Redis advanced features
Slow query
Many storage systems (such as MySQL) provide slow query logs to help developers and operation and maintenance personnel locate the slow operation of the system. The so-called slow query log is that the system calculates the execution time of each command before and after the command is executed. When it exceeds the preset threshold, it records the relevant information of the command (such as occurrence time, time consumption and command details). Redis also provides similar functions.
The Redis client executes a command, which is divided into the following four parts:
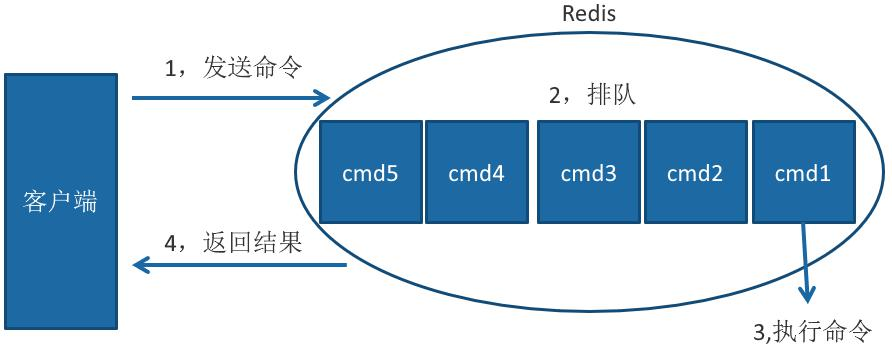
1) Send command 2) command queuing 3) command execution 4) return result
It should be noted that slow query only counts the time in step 3), so no slow query does not mean that the client has no timeout problem.
Slow query configuration
For any slow query function, two things need to be clear: how slow is slow, that is, how to set the preset threshold? Where are slow query records stored?
Redis provides slowlog log lower than and slowlog Max len configurations to solve these two problems. Slowlog log slow than is the preset threshold value. Its unit is microseconds (1 second = 1000 milliseconds = 1 000 000 microseconds). The default value is 10 000. If a "very slow" command (such as keys *) is executed, if its execution time exceeds 10 000 microseconds, that is, 10 milliseconds, it will be recorded in the slow query log.
If slowlog log slow than = 0, all commands will be recorded. If slowlog log slow than < 0, no commands will be recorded.
Slowlog Max len is used to set the maximum number of slow query logs. It does not specify where to store them. In fact, Redis uses a list to store slow query logs. Slowlog Max len is the maximum length of the list. When the slow query log list is filled, the new slow query command will continue to queue, and the first data in the queue will be out of line.
Although the slow query log is stored in the Redis memory list, Redis does not tell us what the list here is, but accesses and manages the slow query log through a set of commands.
Slow query operation command
Get slow query log
slowlog get [n]
Parameter n can specify the number of queries.
Get the current length of slow query log list slowlog len
Slow query log reset slowlog reset actually cleans up the list
Slow query suggestions
The slow query function can effectively help us find the possible bottlenecks of Redis, but we should pay attention to the following points in the actual use process:
Slowlog Max len configuration suggestions; It is recommended to increase the slow query list. When recording slow queries, Redis will truncate long commands and will not occupy a lot of memory. Increasing the slow query list can slow down the possibility that slow queries can be eliminated. For example, online queries can be set to more than 1000.
Suggestions for slowlog log slow than configuration: if the default value exceeds 10ms, it is judged as a slow query, which needs to be adjusted according to the Redis concurrency. Because Redis adopts single thread to respond to commands, for high traffic scenarios, if the command execution time is more than 1 ms, Redis can support less than 1000 OPS at most. Therefore, Redis for high OPS scenarios is recommended to be set to 1 ms or less, such as 100 microseconds.
Slow query only records command execution time, not including command queuing and network transmission time. Therefore, the time for the client to execute the command will be greater than the actual execution time of the command. Because of the command execution queuing mechanism, slow query will lead to cascading blocking of other commands. Therefore, when the client requests timeout, it is necessary to check whether there is a corresponding slow query at this time point, so as to analyze whether it is the command cascading blocking caused by slow query.
In order to prevent the log from being lost when the get command is executed slowly, it is possible to store more than one log in the queue.
Pipeline
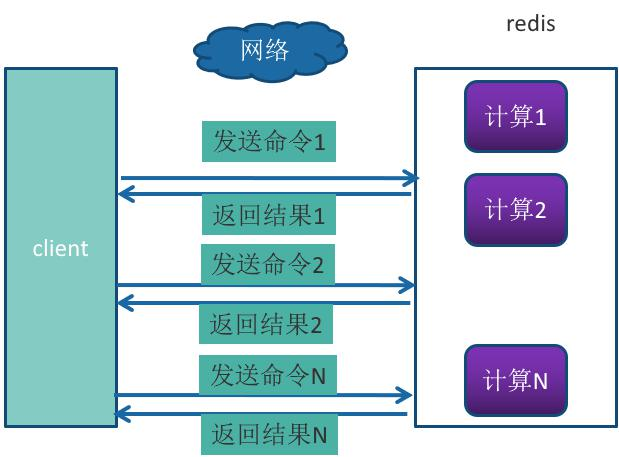
Redis provides batch operation commands (such as mget, mset, etc.) to effectively save RTT. However, most commands do not support batch operations. For example, if you want to execute the hgetall command n times, there is no mhgetall command, and you need to consume n times of RTT. Redis client and server may be deployed on different machines. For example, if the client is local and the redis server is in alicloud Guangzhou, the straight-line distance between the two places is about 800 km, then the time of one RTT = 800 x2 / (300000) × 2 / 3) = 8ms (the transmission speed of light in vacuum is 300000 kilometers per second. Here, it is assumed that the optical fiber is 2 / 3 of the speed of light). Then the client can only execute about 125 commands in one second, which runs counter to the high concurrency and high throughput characteristics of redis.
Pipeline mechanism can improve the above problems. It can assemble a group of Redis commands, transmit them to Redis through one RTT, and then return the execution results of this group of Redis commands to the client in order. N commands are executed without pipeline, and the whole process requires n RTTS.
Pipeline is used to execute commands n times, and the whole process requires one RTT.
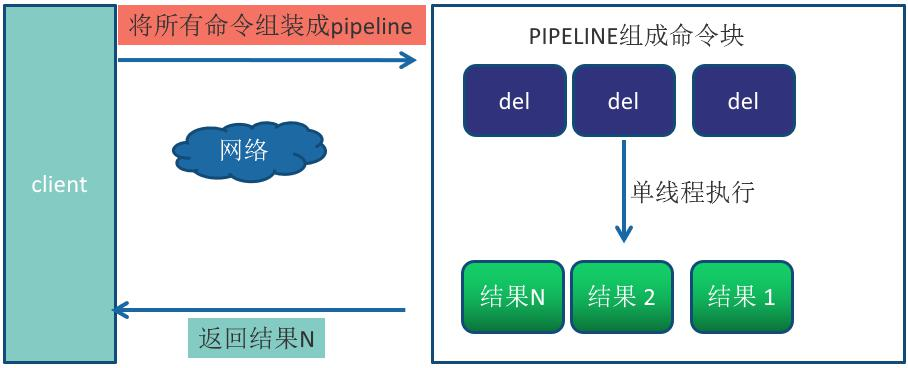
Pipeline is not a new technology or mechanism. It has been used in many technologies. Moreover, RTT will be different in different network environments. For example, the computer room and the same machine will be faster, and the cross computer room and cross region will be slower. The actual execution time of Redis commands is usually at the microsecond level, so there is a saying that the Redis performance bottleneck is the network.
The – pipe option of Redis cli actually uses the Pipeline mechanism, but in some cases, there will be more pipelines in Redis clients using Java language.
Code example
@Component
public class RedisPipeline {
@Autowired
private JedisPool jedisPool;
public List<Object> plGet(List<String> keys) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
Pipeline pipelined = jedis.pipelined();
for (String key : keys) {
pipelined.get(key);
}
return pipelined.syncAndReturnAll();
} catch (Exception e) {
throw new RuntimeException("implement Pipeline Acquisition failed!", e);
} finally {
jedis.close();
}
}
public void plSet(List<String> keys, List<String> values) {
if (keys.size() != values.size()) {
throw new RuntimeException("key and value The number does not match!");
}
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < keys.size(); i++) {
pipelined.set(keys.get(i), values.get(i));
}
pipelined.sync();
} catch (Exception e) {
throw new RuntimeException("implement Pipeline Setting failed!", e);
} finally {
jedis.close();
}
}
}
affair
Redis provides a simple transaction function, which places a group of commands to be executed together between multi and exec commands. multi(['m ʌ The lti]) command starts the transaction, Exec[ ɪɡˈ zek]) represents the end of the transaction. If you want to stop the execution of the transaction, you can use the discard command instead of the exec command.
The commands between them are executed in atomic order. For example, the following operations realize the above user concerns.
127.0.0.1:6379> multi OK 127.0.0.1:6379> sadd u:a:follow ub QUEUED 127.0.0.1:6379> sadd u:b:fans ua QUEUED 127.0.0.1:6379>
You can see that the return result of the sadd command is QUEUED, which means that the command is not actually executed, but is temporarily saved in a cache queue in Redis (so discard only discards the unexecuted commands in the cache queue and does not Rollback the operated data, which should be distinguished from the Rollback operation of relational databases). If another client executes sismember u:a:follow ub at this time, the returned result should be 0.
127.0.0.1:6379> sismember u:a:follow ub (integer) 0
Only after exec is executed can user A pay attention to the behavior of user B. as shown below, the two results returned by exec correspond to the sadd command.
