Review the zipper table Spark SQL|
Zipper Watch
First put it into the incremental table, and then associate it into a temporary table. After inserting it into the new table, 1. Judge the invalid value,
2. Judge the valid value,
3. Union through UNION ALL
DROP TABLE IF EXISTS dw_orders_his_tmp;
CREATE TABLE dw_orders_his_tmp AS
SELECT orderid,
createtime,
modifiedtime,
status,
dw_start_date,
dw_end_date
FROM (
//Judge failure value
SELECT a.orderid,
a.createtime,
a.modifiedtime,
a.status,
a.dw_start_date,
CASE WHEN b.orderid IS NOT NULL AND a.dw_end_date > '2016-08-21' THEN '2016-08-21' ELSE a.dw_end_date END AS dw_end_date
FROM dw_orders_his a
left outer join (SELECT * FROM ods_orders_inc WHERE day = '2016-08-21') b
ON (a.orderid = b.orderid)
UNION ALL
//Judge valid value
SELECT orderid,
createtime,
modifiedtime,
status,
modifiedtime AS dw_start_date,
'9999-12-31' AS dw_end_date
FROM ods_orders_inc
WHERE day = '2016-08-21'
) x
ORDER BY orderid,dw_start_date;
INSERT overwrite TABLE dw_orders_his
SELECT * FROM dw_orders_his_tmp;
Spark SQL
DateFrame
What is DateFrame
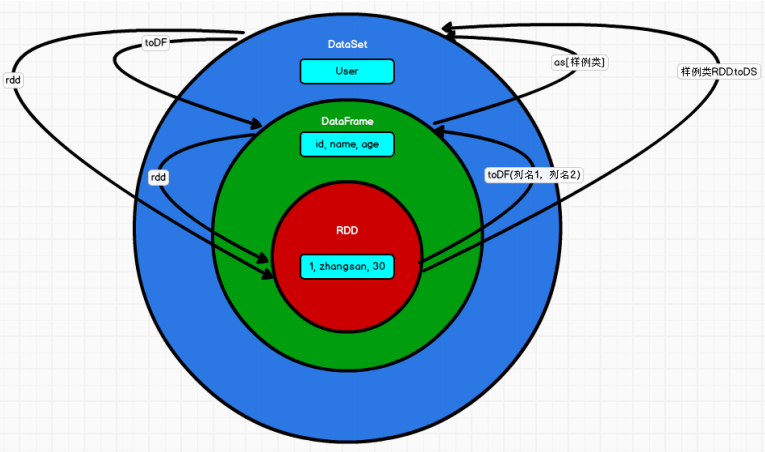
DataFrame is a distributed data set based on RDD, which is similar to two-dimensional tables in traditional databases.
The main difference between DataFrame and RDD is that the former has schema meta information, that is, each column of the two-dimensional table dataset represented by DataFrame has a name and type.
RDD ==> DateFrame
When developing programs in IDEA, if you need RDD and DF or DS to operate with each other, you need to introduce importspark implicits._ The spark here is not the package name in Scala, but the created sparkSession
Object, so you must create a SparkSession object before importing. The spark object here cannot be declared with var, because Scala only supports the introduction of val decorated objects.
//In actual development, RDD is generally transformed into DataFrame through sample classes
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1,
t._2)).toDF.show
DateFrame ==> RDD
//DataFrame is actually the encapsulation of RDD, so you can directly obtain the internal RDD
scala> val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1,
t._2)).toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val rdd = df.rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[46]
at rdd at <console>:25
scala> val array = rdd.collect
array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])
//Note: the RDD storage type obtained at this time is Row
scala> array(0)
res28: org.apache.spark.sql.Row = [zhangsan,30]
scala> array(0)(0)
res29: Any = zhangsan
scala> array(0).getAs[String]("name")
res30: String = zhangsan
DateSet
DataSet is a strongly typed data set, and the corresponding type information needs to be provided.
RDD ⇒ DateSet
SparkSQL can automatically convert the RDD containing the case class into a DataSet. The case class defines the structure of the table
Class attribute becomes the column name of the table through reflection. Case classes can contain complex structures such as Seq or Array.
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1,
t._2)).toDS
res11: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
DateSet ==> RDD
DataSet is actually an encapsulation of RDD, so you can directly obtain the internal RDD
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1,
t._2)).toDS
res11: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> val rdd = res11.rdd
rdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[51] at rdd at
<console>:25
scala> rdd.collect
res12: Array[User] = Array(User(zhangsan,30), User(lisi,49))
Relationship among RDD, DataFrame and DataSet
Same point
∙ RDD, DataFrame and DataSet are all distributed elastic data sets under the spark platform, providing convenience for processing super large data; ➢
All three have inert mechanisms. They will not be executed immediately when creating and converting, such as map methods, but only when encountering actions such as foreach
When, the three start traversal operation; The three have many common functions, such as filter, sorting, etc; when comparing DataFrame and Dataset
This package is required for many operations: import spark implicits._ (try to import directly after creating the SparkSession object)
All three will automatically cache operations according to Spark's memory conditions, so that even if there is a large amount of data, there is no need to worry about memory overflow. All three have the concept of partition
Both DataFrame and DataSet can use pattern matching to obtain the value and type of each field
The difference between the three
-
RDD
Generally, RDD and spark mllib are used at the same time
RDD does not support sparksql operation -
DataFrame
Unlike RDD and Dataset, the type of each Row of DataFrame is fixed as Row, and the value of each column cannot be directly
The value of each field can be obtained only through parsing
Generally, DataFrame and DataSet are not used together with spark mllib
Both DataFrame and DataSet support SparkSQL operations, such as select, groupby, and so on
Register temporary tables / windows for sql statement operations
The DataFrame and DataSet support some particularly convenient saving methods, such as saving as csv and bringing tables
Header, so that the field name of each column is clear at a glance (specifically explained later) -
DataSet
The Dataset and DataFrame have identical member functions, except that the data type of each row is different.
DataFrame is actually a special case of DataSet. type DataFrame = Dataset[Row]
The DataFrame can also be called Dataset[Row]. The type of each Row is Row, which is not resolved. What is the type of each Row
The fields and the types of each field are unknown. You can only use the getAS method mentioned above or Co
The pattern matching mentioned in Article 7 of sex takes out specific fields. What is the type of each row in the Dataset
Not necessarily. After customizing the case class, you can freely obtain the information of each line
Transformation of the three
GIt Commit
Commit specification
Use Git Commit Guidelines as the specification scheme
Commit Message format
<type>(<scope>): <subject> <Blank line> <body> <Blank line> <footer>
Type
feat: New features( feature) fix: repair bug docs: Documentation( documentation) style: Format (changes that do not affect code operation) refactor: Refactoring (i.e. neither new nor modified) bug (code change of) test: Add test chore: Changes in the construction process or auxiliary tools
Scope
It is used to describe the scope of the impact of this Commit, that is, to briefly describe the parts involved in the modification It can be seen from the actual project that it has basically become a required item.
Subject
It is used to briefly describe this change. It is good to summarize it, because the specific information will be given in the Body later. And it is best to follow the following three rules:
Start with a verb and use the first person present tense, such as change,instead of changed or changes Don't capitalize No period at the end(.)
Body
The content in is the expansion of the content in the above subject, which is described in more detail here. The content should include the modification motivation and the comparison before and after modification.Footer
The information of incompatible changes and Issue closure is mainly placed in the footer