Solution for automatic update of Chinese word segmentation full-text index in NEO4J
- 1. Sample data
- 2. Differences between English and Chinese Full-Text Indexes
- 3. APOC has its own English full-text indexing process (indexing can be updated automatically)
- 4. Custom Chinese word segmentation full-text index plug-in (unsuccessful automatic index update)
- V. Label Cross-search
- 6. Custom Chinese Word Segmentation Plugin (Failed to Update Indexes Independently of Nodes)
- 1. Add Full-Text Index
- 2. Add Nodes and Attributes and Update Full-Text Index
- 3. Add 2 new nodes or updated attributes to the index
- 4. Retrieval
- 7. Resolve Transaction Submission Timeout
Failed to implement automatic updates using the NEO4J INDEX API, converting a way of thinking to solve this problem (synchronizing updates to the corresponding full-text index when updating a node or creating a new one.)
1. Sample data
2. Differences between English and Chinese Full-Text Indexes
1. Create NEO4J default index
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]})
// The following retrieval was unsuccessful: CALL apoc.index.search('Loc', 'Loc.description:Chinese~') YIELD node RETURN node CALL apoc.index.search('Loc', 'Loc.description:Chinese*') YIELD node RETURN node CALL apoc.index.search('Loc', 'Loc.description:test~') YIELD node RETURN node CALL apoc.index.search('Loc', 'Loc.description:Test Chinese~') YIELD node RETURN node
2. Delete Index
CALL apoc.index.remove('Loc')
3. Create an index that supports Chinese words
CALL zdr.index.addChineseFulltextIndex('Loc', ["description","cause","year"], 'Loc') YIELD message RETURN message
// The following retrieval was successful: CALL apoc.index.search('Loc', 'description:Chinese~') YIELD node RETURN node CALL apoc.index.search('Loc', 'description:Chinese*') YIELD node RETURN node CALL apoc.index.search('Loc', 'description:test~') YIELD node RETURN node CALL apoc.index.search('Loc', 'description:Test Chinese~') YIELD node RETURN node
3. APOC has its own English full-text indexing process (indexing can be updated automatically)
1. Add Full-Text Index
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]},{autoUpdate:true})
2. New Nodes and Attributes
CREATE (n:Loc {name:'V'}) SET n.description='Testing Chinese word segmentation, the final chapter of the duplicate show was very exciting. It is said that knowledge mapping and artificial intelligence technology were applied to that movie!',n.cause='Test the English word breaker, Mobile World Congress, the world's largest gathering for the mobile industry, ' RETURN n
3. Retrieval
Indexes can be updated automatically, but they are not friendly to Chinese retrieval, such as the following tests:
// Retrieval failed: CALL apoc.index.search('Loc', 'Loc.cause:Test English word breakers~') YIELD node RETURN node CALL apoc.index.search('Loc', 'Loc.description:Test Chinese word segmentation~') YIELD node RETURN node
// Retrieved successfully: CALL apoc.index.search('Loc', 'Loc.cause:Test English word breakers*') YIELD node RETURN node CALL apoc.index.search('Loc', 'Loc.description:Test Chinese word segmentation*') YIELD node RETURN node
4. Custom Chinese word segmentation full-text index plug-in (unsuccessful automatic index update)
The addChineseFulltextAutoIndex process succeeds in creating a full-text index to add a full-text indexing process that supports Chinese, but automatic updates are not supported for updating new attributes of nodes.
1. Add Full-Text Index
CALL zdr.index.addChineseFulltextAutoIndex('IKAnalyzer',["description","cause","year"],'Loc',{autoUpdate:'true'}) YIELD message RETURN message
2. New Nodes and Attributes
CREATE (n:Loc {name:'V'}) SET n.description='Testing Chinese word segmentation, the final chapter of the duplicate show was very exciting. It is said that knowledge mapping and artificial intelligence technology were applied to that movie!',n.cause='Test the English word breaker, Mobile World Congress, the world's largest gathering for the mobile industry, ' RETURN n
3. Retrieval
After adding a full-text search, you can retrieve:
CALL zdr.index.chineseFulltextIndexSearch('IKAnalyzer', 'description:Acridyl Aminomethane Sulfonymethoxyaniline', 100) YIELD node RETURN node
Re-index before retrieving:
CALL zdr.index.chineseFulltextIndexSearch('IKAnalyzer', 'description:test~', 100) YIELD node RETURN node
V. Label Cross-search
Add ChineseFulltextAutoIndex/addChineseFulltextIndex supports multiple tags while retrieving, using the same index name when building the index.