127.0.0.1:6379> exec 1) (integer) 1 2) (integer) 1
Another client:
127.0.0.1:6379> sismember u:a:follow ub (integer) 1
If there is an error in the command in the transaction, Redis's processing mechanism is also different.
1 command error
For example, the following operation error writes set as set, which is a syntax error, which will make the whole transaction unable to execute, and the values of key and counter have not changed:
127.0.0.1:6379> sett txkey v (error) ERR unknown command `sett`, with args beginning with: `txkey`, `v`, 127.0.0.1:6379> incr txcount QUEUED 127.0.0.1:6379> exec (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379> mget txkey txcount 1) (nil) 2) (nil) 127.0.0.1:6379> 127.0.0.1:6379> unwatch ##You also need to perform unwatch OK
2 runtime error
For example, when adding a fan list, user B mistakenly wrote the sadd command into the zadd command, which is a runtime command because the syntax is correct:
127.0.0.1:6379> sadd u:c:follow ub QUEUED 127.0.0.1:6379> zadd u:b:fans 1 uc QUEUED 127.0.0.1:6379> exec 127.0.0.1:6379> ismember u:c:follow 1) (integer) 1
It can be seen that Redis does not support rollback. The sadd u:c:follow ub command has been executed successfully. Developers need to fix such problems themselves.
In some application scenarios, you need to ensure that the key in the transaction has not been modified by other clients before executing the transaction. Otherwise, it will not be executed (similar to optimistic locking). Redis provides the watch command to solve such problems.
Client 1:
127.0.0.1:6379> set testwatch redis OK 127.0.0.1:6379> watch testwatch OK 127.0.0.1:6379> mutil 127.0.0.1:6379> multi OK
Client 2:
127.0.0.1:6379> append testwatch java (integer) 9
Client 1 continues:
127.0.0.1:6379> append testwatch c++ QUEUED 127.0.0.1:6379> 127.0.0.1:6379> exec (nil) ## It's nil 127.0.0.1:6379> get testwatch "redisjava"
You can see that "client-1" executed the watch command before executing multi, and "client-2" modified the key value before "client-1" executed exec, resulting in no execution of client-1 transactions (the result of exec is nil).
For the transaction usage code in Redis client, see:
@Component
public class RedisTransaction {
public final static String RS_TRANS_NS = "rts:";
@Autowired
private JedisPool jedisPool;
public List<Object> transaction(String... watchKeys) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
if (watchKeys.length > 0) {
/*Using the watch function*/
String watchResult = jedis.watch(watchKeys);
if (!"OK".equals(watchResult)) {
throw new RuntimeException("implement watch fail:" + watchResult);
}
}
Transaction multi = jedis.multi();
multi.set(RS_TRANS_NS + "testa1", "a1");
multi.set(RS_TRANS_NS + "testa2", "a2");
multi.set(RS_TRANS_NS + "testa3", "a3");
List<Object> execResult = multi.exec();
if (execResult == null) {
throw new RuntimeException("The transaction cannot be executed. The monitored key Modified:" + Arrays.toString(watchKeys));
}
System.out.println(execResult);
return execResult;
} catch (Exception e) {
throw new RuntimeException("implement Redis Transaction failed!", e);
} finally {
if (watchKeys.length > 0) {
if (jedis != null) {
jedis.unwatch();/*If there is a watch in front, there must be an unwatch*/
}
}
if (jedis != null) {
jedis.close();
}
}
}
}
The difference between Pipeline and transaction
In short,
1. Pipeline is the behavior of the client and is transparent to the server. It can be considered that the server cannot distinguish whether the query command sent by the client is sent to the server in the form of ordinary command or pipeline;
2. The transaction is to realize the behavior on the server side. When the user executes the MULTI command, the server will set the client object corresponding to the user to a special state. In this state, the subsequent query commands executed by the user will not be actually executed, but will be cached by the server until the user executes the EXEC command, The server will execute the commands cached in the client object corresponding to the user in the order of submission.
3. Applying pipeline can improve the server's throughput and Redis's ability to process query requests. However, there is a problem here. When the query command data submitted through pipeline is small and can be accommodated by the kernel buffer, Redis can ensure the atomicity of these commands. However, once the amount of data exceeds the received size of the kernel buffer, the execution of the command will be interrupted and the atomicity cannot be guaranteed. Therefore, pipeline is only a mechanism to improve the server throughput. If you want commands to be executed atomically in a transactional manner, you still need a transaction mechanism, or use more advanced script functions and module functions.
4. Transaction and pipeline can be used together to reduce the transmission time of transaction commands on the network and reduce multiple network IO to one network io.
Redis provides simple transactions. The reason why it is simple is that it does not support rollback in transactions and cannot calculate the logical relationship between commands. Of course, it also reflects redis's "keep simple" feature. The Lua script introduced in the next section can also realize transaction related functions, but it is much more powerful.
Lua
Lua language was invented by a university research team in Brazil in 1993. Its design goal is to transplant it as an embedded program to other applications. It is implemented by C language. Although it is simple and small, it has powerful functions. Therefore, many applications choose it as a script language, especially in the field of games, Blizzard's "world of Warcraft", "angry birds", Nginx uses the Lua language as an extension. Redis uses Lua as a scripting language to help developers customize their own redis commands.
Redis version 2.6 supports Lua environment through embedded. In other words, Lua does not need to be installed separately for general application.
The benefits of using LUA scripts in Redis include:
1. Reduce network overhead. Multiple commands can be run in the same script in Lua script;
2. For atomic operation, Redis will execute the entire script as a whole without being inserted by other commands. In other words, there is no need to worry about race conditions during script writing;
3. Reusability. The script sent by the client will be stored in Redis, which means that other clients can reuse this pin to complete the same logic
Introduction to Lua
Installing Lua
Installation of Lua in linux
Go to the official website to download lua's tar GZ source package
wget http://www.lua.org/ftp/lua-5.3.6.tar.gz tar -zxvf lua-5.3.6.tar.gz
``wget http://www.lua.org/ftp/lua-5.3.6.tar.gz `
2,tar -zxvf lua-5.3.6.tar.gz
Enter the extracted Directory:
cd lua-5.3.6/ make linux make install (Need in root User under)
If an error is reported, it says that readLine / readLine cannot be found h. You can install it by using the yum command under the root user
yum -y install libtermcap-devel ncurses-devel libevent-devel readline-devel
make linux / make instal after installation
Finally, directly enter the lua command to enter the lua console:
[root@localhost lua-5.3.6]# lua Lua 5.3.6 Copyright (C) 1994-2020 Lua.org, PUC-Rio >
Lua basic grammar
Lua is very simple to learn. Of course, no matter how simple it is, it is also an independent language and has its own system. If you need to study Lua deeply in your work, you can refer to Lua programming, written by Roberto ierusalimschy.

Now we need: print("Hello World!")
> print("hello world!")
hello world!
Or write a lua script (exit the lua command window)
[root@localhost mylua]# vim hello.lua
print("hello world!")
[root@localhost mylua]# lua hello.lua
hello world!
notes
Two minus signs are single line comments: –
Multiline comment
--[[
Note content
Note content
--]]
Identifier
The Lua identifier is used to define a variable, and the function gets other user-defined items. The identifier is underlined with a letter A to Z or a to Z_ Add 0 or more letters, underscores and numbers (0 to 9) after the beginning.
It is better not to use the identifier of underline and uppercase letters, because some reserved words in Lua's language are the same.
Lua does not allow special characters such as @, $, and% to define identifiers. Lua is a case sensitive programming language. Therefore, Lua and Lua are two different identifiers in Lua.
key word
Lua's reserved keywords are listed below. Reserved keywords cannot be used as constants or variables or other user-defined identifiers:
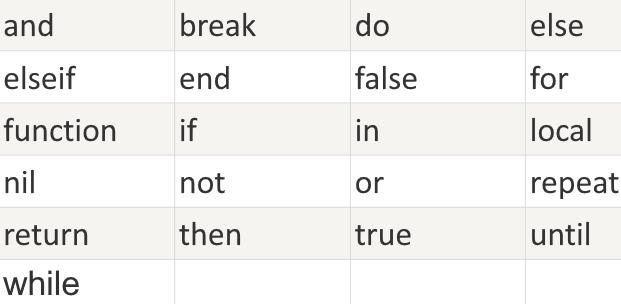
At the same time, it is a general convention that names starting with an underscore and connecting a string of uppercase letters (such as _VERSION) are reserved for Lua's internal global variables.
global variable
By default, variables are always considered global.
Global variables do not need to be declared. After assigning a value to a variable, the global variable is created. There will be no error accessing a global variable that is not initialized, but the result is nil.
> print(b) nil
If you want to delete a global variable, you only need to assign the variable nil. This makes the variable b seem to have never been used. In other words, a variable exists if and only if it is not equal to nil.
> b = 1234 > print(b) 1234 > b = nil
Data types in Lua
Lua is a dynamically typed language. Variables do not need type definitions, but only need to be assigned values. Values can be stored in variables, passed as parameters or returned as results.
There are eight basic types in Lua: nil, boolean, number, string, userdata, function, thread and table.
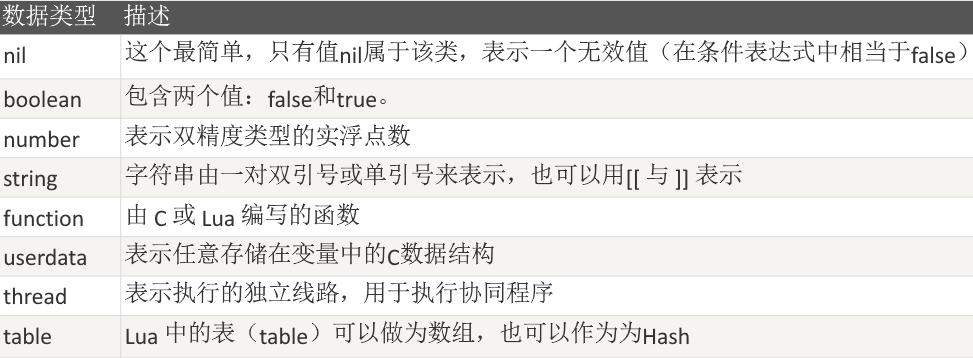
We can use the type function to test the type of a given variable or value.
