Falling in love with Program Network
Reason: This website is in the work of Google to find problems, and then found that there are many articles inside, after all, I usually prefer to read technical articles, what I want to understand, what I do not know in-depth, this is not, want to reptile work, is still in the development of android.
Don't talk much nonsense.
The results of the next database:
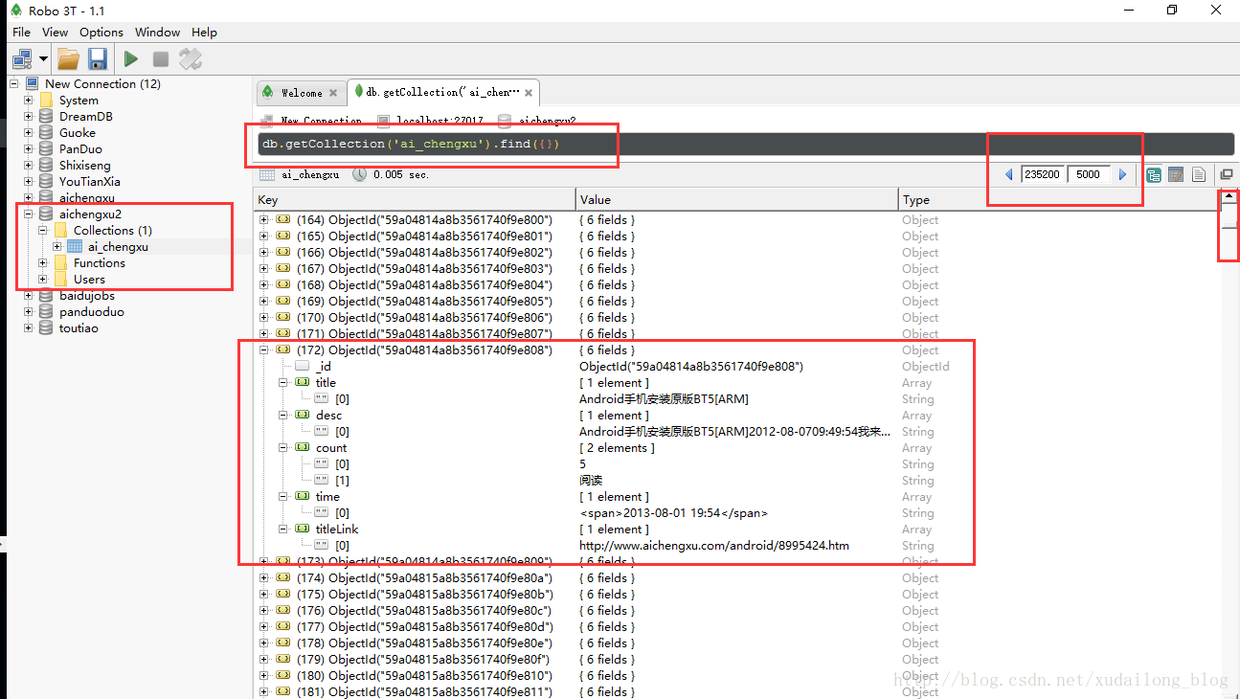
Why is this for the time being? Because the use of recycling 10,000 times, there may be more, data crawled to 2013, presumably this site has been built for a long time, it may be traversed more bar. In the second crawl, about 240,000 data were crawled, maybe more.
Here is a summary of the experience:
Previously, writing scrapy project import module directly in the folder in pycharm has been wrong because import is not going in. You can see the following screenshots for comparison:
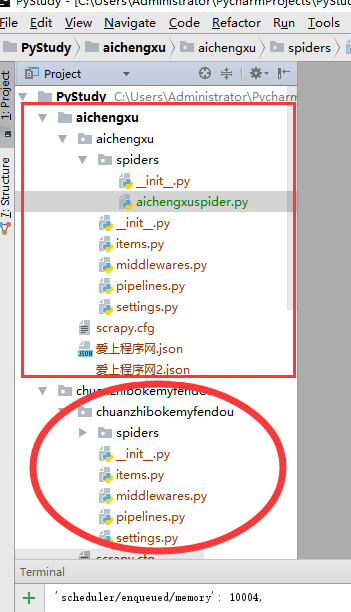
It can be seen that the following project is not blackened in the project, so importing the classes in items in spider is always importing the error, which is no module named''xxx'.
Solution:
We need to re open... in the file menu bar. Then import the project and associate it with the project. add xxx and the project becomes black, so that the subpackage is normal.
