1, Foreword
Hello, everyone. I'm an old watch. When I looked at station B this morning, I found that the home page pushed me a video of an up master (@ it's me it's me it's me, for the convenience of the small one in the following), so I opened it and watched it, so I had the next story ~
@Screenshot use has been approved
What Xiaoshi wants to achieve is a task given by the teacher: read txt files and store them in mysql. Just two days ago, Xiaoshi helped the reader write an excel to sqlserver software. In addition, Xiaoshi said two problems in the current java version:
- Only string type data can be read (this is not understood. It may be reading file format or file field type)
- Dynamic modification of read file and database configuration is not supported (writing a gui or simply writing a terminal logic program directly is also acceptable)
I thought, I can, and then first provided ideas to occupy a pit, and then came my implementation code.

2, Start thinking
All source code + environment + test files of this project have been open source. If you don't want to see the code implementation process, you can directly skip to the next part of the direct eating method.
2.0 environmental preparation
What I use here is:
- python 3.10
- Third party packages and corresponding versions:
pandas==1.3.5 PyMySQL==1.0.2 SQLAlchemy==1.4.30 PySimpleGUI==4.56.0
To facilitate project environment management, I usually use pipenv to create and manage virtual environment. If you are also interested, you can see what I wrote before pipenv basic tutorial.
pipenv install # Create virtual environment pipenv shell # Enter virtual environment pip install pandas PyMySQL SQLAlchemy PySimpleGUI # Install required packages in virtual environment exit # Exit the virtual environment and close cmd directly
2.1 data reading
Looking at the sample data, we found that there are two kinds of separators, space and tab \ t, so we also need to specify two kinds of separators when reading data. In addition, this file has no header, so it is convenient for data processing and storage. It is best to add a header, which is consistent with the database field name.

The following code:
import pandas as pd
'''
read_csv Parameter interpretation:
1,File path to read
2,sep Specify separator, read data, use|You can add multiple separators
3,header=None If there is no header, the first row header will be used by default
4,engine Setup engine
'''
data = pd.read_csv('./resources/ctd2020-09-27.txt', sep=' |\t',header=None, engine='python')
data
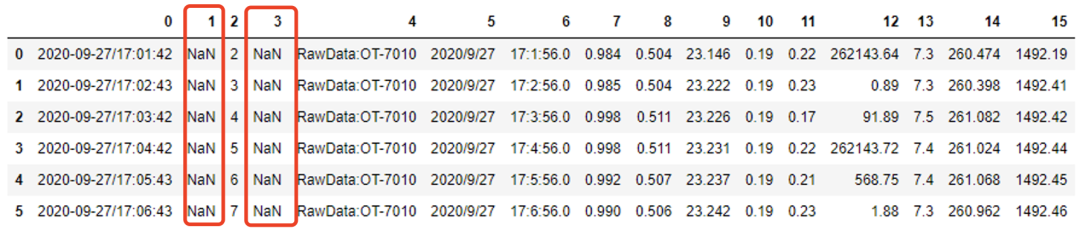
It is not difficult to see that there will be two columns of nan in this direct reading, because there are two spaces separated. It doesn't matter. We can delete the column whose whole column is nan. After the data is read correctly, we add the header, and the implementation code is as follows:
# read file
def get_txt_data(filepath):
columns = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N']
data = pd.read_csv(filepath, sep=' |\t',header=None,engine='python')
# Delete all nan columns of data (if there is such a column, it can be added later without affecting)
data.dropna(axis=1, how='all', inplace=True)
# Specify column name
data.columns = columns
return data
get_txt_data('./resources/ctd2020-09-27.txt')
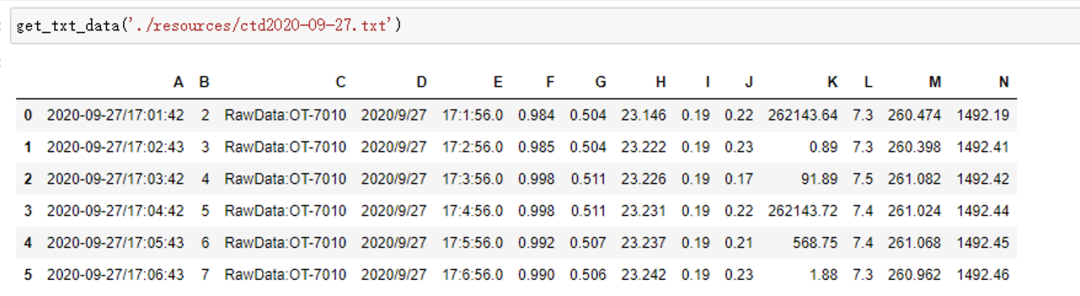
2.2 data processing
Because the small does not indicate what data processing will occur (except for the data reading obstacles above), we will simply delete the duplicate columns here. The next shared Excel to SQL server will involve some data processing (such as de duplication according to the specified field, date format transformation, etc.)