> type([[lua]]) string > type(2) number
Functions in Lua
In Lua, the function starts with function and ends with end. funcName is the function name and the middle part is the function body:
function funcName ()
--[[Function content --]]
end
For example, define a string connection function:
function contact(str1,str2)
return str1..str2
end
print(contact("hello"," Mark"))
Lua variable
Before using a variable, you need to declare it in the code, that is, create the variable.
Before the compiler executes the code, the compiler needs to know how to open up a storage area for statement variables to store the value of variables.
Lua variables include global variables and local variables.
All variables in Lua are global variables, even in statement blocks or functions, unless explicitly declared as local variables with local. The scope of a local variable is from the declaration position to the end of the statement block.
The default value of variables is nil.
local local_var = 6
Control statements in Lua
Cycle control
Lua supports while loop, for loop, repeat... until loop and loop nesting. At the same time, Lua provides break statement and goto statement.
for loop
There are two types of for statements in Lua programming language: numeric for loop and generic for loop.
Numeric for loop
Syntax format of numeric for loop in Lua programming language:
for var=exp1,exp2,exp3 do <Executive body> end
var changes from exp1 to exp2, increment var in steps of exp3 each time, and execute the "actuator" once. exp3 is optional. If it is not specified, it defaults to 1.
Generic for loop
The generic for loop traverses all values through an iterator function, similar to the foreach statement in java. Generic for loop syntax format in Lua programming language:
– print all values of array a
a = {"one", "two", "three"}
for i, v in ipairs(a) do
print(i, v)
end
i is the array index value, and v is the array element value of the corresponding index. ipairs is an iterator function provided by Lua to iterate the array.
tbl3={age=18,name='mark'} -- This is an array,no"object"
for i, v in pairs(tbl3) do
print(i,v)
end
while loop
while(condition)
do
statements
end
a=10
while(a<20)
do
print("a= ",a) a=a+1
end
if conditional control
Lua supports if statements, if... else statements, and if nested statements.
if(Boolean expression) then
--[ The Boolean expression is true Statement executed when --]
end
if(Boolean expression) then
--[ Boolean expression is true Execute the statement block when --]
else
--[ Boolean expression is false Execute the statement block when --]
end
Lua operator
Arithmetic operator
+Addition
-Subtraction
*Multiplication
/Division
%Surplus
^Power
-Minus sign
Relational operator
==Equals
~=Not equal to
>Greater than
< less than
>=Greater than or equal to
< = less than or equal to
Logical operator
and
Logic and operators
or
Logical or operator
not
Logical Negation Operator
explain:
When lua splices strings –, "a" + 1 will fail because a will be converted into a number for operation
Lua other features
Lua supports modules and packages, that is, encapsulation libraries, metatables, coroutines, file IO operations, error handling, code debugging, Lua garbage collection, object-oriented and database access. For more details, please refer to the corresponding books.
Java support for Lua
At present, in the Java ecosystem, LuaJ is the support for Lua. It is a Java Lua interpreter based on Lua 5.2 X version.
maven coordinates
<dependency>
<groupId>org.luaj</groupId>
<artifactId>luaj-jse</artifactId>
<version>3.0.1</version>
</dependency>
Reference code
Lua function
public class LuaFunctions {
public static void main(String[] args) throws Exception {
LuaFunctions luaFunctions = new LuaFunctions();
String luaFileName = luaFunctions.getClass()
.getClassLoader()
.getResource("func.lua")
.toURI()
.getPath();
Globals globals = JsePlatform.standardGlobals();
LuaValue luaObj = globals.loadfile(luaFileName).call();
/*Call the parameterless lua function*/
LuaValue helloSimple = globals.get(LuaValue.valueOf("helloSimple"));
helloSimple.call();
//System.out.println("result---"+result);
/*Call lua function with return and no parameters*/
LuaValue hello = luaObj.get(LuaValue.valueOf("hello"));
String result2 = hello.call().toString();
System.out.println("result2---" + result2);
/*Call the lua function that returns a lua object*/
LuaValue getObj = luaObj.get(LuaValue.valueOf("getObj"));
LuaValue hTable = getObj.call();
//Parse the returned table. Here, get the parameters one by one according to the format
String userId = hTable.get("userId").toString();
LuaTable servicesTable = (LuaTable) CoerceLuaToJava.coerce(hTable.get("services"), LuaTable.class);
List<String> servciesList = new ArrayList<>();
for (int i = 1; i <= servicesTable.length(); i++) {
int length = servicesTable.get(i).length();
StringBuilder service = new StringBuilder();
for (int j = 1; j <= length; j++) {
service.append("-" + servicesTable.get(i).get(j).toString());
}
servciesList.add(service.toString());
}
System.out.println("getObj-userId:" + userId);
System.out.println("getObj-servcies:" + servciesList);
/*Pass in a java object to the lua function*/
LuaValue readObj = luaObj.get(LuaValue.valueOf("readObj"));
LuaValue luaValue = new LuaTable();
luaValue.set("userId", "11111");
String userIdIn = readObj.invoke(luaValue).toString();
System.out.println("readObj-userIdIn:" + userIdIn);
}
}
Test code
public class TestLuaJ {
public static void main(String[] args) {
String luaStr = "print 'hello,world!'";
Globals globals = JsePlatform.standardGlobals();
LuaValue chunk = globals.load(luaStr);
chunk.call();
}
}
Lua in Redis
eval command
Command format
EVAL script numkeys key [key ...] arg [arg ...]
Command description
1) Script parameter: it is a Lua script program, which will be run in the context of Redis server. This script does not need (and should not) be defined as a Lua function.
2) numkeys parameter: used to specify the number of key name parameters.
3) key [key...] parameters: from the third parameter of EVAL, numkeys are used to represent the Redis KEYS used in the script. These key name parameters can be accessed in Lua through the global variable KEYS array with 1 as the base address (KEYS[1],KEYS[2] ·).
4) arg [arg...] parameter: it can be accessed through the global variable ARGV array in Lua in a form similar to the KEYS variable (ARGV[1],ARGV[2] ··).
Example
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
In this example, the role of key [key...] is not obvious. Actually, its biggest role is to facilitate our calling Redis commands in Lua scripts.
Invoke Redis command in Lua script
Mainly remember the call() command:
eval "return redis.call('mset',KEYS[1],ARGV[1],KEYS[2],ARGV[2])" 2 key1 key2 first second
eval "return redis.call('set',KEYS[1],ARGV[1])" 1 key1 newfirst
evalsha command
However, the eval command requires you to send the script every time you execute the script, so Redis has an internal cache mechanism, so it will not recompile the script every time. However, in many cases, paying unnecessary bandwidth to transmit the script body is not the best choice.
In order to reduce bandwidth consumption, Redis provides the evalsha command. Like EVAL, it is used to evaluate the script, but the first parameter it accepts is not the script, but the SHA1 summary of the script.
Here you need to use the script command.
script flush: clear all script caches.
Script exists: checks whether the specified script exists in the script cache according to the given script verification.
script load: loads a script into the script cache and returns the SHA1 summary, but does not run it immediately.
script kill: kill the currently running script
The SCRIPT LOAD command here can be used to generate the SHA1 summary of the script
script load "return redis.call('set',KEYS[1],ARGV[1])"
Redis cli execution script
You can use the Redis cli command to execute the script directly. Here, we directly create a Lua script file to obtain the value of key1 just saved in Redis, VIM Redis Lua, and then write the Lua command:
test.lua
local value = redis.call('get','key1')
return value
Then execute
./redis-cli -p 6880 --eval .../scripts/test.lua
it's fine too
./redis-cli -p 6880 script load "$(cat .../scripts/test.lua)"
But you can't load script files directly from the redis command prompt
The Java client uses Lua scripts
One current limiting function based on redis:
/*A current limiting function based on redis*/
@Component
public class RedisLua {
public final static String RS_LUA_NS = "rlilf:";
/*For the first time, incr is used to add one to the KEY (an IP is used as the KEY). If it is the first access,
Use expire to set a timeout, which is passed in as the first parameter of Value,
If the number of increments is greater than the second Value parameter entered, a failure flag is returned; otherwise, it succeeds.
redis When the timeout period of the Key expires, the Key disappears and can be accessed again
local num = redis.call('incr', KEYS[1])
if tonumber(num) == 1 then
redis.call('expire', KEYS[1], ARGV[1])
return 1
elseif tonumber(num) > tonumber(ARGV[2]) then
return 0
else
return 1
end
* */
public final static String LUA_SCRIPTS =
"local num = redis.call('incr', KEYS[1])\n" +
"if tonumber(num) == 1 then\n" +
"\tredis.call('expire', KEYS[1], ARGV[1])\n" +
"\treturn 1\n" +
"elseif tonumber(num) > tonumber(ARGV[2]) then\n" +
"\treturn 0\n" +
"else \n" +
"\treturn 1\n" +
"end";
@Autowired
private JedisPool jedisPool;
public String loadScripts(){
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
String sha =jedis.scriptLoad(LUA_SCRIPTS);
return sha;
} catch (Exception e) {
throw new RuntimeException("Failed to load script!",e);
} finally {
jedis.close();
}
}
public String ipLimitFlow(String ip){
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
String result = jedis.evalsha("9ac7623ae2435baf9ebf3ef4d21cde13de60e85c",
Arrays.asList(RS_LUA_NS+ip),Arrays.asList("60","2")).toString();
return result;
} catch (Exception e) {
throw new RuntimeException("Failed to execute script!",e);
} finally {
jedis.close();
}
}
}
Publish And Subscribe
Redis provides a message mechanism based on the publish / subscribe mode. In this mode, the message publisher and subscriber do not communicate directly. The publisher client publishes messages to the specified channel, and each client subscribing to the channel can receive the message.
