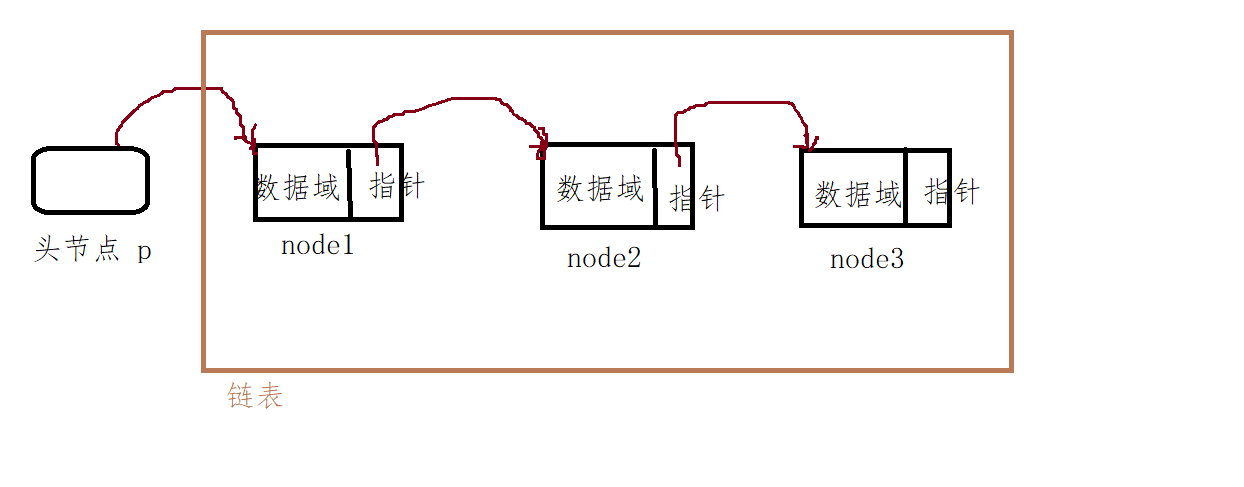
2.1 node composition of single linked list: valid data + pointer
The struct node defined in 2.2 is just a structure, which has no variable generation and does not occupy memory. The definition of structure is equivalent to defining a template for the nodes of the linked list, but there is no node yet. When a node is needed to create the linked list in the future, you can use this template to copy one.
2.3 Application and use of heap memory
(1) The memory requirements of the linked list are relatively flexible. You can't use stacks or data segments (for storing global variables). Only heap memory can be used.
(2) Steps to create a linked list node using heap memory: first, apply for heap memory with a size of one node (including checking whether the application result is correct); Second, clean up the heap memory applied for; Third, treat the heap memory as a new node; Fourth, fill in the valid data and pointer area of the new node.
2.4 head pointer of linked list
(1) The header pointer is not a node, but an ordinary pointer, accounting for only 4 bytes. The type of header pointer is struct node *, so it can point to the node of the linked list.
(2) A typical implementation of a linked list is: the head pointer points to the first node of the linked list, the pointer in the first node points to the second node, and the pointer of the second node points to the third node, so push all the time. A linked list is formed.
Single linked list implementation code:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
/* Function to create a linked list node
Return value: pointer of structure type,
Point to the first address of the node newly created by this function.
*/
struct node *cread_node(int Data)
{
// Create a structure pointer p,
// p refers to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node,
//In actual operation, assign the pointer returned by the next node malloc to pNext.
return p;
}
int main(void)
{
// Define header pointer
struct node *pHeader = NULL;
// Create the first node and bind it to the head node
pHeader = cread_node(1);
// cread_ The return value (pointer p) of the node function is the first address of a node
// Create a second node
pHeader -> pNext = cread_node(2);
// Create 3rd node
pHeader ->pNext -> pNext = cread_node(3);
// Access the node and take out the data of the node data field
printf("node 1 data = %d\n",pHeader -> data );
printf("node 2 data = %d\n",pHeader ->pNext -> data );
printf("node 3 data = %d\n",pHeader -> pNext ->pNext -> data );
return 0;
}
result:
node 1 data = 1
node 2 data = 2
node 3 data = 3
Note:
(1) Because it is a linked list, you should start from the pointer (pHeader) when filling data and accessing nodes.
(2) The key point of encapsulating and creating a new node function lies in the interface design of the function (the design of function parameters and return values).
3, Insertion of single linked list
3.1 tail insertion of single linked list
// Header pointer - > first node - > second node - > third node The way.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
// Function to create a linked list node
// Return value: pointer of structure type, pointing to the first address of the node newly created by this function.
struct node *cread_node(int Data)
{
// Create a structure pointer p, which points to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node. In actual operation, assign the pointer returned by malloc of the next node to pNext.
return p;
}
// Tail insertion function
void insert_tail(struct node *pH,struct node *new)
{
// Two step tail insertion
// The first step is to find the last node of the linked list
struct node *p = pH;
while (NULL != p->pNext)
{
p = p->pNext; // Go back one node
}
// The second step is to insert the new node into the tail of the last node
p->pNext = new;
}
int main(void)
{
// Define header pointer
struct node *pHeader = cread_node(1);// The pHeader is bound to the first node
insert_tail(pHeader,cread_node(23)); // Insert the second node into the tail of the first node
insert_tail(pHeader,cread_node(356));// Insert the third node into the tail of the second node
insert_tail(pHeader,cread_node(467));// Insert the 4th node into the tail of the 3rd node
// Access the node and take out the data of the node data field
printf("node 1 data = %d\n",pHeader -> data );
printf("node 2 data = %d\n",pHeader ->pNext -> data );
printf("node 3 data = %d\n",pHeader -> pNext ->pNext -> data );
printf("node 4 data = %d\n",pHeader->pNext->pNext->pNext->data );
return 0;
}
result:
node 1 data = 1
node 2 data = 23
node 3 data = 356
node 4 data = 467
Another use of linked list is to point the head pointer to the first node as the head node.