The data captured are mainly:
Reading, Title, Title Link (Content Details Page), Content, Time
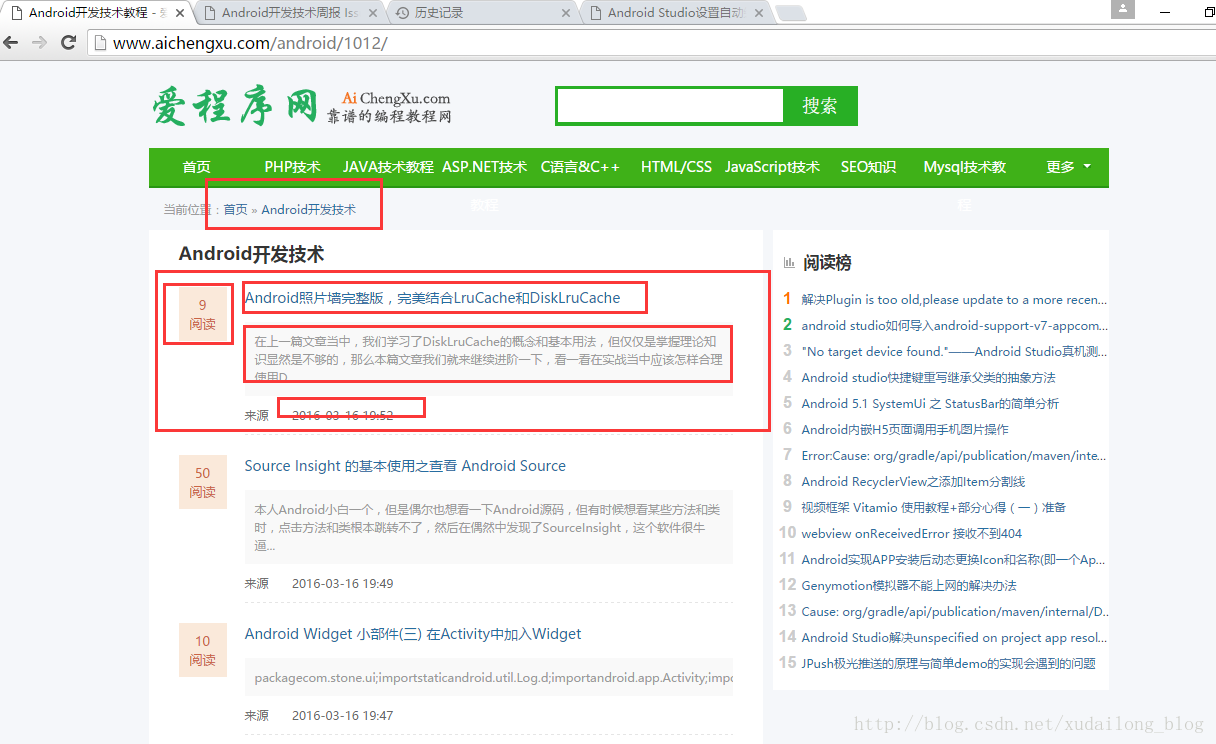
Using scrapy to crawl data is not very skilled in parse () method. It can be adjusted and used at the same time.
Step one:
Configuration of settings files:
# -*- coding: utf-8 -*- # Scrapy settings for aichengxu project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'aichengxu' SPIDER_MODULES = ['aichengxu.spiders'] NEWSPIDER_MODULE = 'aichengxu.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent # USER_AGENT = 'aichengxu (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) # CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: # CONCURRENT_REQUESTS_PER_DOMAIN = 16 # CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) # COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) # TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Cookie': 'ras=24656333; cids_AC31=24656333', 'Host': 'www.aichengxu.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36', } # Configure mongoDB MONGO_HOST = "127.0.0.1" # Host IP MONGO_PORT = 27017 # Port number MONGO_DB = "aichengxu2" # Library name MONGO_COLL = "ai_chengxu" # collection # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html # SPIDER_MIDDLEWARES = { # 'aichengxu.middlewares.AichengxuSpiderMiddleware': 543, # } # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # DOWNLOADER_MIDDLEWARES = { # 'aichengxu.middlewares.MyCustomDownloaderMiddleware': 543, # 'aichengxu.middlewares.MyCustomDownloaderMiddleware': 543, # 'aichengxu.middlewares.MyCustomDownloaderMiddleware': 543, # } # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html # EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, # } # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'aichengxu.pipelines.AichengxuPipeline': 300, 'aichengxu.pipelines.DuoDuoMongo': 300, 'aichengxu.pipelines.JsonWritePipline': 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html # AUTOTHROTTLE_ENABLED = True # The initial download delay # AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies # AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server # AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: # AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings # HTTPCACHE_ENABLED = True # HTTPCACHE_EXPIRATION_SECS = 0 # HTTPCACHE_DIR = 'httpcache' # HTTPCACHE_IGNORE_HTTP_CODES = [] # HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Of course, the useful ones are those that have not been commented out. It's a habit. No, sometimes I wonder why scrapy didn't run, or make a mistake directly. Ha-ha.