# data processing
def process_data(data):
# If it does not contain the columns to be processed, it will be directly and simply de duplicated and stored in the database
data.drop_duplicates(inplace=True)
return data
2.3 data storage
Because we want to store the data in mysql, we need to connect to the database before storage. Here I use sqlalchemy+pymysql to link to the MySQL database. The code is as follows:
# Linked database
def link_mysql(user, password, database):
# create_engine("database type + database driver: / / database user name: database password @ IP address: port / database", other parameters)
engine = create_engine(f'mysql+pymysql://{user}:{password}@localhost:3306/{database}?charset=utf8')
return engine
Then use pandas's to_sql function can simply and quickly store data in Dataframe format into the database. Those interested can see what I wrote earlier Python data storage and reading, 6000 words, various methods , there is a comparison between using pymysql directly and using pandas to_ The rate of data stored in SQL is different, and the description is not necessarily accurate. Please read and correct.
# Store data
def data_to_sql(data, user='root', password='Zjh!1997', database='sql_study', table='ctd'):
engine = link_mysql(user, password, database)
# To call pandas_ SQL store data
t1 = time.time() # Timestamp in seconds
print('Data insertion start time:{0}'.format(t1))
# First parameter: table name
# Second parameter: database connection engine
# Third parameter: store index
# The fourth parameter: append data if the table exists
data.to_sql(table, engine, index=False, if_exists='append')
t2 = time.time() # Timestamp in seconds
print('Data insertion end time:{0}'.format(t2))
print('Successfully inserted data%d Article,'%len(data), 'Time consuming:%.5f Seconds.'%(t2-t1))
Finally, we can write a summary function to connect the above logic here:
# The text file is stored in mysql
def txt_to_sql(filepath, user='root', password='Zjh!1997', database='sql_study', table='ctd'):
# read file
data = get_txt_data(filepath)
# data processing
data = process_data(data)
# data storage
data_to_sql(data, user, password, database, table)
2.4 calling function test
filepath = './resources/ctd2020-09-27.txt' # Only specify the file path, and use the default values for other parameters to facilitate testing txt_to_sql(filepath)
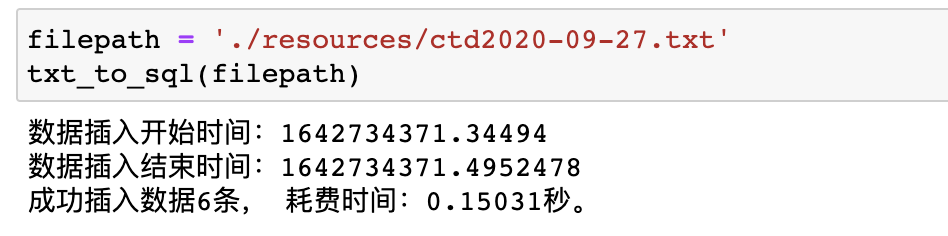
Then you can write a database reading function to further test whether the data is really stored in the database:
# Read data from database
def read_mysql(user='root', password='Zjh!1997', database='sql_study', table='ctd'):
engine = link_mysql(user, password, database)
# Read sql statements
sql = f'select * from {table} limit 3'
# First parameter: query sql statement
# The second parameter: engine, database connection engine
pd_read_sql = pd.read_sql(sql, engine)
return pd_read_sql
Call the function and check the storage. No problem.

Here, even if the program function part is completed, the next step is to write a gui interface to make it more convenient for users to use, such as file path, database parameter input, etc.
2.5 write a GUI
Here we use the PySimpleGUI package. As the name says, it's really simple. Its bottom layer is the tkinter provided by Python.