The characteristics of the head node are: first, immediately following the head pointer; Second, the data of the head node is empty (sometimes the number of nodes of the whole linked list stored), and the pointer part points to the next node, that is, the first node.
In this way, the head node is really different from other nodes. Therefore, we have different methods to add nodes when creating a linked list. The header node is created together with the header pointer and associated with the header pointer; After that, the node where the pointer stores data is added with the node addition function (intsert_tail).
// Header pointer - > header node - > first node - > second node The way.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
// Function to create a linked list node
// Return value: pointer of structure type, pointing to the first address of the node newly created by this function.
struct node *cread_node(int Data)
{
// Create a structure pointer p, which points to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node. In actual operation, assign the pointer returned by malloc of the next node to pNext.
return p;
}
// Tail insertion function
// And calculate the total number of nodes after adding new nodes, and write the total number of nodes into the head node.
/* Idea: traverse the header pointer until you reach the original last node.
It turns out that pNext in the last node is NULL,
Now we just need to change it to new. After adding, the new node becomes the last one.
*/
void insert_tail(struct node *pH,struct node *new)
{
int node_sum_num = 0;
// Two step tail insertion
// The first step is to find the last node of the linked list
struct node *p = pH;
while (NULL != p->pNext)
{
p = p->pNext; // Go back one node
node_sum_num ++;
}
// The second step is to insert the new node into the tail of the last node
p->pNext = new;
pH -> data = node_sum_num + 1; // This 1 represents the header node
}
int main(void)
{
// Define header pointer and bind header node
struct node *pHeader = cread_node(-1);
insert_tail(pHeader,cread_node(1)); // Insert the first node into the tail of the head node
insert_tail(pHeader,cread_node(356));// Insert the second node into the tail of the first node
insert_tail(pHeader,cread_node(467));// Insert the third node into the tail of the second node
// Access the node and take out the data of the node data field
printf("head node data is = %d\n",pHeader -> data );
printf("node 1 data is = %d\n",pHeader ->pNext -> data );
printf("node 2 data is = %d\n",pHeader -> pNext ->pNext -> data );
printf("node 3 data is = %d\n",pHeader->pNext->pNext->pNext->data );
return 0;
}
Note: the head node of the linked list is different, which is reflected in the different algorithms of inserting, deleting, traversing and parsing the linked list. If there is a header node, the subsequent processing is handled according to the situation of a header node. In reality, there are both cases, so you need to pay attention to whether there is a header node when looking at other people's linked list code.
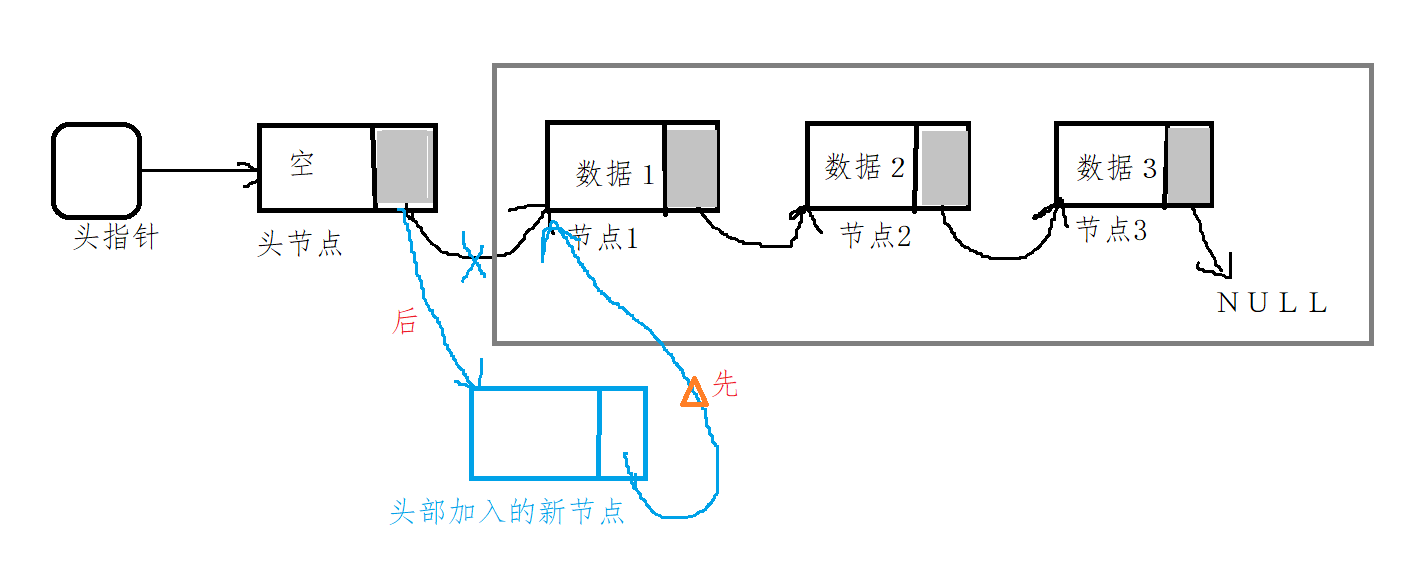
3.2 insert a new node from the head of the linked list (headed node)
[writing method of header node]
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
// Function to create a linked list node
// Return value: pointer of structure type, pointing to the first address of the node newly created by this function.
