Analyzing Page Structure
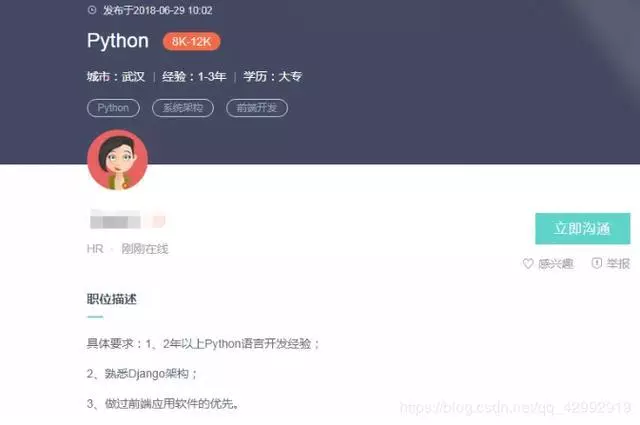
Through the analysis of the page, it is found that the details of recruitment are in the details page (as shown below), so the details page is used to extract the recruitment content.
Designing crawler strategies
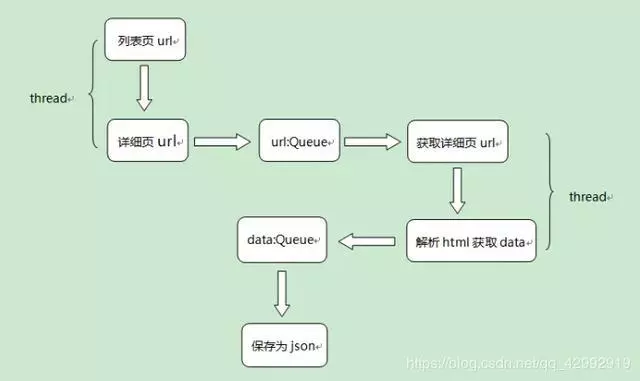
The url address of the detailed page is obtained from the list page and stored in the url queue. It is found that the list page has 10 pages. Multithreading is used to improve the crawling efficiency.
html content of detail page is obtained by url address of detail page in url queue, and recruitment information is extracted by xpath parsing and stored in data queue in the form of dictionary. Multithreading is also used here.
Save the data in the data queue as a json file, where each json file saved is a list page with all the recruitment information.
Judgment of Page Request Mode
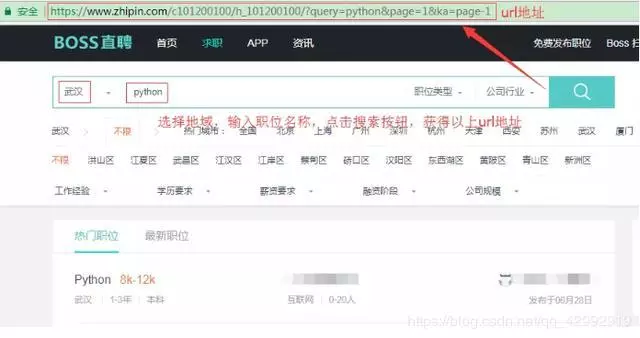
It is not difficult to find that the specified page is obtained through get request and add query string.
The meaning of the query string parameter: query=python denotes the search position, page=1 denotes the page number of the list page, ka=page-1 is useless and can be ignored;
The corresponding code is as follows:
# Regular expressions: Remove the < br/> and < EM > </em> tags from the tags, and facilitate the use of xpath to parse and extract text
regx_obj = re.compile(r'<br/>|<(em).*?>.*?</\1>')
def send_request(url_path, headers, param=None):
"""
:brief Send a request, get it html response(Here is get request)
:param url_path: url address
:param headers: Request header parameters
:param param: Query parameters, For example: param = {'query': 'python', 'page': 1}
:return: Return the response content
"""
response = requests.get(url=url_path, params=param, headers=headers)
response = regx_obj.sub('', response.text)
return response
Get the details page url from the list page
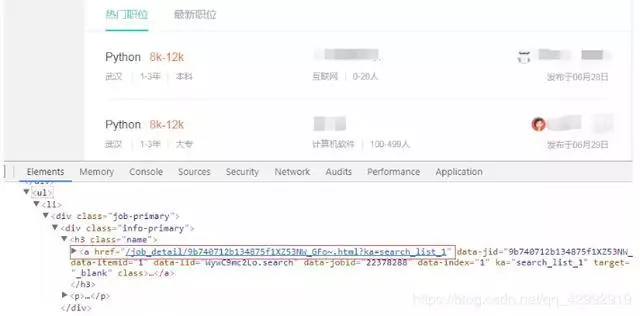
Here, the href attribute value of a tag is obtained through xpath grammar @href, and the url address of the detailed page is obtained. The code is as follows:
def detail_url(param):
"""
:brief Getting Details Page url address
:param param: get Query parameters of requests
:return: None
"""
wuhan_url = '/'.join([base_url, "c101200100/h_101200100/"])
html = send_request(wuhan_url, headers, param=param)
# List Page Page
html_obj = etree.HTML(html)
# Extract details page url address
nodes = html_obj.xpath(".//div[@class='info-primary']//a/@href")
for node in nodes:
detail_url = '/'.join([base_url, node]) # Stitching into a complete url address
print(detail_url)
url_queue.put(detail_url) # Add to the queue
Parsing Details Page Data
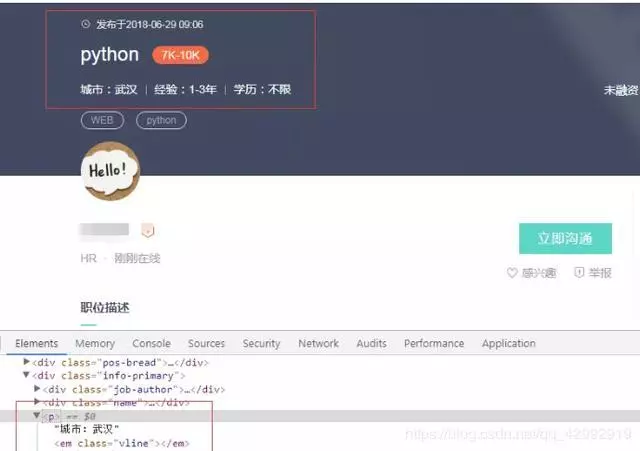
The data is parsed by xpath, and then stored as a dictionary in the queue. The code is as follows:
def parse_data():
"""
:brief from html Extracting specified information from text
:return: None
"""
# # Resolve into HTML documents
try:
while True:
# Wait 25 seconds, and an exception is thrown if the timeout occurs
detail_url = url_queue.get(timeout=25)