- Import related packages
# Write a GUI import PySimpleGUI as sg # Call data store function from txt_to_sql import txt_to_sql
- Write GUI layout
# Set GUI layout
# Related parameter key: the key to receive the input data. Target: the corresponding data is displayed to the specified target
# default_text: sets the default value of the input box
layout = [
[sg.Text('Read the contents of the specified file and store it in the specified database table after processing~')],
[sg.FileBrowse('Click to select a file', key='filepath', target='file'), sg.Text(key='file')],
[sg.Text('Login user name'), sg.InputText(key='user', default_text='root', )],
[sg.Text('Login password'), sg.InputText(key='password', default_text='Zjh!1997')],
[sg.Text('Database name'), sg.InputText(key='database', default_text='sql_study')],
[sg.Text('Stored table name'), sg.InputText(key='table', default_text='ctd')],
[sg.Button('Start processing'), sg.Button('sign out')]
]
- Create program window and business logic
# Create window program
window = sg.Window('Txt To MySQL', layout, default_element_size=(100,))
while True:
event, values = window.read() # get data
# print(event)
if event=='Start processing':
# Pass input data into data handler
txt_to_sql(values['filepath'], values['user'], values['password'], values['database'], values['table'])
else:
# event in (None, 'sign out'): # Click exit to close the program
break
window.close()
- Display effect
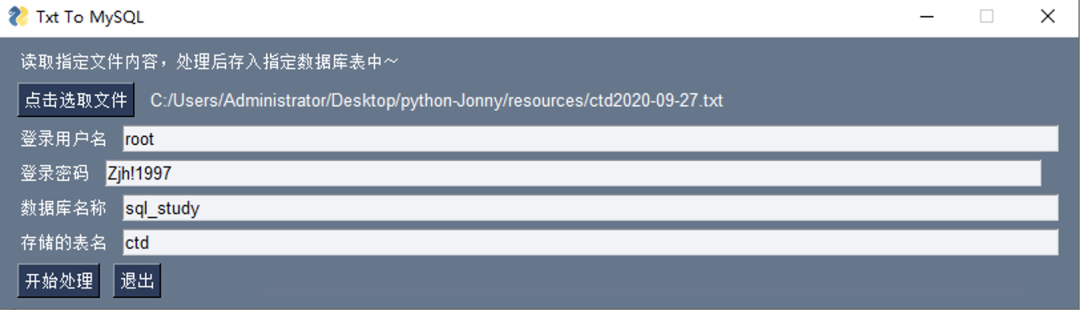
In the layout part, layout is a list data, and each element in the list is also a list, representing a column. The commonly used layout modules are: Text (shown in this paper), InputText (input box), Button (ordinary Button), FileBrowse (single file selection);
In the part of creating window program, it is mainly to set the default window size default_element_size, just set the width, and the height will be adaptive according to the layout control. In addition, it is very simple to obtain the input value. Just read it directly, and the dictionary is returned, which is more convenient for data processing.
Here, we will complete the development of all programs, followed by the method of using programs directly.
3, Direct edible method
Two code files, excluding spaces and comments, and 51 lines of code, hey ~

3.1 functions
- GUI interface, which supports selecting specified files, entering database user name and password, database name and table name.

- Read the specified file and store the data in the specified database table after data processing. If the table does not exist, directly create a new table to store data; Otherwise, add the data directly to the data table.
3.2 application method
Download the project code: https://github.com/XksA-me/txt-to-mysql
After decompression, open the file: python Jonny. This file contains all python code + test data + environment + windows bat running files. Other files are @ txt to mysql method written in Java and related configuration files,
Original project address: https://github.com/schatz0-0/txt-to-mysql Video sharing address of station B of the original project: https://www.bilibili.com/video/BV12b4y1J7pD
Continue to introduce how to use the python version. First, we need to unzip the python environment package provided by me and unzip it directly without secondary installation.