struct node *cread_node(int Data)
{
// Create a structure pointer p, which points to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node. In actual operation, assign the pointer returned by malloc of the next node to pNext.
return p;
}
/*
// Tail insertion function
// And calculate the total number of nodes after adding new nodes, and write the total number of nodes into the head node.
void insert_tail(struct node *pH,struct node *new)
{
int node_sum_num = 0;
// Two step tail insertion
// The first step is to find the last node of the linked list
struct node *p = pH;
while (NULL != p->pNext)
{
p = p->pNext; // Go back one node
node_sum_num ++;
}
// The second step is to insert the new node into the tail of the last node
p->pNext = new;
pH -> data = node_sum_num + 1; // This 1 represents the header node
}
*/
// Insert a new node from the head of the linked list
/*
Idea:
If according to:
Point the pNext of the head node to the first address of the new node, and point the pNext of the new node to the first address of the original first node.
Think like this, there will be a consequence: after the head node points to the address of the new node, the address of the original first node is lost.
Therefore, the address of the original first node should be bound to the pNext of the new node to be added first,
In case the original address of the first node is lost.
*/
void insert_head(struct node *pH,struct node *new)
{
// First: the pNext of the new node points to the original first node
new -> pNext = pH -> pNext;
// Second: the pNext of the head node points to the address of the new node
pH -> pNext = new;
// Add one to the data in the header node.
pH -> data += 1;
}
int main(void)
{
// Define header pointer and bind header node
struct node *pHeader = cread_node(0); //The header pointer is bound to the header node
/*
insert_tail(pHeader,cread_node(1)); // Insert the first node into the tail of the head node
insert_tail(pHeader,cread_node(356));// Insert the second node into the tail of the first node
insert_tail(pHeader,cread_node(467));// Insert the third node into the tail of the second node
*/
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(22));
insert_head(pHeader,cread_node(333));
// Access the node and take out the data of the node data field
printf("head node data is = %d\n",pHeader -> data );
printf("node 1 data is = %d\n",pHeader ->pNext -> data );
printf("node 2 data is = %d\n",pHeader -> pNext ->pNext -> data );
printf("node 3 data is = %d\n",pHeader->pNext->pNext->pNext->data );
return 0;
}
result:
head node data is = 3
node 1 data is = 333
node 2 data is = 22
node 3 data is = 1
If you want to insert both the head and the tail, you only need to release the comments inserted in the tail and call them in the main function.
3.3 traversal node of single linked list algorithm
(1) What is traversal
Traversal is to take out each node in the single linked list one by one.
traverse (struct node *pH);
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
// Function to create a linked list node
// Return value: pointer of structure type, pointing to the first address of the node newly created by this function.
struct node *cread_node(int Data)
{
// Create a structure pointer p, which points to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node. In actual operation, assign the pointer returned by malloc of the next node to pNext.
return p;
}
// Insert a new node from the head of the linked list
void insert_head(struct node *pH,struct node *new)
{
// First: the pNext of the new node points to the original first node
new -> pNext = pH -> pNext;
// Second: the pNext of the head node points to the address of the new node
pH -> pNext = new;
// Add one to the data in the header node.
pH -> data += 1;
}
// The function of traversing the single linked list, pH is the head pointer
void traverse(struct node *pH)
{
// PH - > data: the data of the header node is not the regular data of the linked list. Do not count it in
struct node *p = pH;// After the header pointer is the header node,
printf("--------------------kaishi--------------------------------\n");
while(NULL != p->pNext) // Is it the last node
{
p = p->pNext;// p starts to point to the head node. After this statement, p jumps over the head node to the first node
printf("node dara is %d\n",p -> data);
}
printf("--------------------kaishi--------------------------------\n");
}
int main(void)
{
// Define header pointer and bind header node
struct node *pHeader = cread_node(0); //The header pointer is bound to the header node
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(22));
insert_head(pHeader,cread_node(333));
traverse(pHeader);
return 0;
}
result:
--------------------kaishi--------------------------------
node dara is 333
node dara is 22
node dara is 1
--------------------kaishi--------------------------------
3.4 deleting nodes of single linked list algorithm
There are 2 steps to delete a node:
The first step is to find the node to be deleted; Step 2: delete this node.
Find the node to be deleted:
Find nodes by traversal. Start from the pointer + head node, take out each node in turn along the linked list, compare it according to a certain method, and find the node we want to delete.
