This year's graduation project is about big data and machine learning. Because that time has entered the front-end industry naturally choose to use JavaScript to implement the specific algorithm. Although JavaScript is not the best language for big data processing and has no advantage over other languages, it improves our understanding of js and makes up for some weaknesses in data structure. Friends who are interested in machine learning still use python, and eventually, besides the rigid paper format requirements of the school, record the implementation process and my own understanding of the algorithm.
The source code is in github: https://github.com/abzerolee/...
Beginning to learn machine learning algorithms is through Tom M. Mitchel. Machine Learning[M] 1994. Friends who like to study machine learning can take a look at this book. The next narration is only a shallow understanding and implementation of the algorithm, but for friends who have not been exposed to machine learning to see a happy, self-summary memory. Of course, it is best to arouse people's enthusiasm for machine learning algorithms.
Algorithmic Principle
In fact, the implementation process is to analyze and analyze the data of training set (known classification) to get a classification model. By inputting a test data (unknown classification), the classification model can deduce the classification results of the data. The training data are shown in the following figure.

This data set means that weather conditions determine whether to eventually play tennis. An array represents a weather condition and its corresponding results. The first four columns represent the characteristic attributes of the data (weather, temperature, humidity, wind or not), and the last column represents the classification results. According to this training set, a data model can be obtained by using Naive Bayesian Classification and Decision Tree ID3 Classification, and then by inputting a test data: "sunny cool high TRUE" to determine whether to go back to play tennis. Similarly, as long as the feature attributes remain certain and have corresponding classification results, no matter what kind of data the training set is, the classification results can be obtained through the feature attributes. The so-called classification model is realized by programming language through some probability theory and the theoretical basis of statistics. The following is a brief introduction to the principles of the two algorithms.
I. Naive Bayesian Classification
The Bayesian theorem of University probability theory achieves the conclusion of hypothetical reasoning by calculating probability. Bayesian Theorem is shown in the following figure:
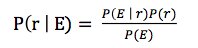
E represents the training set, R represents a classification result (yes or no), P(E) is a constant independent of the classification result R. It can be found that the larger P(E), the less affected P(r|E) is by the training set.
That is, P (r) => P (yes) = 9/14, or P(no)=5/14.
The conditional probability P (E | r) => P (wind = TRUE | yes) = 3/9 P (wind = FALSE | no) = 2/5
In this way, the conditional probability of each feature attribute in the case of classification results can be obtained. When a test data is input, the probability of the corresponding classification hypothesis can be obtained by calculating the conditional probability of the characteristic attribute value of the data below the money of a certain classification hypothesis. Then the maximum value can be compared, which is called the maximum likelihood hypothesis. The corresponding classification result is the classification result of the test data.
For example, the test data are as follows: sunny, cool, high and TRUE are calculated as follows:
P(yes)P(sunny|yes)P(high|yes)P(cool|yes)P(TRUE|yes) = P(yes|E)
P(no)P(sunny|no)P(high|no)P(cool|no)P(TRUE|no) = P(no|E)
Infer no.
Here's a recommendation for a blog that introduces Bayesian text categorization http://www.cnblogs.com/phinec...
II. Decision Tree ID3 Classification
Decision tree classification is more like a process of thinking:
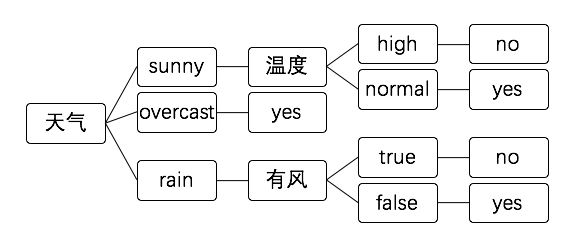
The test data are the same as those above. When the weather node judges the sunny branch temperature node judges the high branch, the result of no is obtained directly.
Decision tree is easy to understand when classifying according to test data. The key point is to construct decision tree through training data. There are two corresponding problems:
1. Which feature attribute should be selected as the root node?
2. How to judge the next attribute node on the branch corresponding to the characteristic attribute value?
These two questions can be summarized as how to determine the optimal test attributes? In information theory, the smaller the expected information, the greater the information gain and the higher the purity. In fact, the more information the feature attributes can bring to the final classification results, the more important the feature attributes are. For an attribute, whether it exists in classification will lead to changes in the amount of classification information, and the difference between the amount of information before and after is the amount of information that this feature attribute brings to classification. And the amount of information is information entropy. Information entropy represents the average amount of information provided by each discrete message.