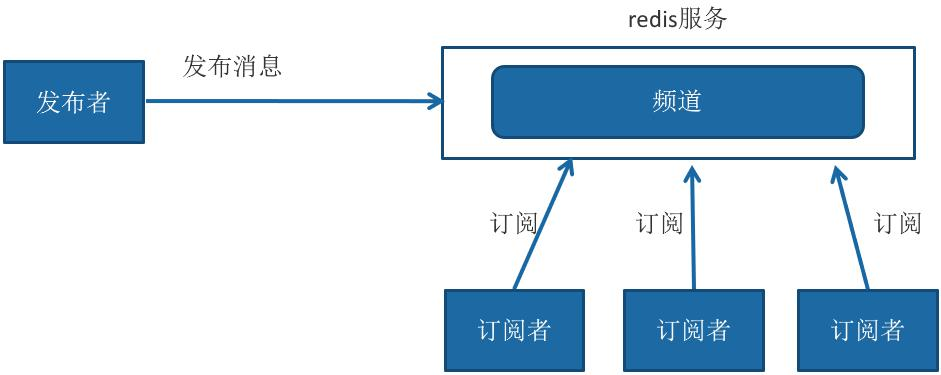
Operation command
Redis mainly provides commands such as publishing messages, subscribing to channels, unsubscribing, and subscribing and unsubscribing according to the mode.
Release news
publish channel message
Subscription message
subscribe channel [channel ...]
Subscribers can subscribe to one or more channels. If another client publishes a message at this time, the current subscriber client will receive the message.
If multiple clients subscribe to the same channel at the same time, they will receive a message.
There are two points to note about subscription commands:
After executing the subscription command, the client enters the subscription state and can only receive four commands: subscribe, psubscribe,unsubscribe and punsubscribe.
Unsubscribe
unsubscribe [channel [channel ...]]
The client can unsubscribe from the specified channel through the unsubscribe command. After the unsubscribe is successful, the client will not receive the publication message of the channel.
Subscribe and unsubscribe by mode
psubscribe pattern [pattern. ...]
punsubscribe [pattern [pattern ...]]
This p is not publish, but pattern
In addition to subscribe and unsubscribe commands, Redis also supports glob e style subscription commands psubscribe and unsubscribe commands punsubscribe,
Query subscription
View active channels
pubsub channels [pattern]
The Pubsub command is used to view the subscription and publishing system status, including active channels (which means that the current channel has at least one subscriber), where [pattern] can specify a specific mode
View channel subscriptions
pubsub numsub channel
View mode subscriptions
pubsub numpat
Usage scenarios and disadvantages
Publish subscribe mode can be used where message decoupling is required and message reliability is not concerned.
The producer of PubSub sends a message, and Redis will directly find the corresponding consumer to send it. If there is no consumer, the message is discarded directly. If there are three consumers at the beginning, one consumer suddenly hangs up, the producer will continue to send messages, and the other two consumers can continue to receive messages. However, when the suspended consumer reconnects, the message sent by the producer during the disconnection is completely lost to the consumer.
Therefore, compared with many professional message queuing systems (such as Kafka and RocketMQ), Redis's publish and subscribe is very rough, for example, it can't realize message accumulation and backtracking. But the victory is simple enough. If the current scene can tolerate these shortcomings, it is a good choice.
Because PubSub has these shortcomings, its application scenario is actually very narrow. From Redis5 0 adds a Stream data structure, which brings a persistent message queue to Redis
Redis Stream
Redis5. The biggest new feature of 0 is an additional data structure Stream, which is a new and powerful persistent message queue supporting multicast. The author states that Redis Stream draws lessons from Kafka's design.
Stream overview
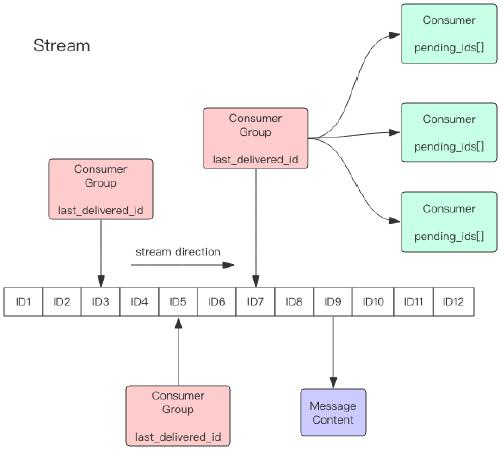
The structure of Redis Stream is shown in the figure above * *. Each Stream has a message linked list, which links all added messages * *, and each message has a unique ID and corresponding content. The message is persistent. After Redis is restarted, the content is still there.
Each Stream has a unique name, which is the Redis key. It is automatically created when we first use the xadd instruction to append messages.
Each Stream can have multiple consumption groups, and each consumption group will have a cursor last_delivered_id moves forward on the Stream array to indicate which message has been consumed by the current consumption group. Each consumption group has a unique name in the Stream. The consumption group will not be created automatically. It needs a separate instruction xgroup create to create it. It needs to specify a message ID of the Stream to start consumption. This ID is used to initialize last_delivered_id variable.
`The status of each consumer group is independent and unaffected by each other. That is to say, the messages inside the same Stream will be consumed by each consumption group.
The same consumer group can be connected to multiple consumers. These consumers are competitive. Any consumer reading the message will make the cursor last_delivered_id moves forward. Each consumer has a unique name within the group.
There will be a status variable pending inside the consumer_ IDS, which records messages that have been read by the client but have not been ack. If the client does not have an ACK, there will be more and more message IDS in this variable. Once a message is acked, it will begin to decrease. This pending_ The IDS variable is officially called PEL in Redis, that is, Pending Entries List. It is a very core data structure. It is used to ensure that the client consumes the message at least once and will not lose the unprocessed message in the middle of network transmission.
The message ID is in the form of timestampinmillis sequence, such as 1527846880572-5. It indicates that the current message is generated at the millimeter timestamp 1527846880572, and it is the fifth message generated within this millisecond. The message ID can be automatically generated by the server or specified by the client itself, but the form must be integer integer, and the ID of the later added message must be greater than the previous message ID.
The message content is a key value pair, such as a key value pair of hash structure, which is nothing special.
Common operation commands
Production end
xadd append message
xdel deletes the message. The deletion here only sets the flag bit and will not actually delete the message.
xrange gets the message list and automatically filters the deleted messages
xlen message length
del delete Stream
xadd streamtest * name mark age 18
127.0.0.1:6379> xadd streamtest * name xx age 18 "1641020605232-0" 127.0.0.1:6379> xadd streamtest * name oo age 18 "1641020610921-0" # Second addition
*The number indicates that the server automatically generates an ID, followed by a bunch of key / values
1626705954593-0 is the generated message ID, which consists of two parts: timestamp sequence number. The time stamp is in milliseconds. It is the Redis server time that generates the message. It is a 64 bit integer. The sequence number is the sequence number of the message within this millisecond time point. It is also a 64 bit integer.
In order to ensure that the messages are orderly, * * therefore, the IDs generated by Redis are monotonically increasing and orderly** Because the ID contains a timestamp, in order to avoid problems caused by server time errors (for example, the server time is delayed), Redis maintains a latest for each Stream type data_ generated_ ID attribute, used to record the ID of the last message. If it is found that the current timestamp is backward (less than that recorded by the latest_generated_id), the scheme of constant timestamp and increasing sequence number is adopted as the new message ID (this is why int64 is used for sequence number to ensure that there are enough sequence numbers), so as to ensure the monotonic increasing nature of ID.
It is strongly recommended to use Redis scheme to generate message ID, because this monotonic increasing ID scheme of timestamp + sequence number can meet almost all your needs. However, ID supports customization.
xrange streamtest - +
127.0.0.1:6379> xrange streamtest - +
Where - represents the minimum value and + represents the maximum value
Or we can specify a list of message ID S:
xrange streamtest - 1641020610921-0
127.0.0.1:6379> xrange streamtest - 1641020610921-0 127.0.0.1:6379> xrange streamtest 1641020605232-0 +
xdel streamtest 1641020610921-0
xlen streamtest
127.0.0.1:6379> xlen streamtest (integer) 2 127.0.0.1:6379> xdel streamtest 1641020610921-0 # Delete single id (integer) 1
del streamtest deletes the entire Stream
127.0.0.1:6379> del streamtest (integer) 1
Consumer end
Single consumer
Although the Stream has the concept of consumer group, it can consume Stream messages independently without defining consumer group. When there is no new message in the Stream, it can even block waiting. Redis has designed a separate consumption instruction xread, which can use Stream as an ordinary message queue (list). When using xread, we can completely ignore the existence of consumer group, just like a Stream is an ordinary list.
xread count 1 streams stream2 0-0
Indicates that 1 message is read from the Stream header. 0-0 refers to starting from scratch
xread count 2 streams stream2 1626710882927-0
You can also specify to start with the message Id of streams (excluding the message Id in the command)
xread count 1 streams stream2 $
$stands for reading from the tail, which means reading the latest message from the tail. At this time, no message is returned by default
The latest message at the tail should be read in a blocking manner until a new message arrives
xread block 0 count 1 streams stream2 $
The number after block represents the blocking time, in milliseconds
Generally speaking, if the client wants to use xread for sequential consumption, it must remember where the current consumption is, that is, the returned message ID. The next time you continue to call xread, pass in the last message ID returned last time as a parameter, and you can continue to consume subsequent messages.
