1, The concept of Hook function
1.1 reasons for hook introduction
The operation mechanism of Python is dynamic calculation graph. After the operation of dynamic graph, some intermediate variables (such as the gradient of feature map and non leaf node) will be released, but sometimes we need to obtain these intermediate variables. At this time, we can obtain or change the intermediate variables by adding additional functions in the main body through Hook function according to Hook mechanism
1.2 Hook function mechanism
Hook function mechanism: does not change the main body (forward propagation and backward propagation), and implements additional functions, such as a pendant, hook, hook

The operation mechanism of call() function in nn.module is hook function mechanism. The whole call function is divided into four parts, namely:
- forward_pre_hook
- forward
- forward_hook
- backward_hook
As shown in the figure above, the call() function executes the forward ﹣ pre ﹣ hook function, then the forward propagation process, then the forward ﹣ hook function, and finally the back ﹣ forward function
Therefore, in the forward propagation process, not only the propagation of the preceding item is performed, but also the hook function interface is provided to realize additional operations and functions
1.3 four hook functions
It can be divided into three categories: for sensor, forward propagation and backward propagation
- torch.Tensor.register_hook(hook)
- torch.nn.Module.register_forward_hook
- torch.nn.Module.register_forward_pre_hook
- torch.nn.Module.register_backward hook
2, Hook function and feature extraction
2.1 Tensor.register_hook
hook(grad)
Function: register a back propagation hook function
The Hook function has only one input parameter, which is the gradient of the tensor and returns the tensor or no return
Example: get and change the gradient of non leaf node through hook function
# -*- coding:utf-8 -*- import torch import torch.nn as nn from tools.common_tools import set_seed set_seed(1) # Set random seed # ----------------------------------- 1 tensor hook 1 ----------------------------------- # flag = 0 flag = 1 if flag: w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True) a = torch.add(w, x) b = torch.add(w, 1) y = torch.mul(a, b) a_grad = list() # Gradient of storage tensor def grad_hook(grad): a_grad.append(grad) handle = a.register_hook(grad_hook) # Register the defined function to the corresponding tensor y.backward() # View gradient print("gradient:", w.grad, x.grad, a.grad, b.grad, y.grad) print("a_grad[0]: ", a_grad[0]) handle.remove() # ----------------------------------- 2 tensor hook 2 ----------------------------------- # flag = 0 flag = 1 if flag: w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True) a = torch.add(w, x) b = torch.add(w, 1) y = torch.mul(a, b) a_grad = list() def grad_hook(grad): # Define hook function to modify tensor gradient grad *= 2 return grad*3 # The gradient returned through return will overwrite the original gradient handle = w.register_hook(grad_hook) y.backward() # View gradient print("w.grad: ", w.grad) handle.remove()
Operation result:
Explain:
- By defining the list, the gradient of the tensor is saved in the list through the hook function, so that the gradient can be obtained after the operation
- If the custom hook function return returns a gradient, the returned gradient will cover the original gradient
2.2 Module.register_forward _hook
hook(module, input, output)
Function: register the forward propagation hook function of the module
Return value: None
Parameters:
- module: current network layer
- Input: current network layer input data
- Output: output data of current network layer
Example: get the feature map in forward propagation
# -*- coding:utf-8 -*- import torch import torch.nn as nn from tools.common_tools import set_seed set_seed(1) # Set random seed # ----------------------------------- 3 Module.register_forward_hook and pre hook ----------------------------------- # flag = 0 flag = 1 if flag: class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 2, 3) self.pool1 = nn.MaxPool2d(2, 2) def forward(self, x): x = self.conv1(x) x = self.pool1(x) return x def forward_hook(module, data_input, data_output): fmap_block.append(data_output) input_block.append(data_input) def forward_pre_hook(module, data_input): print("forward_pre_hook input:{}".format(data_input)) def backward_hook(module, grad_input, grad_output): print("backward hook input:{}".format(grad_input)) print("backward hook output:{}".format(grad_output)) # Initialize network net = Net() net.conv1.weight[0].detach().fill_(1) net.conv1.weight[1].detach().fill_(2) net.conv1.bias.data.detach().zero_() # Registered hook fmap_block = list() input_block = list() net.conv1.register_forward_hook(forward_hook) # net.conv1.register_forward_pre_hook(forward_pre_hook) # net.conv1.register_backward_hook(backward_hook) # inference fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W output = net(fake_img) # loss_fnc = nn.L1Loss() # target = torch.randn_like(output) # loss = loss_fnc(target, output) # loss.backward() # observation print("output shape: {}\noutput value: {}\n".format(output.shape, output)) print("feature maps shape: {}\noutput value: {}\n".format(fmap_block[0].shape, fmap_block[0])) print("input shape: {}\ninput value: {}".format(input_block[0][0].shape, input_block[0]))

2.3 Module.register_forward_pre_hook
hook(module, input)