As the example above: can be expressed as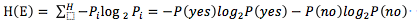
When attr is selected, the information entropy can be expressed as
The information gain corresponding to this attribute can be expressed as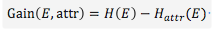
Choosing the most suitable feature attributes for tree nodes is the attribute with the greatest information gain. You should get Gain = 0.246
The next step is to judge the node selection of the branch of the attribute value, find out the subset satisfying the attribute value from the training set, and then compare the information gain of each attribute of the subset. Repeat the above steps until the subset is empty and returns the most common classification results.

The figure above is an introduction to ID3 algorithm in Machine Learning, and the figure below is a program flow chart.

III. Classification Model Assessment
The evaluation index of classification model is calculated by confusion matrix.
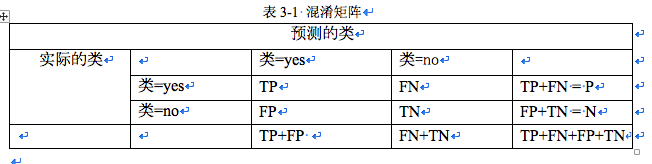
P is the number of yes in sample data, N is the number of no in sample data, TP is the number of yes correctly predicted, FP is the number of yes predicted as no, FN is the number of yes predicted as no, TN is the number of yes correctly predicted. The evaluation measure is
1. Hit Rate: The Probability of Correct Diagnosis of Real Illness TP/P
2. False alarm rate: the probability of being diagnosed with no illness. FP/N
The evaluation methods of classification model are cross-validation method and average sampling method of. 632, such as 100 original data, 100 random sampling times for training set, and annotate that the number of times extracted will be more than 63.2 as training set and less than data as test set at each sampling time. But in the actual program implementation, sample deviation is too severe. I chose 44 times as standard.
In this way, each data of the test set is input and the classification model obtained from the training set is used to compare the classification results of the test data with the real classification. Finally, the hit rate and false alarm rate of decision tree and Bayesian classification can be obtained according to the confusion matrix. Repeated evaluation of 40 times can get [hit rate, false alarm rate], with the hit rate as the ordinate, false alarm rate as the abscissa point can get ROC curve, the nearer the point is to the upper left corner, the more correct the classification model is, the more intuitive the performance of the difference between the two classification models. The plot I got is as follows
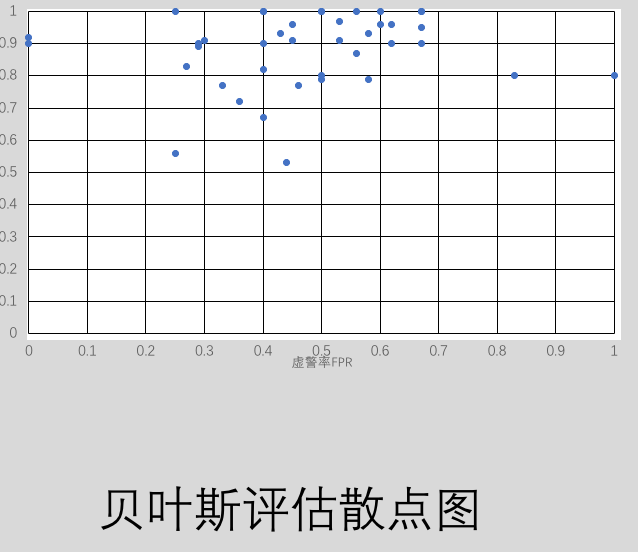
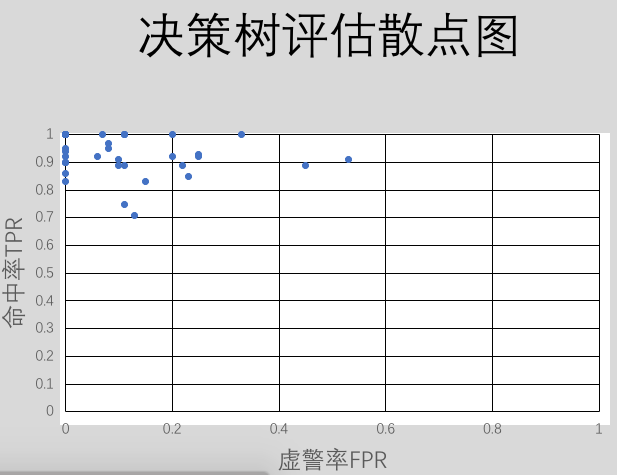
It is obvious from the graph that the decision tree classification model is more accurate for small sample data.