Consumer group
Create consumption group
Stream creates a consumer group through the xgroup create instruction. It needs to pass the start message ID parameter to initialize last_delivered_id variable.
xgroup create stream2 cg1 0-0 It means spending from scratch
xgroup create stream2 cg2 $ $ It means that consumption starts from the tail and only new messages are accepted. Currently Stream All messages are ignored
Now we can use the xinfo command to see the situation of stream2:
xinfo stream stream2 xinfo groups stream2
Message consumption
With a consumer group, consumers are naturally required. Stream provides xreadgroup instruction to consume within the consumer group. It needs to provide consumer group name, consumer name and start message ID.
Like xread, it can also block waiting for new messages. After reading the new message, the corresponding message ID will enter the consumer's PEL (message being processed) structure. After the client completes processing, it will use the xack instruction to notify the server that this message has been processed, and the message ID will be removed from the PEL.
xreadgroup GROUP cg1 c1 count 1 streams stream2 >
The > sign indicates the last from the current consumption group_ delivered_ Start reading after ID. every time the consumer reads a message, last_ delivered_ The ID variable will advance
Then set blocking wait
xreadgroup GROUP cg1 c1 block 0 count 1 streams stream2 >
If there are multiple consumers in the same consumer group, we can also observe the status of each consumer through the xinfo consumers command
xinfo consumers stream2 cg1
We confirm a message
xack stream2 cg1 1626751586744-0 # xack allows multiple message IDs
Message queue based on pub/sub
/**
* Implementation of message oriented middleware based on PUBSUB
*/
@Component
public class PSVer extends JedisPubSub {
public final static String RS_PS_MQ_NS = "rpsm:";
@Autowired
private JedisPool jedisPool;
@Override
public void onMessage(String channel, String message) {
System.out.println("Accept " + channel + " message:" + message);
}
@Override
public void onSubscribe(String channel, int subscribedChannels) {
System.out.println("Subscribe " + channel + " count:" + subscribedChannels);
}
public void pub(String channel, String message) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.publish(RS_PS_MQ_NS + channel, message);
System.out.println("Post message to" + RS_PS_MQ_NS + channel + " message=" + message);
} catch (Exception e) {
throw new RuntimeException("Failed to publish message!");
}
}
public void sub(String... channels) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.subscribe(this, channels);
} catch (Exception e) {
throw new RuntimeException("Failed to subscribe to channel!");
}
}
}
test case
@SpringBootTest
public class TestPSVer {
@Autowired
private PSVer psVer;
@Test
void testSub(){
psVer.sub(PSVer.RS_PS_MQ_NS+"psmq", PSVer.RS_PS_MQ_NS+"psmq2");
}
@Test
void testPub(){
psVer.pub("psmq","msgtest");
psVer.pub("psmq2","msgtest2");
}
}
Stream based message queue
/**
* Realize group consumption, regardless of single consumer mode
*/
@Component
public class StreamVer {
public final static String RS_STREAM_MQ_NS = "rsm:";
public final static int MQ_INFO_CONSUMER = 1;
public final static int MQ_INFO_GROUP = 2;
public final static int MQ_INFO_STREAM = 0;
@Autowired
private JedisPool jedisPool;
/**
* Publish message to Stream
*/
public StreamEntryID produce(String key, Map<String, String> message) {
try (Jedis jedis = jedisPool.getResource()) {
StreamEntryID id = jedis.xadd(RS_STREAM_MQ_NS + key, StreamEntryID.NEW_ENTRY, message);
System.out.println("Post message to" + RS_STREAM_MQ_NS + key + " Return message id=" + id.toString());
return id;
} catch (Exception e) {
throw new RuntimeException("Failed to publish message!");
}
}
/**
* Create a consumer group. Consumer groups cannot be created repeatedly
*/
public void createCustomGroup(String key, String groupName, String lastDeliveredId) {
Jedis jedis = null;
try {
StreamEntryID id;
if (lastDeliveredId == null) {
lastDeliveredId = "0-0";
}
id = new StreamEntryID(lastDeliveredId);
jedis = jedisPool.getResource();
/*makeStream Indicates whether to automatically create a stream when there is no stream, but if there is, automatic creation will cause an exception*/
jedis.xgroupCreate(RS_STREAM_MQ_NS + key, groupName, id, false);
System.out.println("Consumer group created successfully:" + groupName);
} catch (Exception e) {
throw new RuntimeException("Failed to create consumer group!", e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
/**
* Message consumption
*/
public List<Map.Entry<String, List<StreamEntry>>> consume(String key, String customerName, String groupName) {
try (Jedis jedis = jedisPool.getResource()) {
/*Parameters for message consumption*/
XReadGroupParams xReadGroupParams = new XReadGroupParams().block(0).count(1);
Map<String, StreamEntryID> streams = new HashMap<>();
streams.put(RS_STREAM_MQ_NS + key, StreamEntryID.UNRECEIVED_ENTRY);
List<Map.Entry<String, List<StreamEntry>>> result
= jedis.xreadGroup(groupName, customerName, xReadGroupParams, streams);
System.out.println(groupName + "from" + RS_STREAM_MQ_NS + key + "Accept message, Return message:" + result);
return result;
} catch (Exception e) {
throw new RuntimeException("Message consumption failed!", e);
}
}
/**
* Message confirmation
*/
public void ackMsg(String key, String groupName, StreamEntryID msgId) {
if (msgId == null) {
throw new RuntimeException("msgId Empty!");
}
try (Jedis jedis = jedisPool.getResource()) {
System.out.println(jedis.xack(key, groupName, msgId));
System.out.println(RS_STREAM_MQ_NS + key + ",Consumer group" + groupName + " Message confirmed");
} catch (Exception e) {
throw new RuntimeException("Message confirmation failed!", e);
}
}
/*
Check whether the consumer group exists, auxiliary methods
* */
public boolean checkGroup(String key, String groupName) {
try (Jedis jedis = jedisPool.getResource()) {
List<StreamGroupInfo> xinfoGroupResult = jedis.xinfoGroup(RS_STREAM_MQ_NS + key);
for (StreamGroupInfo groupinfo : xinfoGroupResult) {
if (groupName.equals(groupinfo.getName())) {
return true;
}
}
return false;
} catch (Exception e) {
throw new RuntimeException("Failed to check consumer group!", e);
}
}
/**
* Message queue information viewing
*/
public void MqInfo(int type, String key, String groupName) {
try (Jedis jedis = jedisPool.getResource()) {
if (type == MQ_INFO_CONSUMER) {
List<StreamConsumersInfo> xinfoConsumersResult = jedis.xinfoConsumers(RS_STREAM_MQ_NS + key, groupName);
System.out.println(RS_STREAM_MQ_NS + key + " Consumer information:" + xinfoConsumersResult);
for (StreamConsumersInfo consumersinfo : xinfoConsumersResult) {
System.out.println("-ConsumerInfo:" + consumersinfo.getConsumerInfo());
System.out.println("--Name:" + consumersinfo.getName());
System.out.println("--Pending:" + consumersinfo.getPending());
System.out.println("--Idle:" + consumersinfo.getIdle());
}
} else if (type == MQ_INFO_GROUP) {
List<StreamGroupInfo> xinfoGroupResult = jedis.xinfoGroup(RS_STREAM_MQ_NS + key);
System.out.println(RS_STREAM_MQ_NS + key + "Consumer group information:" + xinfoGroupResult);
for (StreamGroupInfo groupinfo : xinfoGroupResult) {
System.out.println("-GroupInfo:" + groupinfo.getGroupInfo());
System.out.println("--Name:" + groupinfo.getName());
System.out.println("--Consumers:" + groupinfo.getConsumers());
System.out.println("--Pending:" + groupinfo.getPending());
System.out.println("--LastDeliveredId:" + groupinfo.getLastDeliveredId());
}
} else {
StreamInfo xinfoStreamResult = jedis.xinfoStream(RS_STREAM_MQ_NS + key);
System.out.println(RS_STREAM_MQ_NS + key + "Queue information:" + xinfoStreamResult);
System.out.println("-StreamInfo:" + xinfoStreamResult.getStreamInfo());
System.out.println("--Length:" + xinfoStreamResult.getLength());
System.out.println("--RadixTreeKeys:" + xinfoStreamResult.getRadixTreeKeys());
System.out.println("--RadixTreeNodes():" + xinfoStreamResult.getRadixTreeNodes());
System.out.println("--Groups:" + xinfoStreamResult.getGroups());
System.out.println("--LastGeneratedId:" + xinfoStreamResult.getLastGeneratedId());
System.out.println("--FirstEntry:" + xinfoStreamResult.getFirstEntry());
System.out.println("--LastEntry:" + xinfoStreamResult.getLastEntry());
}
} catch (Exception e) {
throw new RuntimeException("Message queue information retrieval failed!", e);
}
}
}
test case
@SpringBootTest
public class TestStreamVer {
@Autowired
private StreamVer streamVer;
private final static String KEY_NAME = "testStream";
private final static String GROUP_NAME = "testgroup";
@Test
void testProduce(){
Map<String,String> message = new HashMap<>();
message.put("name","Mark");
message.put("age","18");
streamVer.produce(KEY_NAME,new HashMap<>(message));
streamVer.MqInfo(StreamVer.MQ_INFO_STREAM,KEY_NAME,null);
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,null);
}
@Test
void testConsumer(){
if (!streamVer.checkGroup(KEY_NAME,GROUP_NAME)){
streamVer.createCustomGroup(KEY_NAME,GROUP_NAME,null);
}
List<Map.Entry<String, List<StreamEntry>>> results = streamVer.consume(KEY_NAME,"testUser",GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_CONSUMER,KEY_NAME,GROUP_NAME);
for(Map.Entry<String, List<StreamEntry>> result:results ){
for(StreamEntry entry:result.getValue()){
streamVer.ackMsg(KEY_NAME,GROUP_NAME,entry.getID());
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_CONSUMER,KEY_NAME,GROUP_NAME);
}
}
}
@Test
void testAck(){
streamVer.ackMsg(KEY_NAME,GROUP_NAME,null);
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_CONSUMER,KEY_NAME,GROUP_NAME);
}
}
Summary of several message queue implementations
Implementation of LPUSH+BRPOP based on List
Simple enough, the consumption message latency is almost zero, but it needs to deal with the problem of idle connections.