html = send_request(detail_url, headers, param=None)
html_obj = etree.HTML(html)
item = {}
# Date of publication
item['publishTime'] = html_obj.xpath(".//div[@class='info-primary']//span[@class='time']/text()")[0]
# Position Title
item['position'] = html_obj.xpath(".//div[@class='info-primary']//h1/text()")[0]
# Publisher's name
item['publisherName'] = html_obj.xpath("//div[@class='job-detail']//h2/text()")[0]
# Publisher position
item['publisherPosition'] = html_obj.xpath("//div[@class='detail-op']//p/text()")[0]
# salary
item['salary'] = html_obj.xpath(".//div[@class='info-primary']//span[@class='badge']/text()")[0]
# Corporate name
item['companyName'] = html_obj.xpath("//div[@class='info-company']//h3/a/text()")[0]
# Type of company
item['companyType'] = html_obj.xpath("//div[@class='info-company']//p//a/text()")[0]
# company size
item['companySize'] = html_obj.xpath("//div[@class='info-company']//p/text()")[0]
# Operating duty
item['responsibility'] = html_obj.xpath("//div[@class='job-sec']//div[@class='text']/text()")[0].strip()
# Recruitment Requirements
item['requirement'] = html_obj.xpath("//div[@class='job-banner']//div[@class='info-primary']//p/text()")[0]
print(item)
jobs_queue.put(item) # Add to the queue
time.sleep(15)
except:
pass
Save the data as a json file
The code is as follows:
def write_data(page):
"""
:brief Save the data as json file
:param page: Number of pages
:return: None
"""
with open('D:/wuhan_python_job_{}.json'.format(page), 'w', encoding='utf-8') as f:
f.write('[')
try:
while True:
job_dict = jobs_queue.get(timeout=25)
job_json = json.dumps(job_dict, indent=4, ensure_ascii=False)
f.write(job_json + ',')
except:
pass
f.seek(0, 2)
position = f.tell()
f.seek(position - 1, 0) # Remove the last comma
f.write(']')
json data example
{
"salary": "4K-6K",
"publisherName": "Zeng Lixiang",
"requirement": "City: Wuhan Experience: Graduate Degree: Undergraduate",
"responsibility": "1,2018 Graduated from the General Enrollment College, majoring in computer science; 2. Familiar with it. python Development; 3. Good communication and expression skills, strong learning ability, positive progress;",
"publishTime": "Published in 2018-06-11 12:15",
"companyName": "Yunzhihui Technology",
"position": "Software development( python,0 Years of experience)",
"publisherPosition": "HR Supervisor just online",
"companySize": "Unfinanced 500-999 people",
"companyType": "Computer software"}
Other
The existence of div
Label, xpath cannot get all the text content in the div tag (as shown below):

Solution: After getting the html text, remove the tag by regular expression in advance
The core code is as follows:
# Regular expressions: Remove the < br/> and < EM > </em> tags from the tags, and facilitate the use of xpath to parse and extract text
regx_obj = re.compile(r'<br/>|<(em).*?>.*?</\1>')
response = requests.get(url=url_path, params=param, headers=headers)
response = regx_obj.sub('', response.text)
When the crawling speed is too fast, the ip will be blocked. Here, multithreading is changed to single-threaded version, and time.sleep is used to reduce the crawling speed.