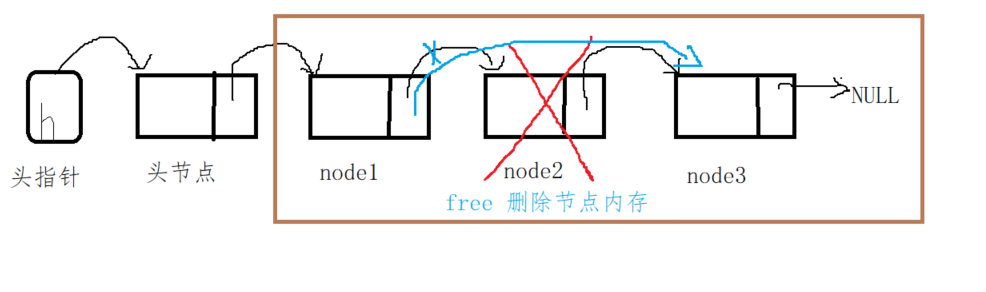
Case 1: the node to be deleted is not the tail node
First, point the pNext pointer of the previous node of the node to be deleted to the first address of the next node of the node to be deleted. Then free the memory space of the deleted node.
Case 2: the node to be deleted is the tail node:
First, point the pNext pointer of the previous node of the tail node to be deleted to NULL. The previous node equivalent to the original tail node becomes a new tail node. Finally, free the memory space of the deleted node.
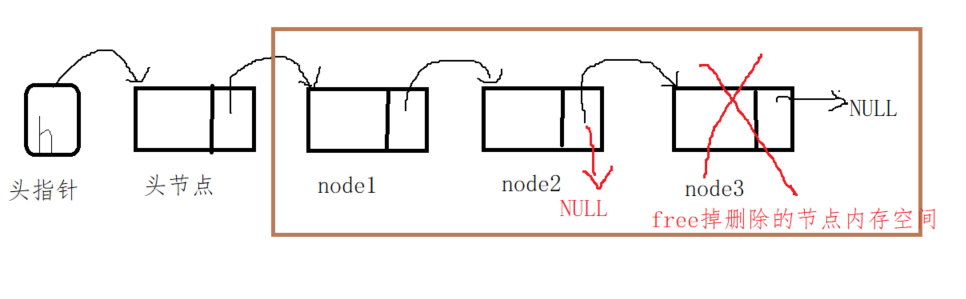
Tip: pay attention to the release of heap memory
(1) None of the above code frees heap memory. When the program is finished, the heap memory without free is also released.
(2) Sometimes the program runs for a long time. At this time, malloc's memory will be occupied until free or the whole program terminates. Therefore, the above codes should be in the return 0 of the main function; Free dropped the linked list before, but because the above example code is very simple, it won't have a great impact even without free. Considering good programming habits, you need free.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
// Function to create a linked list node
// Return value: pointer of structure type, pointing to the first address of the node newly created by this function.
struct node *cread_node(int Data)
{
// Create a structure pointer p, which points to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node,
//In actual operation, assign the pointer returned by the next node malloc to pNext.
return p;
}
// Insert a new node from the head of the linked list
void insert_head(struct node *pH,struct node *new)
{
// First: the pNext of the new node points to the original first node
new -> pNext = pH -> pNext;
// Second: the pNext of the head node points to the address of the new node
pH -> pNext = new;
// Add one to the data in the header node.
pH -> data += 1;
}
// The function of traversing the single linked list, pH is the head pointer
void traverse(struct node *pH)
{
// PH - > data: the data of the header node is not the regular data of the linked list. Do not count it in
struct node *p = pH;// After the header pointer is the header node,
while(NULL != p->pNext) // Is it the last node
{
p = p->pNext;
// p starts to point to the head node. After this statement, p jumps to the first node
printf("node dara is %d\n",p -> data);
}
}
// Delete node function: delete the node whose Data field is Data in the linked list
int delete_node(struct node *pH,int Data)
{
// First, traverse the linked list to find the node to be deleted
struct node *p = pH; // This p is used to point to the current node
struct node *pBefore = pH;
// pBefore is used to point to the previous node of the current node
while(NULL != p->pNext) // Is it the last node
{
pBefore = p;
//Before moving p to the next node, save P in pBefore, so that pBefore is one node slower than P.
p = p->pNext;
// p starts to point to the head node. After this statement, p jumps to the first node,
// This statement is to move p to the next node
// Judge whether this node is a node to be deleted
if(p->data == Data)
{
// Found the node to be deleted, delete this node
// This node is divided into two cases: normal node and tail node
/* The difficulty of deleting nodes is to access each node in turn through the traversal of the linked list. After finding this node, p points to this node
However, to delete this node, you must operate the previous node, but at this time, there is no pointer to the previous node, so there is no way to operate.
The solution is to define a pointer to the previous node.
*/
if(NULL == p->pNext)//Indicates the tail node
{
pBefore -> pNext = NULL;
free(p); // Release the original tail node
}
else // Indicates a normal node
{
pBefore ->pNext = p -> pNext;
free(p);
}
// Push out loop after deleting node
printf("delete success!\n");
return 0;
}
}
printf("do not fond this node !\n");
return -1;
}
int main(void)
{
// Define header pointer and bind header node
struct node *pHeader = cread_node(0); //The header pointer is bound to the header node
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(22));
insert_head(pHeader,cread_node(333));
insert_head(pHeader,cread_node(4444));
insert_head(pHeader,cread_node(1233));
printf("delete before :\n");
traverse(pHeader);
delete_node(pHeader,22);
printf("delete after :\n");
traverse(pHeader);
return 0;
}
result:
delete before :
node dara is 1233
node dara is 4444
node dara is 333
node dara is 22
node dara is 1
delete success!
delete after :
node dara is 1233
node dara is 4444
node dara is 333
node dara is 1
Table 5 algorithm of reverse chain
(1) Reverse order: the order of valid nodes (excluding head nodes) in the linked list is reversed.
(2) Idea: first traverse the original linked list, take the head pointer and head node of the original linked list as the head pointer and head node of the new linked list, then take out the effective nodes in the original linked list in turn, and insert the head insertion method into the new linked list.
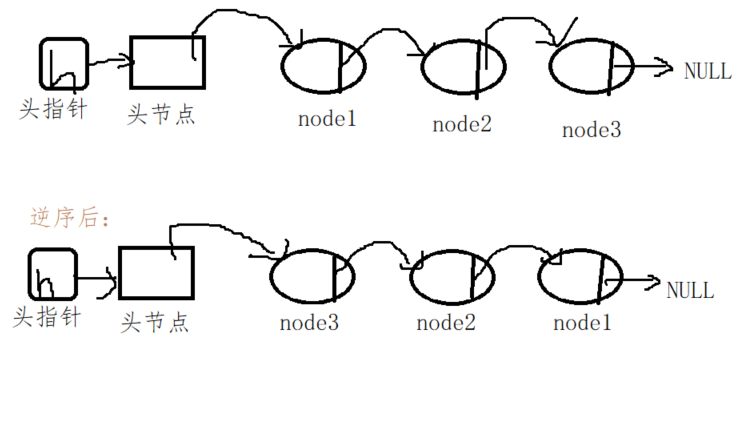
(3) Reverse order of linked list: traversal + header insertion
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Build a linked list node and package the structure
struct node
{
int data; //Valid data
struct node *pNext; // Pointer to the next node
};
// Function to create a linked list node
// Return value: pointer of structure type, pointing to the first address of the node newly created by this function.
struct node *cread_node(int Data)
{
// Create a structure pointer p, which points to the first address of the new node applied by malloc
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
// Clean up the heap memory requested
memset(p,0,sizeof(struct node));
// Fill node
p->data = Data;
p->pNext = NULL;
//pNext should point to the first address of the next node. In actual operation, assign the pointer returned by malloc of the next node to pNext.
return p;
}
// Insert a new node from the head of the linked list
void insert_head(struct node *pH,struct node *new)
{
// First: the pNext of the new node points to the original first node
new -> pNext = pH -> pNext;
// Second: the pNext of the head node points to the address of the new node
pH -> pNext = new;
// Add one to the data in the header node.
pH -> data += 1;
}
// The function of traversing the single linked list, pH is the head pointer
void traverse(struct node *pH)
{
// PH - > data: the data of the header node is not the regular data of the linked list. Do not count it in
struct node *p = pH;// After the header pointer is the header node,
while(NULL != p->pNext) // Is it the last node
{
p = p->pNext;// p starts to point to the head node. After this statement, p jumps to the first node
printf("node dara is %d\n",p -> data);
}
}
// Delete node function: delete the node whose Data field is Data in the linked list
int delete_node(struct node *pH,int Data)
{
// First, traverse the linked list to find the node to be deleted
struct node *p = pH; // This p is used to point to the current node
struct node *pBefore = pH; // pBefore is used to point to the previous node of the current node
while(NULL != p->pNext) // Is it the last node
{
pBefore = p;
//Before moving p to the next node, save P in pBefore, so that pBefore is one node slower than P.
p = p->pNext;
// p starts to point to the head node. After this statement, p jumps to the first node,
// This statement is to move p to the next node
// Judge whether this node is a node to be deleted
if(p->data == Data)
{
// Found the node to be deleted, delete this node
// This node is divided into two cases: normal node and tail node
/* The difficulty of deleting nodes is to access each node in turn through the traversal of the linked list. After finding this node, p points to this node
However, to delete this node, you must operate the previous node, but at this time, there is no pointer to the previous node, so there is no way to operate.
The solution is to define a pointer to the previous node.
*/
if(NULL == p->pNext)//Indicates the tail node
{
pBefore -> pNext = NULL;
free(p); // Release the original tail node
}
else // Indicates a normal node
{
pBefore ->pNext = p -> pNext;
free(p);
}
// Push out loop after deleting node
printf("delete success!\n");
return 0;
}
}
printf("do not fond this node !\n");
return -1;
}
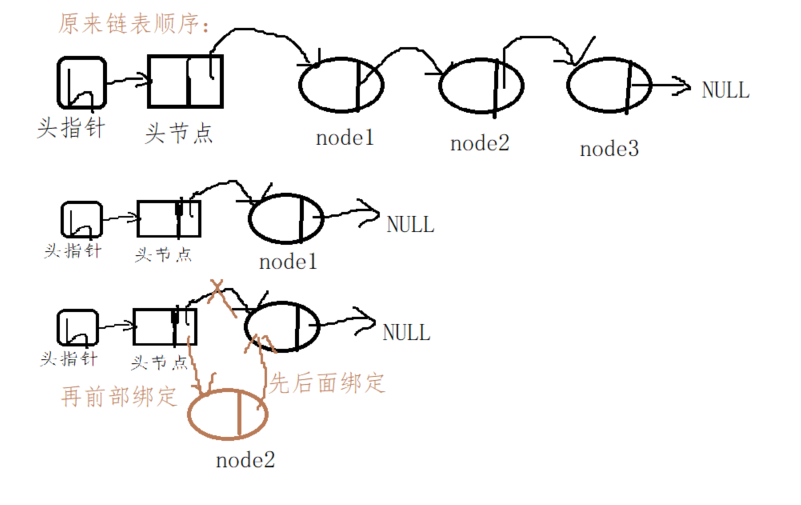
// Linked list reverse order function
void reverse_linklist(struct node *pH)
{
struct node *p =pH -> pNext;
// pH points to the head node and p points to the first effective node
struct node *pBack = NULL;//Save p points to the next node after the node
if((NULL == pH->pNext) || (NULL == p->pNext))
// If there is no valid node and there is only one valid node, the reverse order of the linked list is meaningless
{
return ;
}
// When there are 2 or more valid nodes in the linked list, reverse order is required
//The first step is to traverse.
while(NULL != p->pNext)
{
pBack = p->pNext; //Before processing the first valid node, save the address of the next valid node to avoid loss.
//If the conditions are met, it indicates that there is a second (or nth) valid node,
// The first valid node of the original linked list will be the tail node of the new linked list in reverse order,
// The pNext of the tail node points to NULL
if(p == pH->pNext)
// Judge that if p points to the first valid node, point the pNext of the first valid node to NULL
{
p->pNext = NULL; // Establish the tail node of the linked list after reverse order
}
else
{
p->pNext = pH->pNext;
pH->pNext = p; // These two sentences need to be understood in combination with the picture drawn above
}
p = pBack; // This leads to the next node
}
// At the end of the loop, the last node disappears. You can insert the last node with header insertion.
insert_head(pH,p);
}
int main(void)
{
// Define header pointer and bind header node
struct node *pHeader = cread_node(0); //The header pointer is bound to the header node
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(22));
insert_head(pHeader,cread_node(333));
insert_head(pHeader,cread_node(4444));
insert_head(pHeader,cread_node(1233));
printf("-------------reverse before :-------------\n");
traverse(pHeader);
printf(":-------------reverse after :-------------\n");
reverse_linklist(pHeader);
traverse(pHeader);
return 0;
}
result:
-------------reverse before :-------------
node dara is 1233
node dara is 4444
node dara is 333
node dara is 22
node dara is 1
:-------------reverse after :-------------
node dara is 1
node dara is 22
node dara is 333
node dara is 4444
node dara is 1233
4, Double linked list
4.1 introduction and basic implementation of double linked list
(1) Limitations of single linked list:
Single linked list is an extension of heap array. Each node of single linked list is connected by only one pointer in one direction, which has some limitations. The limitation is that the single linked list can only move in one direction through the pointer (once the pointer moves over a node, it can't come back. If you need to operate the node again, you can't traverse it again from the beginning). Therefore, some operations of the single linked list are more troublesome. For example, the previous single linked list insertion, deletion, traversal and other operations cause a lot of trouble because of the one-way movement of the single linked list.
(2) Valid data + node with 2 pointers (double linked list): one pointer points to the next node and one pointer points to the previous node.
4.1 insertion node of double linked list
Head insertion and tail insertion
(1) Head insertion
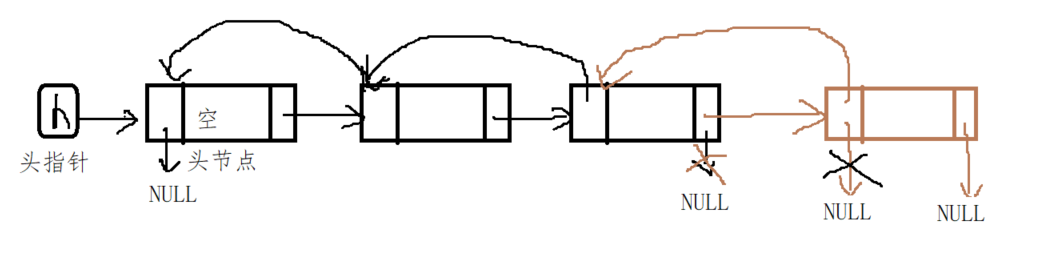
The first step is to go to the tail node of the linked list; The second step is to insert the new node behind the original tail node.
(2) Tail insertion
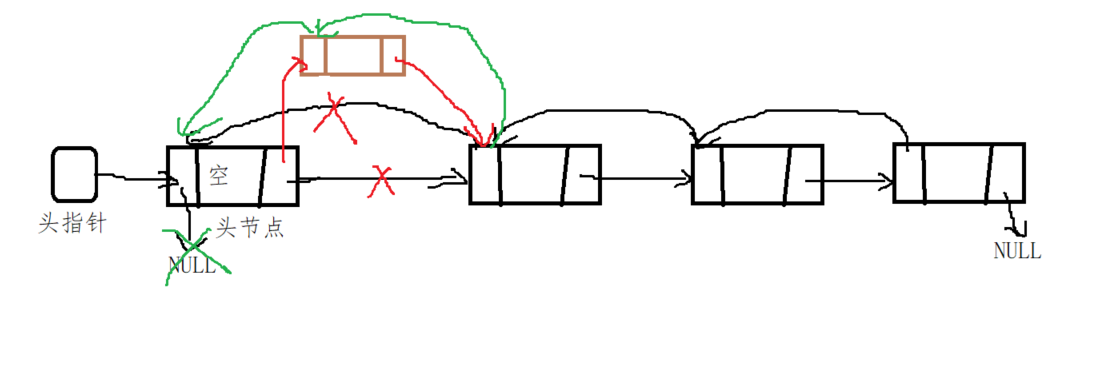
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Create a double linked list node
struct node
{
struct node *pPrev; // Forward pointer to the previous node
int data ;
struct node *pNext; // Backward pointer to the next node
};
struct node * cread_node(int Data)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc struct node error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
p-> data = Data;
p-> pPrev = NULL;
p-> pNext = NULL;
return p;
}
// Tail insert node function
void insert_tail(struct node *pH,struct node *new)
{
// The first step is to go to the end node of the linked list
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
// At the end of the loop, p points to the original tail node
// The second step is to insert the new node behind the original tail node
p->pNext = new; // The backward pointer of p is associated with the first address of the new node
new->pPrev = p;// The forward pointer of new is associated with the address of p (the original tail node)
// The pPrev of the previous node and the pNext pointer of the new node do not move
}
// Head insertion
void insert_head(struct node *pH,struct node *new)
{
// The pNext of the new node points to the pPrev of the original first node to prevent the loss of subsequent nodes
new->pNext = pH->pNext;
// The original pPrev of the first node points to the pPrev of the new node. Because the p pointer is kept, it is still pointing to the original position of the first node
// If there is no valid node, pH - > pnext refers to NULL. If you continue pH - > pnext - > pprev, you will get a segment error.