If the thread is always blocked there, the connection of Redis client will become an idle connection. If it is idle for too long, the server will generally take the initiative to disconnect and reduce the occupation of idle resources. At this time, blpop and brpop or throw exceptions. Therefore, be careful when writing client consumers. If exceptions are caught, try again.
Other disadvantages include:
It is troublesome to confirm the ACK of the consumer, which can not guarantee whether the consumer can successfully handle the problem after consuming the message (downtime or handling exceptions, etc.). Generally, it is necessary to maintain a Pending list to ensure the confirmation of message processing; Broadcast mode cannot be used, such as pub/sub, message publishing / subscription model; It cannot be consumed repeatedly. Once consumed, it will be deleted; Group consumption is not supported.
Implementation based on sorted set
It is mostly used to implement delay queues. Of course, it can also implement ordered ordinary message queues. However, consumers can not block the acquisition of messages. They can only poll and are not allowed to repeat messages.
PUB/SUB, subscription / publish mode
advantage:
In a typical broadcast mode, a message can be published to multiple consumers; Multi channel subscription, consumers can subscribe to multiple channels at the same time to receive multiple types of messages; The message is sent instantly. The message does not need to wait for the consumer to read. The consumer will automatically receive the message published by the channel.
Disadvantages:
Once the message is published, it cannot be received. In other words, if the client is not online during publishing, the message will be lost and cannot be retrieved; There is no guarantee that the receiving time of each consumer is consistent; If the consumer client has message backlog, to a certain extent, * * will be forcibly disconnected, resulting in accidental loss of messages** It usually occurs when the production of messages is much faster than the consumption speed; It can be seen that the Pub/Sub mode is not suitable for message storage and message backlog, but is good at handling broadcasting, instant messaging and instant feedback.
Message queuing problem
Our use of Stream above shows that Stream already has the basic elements of a message queue, such as producer API, consumer API, message Broker, message confirmation mechanism, etc. Therefore, problems arising from the use of message middleware will also be encountered here.
What if there are too many Stream messages?
If too many messages are accumulated, isn't the linked list of Stream very long and the content will explode? The xdel instruction does not delete the message, it just makes a flag bit for the message.
Redis naturally takes this into account, so it provides a fixed length Stream function. The xadd instruction provides a fixed length maxlen, which can kill the old message and ensure that it does not exceed the specified length at most.
What happens if you forget the ACK message?
Stream stores the message ID list PEL being processed in each consumer structure. If the consumer receives the message and processes it but does not reply to ack, the PEL list will continue to grow. If there are many consumer groups, the memory occupied by this PEL will be increased. Therefore, the news should be consumed and confirmed as quickly as possible.
How does PEL avoid message loss?
When the client consumer reads the Stream message, when the * * Redis server replies the message to the client, the client suddenly disconnects and the message is lost** However, the message ID sent has been saved in PEL. After the client is reconnected, the message ID list in PEL can be received again. However, at this time, the starting message ID of xreadgroup cannot be the parameter >, but must be any valid message ID. generally, the parameter is set to 0-0, indicating that all PEL messages and self last messages are read_ delivered_ New message after ID.
Bad faith problem
If a message cannot be processed by consumers, that is, it cannot be XACK, * * it needs to be in the Pending list for a long time, even if it is repeatedly transferred to each consumer** At this time, the delivery counter of the message (which can be queried through XPENDING) will be accumulated. When it is accumulated to a preset critical value, we will consider it as bad news (also known as dead letter, DeadLetter, undeliverable message). Due to the judgment conditions, we can dispose of the bad news and delete it. To delete a message, use XDEL syntax. Note that this command does not delete the message in Pending. Therefore, when viewing Pending, the message will still be. After XDEL is executed, XACK this message indicates that it has been processed.
High availability of Stream
The high availability of Stream is based on master-slave replication. It is no different from the replication mechanism of other data structures, that is, Stream can support high availability in Sentinel and Cluster environments. However, since the instruction replication of Redis is asynchronous, when a failover occurs, Redis may lose a small part of data, which is the same as other data structures of Redis.
Partition
Redis servers do not have native partitioning capabilities. If you want to use partitions, you need to allocate multiple streams, and then use certain policies on the client to produce messages to different streams.
Stream summary
The consumption model of Stream draws lessons from Kafka's concept of consumption grouping, which makes up for the defect that Redis Pub/Sub cannot persist messages. But it is different from Kafka. Kafka's messages can be divided into partition s, but Stream can't. If you have to divide parities, you have to do it on the client, provide different Stream names, and hash the message to select which Stream to insert.
Therefore, in general, if Redis has been used in the work, the Stream function of Redis can be considered when the business volume is not large and the message middleware function is required. However, if the concurrency is high, it is better to support the business with professional message middleware, such as RocketMQ and Kafka.
Persistence
Although Redis is an in memory database, it supports RDB and AOF persistence mechanisms to write data to disk, which can effectively avoid the problem of data loss caused by process exit. Data recovery can be realized by using the previously persistent files when restarting next time.
RDB (Redis Database)
RDB persistence is the process of saving the snapshot generated by the current process data to the hard disk. The process of triggering RDB persistence is divided into manual trigger and automatic trigger.
Trigger mechanism
Manually trigger the corresponding save and bgsave commands:
* * save command: * * block the current Redis server until the RDB process is completed. Instances with large memory will be blocked for a long time. It is not recommended for online environments.
* * bgsave command: * * the Redis process performs a fork operation to create a child process. The RDB persistence process is the responsibility of the child process and ends automatically after completion. Blocking only occurs in the fork phase, usually for a short time.
Obviously, the bgsave command is optimized for the save blocking problem. Therefore, all RDB related operations in Redis adopt bgsave.
In addition to manual triggering by executing commands, Redis also has a persistence mechanism that automatically triggers RDB,
For example, the following scenarios:
1) use save related configuration * *, such as "save m n". Indicates that bgsave is automatically triggered when the dataset is modified n times within m seconds**
2) if the slave node performs full copy, the master node automatically executes bgsave to generate RDB files and send them to the slave node.
3) when you execute the debug reload command to reload Redis, the save operation will also be triggered automatically.
4) by default, when executing the shutdown command, if the AOF persistence function is not enabled, bgsave will be executed automatically.
bgsave execution process
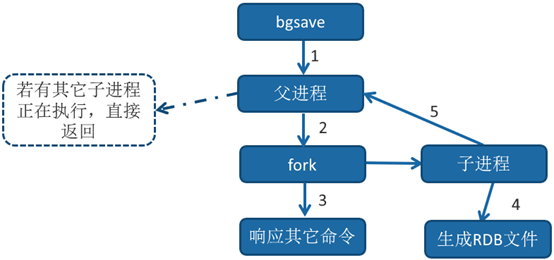
-
Execute the bgsave command. Redis parent process judges whether there are currently executing child processes. For example, RDB/AOF child processes exist, and the bgsave command returns directly.
-
The parent process performs a fork operation to create a child process. During the fork operation, the parent process will block. View the latest through the info stats command_ fork_ With the USEC option, you can obtain the time-consuming of the latest fork operation, in microseconds.
- After the parent process fork is completed, the bgsave command returns the "Background saving started" information and no longer blocks the parent process. You can continue to respond to other commands.
-
The child process creates an RDB file, generates a temporary snapshot file according to the memory of the parent process, and atomically replaces the original file after completion. Execute the lastsave command to obtain the last generation time of RDB, corresponding to the RDB of info statistics_ last_ save_ Time option.
-
The process sends a signal to the parent process to indicate completion. The parent process updates the statistical information. See rdb under info Persistence for details_* Related options.
127.0.0.1:6379> info Persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1641024206
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:2478080
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
RDB file
RDB files are saved in the directory specified by dir configuration, and the file name is specified by dbfilename configuration. It can be dynamically executed during the run-time by executing config set dir {newDir} and config set dbfilename (newFileName}. The RDB file will be saved to the new directory when running next time.
Redis uses LZF algorithm to compress the generated RDB files by default. The compressed files are far smaller than the memory size. They are enabled by default and can be dynamically modified through the parameter config set rdbcompression {yes | no}.
Although compressing RDB will consume CPU, it can greatly reduce the volume of files, * * it is convenient to save to the hard disk or send to the slave node through the network dimension, * * therefore, it is recommended to start online.
If Redis refuses to start when loading damaged RDB files, it will print the following log:
# Short read or 0OM loading DB. Unrecoverable error,aborting now.
At this time, you can use the Redis check dump tool provided by Redis to detect the RDB file and obtain the corresponding error report.
Advantages and disadvantages of RDB
Advantages of RDB
RDB is a compact compressed binary file, which represents the data snapshot of Redis at a certain point in time. It is very suitable for backup, full replication and other scenarios.
For example, bgsave backups are performed every few hours, and RDB files are copied to a remote machine or file system (such as hdfs) for disaster recovery.