Core code
naive bayes classifier
const HashMap = require('./HashMap'); function Bayes($data){ this._DATA = $data; } Bayes.prototype = { /** * Classification of training data by category * @return HashMap<Categories, Training Data for Use Categories > */ dataOfClass: function() { var map = new HashMap(); var t = [], c = ''; var datas = this._DATA; if(!(datas instanceof Array)) return; for(var i = 0; i < datas.length; i++){ t = datas[i]; c = t[t.length - 1]; if(map.hasKey(c)){ var ot = map.get(c); ot.push(t); map.put(c, ot); }else{ var nt = []; nt.push(t); map.put(c, nt); } } return map; }, /** * Categories of Predictive Test Data * @param Array testT test data * @return String Test data corresponding categories */ predictClass: function(testT){ var doc = this.dataOfClass(); var maxP = 0, maxPIndex = -1; var classes = doc.keys(); for(var i = 0; i < classes.length; i++){ var c = classes[i] var d = doc.get(c); var pOfC = d.length / this._DATA.length; for(var j = 0; j < testT.length; j++){ var pv = this.pOfV(d, testT[j], j); pOfC = pOfC * pv; } if(pOfC > maxP){ maxP = pOfC; maxPIndex = i; } } if(maxPIndex === -1 || maxPIndex > doc.length){ return 'Unable to classify'; } return classes[maxPIndex]; }, /** * Calculating the conditional probability of the occurrence of specified attributes in training data * @param d A training tuple belonging to a certain class * @param value Specify attributes * @param index Specify the column in which the property is located * @return Conditional Probability of Characteristic Attributes under a Category */ pOfV: function(d, value, index){ var p = 0, count = 0, total = d.length, t = []; for(var i = 0; i < total; i++){ if(d[i][index] === value) count++; } p = count / total; return p; } } module.exports = Bayes;
2. Decision Tree ID3 Classification
const HashMap = require('./HashMap'); const $data = require('./data'); const TreeNode = require('./TreeNode'); const InfoGain = require('./InfoGain'); function Iterator(arr){ if(!(arr instanceof Array)){ throw new Error('iterator needs a arguments that type is Array!'); } this.arr = arr; this.length = arr.length; this.index = 0; } Iterator.prototype.current = function() { return this.arr[this.index-1]; } Iterator.prototype.next = function(){ this.index += 1; if(this.index > this.length || this.arr[this.index-1] === null) return false; return true; } function DecisionTree(data, attribute) { if(!(data instanceof Array) || !(attribute instanceof Array)){ throw new Error('argument needs Array!'); } this._data = data; this._attr = attribute; this._node = this.createDT(this._data,this._attr); } DecisionTree.prototype.createDT = function(data, attrList) { var node = new TreeNode(); var resultMap = this.isPure(this.getTarget(data)); if(resultMap.size() === 1){ node.setType('result'); node.setName(resultMap.keys()[0]); node.setVals(resultMap.keys()[0]); // console.log('single node tree: '+ node.getVals())); return node; } if(attrList.length === 0){ var max = this.getMaxVal(resultMap); node.setType('result'); node.setName(max) node.setVals(max); // console.log('most universal result:'+max); return node; } var maxGain = this.getMaxGain(data, attrList).maxGain; var attrIndex = this.getMaxGain(data, attrList).attrIndex // console.log('The maximum gain rate attribute selected is:'+attrList[attrIndex]); // console.log('create node:'+attrList[attrIndex]) node.setName(attrList[attrIndex]); node.setType('attribute'); var remainAttr = new Array(); remainAttr = attrList; // remainAttr.splice(attrIndex, 1); var self = this; var gain = new InfoGain(data, attrList) var attrValueMap = gain.getAttrValue(attrIndex); //The value MAP of the best categorized attribute var possibleValues = attrValueMap.keys(); node_vals = possibleValues.map(function(v) { // console.log('create branch:'+v); var newData = data.filter(function(x) { return x[attrIndex] === v; }); // newData = newData.map(function(v) { // return v.slice(1); // }) var child_node = new TreeNode(v, 'feature_values'); var leafNode = self.createDT(newData, remainAttr); child_node.setVals(leafNode); return child_node; }) node.setVals(node_vals); this._node = node; return node; } /** * Judging whether the training data purity classification is a classification or not */ DecisionTree.prototype.getTarget = function(data){ var list = new Array(); var iter = new Iterator(data); while(iter.next()){ var index = iter.current().length - 1; var value = iter.current()[index]; list.push(value); } return list; }, /** * Get an array of classification results and judge the purity */ DecisionTree.prototype.isPure = function(list) { var map = new HashMap(), count = 1; list.forEach(function(item) { if(map.get(item)){ count++; } map.put(item, count); }); return map; } /** * Getting Maximum Gain Attribute */ DecisionTree.prototype.getMaxGain = function(data, attrList) { var gain = new InfoGain(data, attrList); var maxGain = 0; var attrIndex = -1; for(var i = 0; i < attrList.length; i++){ var temp = gain.getGainRaito(i); if(maxGain < temp){ maxGain = temp; attrIndex = i; } } return {attrIndex: attrIndex, maxGain: maxGain}; } /** * Get the maximum key in the resultMap median */ DecisionTree.prototype.getMaxVal = function(map){ var obj = map.obj, temp = 0, okey = ''; for(var key in obj){ if(temp < obj[key] && typeof obj[key] === 'number'){ temp = obj[key]; okey = key; }; } return okey; } /** * Predictive attributes */ DecisionTree.prototype.predictClass = function(sample){ var root = this._node; var map = new HashMap(); var attrList = this._attr; for(var i = 0; i < attrList.length; i++){ map.put(attrList[i], sample[i]); } while(root.type !== 'result'){ if(root.name === undefined){ return root = 'Unable to classify'; } var attr = root.name; var sample = map.get(attr); var childNode = root.vals.filter(function(node) { return node.name === sample; }); if(childNode.length === 0){ return root = 'Unable to classify'; } root = childNode[0].vals; // Only traverse attribute s nodes } return root.vals; } module.exports = DecisionTree;
3. Gain Rate Calculation
function InfoGain(data, attr) { if(!(data instanceof Array) || !(attr instanceof Array)){ throw new Error('arguments needs Array!'); } this._data = data; this._attr = attr; } InfoGain.prototype = { /** * Getting the Number of Training Data Classification * @return hashMap<Category, Number of Categories > */ getTargetValue: function() { var map = new HashMap(); var iter = new Iterator(this._data); while(iter.next()){ var t = iter.current(); var key = t[t.length-1]; var value = map.get(key); map.put(key, value !== undefined ? ++value : 1); } return map; }, /** * Obtaining Information Entropy of Training Data * @return Information Entropy of Training Data */ getEntroy: function(){ var targetValueMap = this.getTargetValue(); var targetKey = targetValueMap.keys(), entroy = 0; var self = this; var iter = new Iterator(targetKey); while(iter.next()){ var p = targetValueMap.get(iter.current()) / self._data.length; entroy += (-1) * p * (Math.log(p) / Math.LN2); } return entroy; }, /** * Get the number of attribute values in the training data set * @param number index Attribute Name Array Index */ getAttrValue: function(index){ var map = new HashMap(); var iter = new Iterator(this._data); while(iter.next()){ var t = iter.current(); var key = t[index]; var value = map.get(key); map.put(key, value !== undefined ? ++value : 1); } return map; }, /** * Get the proportion of attribute values in decision space * @param string name Attribute value * @param number index Which column is the property in? */ getAttrValueTargetValue: function(name, index){ var map = new HashMap(); var iter = new Iterator(this._data); while(iter.next()){ var t = iter.current(); if(name === t[index]){ var size = t.length; var key = t[t.length-1]; var value = map.get(key); map.put(key, value !== undefined ? ++value : 1); } } return map; }, /** * Entropy of data set classified after feature attributes acting on training data set * @param number index Attribute Name Array Index */ getInfoAttr: function(index){ var attrValueMap = this.getAttrValue(index); var infoA = 0; var c = attrValueMap.keys(); for(var i = 0; i < attrValueMap.size(); i++){ var size = this._data.length; var attrP = attrValueMap.get(c[i]) / size; var targetValueMap = this.getAttrValueTargetValue(c[i], index); var totalCount = 0 ,valueSum = 0; for(var j = 0; j < targetValueMap.size(); j++){ totalCount += targetValueMap.get(targetValueMap.keys()[j]); } for(var k = 0; k < targetValueMap.size(); k++){ var p = targetValueMap.get(targetValueMap.keys()[k]) / totalCount; valueSum += (Math.log(p) / Math.LN2) * p; } infoA += (-1) * attrP * valueSum; } return infoA; }, /** * Gain information gain */ getGain: function(index) { return this.getEntroy() - this.getInfoAttr(index); }, getSplitInfo: function(index){ var map = this.getAttrValue(index); var splitA = 0; for(var i = 0; i < map.size(); i++){ var size = this._data.length; var attrP = map.get(map.keys()[i]) / size; splitA += (-1) * attrP * (Math.log(attrP) / Math.LN2); } return splitA; }, /** * Gain rate */ getGainRaito: function(index){ return this.getGain(index) / this.getSplitInfo(index); }, getData4Value: function(attrValue, attrIndex){ var resultData = new Array(); var iter = new Iterator(this._data); while(iter.next()){ var temp = iter.current(); if(temp[attrIndex] === attrValue){ resultData.push(temp); } } return resultData; } }
Specific procedures to achieve I will continue to introduce, to be continued...
The first time I posted an article in segmentfault, I was a little nervous. What opinions or ideas do you have that you can correct me in time?