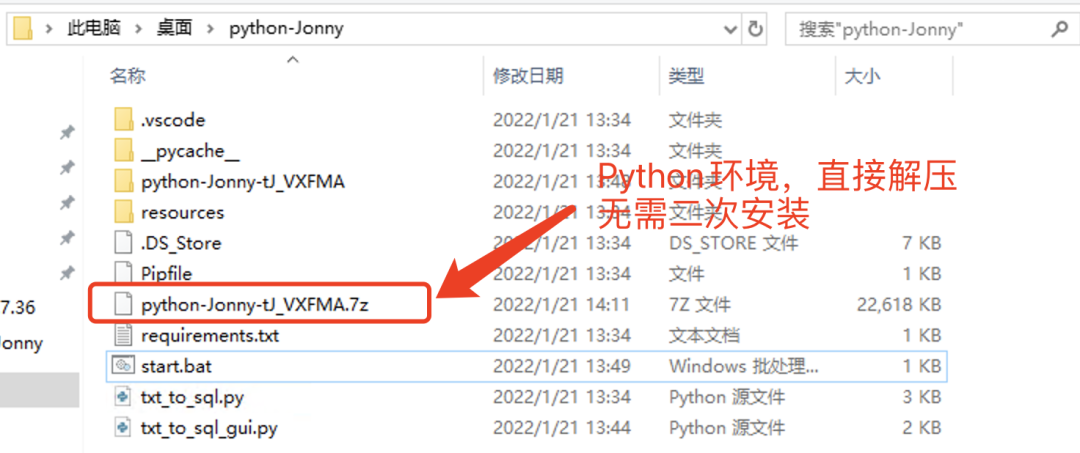
Explanation of relevant documents in the screenshot above:
├── Pipfile Virtual environment profile (not managed) ├── Pipfile.lock Virtual environment dependency package relationship (regardless) ├── __pycache__ ((leave it alone) │ └── txt_to_sql.cpython-310.pyc ((leave it alone) ├── python-Jonny-tJ_VXFMA.7z (Compressed package of virtual environment, which needs to be decompressed directly) ├── requirements.txt (The third party required by the project Python Packages have been installed in the given virtual environment) ├── resources ((test data) │ └── ctd2020-09-27.txt ├── start.bat (windwos (you can directly run the file and start the project) ├── txt_to_sql.py (Python Code file, including data reading, processing and storage) └── txt_to_sql_gui.py (Python Code file, including gui Interface, call in it txt_to_sql.py File, so just run this file)
After the virtual environment is decompressed, we need to modify start according to our local directory Bat file, as follows:
@echo off C: cd C:\Users\Administrator\Desktop\python-Jonny C:\Users\Administrator\Desktop\python-Jonny\python-Jonny-tJ_VXFMA\Scripts\python txt_to_sql_gui.py exit
I don't know this very well. I'm learning and selling it now. The general meaning of the above is: enter the project directory of Disk c, then use the python executable file in the virtual environment to run the code I can, and finally exit the program.
What you need to modify is the file directory involved, which can be consistent with your local. I wrote it on the ECS and put it on Disk c (there is only one disk). You can choose to put it on other disks for management.
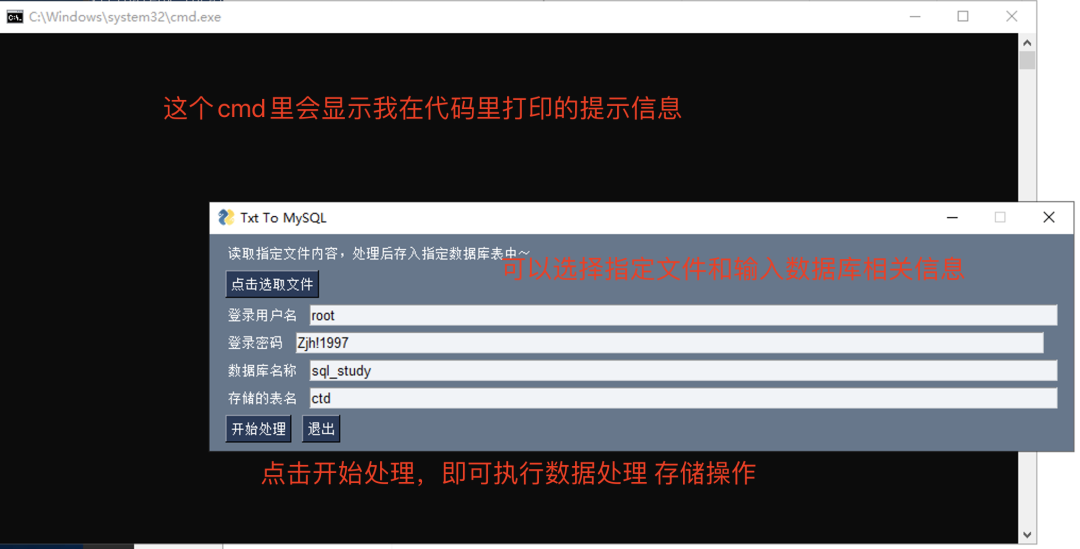
After modification, click start Bat to run the project, and a black box (cmd) and gui program interface will pop up. In the black box, the log of program execution output (that is, the print or error message in the program) will be displayed. In gui, we need to click the button to select the stored file, then enter the relevant information of the database, set the default value, and then click the start processing button to run the program Store the data and click the exit button to close the program.
4, Can expand
- At present, only txt is supported, and the data format is the specified type (separated by space or tab). If you have time and need, you can expand to support multiple format files and add a file suffix to identify them
- The interface is simple. I saw up@ it in the morning_ It's me_ It's the video I sent. I thought it's convenient to write in python. The time is short and the interface is relatively general. However, as for tools, it's important to realize functions at the beginning.
This project has many shortcomings and can be improved. Welcome to learn and exchange ~

Today's recording + simple editing, and tomorrow's video explanation.