Function: register the hook function before module forward propagation
Return value: None
Parameters:
- module: current network layer
- Input: current network layer input data
2.4 Module.register_backward_hook
hook(module, grad_input, grad_output)
Function: register the hook function of module back propagation
Return value: sensor or none
Parameters:
- module: current network layer
- Grad Ou input: current network layer input gradient data
- Grad Ou output: output gradient data of current network layer
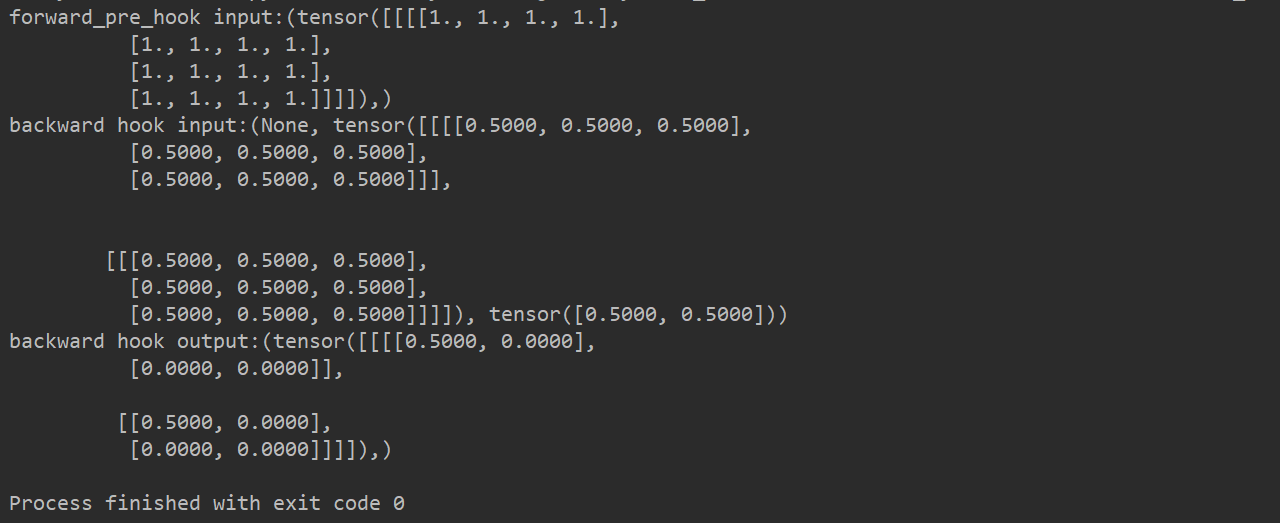
Example: use of forward ﹐ pre ﹐ hook and backward ﹐ hook
# -*- coding:utf-8 -*- import torch import torch.nn as nn from tools.common_tools import set_seed set_seed(1) # Set random seed # ----------------------------------- 3 Module.register_forward_hook and pre hook ----------------------------------- # flag = 0 flag = 1 if flag: class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 2, 3) self.pool1 = nn.MaxPool2d(2, 2) def forward(self, x): x = self.conv1(x) x = self.pool1(x) return x def forward_hook(module, data_input, data_output): fmap_block.append(data_output) input_block.append(data_input) def forward_pre_hook(module, data_input): print("forward_pre_hook input:{}".format(data_input)) def backward_hook(module, grad_input, grad_output): print("backward hook input:{}".format(grad_input)) print("backward hook output:{}".format(grad_output)) # Initialize network net = Net() net.conv1.weight[0].detach().fill_(1) net.conv1.weight[1].detach().fill_(2) net.conv1.bias.data.detach().zero_() # Registered hook fmap_block = list() input_block = list() net.conv1.register_forward_hook(forward_hook) net.conv1.register_forward_pre_hook(forward_pre_hook) net.conv1.register_backward_hook(backward_hook) # inference fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W output = net(fake_img) loss_fnc = nn.L1Loss() target = torch.randn_like(output) loss = loss_fnc(target, output) loss.backward()
2.5 use hook function to visualize feature map
# -*- coding:utf-8 -*- import torch.nn as nn import numpy as np from PIL import Image import torchvision.transforms as transforms import torchvision.utils as vutils from torch.utils.tensorboard import SummaryWriter from tools.common_tools import set_seed import torchvision.models as models set_seed(1) # Set random seed # ----------------------------------- feature map visualization ----------------------------------- # flag = 0 flag = 1 if flag: writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix") # data path_img = "./lena.png" # your path to image normMean = [0.49139968, 0.48215827, 0.44653124] normStd = [0.24703233, 0.24348505, 0.26158768] norm_transform = transforms.Normalize(normMean, normStd) img_transforms = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), norm_transform ]) img_pil = Image.open(path_img).convert('RGB') if img_transforms is not None: img_tensor = img_transforms(img_pil) img_tensor.unsqueeze_(0) # chw --> bchw # Model alexnet = models.alexnet(pretrained=True) # Registered hook fmap_dict = dict() for name, sub_module in alexnet.named_modules(): # named_modules() returns the subnet layer and its name of the network if isinstance(sub_module, nn.Conv2d): key_name = str(sub_module.weight.shape) fmap_dict.setdefault(key_name, list()) n1, n2 = name.split(".") def hook_func(m, i, o): key_name = str(m.weight.shape) fmap_dict[key_name].append(o) alexnet._modules[n1]._modules[n2].register_forward_hook(hook_func) # forward output = alexnet(img_tensor) # add image for layer_name, fmap_list in fmap_dict.items(): fmap = fmap_list[0] fmap.transpose_(0, 1) nrow = int(np.sqrt(fmap.shape[0])) fmap_grid = vutils.make_grid(fmap, normalize=True, scale_each=True, nrow=nrow) writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)

3, Cam and grad cam
3.1 CAM
CAM: Class activation map
Function: according to the output of the network, analyze the output that the network focuses on the part of the image
Basic idea: weighted sum and average the last characteristic graph of network output to get an attention mechanism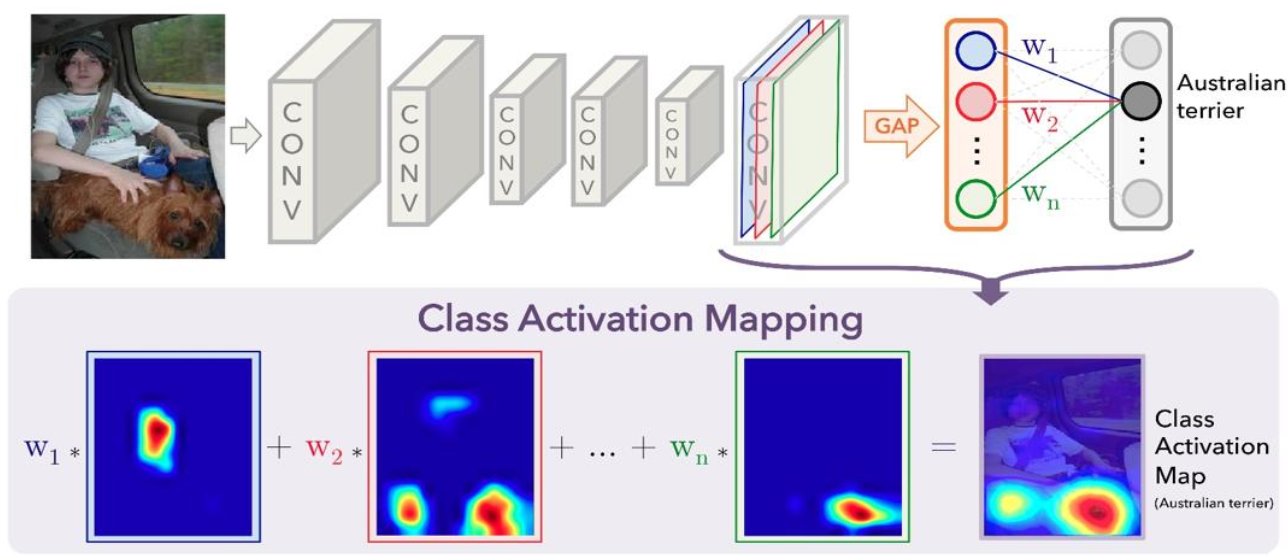
Operation mechanism: pool the final feature map with global average, convert the feature map into vector form, each channel corresponds to a neuron, then another fc layer is output, and the weight of neuron corresponding to the class of image output is the weight of the feature map
Disadvantages: the network model needs to be changed, and the final output of the network must be globally averaged and pooled to obtain the weight, because it is often necessary to change the later network layer to retrain
CAM: <Learning Deep Features for Discriminative Localization>
3.2 Grad-CAM
Grad CAM: an improved version of CAM, which uses gradient as the weight of feature map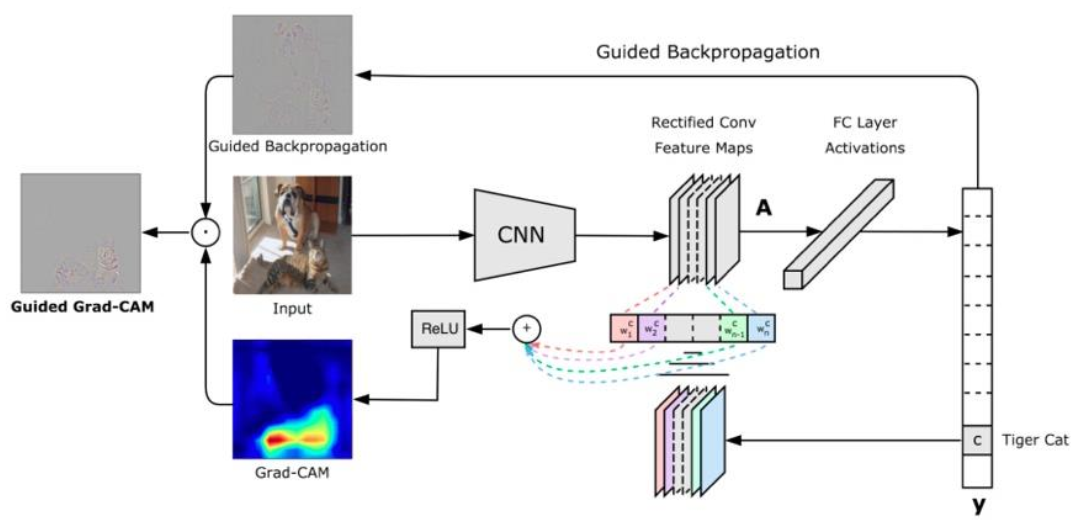
Operation mechanism: according to the output vector, carry out backward, calculate the gradient of the feature map, get the gradient corresponding to each pixel on each feature map, that is, the gradient map corresponding to the feature map, and then average each gradient map, the average value corresponds to the weight of each feature map, and then weighted sum the weight and the feature map, finally through the relu activation function You can get the final class activation graph
Grad-CAM: <Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization>
Experimental example:
Analysis and code: https://xuanlan.zhihu.com/p/75894080