Step two:
Definition in items:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class AichengxuItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class androidItem(scrapy.Item): # Reading volume count = scrapy.Field() # Title title = scrapy.Field() # link titleLink = scrapy.Field() # describe desc = scrapy.Field() # time time = scrapy.Field()
Step three:
Coding in spiders
# -*- coding: utf-8 -*- # @Time : 2017/8/25 21:54 # @ Author: Snake pup # @Email : 17193337679@163.com # @ File: aichengxuspider.py Ai Program Network www.aichengxu.com import scrapy from aichengxu.items import androidItem import logging class aiChengxu(scrapy.Spider): name = 'aichengxu' allowed_domains = ['www.aichengxu.com'] start_urls = ["http://www.aichengxu.com/android/{}/".format(n) for n in range(1,10000)] def parse(self, response): node_list = response.xpath("//*[@class='item-box']") print('nodelist',node_list) for node in node_list: android_item = androidItem() count = node.xpath("./div[@class='views']/text()").extract() title_link = node.xpath("./div[@class='bd']/h3/a/@href").extract() title = node.xpath("./div[@class='bd']/h3/a/text()").extract() desc = node.xpath("./div[@class='bd']/div[@class='desc']/text()").extract() time = node.xpath("./div[@class='bd']/div[@class='item-source']/span[2]").extract() print(count,title,title_link,desc,time) android_item['title'] = title android_item['titleLink'] = title_link android_item['desc'] = desc android_item['count'] = count android_item['time'] = time yield android_item
Here's my opinion about the key word "yield": to return to this item and continue to perform the next task, or to return to item and then continue to the next crawler.
Step four:
piplines code:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json import pymongo from scrapy.conf import settings class AichengxuPipeline(object): def process_item(self, item, spider): return item class DuoDuoMongo(object): def __init__(self): self.client = pymongo.MongoClient(host=settings['MONGO_HOST'], port=settings['MONGO_PORT']) self.db = self.client[settings['MONGO_DB']] self.post = self.db[settings['MONGO_COLL']] def process_item(self, item, spider): postItem = dict(item) self.post.insert(postItem) return item # Write to json file class JsonWritePipline(object): def __init__(self): self.file = open('Falling in love with Programnet 2.json','w',encoding='utf-8') def process_item(self,item,spider): line = json.dumps(dict(item),ensure_ascii=False)+"\n" self.file.write(line) return item def spider_closed(self,spider): self.file.close()
There are mainly two types of storage, one is mogodb, the other is json file storage.
In this way, the code will crawl out, and then it will be over, the code has not been written for a long time, a lot of strangers.
There is a question: 240,000 data crawled here, not in the middle because cookie s or agents are stationary, it may be set in settings because of the request head, DEFAULT_REQUEST_HEADERS
Again, why do I want to climb this website? I always feel that I am very technology-driven. Of course, android is not my favorite. Maybe I am afraid of it. android adaptation is disgusting. Model, screen or something.
There are many other entries on this website:
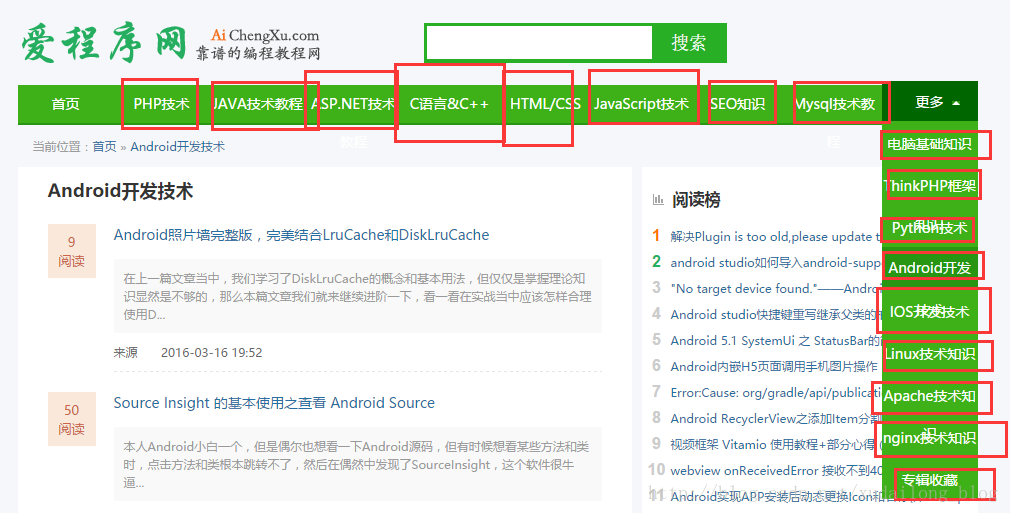
If all the crawls are taken down, honestly, I haven't crawled them, but a little buddy with an idea tries it, and finally uploads the code to my github: