Histogram, a special type of statistical information of columns, can provide more detailed data distribution information of columns in the table. Histogram stores values in buckets. Based on the number of different values and the distribution of data, the database selects the type of histogram to be created. The types of histogram are as follows:
- Frequency histograms and to frequency histograms;
- Height balanced histograms;
- Hybrid histograms;
1 histogram introduction
1.1 purpose of histogram
By default, the optimizer assumes a uniform distribution of values between columns. For columns containing data skew (columns in which the data is unevenly distributed), histograms enable the optimizer to generate more accurate cardinality estimates for filter or join predicates involving these columns, resulting in more accurate execution plans.
1.2 when to create histogram in database
Using DBMS_STATS collects the statistics of the table. When querying and referencing the columns in the table, the database will automatically create a histogram based on the previous query load. The basic process is as follows:
- Using DBMS_STATS collects statistics for a table and specifies the method_ The opt parameter defaults to SIZE AUTO;
- The user queries the corresponding table;
- The database records the predicate used in the previous query and updates the data dictionary table SYS.COL_USAGE$;
- Run DBMS again_ When stats, DBMS_STATS will query SYS.COL_ The usage $view determines which columns need histograms based on the previous query load.
Example:
1) Create test table
SQL> create table sh.sales_new as select * from sh.sales; Table created.
2) View statistics
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='SALES_NEW'; COLUMN_NAME NOTES HISTOGRAM ------------------------------ ------------------------------ --------------- AMOUNT_SOLD STATS_ON_LOAD NONE QUANTITY_SOLD STATS_ON_LOAD NONE PROMO_ID STATS_ON_LOAD NONE CHANNEL_ID STATS_ON_LOAD NONE TIME_ID STATS_ON_LOAD NONE CUST_ID STATS_ON_LOAD NONE PROD_ID STATS_ON_LOAD NONE 7 rows selected.
3) Execute query
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='SALES_NEW'; COLUMN_NAME NOTES HISTOGRAM ------------------------------ ------------------------------ --------------- AMOUNT_SOLD STATS_ON_LOAD NONE QUANTITY_SOLD STATS_ON_LOAD NONE PROMO_ID STATS_ON_LOAD NONE CHANNEL_ID STATS_ON_LOAD NONE TIME_ID STATS_ON_LOAD NONE CUST_ID STATS_ON_LOAD NONE PROD_ID STATS_ON_LOAD NONE 7 rows selected.
4) Collect statistics
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','SALES_NEW',OPTIONS=>'GATHER AUTO');
PL/SQL procedure successfully completed.5) View statistics
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='SALES_NEW'; COLUMN_NAME NOTES HISTOGRAM ------------------------------ ------------------------------ --------------- AMOUNT_SOLD STATS_ON_LOAD NONE QUANTITY_SOLD STATS_ON_LOAD NONE PROMO_ID STATS_ON_LOAD NONE CHANNEL_ID STATS_ON_LOAD NONE TIME_ID STATS_ON_LOAD NONE CUST_ID STATS_ON_LOAD NONE PROD_ID HISTOGRAM_ONLY FREQUENCY 7 rows selected.
6) View the use of columns
SQL> select * from sys.col_usage$ where obj#=93264; OBJ# INTCOL# EQUALITY_PREDS EQUIJOIN_PREDS NONEQUIJOIN_PREDS RANGE_PREDS LIKE_PREDS NULL_PREDS TIMESTAMP ---------- ---------- -------------- -------------- ----------------- ----------- ---------- ---------- --------- 93264 1 1 0 0 0 0 0 25-APR-20
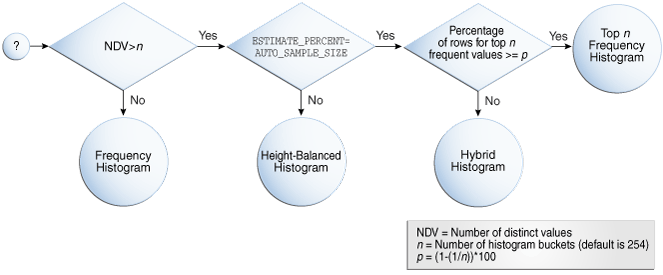
1.3 how to select histogram type
As mentioned earlier, there are many types of histogram, so how to choose the type of histogram when creating a histogram? Here are several reference variables:
- NDV: indicates the number of different values of the column;
- n: Represents the number of histogram buckets (254 by default);
- p: Represents the internal percentage threshold equal to (1-(1/n))*100;
- DBMS_ Estimate in stats_ Whether the percent parameter is set to auto_sample_size (default).