// So, add an if statement.
if(NULL != pH->pNext)
pH->pNext->pPrev = new;// Combined with graphic understanding
// The pNext pointer of the head node is the first address of the new node
pH->pNext = new;
// The new node's pPrev points to the head node's pPrev
new ->pPrev = pH;
}
int main(void)
{
struct node *pHeader = cread_node(0);// The header pointer points to the header node
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(12));
insert_head(pHeader,cread_node(123));
insert_head(pHeader,cread_node(1234));
struct node *p = pHeader->pNext->pNext->pNext->pNext;
printf("node 4 is %d\n",p->data );
printf("node 3 is %d\n",p->pPrev->data );
printf("node 2 is %d\n",p->pPrev->pPrev->data );
printf("node 1 is %d\n",p->pPrev->pPrev->pPrev->data );
return 0;
}
4.2 traversal node of double linked list
Double linked list can traverse backward or forward. (forward traversal is not of great significance) choose single linked list or double linked list according to the situation, as well as backward traversal and forward traversal.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Create a double linked list node
struct node
{
struct node *pPrev; // Forward pointer to the previous node
int data ;
struct node *pNext; // Backward pointer to the next node
};
struct node * cread_node(int Data)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc struct node error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
p-> data = Data;
p-> pPrev = NULL;
p-> pNext = NULL;
return p;
}
// Tail insert node function
void insert_tail(struct node *pH,struct node *new)
{
// The first step is to go to the end node of the linked list
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
// At the end of the loop, p points to the original tail node
// The second step is to insert the new node behind the original tail node
p->pNext = new; // The backward pointer of p is associated with the first address of the new node
new->pPrev = p;// The forward pointer of new is associated with the address of p (the original tail node)
// The pPrev of the previous node and the pNext pointer of the new node do not move
}
// Head insertion
void insert_head(struct node *pH,struct node *new)
{
// The pNext of the new node points to the pPrev of the original first node to prevent the loss of subsequent nodes
new->pNext = pH->pNext;
// The original pPrev of the first node points to the pPrev of the new node. Because the p pointer is kept, it is still pointing to the original position of the first node
// If there is no valid node, pH - > pnext refers to NULL. If you continue pH - > pnext - > pprev, you will get a segment error.
// So, add an if statement.
if(NULL != pH->pNext)
pH->pNext->pPrev = new;// Combined with graphic understanding
// The pNext pointer of the head node is the first address of the new node
pH->pNext = new;
// The new node's pPrev points to the head node's pPrev
new ->pPrev = pH;
}
// Traverse the linked list and traverse backward
void traverse(struct node *pH)
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
printf("data = %d\n",p->data );
}
}
// Traverse a double linked list forward, and the parameter pTail should point to the end of the linked list
void forward_traverse(struct node *pTail)
{
struct node *p = pTail;
while(NULL != p->pPrev)
{
printf("data is %d\n",p->data );
p = p->pPrev; // Pay attention to the order of these two sentences. If the p pointer moves forward before printing, it will cause the tail node to leak.
}
}
int main(void)
{
struct node *pHeader = cread_node(0);// The header pointer points to the header node
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(12));
insert_head(pHeader,cread_node(123));
insert_head(pHeader,cread_node(1234));
traverse(pHeader);
struct node *p = pHeader->pNext->pNext->pNext->pNext;
forward_traverse(p);
/*
struct node *p = pHeader->pNext->pNext->pNext->pNext;
printf("node 4 is %d\n",p->data );
printf("node 3 is %d\n",p->pPrev->data );
printf("node 2 is %d\n",p->pPrev->pPrev->data );
printf("node 1 is %d\n",p->pPrev->pPrev->pPrev->data );
*/
return 0;
}
result:
data = 1234
data = 123
data = 12
data = 1
data is 1
data is 12
data is 123
data is 1234
4.3 delete node of double linked list
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// Create a double linked list node
struct node
{
struct node *pPrev; // Forward pointer to the previous node
int data ;
struct node *pNext; // Backward pointer to the next node
};
struct node * cread_node(int Data)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc struct node error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
p-> data = Data;
p-> pPrev = NULL;
p-> pNext = NULL;
return p;
}
// Tail insert node function
void insert_tail(struct node *pH,struct node *new)
{
// The first step is to go to the end node of the linked list
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
// At the end of the loop, p points to the original tail node
// The second step is to insert the new node behind the original tail node
p->pNext = new; // The backward pointer of p is associated with the first address of the new node
new->pPrev = p;// The forward pointer of new is associated with the address of p (the original tail node)
// The pPrev of the previous node and the pNext pointer of the new node do not move
}
// Head insertion
void insert_head(struct node *pH,struct node *new)
{
// The pNext of the new node points to the pPrev of the original first node to prevent the loss of subsequent nodes
new->pNext = pH->pNext;
// The original pPrev of the first node points to the pPrev of the new node. Because the p pointer is kept, it is still pointing to the original position of the first node
// If there is no valid node, pH - > pnext refers to NULL. If you continue pH - > pnext - > pprev, you will get a segment error.
