Recent classes are always unable to remember which classroom, I feel it is very troublesome to visit the website of the Academic Affairs Office manually every time. It happened that I was learning to crawl, so I wanted to write a crawler to help me look up the information on the timetable.
Do as you say. With requests, a third-party library that feels better for personal use is based on py3; beautifulsoup is used for parsing. Open Chorme, log on to the website of Nantong Institute of Technology and track the network behavior during the login process.
As you can see, there are three kinds of information to enter. User names and passwords are easy to handle, mainly the timely identification of authentication codes. The strategy to be adopted is to download the validation code file to the local area and then enter it manually. Click on login to continue tracking network behavior and find that the data entered here (along with some other incidental data) is post ed to http://gsmis.njust.edu.cn/.
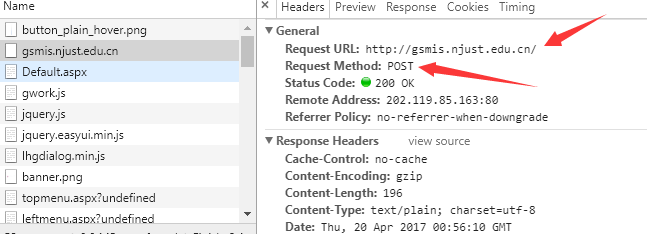
Looking further at the post's FormData, you can find the three data, UserName, PassWord and ValidateCode.
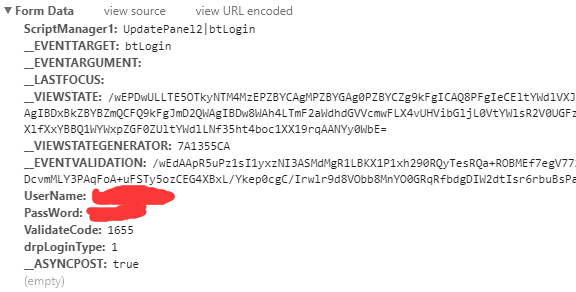
Find out here has solved the problem of which way the verification code goes (post) and where to go (http://gsmis.njust.edu.cn/), and then the problem of where to come from. Checking the elements of the validation code on HTML shows that its src is Public/ValidateCode.aspx?image=a string of irrelevant numbers. That is to say, you need to get the validation code file in http://gsmis.njust.edu.cn/Public/ValidateCode.aspx?image= In this way, the context of the verification code can be clarified. The link of the verification code is obtained from the src and downloaded to the local area. The verification code and other necessary information are sent to http://gsmis.njust.edu.cn/ via post.
After landing, we can automatically schedule by analyzing the data and network behavior when we query the timetable in a similar way. (Although there are really few classes, there are really many things to do). In addition, I found that this method is also troublesome, it is better to check directly online.
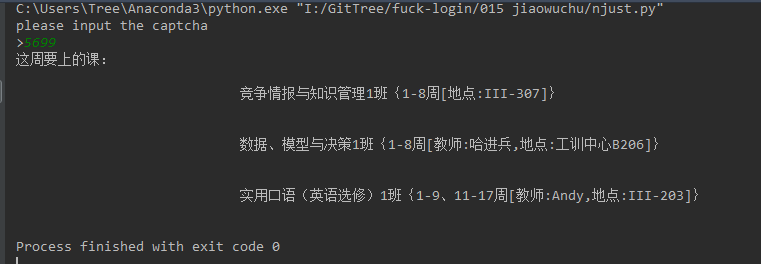
Next, go directly to the code:
# -*- coding: utf-8 -*-
"""
@author: Tree
"""
import requests
from bs4 import BeautifulSoup
# Login Address and the Address of Query Course Schedule
LoginUrl = "http://gsmis.njust.edu.cn/UserLogin.aspx?exit=1"
class_url = "http://gsmis.njust.edu.cn/Gstudent/Course/StuCourseWeekQuery.aspx"
session = requests.session()
# Login main function
def login():
headerdic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',
'Host': 'gsmis.njust.edu.cn',
'Referer': 'http://gsmis.njust.edu.cn/',
'Accept': '*/*',
'Connection': 'Keep-Alive',
}
postdic = {
'UserName': "Student number,
'PassWord': "Password.
'drpLoginType': '1',
'__ASYNCPOST': 'true',
'ScriptManager1': 'UpdatePanel2|btLogin',
'__EVENTTARGET': 'btLogin',
'__VIEWSTATE': '/wEPDwULLTE5OTkyNTM4MzEPZBYCAgMPZBYGAg0PZBYCZg9kFgICAQ8PFgIeCEltYWdlVXJsBSp+L1B1YmxpYy9WYWxpZGF0ZUNvZGUuYXNweD9pbWFnZT02ODA3OTUyOTFkZAIRD2QWAmYPZBYCAgEPEGRkFgFmZAIVD2QWAmYPZBYCAgEPDxYCHgtOYXZpZ2F0ZVVybAUtfi9QdWJsaWMvRW1haWxHZXRQYXNzd2QuYXNweD9FSUQ9VHVyOHZadXVYa3M9ZGQYAQUeX19Db250cm9sc1JlcXVpcmVQb3N0QmFja0tleV9fFgEFDVZhbGlkYXRlSW1hZ2W5HJlvYqz666q9lGAspojpOWb4sA==',
'__EVENTVALIDATION': '/wEdAAoKNGMKLh/WwBcPaLKBGC94R1LBKX1P1xh290RQyTesRQa+ROBMEf7egV772v+RsRJUvPovksJgUuQnp+WD/+4LQKymBEaZgVw9rfDiAaM1opWKhJheoUmouOqQCzlwTSNWlQTw3DcvmMLY3PAqFoA+uFSTy5ozCEG4XBxL/Ykep0cgC/Irwlr9d8VObb8MnYO0GRqRfbdgDIW2dtIsr6rbUIwej/LsqVAg3gLMpVY6UeARlz0=',
'__EVENTARGUMENT': '',
'__LASTFOCUS': ''
}
login_header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Host': 'gsmis.njust.edu.cn',
'Referer': 'http://gsmis.njust.edu.cn/UserLogin.aspx?exit=1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3067.6 Safari/537.36'
}
# Execute getCheckCode and store the verification code information in postdic
img_url = "http://gsmis.njust.edu.cn/Public/ValidateCode.aspx?image="
postdic = getCheckCode(img_url, postdic, headerdic)
# Get this week's schedule and use get to construct access with parameters
eid = {'EID': 'j747VIAgTbv89k5pIqOcwJMucc!p3AXikfLcF!otxmBkw0iDLfKWdA=='}
session.post("http://gsmis.njust.edu.cn/", data=postdic, headers=login_header)
sclass = session.get(class_url, params=eid, headers=headerdic)
soup = BeautifulSoup(sclass.text, "lxml")
print("Lessons to be taught this week:")
for i in range(len(soup.select('td[rowspan="4"]'))):
print(soup.select('td[rowspan="4"]')[i].get_text())
for i in range(len(soup.select('td[rowspan="2"]'))):
print(soup.select('td[rowspan="2"]')[i].get_text())
# Get the authentication code and save it locally
def getCheckCode(url, postdic, headerdic):
r = session.get(url, headers=headerdic)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
f.close()
captcha = input("please input the captcha\n>")
postdic["ValidateCode"] = captcha
return postdic
if __name__ == '__main__':
login()