Tag: Loc
CALL zdr.index.addChineseFulltextAutoIndex('Loc',["description","cause","name"],'Loc',{autoUpdate:'true'}) YIELD message RETURN message
Tag: LocProvince'
CALL zdr.index.addChineseFulltextAutoIndex('Loc',["description","cause","name"],'LocProvince',{autoUpdate:'true'}) YIELD message RETURN message
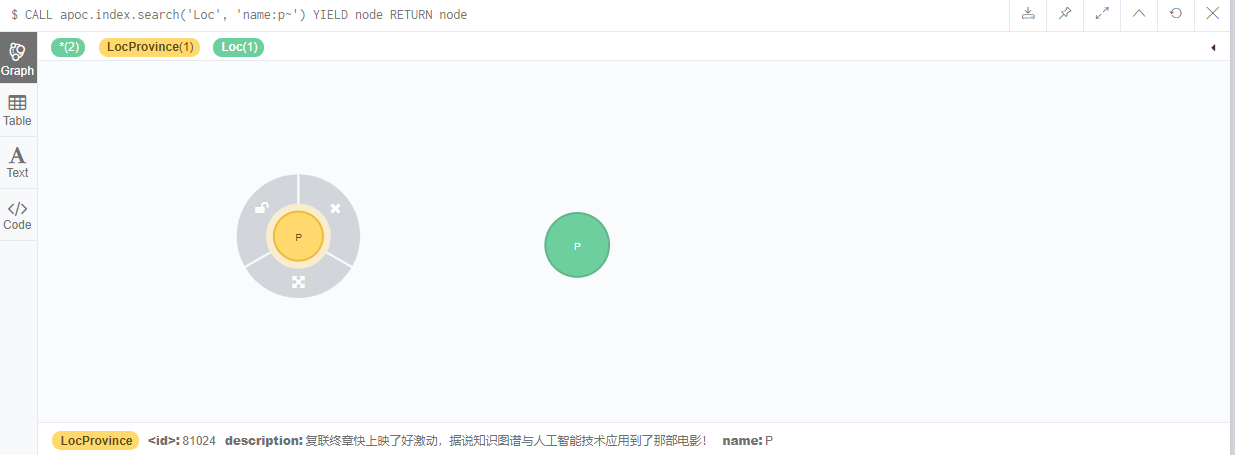
Retrieve node:
CALL apoc.index.search('Loc', 'name:p~') YIELD node RETURN node
6. Custom Chinese Word Segmentation Plugin (Failed to Update Indexes Independently of Nodes)
To support single-node index updates, develop the following process.(The automatic update scheme described in the third section fails, and updates to the corresponding full-text index synchronously when updating or creating a new node.)
1. Add Full-Text Index
CALL apoc.index.remove('Loc') CALL zdr.index.addChineseFulltextIndex('Loc',["description","cause","year"],'Loc') YIELD message RETURN message
2. Add Nodes and Attributes and Update Full-Text Index
CREATE (n:Loc {name:'V'}) SET n.description='Testing Chinese word segmentation, the final chapter of the duplicate show was very exciting. It is said that knowledge mapping and artificial intelligence technology were applied to that movie!',n.cause='Test the English word breaker, Mobile World Congress, the world's largest gathering for the mobile industry, ' RETURN n
3. Add 2 new nodes or updated attributes to the index
MATCH (n) WHERE n.name='V' WITH n CALL zdr.index.addNodeChineseFulltextIndex(n, ['description']) RETURN *
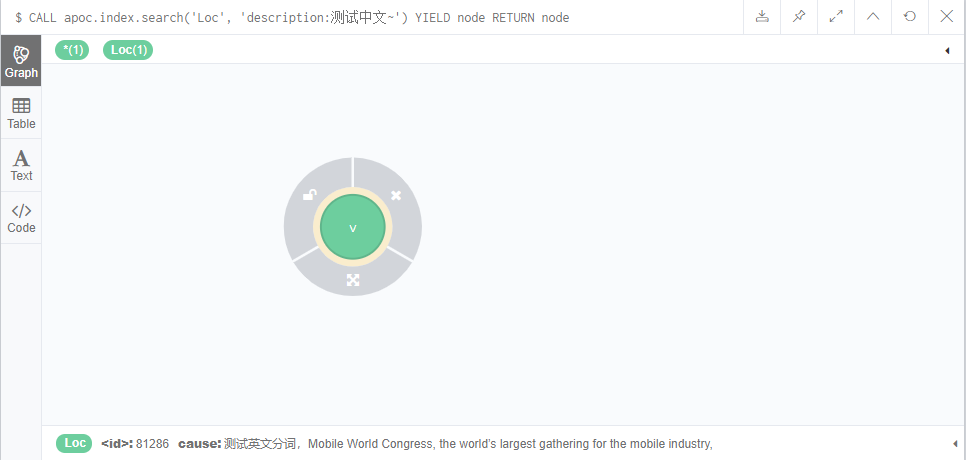
4. Retrieval
CALL zdr.index.chineseFulltextIndexSearch('Loc', 'description:Test Chinese~') YIELD node RETURN node
7. Resolve Transaction Submission Timeout
If the transaction commit timeout setting is configured, Cancel when building the index.
#******************************************************************** ### Neo4j transcation timeout ###****************************************************************** #dbms.transaction.timeout=180s
Use a background script to execute the indexer:
# index.sh #!/usr/bin/env bash nohup /neo4j-community-3.4.9/bin/neo4j-shell -file build.cql >>indexGraph.log 2>&1 &
// build.cql CALL zdr.index.addChineseFulltextIndex('IKAnalyzer', ['description','fullname','name','lnkurl'], 'LinkedinID') YIELD message RETURN message;