redis master-slave replication
concept
Master Slave replication refers to copying data from one Redis server to other Redis servers. The former is called master / leader and the latter is called Slave / follower; Data replication is unidirectional and can only be from master node to Slave node. Master mainly writes, Slave mainly reads.
By default, each Redis server is the master node; A master node can have multiple slave nodes (or no slave nodes), but a slave node can only have one master node,
The functions of master-slave replication include:
1. Data redundancy
2. Fault recovery
3. Load balancing
4. High availability (cluster) cornerstone
Generally speaking, to apply Redis to engineering projects, it is absolutely impossible to use only one Redis (downtime). The reasons are as follows:
1. Structurally, a single Redis server will have a single point of failure, and one server needs to handle all request loads, resulting in great pressure;
2. In terms of capacity, the memory capacity of a single Redis server is limited. Even if the memory capacity of a Redis server is 256G, all memory can not be used as Redis storage memory. Generally speaking, the maximum memory used by a single Redis should not exceed 20G
Commodities on e-commerce websites are usually uploaded at one time and browsed countless times. To be professional is to "read more and write less"
For this scenario, we can make the following architecture:
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (IMG odswahbv-1633684064333) (14 redis master-slave copy. assets/image-20211007203352365.png)]
Master-slave copy, read-write separation! 80% of the cases are read operations! Reduce the pressure on the server! Often used in architecture!
Often used in architecture! One master and two slaves!
Master-slave replication must be used in the company, because Redis cannot be used on a single machine in a real project!
Environment construction
Configure only slave libraries, not master libraries!
127.0.0.1:6379> info replication #View information about the current library # Replication role:master # role connected_slaves:0 # No slave master_replid:e52d2190f120980eb1124b83538fede4be7540fb master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6379>
A total of four machines, one machine to see the situation First, copy three configuration files redis.conf redis79.conf redis80.conf redis81.conf redis.conf Second amendment vim redis79.conf This port number does not need to be changed logfile "" ---->logfile "6379.log" dump.rdb ------> dump6379.rdb Third amendment vim redis80.conf port 6379 ---> port 6380 6379 are changed to 6380 logfile "" ---->logfile "6380.log" dump.rdb ------> dump6380.rdb Fourth amendment vim redis81.conf port 6379 ---> port 6381 All 6379 are changed to 6381 logfile "" ---->logfile "6381.log" dump.rdb ------> dump6381.rdb All on~
Replication principle of master-slave replication
By default, each redis server is the primary node!
We usually only use slave machines!
Recognize the first leader (79) and the second follower (80, 81)
slaveof 127.0.0.1 6379 #Looking for the boss #(80) info replication #View information about the current library One more slave information will be viewed in the host info replication slaveof 127.0.0.1 6379 #Looking for the boss #Another (81) info replication #View information about the current library
The real slave configuration should be configured in the configuration file. In this case, it is permanent. We use commands here, temporary!
details
The host can write, the slave can't write, can only read!
All information and data in the host will be automatically saved by the slave!
test∶When the host is disconnected, the slave is still connected to the host, but there is no write operation. At this time, if the host returns, the slave can still directly obtain the information written by the host! If you use the command line to configure the master-slave, if the slave restarts at this time, it will change back to the host! test∶The slave is disconnected, the host setting value, the slave is connected, and the slave cannot be obtained,(The reason is that when the slave is restarted, it will change back to the host) test:Recognize the boss after the slave is restarted, that is, become a slave again, and you can still get the data of the host~
Replication principle
After Slave is successfully started and connected to the master, it will send a sync synchronization command
After receiving the command, the master starts the background save process and collects all received commands for modifying the dataset. After the background process is executed, the master will transfer the entire data file to the slave and complete a complete synchronization.
**Full copy: * * the slave service saves and loads the database file data into memory after receiving it.
**Incremental replication: * * the Master continues to pass all new collected modification commands to the slave in turn to complete the synchronization
However, as long as the master is reconnected, a full synchronization (full replication) will be performed automatically! Our data must be visible in the slave!
understand
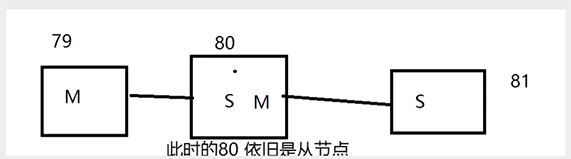
Manually configure hosts after downtime
Conspire to usurp the throne
If the host is disconnected, we can use SLAVEoF no one to turn ourselves into a host! Other nodes can be manually connected to the latest master node (manual)! If the boss fixes it at this time, reconnect it!