Last article: Noejs WeChat Public Number Development - 8. Mass Message , briefly introduces the implementation of advanced group interface, and illustrates it with a simple example.The content of this section may not have much to do with the development of WeChat Public Number itself, but the content involved in my small project, the knowledge point contains nodejs crawler and timer module.(Project github: https://github.com/Panfen/wem...
1. Noejs Web Crawler
Crawlers are an effective tool for automatically getting Web content.Although crawlers are developed more in Python, using nodejs is also a good choice.We take Crawl Flower Movie Network For your goal, crawl the movies that have been online in the last two days, get their movie names, Movie Poster pictures, movie details page web page links, ftp download links.Integrate into WeChat push content.
2. Basic crawl operations
2.1 Use the request module to get web content
request is a module that simplifies the operation of HTTP requests. It is powerful and easy to use, and a GET method is used to get the content of a URL:
var request = require('request'); var URL = 'http://www.piaohua.com/'; request.get(URL,function(err,res,body){ if(!err && res.statusCode == 200){ //Output Page Content console.log(body); }else{ console.log('failed to crawl the website!'); } });
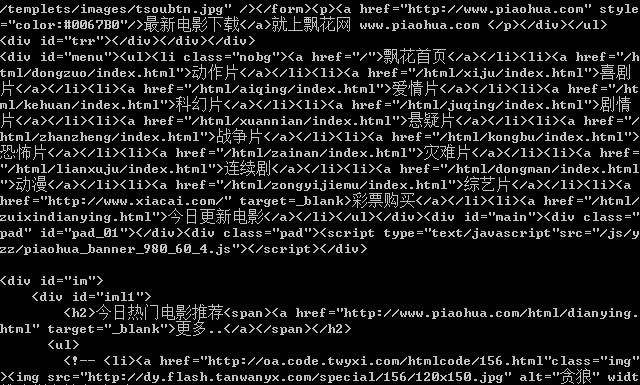
Of course, we also use the http module to get data:
var request = require('request'); var URL = 'http://www.piaohua.com/'; http.get(URL,function(res){ var html = ''; res.on('data',function(data){ html += data; }); res.on('end',function(){ console.log(html); //Output Page Content }); }).on('error',function(){ console.log('failed to crawl the website!'); });
The same is true for request s.
2.2 Use the cheerio module to present web page data
What we get from request is a pair of web page codes, and what we really need is data that gets into this stack of codes.cheerio is a subset of jQuery Core that implements a browser-independent DOM operation API in jQuery Core.You can use the same syntax as jquery to work with elements.
var cheerio = require('cheerio'); ... if(!err && res.statusCode == 200){ var $ = cheerio.load(body); var movieList = $('#iml1').children("ul").first().find('li'); var myMovieList = []; movieList.each(function(item){ var time = $(this).find('span font').html() ? $(this).find('span font').html() : $(this).find('span').html(); //Filter movies from the last three days if((new Date() - new Date(time)) < 259200000){ var dom = $(this).find('a').first(); var link = URL + $(dom).attr('href'); var img = $(dom).find('img').attr('src'); var name = $(dom).find('img').attr('alt').substr(22).replace('</font>',''); var movie = { name:name, img:img, link:link, time:time, } myMovieList.push(movie); }; }); console.log(myMovieList); }
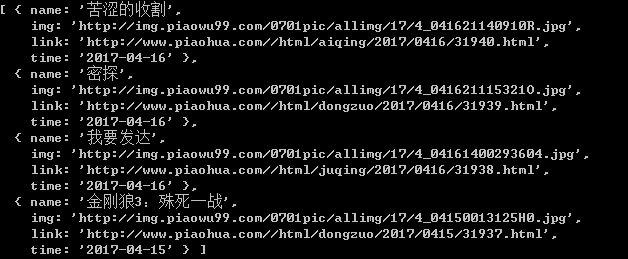
Here we have successfully obtained an array of objects for the last three days of the movie. The information includes the title of the movie, the cover image, detailed links, and the time to go online, as well as one of the properties we expected: the ftp download link.The ftp download link is in the details page, so we need to crawl further information.
if((new Date() - new Date(time)) < 259200000){ var dom = $(this).find('a').first(); var link = URL + $(dom).attr('href'); var img = $(dom).find('img').attr('src'); var name = $(dom).find('img').attr('alt').substr(22).replace('</font>',''); getftpLink(link,function(ftp){ var movie = { name:name, img:img, link:link, time:time, ftp:unescape(ftp.replace(/;/g,'').replace(/&#x/g, "%u")) } myMovieList.push(movie); }); };
The getftpLink function is used to get the download ftp by link ing to the details page:
function getftpLink(link,callback){ request.get(link,function(err,res,body){ if(!err && res.statusCode == 200){ var $ = cheerio.load(body); var ftp = $('#showinfo').find('table tbody tr td a').html(); callback(ftp); } }); }
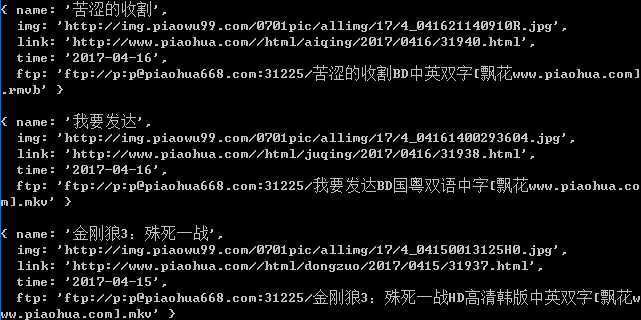
Is it great?Get the ftp and download it directly with Thunder.
3. Crawler Timing
3.1 Use the cron module to perform tasks on a regular basis
var cronJob = require('cron').CronJob; var job = new cronJob('f1 f2 f3 f4 f5 f6',function(){ //do something });
f1 f2 f3 f4 f5 f6 is an option for controlling time, where F1 represents seconds, f2 represents minutes, f3 represents hours, f4 represents the day of a month, f5 represents months, and f6 represents the day of a week.The values of each part are as follows (for example, f1):
When the value is * it means one execution per second;
When the value is a-b, it means that it is executed once in the period from second a to second B.
When the value is */n, it means every n seconds;
When the value is a-b/n, it means that it is executed every N seconds from the first a to the second B.
var cronJob = require('cron').CronJob;
var job = new cronJob('00 30 11 * * *',function(){ request.get(URL,function(err,res,body){ ... }); });
This means performing a crawl every day at 11:30 p.m., getting information and pushing graphical messages.