// So, add an if statement.
if(NULL != pH->pNext)
pH->pNext->pPrev = new;// Combined with graphic understanding
// The pNext pointer of the head node is the first address of the new node
pH->pNext = new;
// The new node's pPrev points to the head node's pPrev
new ->pPrev = pH;
}
// Traverse the linked list and traverse backward
void traverse(struct node *pH)
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
printf("data = %d\n",p->data );
}
}
// Traverse a double linked list forward, and the parameter pTail should point to the end of the linked list
void forward_traverse(struct node *pTail)
{
struct node *p = pTail;
while(NULL != p->pPrev)
{
printf("data is %d\n",p->data );
p = p->pPrev;
// Pay attention to the order of these two sentences. If the p pointer moves forward before printing,
// It will cause the tail node to leak.
}
}
// Delete node function
int delete_node(struct node *pH,int Data )
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
if(p->data == Data)
{
if(NULL == p->pNext)
{
p->pPrev->pNext = NULL;
//p represents the address of the current node, and p - > pprev represents the address of the previous node
}
else // Deletion of ordinary nodes
{
p->pPrev->pNext = p->pNext;
p->pNext->pPrev = p->pPrev;
}
free(p);
return 0;
}
}
return -1;
}
int main(void)
{
struct node *pHeader = cread_node(0);// The header pointer points to the header node
insert_head(pHeader,cread_node(1));
insert_head(pHeader,cread_node(12));
insert_head(pHeader,cread_node(123));
insert_head(pHeader,cread_node(1234));
delete_node(pHeader,12);
traverse(pHeader);
return 0;
}
result:
data = 1234
data = 123
data = 1
5, Linux kernel linked list
5.1 limitations of the above linked list data area
(1) The previously defined data area is directly int data; But in reality, the nodes of the linked list can not be so simple in programming, but are diverse.
(2) In a linked list in a general project, the data stored in the node is actually a structure, which contains several members, which together constitute the node data area.
5.2 design idea of kernel chain
The kernel linked list directly implements the encapsulation of a pure linked list (no data field, only forward and backward pointers), as well as various operation functions of the pure linked list (node creation, insertion, deletion, traversal, etc.). This pure linked list itself is of no use. Its usage is called by our specific chain.
5·3 list.h file
The implementation of pure linked list in kernel is in include / Linux / list H file
6, State machine
6.1 the state machine often referred to is the Finite State Machine FSM. FSM refers to a limited number of states (generally the value of a state variable). The machine can receive signals and information input from the outside at the same time. After receiving the external input signal, the machine will comprehensively consider its current state and user information, and then the machine makes an action: jump to another state.
6.2 two state machines: Moore type and Mealy type
(1) Moore state machine: the output is only related to the current state machine (independent of the input signal). Relatively simple, when considering the next state of the state machine, you only need to consider its current state.
(2) Mealy type: the output is not only related to the state, but also related to the input. When the state machine receives an input signal and needs to jump to the next state, the state machine decides which state to jump to after comprehensively considering two conditions (current state, input value).
6.3 main uses of state machine: circuit design, FPGA program design, software design.
7. Introduction to multithreading
Parallel execution mechanism under 7.1 operating system
Parallel in macro and serial in micro.
Theoretically, a single core CPU has only one core and can only execute one instruction at the same time. This kind of CPU can only realize parallel in the macro and serial in the micro. Micro parallelism requires multi-core CPU. Multiple cores in multi-core CPU can execute multiple instructions at the same time. Therefore, micro parallelism can be achieved, so as to improve the macro parallelism.
7.2 differences and relations between processes and threads
(1) Process and thread are two different software technologies of the operating system. The purpose is to realize macro parallelism (popular point is to let multiple processes run on one machine at the same time to achieve macro parallelism).
(2) Process and thread are different in the principle of realizing parallel effect. And the difference is related to the operating system. For example, there are great differences between processes and threads in windows, but there is little difference between processes and threads in Linux (threads are lightweight processes in Linux).
(3) Whether it is multi process or multi thread, the ultimate goal is to achieve parallel execution.
7.3 advantages of multithreading
Before, there were more multi processes. In recent years, there have been more multi threads. In the design of modern operating system, the optimization of multi-core CPU is considered to ensure that when multi-threaded programs are running, the operating system will give priority to putting multiple threads in multiple cores to run separately. Therefore, multi-core CPU provides a perfect running environment for multithreaded programs. Therefore, using multithreaded programs on multi-core CPUs has great benefits.
7.4 thread synchronization and locking
See system programming for details.