Redis loads RDB to recover data much faster than AOF.
Disadvantages of RDB
RDB data cannot be persisted in real time / second level. Because every time bgsave runs, it needs to perform a fork operation to create a child process, which is a heavyweight operation, and the cost of frequent execution is too high.
RDB files are saved in a specific binary format. During the evolution of Redis version, there are RDB versions in multiple formats. There is a problem that the old version of Redis service cannot be compatible with the new version of RDB format.
Redis provides AOF persistence to solve the problem that RDB is not suitable for real-time persistence.
AOF (Append Only File)
AOF(append only file) persistence: record each write command in the form of an independent log, and re execute the commands in the AOF file when restarting to recover data. The main function of AOF is to solve the real-time of data persistence. At present, AOF has become the mainstream way of Redis persistence. Understanding and mastering AOF persistence mechanism is very helpful for us to take into account data security and performance.
Use AOF
To enable the AOF function, you need to set the configuration: appendonly yes, which is not enabled by default. The AOF file name is set through the appendfilename configuration. The default file name is appendonly aof. The save path is consistent with the RDB persistence mode and is specified through dir configuration. Aof workflow operations: append, sync, rewrite, and load.
technological process

- All write commands are appended to AOF_ BUF (buffer).
- The AOF buffer performs synchronization operations to the hard disk according to the corresponding policies.
- With the increasing size of AOF files, AOF files need to be rewritten regularly to achieve the purpose of compression.
- When the Redis server restarts, the AOF file can be loaded for data recovery. After understanding the AOF workflow, each step is described in detail below.
Command write
The content written by the AOF command is directly in the RESP text protocol format. For example, the command set hello world will append the following text to the AOF buffer:
* 3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n
1) why does AOF directly adopt text protocol format?
* * text protocol has good compatibility** After AOF is enabled, all write commands include append operations, which directly adopts the protocol format to avoid secondary processing overhead. The text protocol is readable and convenient for direct modification and processing.
2) Why does AOF append commands to AOF_ In buf? (therefore, a certain synchronization cannot be guaranteed)
Redis uses a single thread to respond to commands. If the command to write AOF files is directly appended to the hard disk every time, the performance depends entirely on the current hard disk load. Write buffer AOF first_ Another advantage of buf is that redis can provide a variety of buffer synchronization strategies for hard disks to balance performance and security.
Redis provides a variety of AOF buffer synchronization file policies, which are controlled by the parameter appendfsync.
# appendfsync always appendfsync everysec # appendfsync no
always
Command write AOF_ After buf, the system fsync operation is synchronized to the AOF file. After fsync completes, the thread returns the command fsync synchronization file.
everysec
Write AOF_ After buf, the system write operation is invoked and the thread is returned after write completes. The fsync command is invoked once per second by a dedicated thread (the default).
no
Write AOF_ After buf, the system write operation is invoked, fsync synchronization is not performed on AOF files, and synchronous disk operation is responsible for operating system. The longest synchronization period is 30 seconds.
TIPS: system call write and fsync * * description
*The write operation triggers the delayed write mechanism. Linux provides a page buffer in the kernel to improve the IO performance of the hard disk. The write * * operation returns directly after writing to the system buffer. Synchronous hard disk operation depends on the system scheduling mechanism, for example: * * the buffer page space is full or reaches a specific time period. Before synchronizing files, if the system fails and goes down at this time, the data in the * buffer will be lost.
** * after the hard disk is blocked (for example, fsync is forced to write data to a single hard disk) until fsync is completed.
Obviously, when it is configured as always, the AOF file must be synchronized every time it is written. On ordinary SATA hard disks, Redis can only support about hundreds of TPS writes, which obviously runs counter to Redis's high-performance features and is not recommended.
Configured as no, because the operating system can not control the period of synchronizing AOF files each time, and it will increase the amount of data synchronized to the hard disk each time, although the performance is improved, the data security cannot be guaranteed.
It is configured as everysec, which is the recommended synchronization policy and the default configuration to achieve both performance and data security. In theory, only when the system suddenly goes down can one second of data be lost. (strictly speaking, lose up to 1 second of data)
rewrite mechanism
As commands are constantly written to AOF, the file will become larger and larger. In order to solve this problem, Redis introduces AOF rewriting mechanism to compress the file volume. Aof file rewriting is the process of converting data in Redis process into write commands and synchronizing them to a new AOF file.
Why can the rewritten AOF file become smaller? There are the following reasons:
1) the data that has timed out in the process will not be written to the file.
2) * * the old AOF file contains invalid commands, * * such as set a 111, set a 222, etc. Rewriting is generated directly using in-process data, so that the new AOF file only retains the write command of the final data.
3) multiple write commands can be combined into one. For example, lpush list a, lpush list b and lpush listc can be transformed into lpush list a, B and C. In order to prevent the client buffer overflow caused by too large a single command, the list, set, hash, zset and other types of operations are divided into multiple operations bounded by 64 elements.
Aof rewriting reduces the file space. In addition, another purpose is that smaller AOF files can be loaded by Redis faster.
AOF rewriting process can be triggered manually and automatically:
Manual trigger: directly call bgrewriteaof command.
Auto trigger: determine the auto trigger timing according to auto AOF rewrite min size and auto AOF rewrite percentage parameters.
Auto AOF rewrite min size: indicates the minimum file size when AOF rewriting is run. The default is 64MB.
Auto AOF rewrite percentage: represents the ratio of the current AOF file space (aof_currentsize) to the AOF file space (aof_base_size) after the last rewrite.
What is done internally when an AOF override is triggered?
Process Description:
1) Execute AOF rewrite request.
If the current process is performing AOF rewriting, the request will not be executed and the following response will be returned:
ERR Background append only file rewriting already in progress
If the current process is executing bgsave, the rewrite command is delayed until bgsave is completed, and the following response is returned:
Background append only file rewriting scheduled
2) The parent process fork s to create a child process, and the cost is equivalent to the bgsave process.
3.1) after the fork operation of the main process is completed, continue to respond to other commands. All modification commands are still written to the AOF buffer and synchronized to the hard disk according to the appendfsync policy to ensure the correctness of the original AOF mechanism.
3.2) because the fork operation uses write time replication technology, the child process can only share the memory data during the fork operation. Because the parent process still responds to the command, Redis uses "AOF rewrite buffer" to save this part of new data to prevent this part of data from being lost during the generation of new AOF files.
4) The child process writes to the new AOF file according to the memory snapshot and the command merge rules. The amount of data written to the hard disk in batch each time is controlled by the configuration AOF rewrite incremental fsync. The default is 32MB to prevent the hard disk from blocking due to too much data in a single disk brushing.
5.1) after the new aof file is written, the child process sends a signal to the parent process, and the parent process updates the statistical information. See aof under info persistence for details_* Relevant statistics.
5.2) the parent process writes the data of AOF rewrite buffer to the new AOF file.
5.3) replace the old file with the new AOF file to complete AOF rewriting.
Restart loading
Both AOF and RDB files can be used for data recovery when the server is restarted. What is the order of loading AOF and RDB when redis restarts?
1. When AOF and RDB files exist at the same time, AOF will be loaded first
2. If AOF is closed, load RDB file
3. AOF/RDB is loaded successfully, and redis is restarted successfully
4. There is an error in AOF/RDB, the startup fails, and the error message is printed
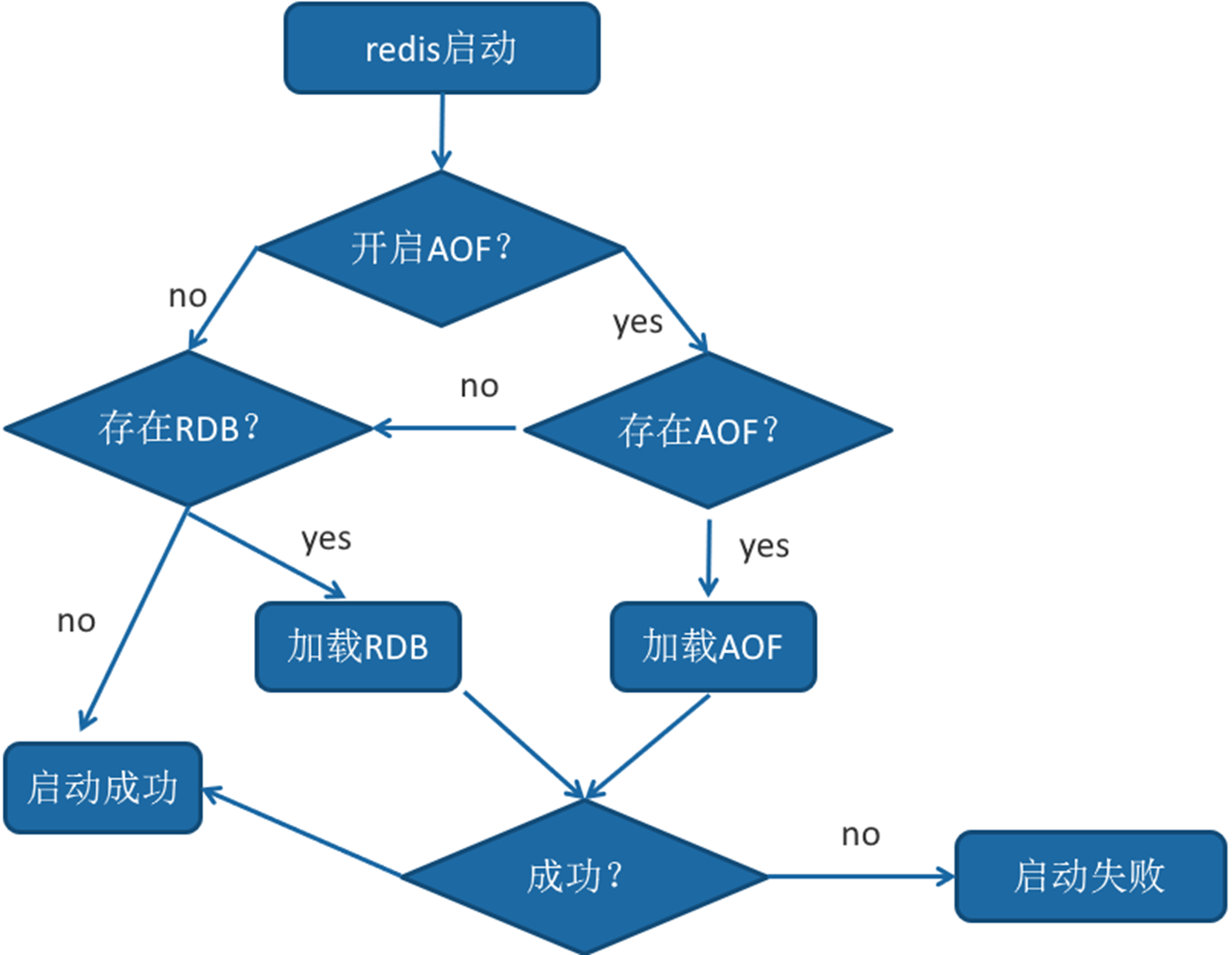
File verification
When loading damaged AOF files, it will refuse to start. For AOF files with wrong format, first backup them, and then use the redis check AOF -- fix command to repair them. Compare the data differences and find out the missing data. Some can be modified and completed manually.