The following figure shows the decision tree when histogram is created:
2 histogram cardinality algorithm
For histograms, the cardinality algorithm depends on factors such as number of endpoints and values, and whether column values are popular.
2.1 Endpoint Numbers and Values
The endpoint number is the number that uniquely identifies the bucket. In the frequency and mix histogram, the endpoint number is the cumulative frequency of all the values contained in the current bucket and the previous bucket. For example, if the endpoint number is 100, the total frequency of the current bucket and the previous bucket values is 100. In the histogram of height balance, the optimizer numbers the buckets in order, starting from 0 or 1. In all cases, the end number is the can number.
The endpoint value is the maximum value in the median range of buckets, for example, if a bucket contains only 52794 and 52795, then the endpoint value is 52795.
2.2 popular and unpopular values
The popularity of a value in the histogram will affect the radix estimation algorithm, as follows:
- Welcome value: the welcome value appears in the endpoint value of multiple buckets. The optimizer determines whether the value is welcome by checking whether a value is the endpoint value of the bucket. If so, for the frequency histogram, the optimizer subtracts the number of endpoints of the previous bucket from the number of endpoints of the current bucket. The mixed histogram stores the information of each endpoint. If the value is greater than 1, the value is welcome Welcome. For popular values, the optimizer calculates cardinality of popular value = (num of rows in table) * (num of endpoints spanned by this value / total num of endpoints);
- Unwelcome value: all unwelcome values are unwelcome values. For unwelcome values, the optimizer calculates the cardinality estimate by the following formula: cardinality of nonpopular value = (num of rows in table) * density.
2.3 Bucket Compression
In some cases, in order to reduce the total number of buckets, the optimizer compresses multiple buckets into one bucket. For example, the following frequency histogram shows that the first bucket number is 1 and the last bucket number is 23:
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
1 52792
6 52793
8 52794
9 52795
10 52796
12 52797
14 52798
23 52799As you can see, there are several buckets "lost". At first, buckets 2 to 6 each contain an instance with a value of 52793. The optimizer compresses all these buckets into buckets with the highest number of points (bucket 6). The bucket now contains the value of 52793 for five instances, which is popular because the difference between the current bucket and the previous bucket's endpoint number is 5, so before compression, 52793 is 5 Ends of buckets. The following figure shows which buckets are compressed and which values are popular:
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
1 52792 -> nonpopular
6 52793 -> buckets 2-6 compressed into 6; popular
8 52794 -> buckets 7-8 compressed into 8; popular
9 52795 -> nonpopular 10 52796 -> nonpopular
12 52797 -> buckets 11-12 compressed into 12; popular
14 52798 -> buckets 13-14 compressed into 14; popular
23 52799 -> buckets 15-23 compressed into 23; popular3 frequency histogram
In the frequency histogram, each different column value corresponds to a histogram bucket. Because each value has its own special bucket, some buckets will have many values, while others will have few.
3.1 conditions of frequency histogram
When the following conditions are met, the database creates a frequency histogram:
- NDV is less than or equal to the number of barrels (default is 254);
- DBMS_ The parameters of the process corresponding to stats are set to AUTO_SAMPLE_SIZE or specify a specific value;
3.2 generate frequency histogram
This experiment sh.countries_new column country_subregion_id generates frequency histogram.
1) Generate test data
SQL> create table sh.countries_new as select * from sh.countries; Table created. SQL> select country_subregion_id,count(1) from sh.countries_new group by country_subregion_id order by 1; COUNTRY_SUBREGION_ID COUNT(1) -------------------- ---------- 52792 1 52793 5 52794 2 52795 1 52796 1 52797 2 52798 2 52799 9 8 rows selected.
2) Collect statistics
begin dbms_stats.gather_table_stats(ownname => 'SH', tabname => 'COUNTRIES_NEW', method_opt => 'for columns country_subregion_id'); end; / PL/SQL procedure successfully completed.
3) View column statistics
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='COUNTRIES_NEW'; COLUMN_NAME NOTES HISTOGRAM ------------------------------ ------------------------------ --------------- COUNTRY_NAME_HIST STATS_ON_LOAD NONE COUNTRY_TOTAL_ID STATS_ON_LOAD NONE COUNTRY_TOTAL STATS_ON_LOAD NONE COUNTRY_REGION_ID STATS_ON_LOAD NONE COUNTRY_REGION STATS_ON_LOAD NONE COUNTRY_SUBREGION_ID FREQUENCY COUNTRY_SUBREGION STATS_ON_LOAD NONE COUNTRY_NAME STATS_ON_LOAD NONE COUNTRY_ISO_CODE STATS_ON_LOAD NONE COUNTRY_ID STATS_ON_LOAD NONE 10 rows selected.
See country_ SUBREGION_ The ID has collected histogram information.
4) View histogram information
select t.endpoint_number, t.endpoint_value from dba_histograms t where t.owner = 'SH' and t.table_name = 'COUNTRIES_NEW' and t.column_name = 'COUNTRY_SUBREGION_ID'; ENDPOINT_NUMBER ENDPOINT_VALUE --------------- -------------- 1 52792 6 52793 8 52794 9 52795 10 52796 12 52797 14 52798 23 52799 8 rows selected.
5) Optimizer evaluates the cardinality of 52799
SQL> select count(1) from sh.countries_new; COUNT(1) ---------- 23 SQL> select count(1) from sh.countries_new where country_subregion_id=52799; COUNT(1) ---------- 9
cardinality of popular value = (num of rows in table) * (num of endpoints spanned by this value / total num of endpoints)
Namely: C=23*(9/23)=9
Same result as query
4 maximum frequency histogram
The highest frequency histogram is a variation of the frequency histogram, which ignores the unwelcome values that are not statistically important.
4.1 conditions of the highest frequency histogram
If a small number of values account for a large number of branches, it is useful to create a frequency histogram on this small number of values, even if the NDV is greater than the number of buckets of the requested histogram. Create a higher quality histogram for the popular values, and the optimizer will ignore the unwelcome values and create a histogram.
When the following conditions are met, the database creates the highest frequency histogram:
- NDV is greater than the number of histogram buckets (default is 254);
- The percentage of rows occupied by the first n frequency values is equal to or greater than the threshold p, p is equal to (1 - (1/n))*100;
- BMS_ The parameters of the process corresponding to stats are set to AUTO_SAMPLE_SIZE;
4.2 generate the highest frequency histogram
This experiment sh.countries_new column country_subregion_id generates frequency histogram.
1) Generate test data
SQL> select country_subregion_id,count(1) from sh.countries_new group by country_subregion_id order by 1; COUNTRY_SUBREGION_ID COUNT(1) -------------------- ---------- 52792 1 52793 5 52794 2 52795 1 52796 1 52797 2 52798 2 52799 9 8 rows selected.
2) Collect statistics
begin dbms_stats.gather_table_stats(ownname => 'SH', tabname => 'COUNTRIES_NEW', method_opt => 'for columns country_subregion_id size 7 '); end; / PL/SQL procedure successfully completed.
3) View column statistics
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='COUNTRIES_NEW'; COLUMN_NAME NOTES HISTOGRAM ------------------------------ ------------------------------ --------------- COUNTRY_NAME_HIST STATS_ON_LOAD NONE COUNTRY_TOTAL_ID STATS_ON_LOAD NONE COUNTRY_TOTAL STATS_ON_LOAD NONE COUNTRY_REGION_ID STATS_ON_LOAD NONE COUNTRY_REGION STATS_ON_LOAD NONE COUNTRY_SUBREGION_ID TOP-FREQUENCY COUNTRY_SUBREGION STATS_ON_LOAD NONE COUNTRY_NAME STATS_ON_LOAD NONE COUNTRY_ISO_CODE STATS_ON_LOAD NONE COUNTRY_ID STATS_ON_LOAD NONE 10 rows selected.
See COUNTRY_SUBREGION_ID has collected TOP-FREQUENCY histogram information.
4) View histogram information
select t.endpoint_number, t.endpoint_value from dba_histograms t where t.owner = 'SH' and t.table_name = 'COUNTRIES_NEW' and t.column_name = 'COUNTRY_SUBREGION_ID'; ENDPOINT_NUMBER ENDPOINT_VALUE --------------- -------------- 1 52792 6 52793 8 52794 9 52796 11 52797 13 52798 22 52799 7 rows selected.
5 high balance histogram (Legacy)
In the height balance histogram, the column values are divided into buckets so that each bucket contains approximately the same data row.
To be continued...