The end of the AOF file may be incomplete. For example, the machine suddenly loses power, resulting in incomplete writing of the AOF tail file command. Redis provides us with AOF load truncated configuration to be compatible with this situation. It is enabled by default. This problem is ignored when AOF is started and continues to be encountered.
Persistence problem
fork operation
When Redis rewrites RDB or AOF, * * an essential operation is to perform the fork operation to create sub processes. For most operating systems, fork is a heavyweight operation** Although the child process created by fork does not need to copy the physical memory space of the parent process, it will copy the memory page table of the parent process. For example, for a 10GB Redis process, about 20MB of memory page table needs to be copied, so the fork operation time is closely related to the total memory of the process. If virtualization technology, especially Xen virtual machine, is used, the fork operation will be more time-consuming.
Positioning of fork time-consuming problem: for Redis instances with high traffic, OPS can reach more than 50000. If the fork operation takes seconds, it will slow down the execution of tens of thousands of Redis commands, which has a significant impact on the delay of online applications. Under normal circumstances, the fork time should be about 20 milliseconds per GB. You can check latest in info stats statistics_ fork_ The USEC indicator obtains the time-consuming of the last fork operation, in microseconds.
OPS: operation per second
How to improve the time consumption of fork operation:
1) Give priority to physical machines or virtualization technologies that efficiently support fork operations
2) Control the maximum available memory of Redis instances. The fork time is proportional to the amount of memory. It is recommended that the memory of each Redis instance be controlled within 10GB online.
- Reduce the frequency of fork operation, such as appropriately relaxing the automatic trigger timing of AOF, avoiding unnecessary full replication, etc.
scan
Redis provides two commands to traverse all keys: keys and scan.
keys
Used to traverse the key, the usage is very simple
keys pattern
Traverse all the keys. You can directly use the asterisk for pattern. Pattern uses glob style wildcards:
*Represents matching any character.
? Represents matching a character.
[] represents matching part of characters. For example, [1,3] represents matching 1,3, [1-10] represents matching any number from 1 to 10.
\x is used for escape. For example, to match asterisks and question marks, escape is required.
For example, match all keys starting with u and V, followed by:, and then any string:
keys [u,v]😗
However, considering the single thread architecture of Redis, it is not so wonderful. If Redis contains a large number of keys, executing the keys command is likely to cause Redis blocking. Therefore, it is generally recommended not to use the keys command in the production environment. But sometimes there is a need to traverse keys. What should I do? It can be used in the following three cases:
It is executed on a Redis slave node that does not provide external services, which will not block the request to the client, but will affect the master-slave replication. We will introduce the master-slave replication in detail in Chapter 6.
If you confirm that the total number of key values is indeed small, you can execute the scan command. Using scan command to incrementally traverse all keys can effectively prevent blocking.
scan
Redis has provided a new command scan since version 2.8, which can effectively solve the problems of the keys command. Unlike the keys command, which traverses all keys during execution, scan uses progressive traversal to solve the possible blocking problem caused by the keys command, but to truly realize the function of keys, you need to execute scan many times. Imagine scanning only a part of the keys in a dictionary until all the keys in the dictionary are traversed. Scan is used as follows:
scan cursor [match pattern] [count number]
Cursor is a required parameter. In fact, cursor is a cursor. The first traversal starts from 0. After each scan traversal, the value of the current cursor will be returned until the cursor value is 0, indicating the end of traversal.
Match pattern is an optional parameter. It is used for pattern matching, which is very similar to the pattern matching of keys.
Count number is an optional parameter. It indicates the number of keys to traverse each time. The default value is 10. This parameter can be increased appropriately.
In addition to scan, Redis provides scan traversal commands for hash type, collection type and ordered collection to solve the possible blocking problems such as hgetall, SMEs and zrange. The corresponding commands are hscan, sscan and zscan respectively. Their usage is basically similar to scan. Please refer to the official website of Redis.
Incremental traversal can effectively solve the possible blocking problem of keys command, but scan is not perfect. If there are key changes (addition, deletion and modification) in the process of scan, the traversal effect may encounter the following problems: the newly added keys may not be traversed, and repeated keys may be traversed, In other words, scan does not guarantee that all keys can be traversed completely, which we need to consider when developing.
Key migration
Sometimes we only want to migrate part of the data from one Redis to another (for example, from the production environment to the test environment). In the development process of Redis, we provide three groups of migration keys: move, dump +restore and migrate. Their implementation methods and use scenarios are different, which are introduced below.
move
move key db
The move command is used for data migration in Redis. There can be multiple databases in Redis. Here, you only need to know that there can be multiple databases in Redis, which are isolated from each other in data. move key db is to move the specified key from the source database to the target database, but the multi database function is not recommended to be used in the production environment, so this command can be known.
dump + restore
dump key restore key ttl value
dump + restore enables data migration between different Redis instances. The whole migration process is divided into two steps:
1) On the source Redis, the dump command will serialize the key values in RDB format.
2) On the target Redis, the restore command restores the above serialized values. The ttl parameter represents the expiration time. If ttl=0, there is no expiration time.
There are two points to note about dump + restore: first, the whole migration process is not atomic, but completed step by step through the client. Second, the migration process opens two client connections, so the result of dump is not transmitted between the source Redis and the target Redis.
migrate
migrate host port key |"" destination-db timeout [copy] [replace] [keys key [key ...]]
The migrate command is also used to migrate data between Redis instances. In fact, the migrate command combines dump, restore, and del to simplify the operation process. The migrate command is atomic and supports the function of migrating multiple keys since Redis version 3.0.6, which effectively improves the migration efficiency. Migrate plays an important role in horizontal capacity expansion.
The whole process is basically similar to dump + restore, but there are three differences:
First, the whole process is executed atomically. You don't need to open the client on multiple Redis instances. You just need to execute the migrate command on the source Redis.
Second, the data transmission of the migrate command is completed directly on the source Redis and the target Redis.
Third, after the target Redis completes the restore, it will send OK to the source Redis. After receiving it, the source Redis will decide whether to delete the corresponding key on the source Redis according to the corresponding options of migrate.
The following describes the parameters of migrate one by one:
host: the IP address of the target Redis.
Port: the port of the target Redis.
keyl "": before redis version 3.0.6, migrate only supported the migration of one key, so this is the key to be migrated, but after redis version 3.0.6, it supports the migration of multiple keys. If multiple keys need to be migrated at present, this is an empty string "".
Destination DB: the database index of the target Redis. For example, to migrate to database 0, write 0 here.
Timeout: the timeout (in milliseconds) of the migration.
[replace]: if this option is added, migrate will migrate normally and overwrite data regardless of whether the key exists in the target Redis.
[keys [key...]: to migrate multiple keys, for example, to migrate key1, key2, and key3, fill in "keys key1, key2, and key3" here.
Now let's assume that there are two Redis. The lower source Redis uses port 6379 and the target Redis uses port 6380. Now we want to migrate the key hello of the source Redis to the target Redis, which can be divided into the following situations:
Case 1: the source Redis has the key hello * *, but the target Redis * * * * does not:**
migrate 127.0.0.1 6380 hello 0 1000OK
Case 2: both source Redis and target Redis * * * * have keys hello:
If the replace option is not added to the migrate command, you will receive an error prompt. If the replace option is added, you will return OK, indicating that the migration is successful.
Case 3: the source Redis does not have the key hello * *. As shown below, * * in this case, you will receive a prompt from nokey
Case 4: the source Redis executes the following command to complete the migration of multiple keys
migrate 127.0.0.1 6380 "" 0 5000 keys key1 key2 key3
Redis-benchmark
Redis benchmark can perform benchmark performance test for redis. It provides many options to help developers and operation and maintenance personnel test redis related performance. These options are described below.
1.-c
-c (clients)Option represents the number of concurrent clients (the default is 50)).
2.-n
-n (num)Option represents the total number of client requests (the default is 100 000) ).
For example, redis benchmark - C 100 - N 20000 represents 100 clients requesting redis at the same time, which is executed 20000 times in total. Redis benchmark will test commands of various data structures and give performance indicators: