This article is from community users. Thank you for your technology sharing.
Brief Introduction of Jushan Database Architecture
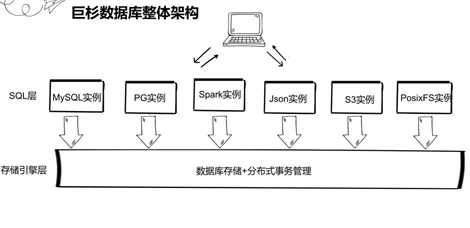
Jushan database, as a distributed database, is a computing and storage separation architecture, which consists of database instance layer and storage engine layer. Storage engine layer is responsible for database core functions such as data read-write storage and distributed transaction management. The database instance layer is also the SQL layer here, which is responsible for processing the application SQL requests and sending them to the storage engine layer, and feeding back the response results of the storage engine layer to the application layer. Structured instances such as MySQL instances / PG instances / spark instances are supported, and unstructured instances such as Json instances / S3 object storage instances / PosixFs instances are also supported. This architecture supports many types of instances, facilitates seamless migration from traditional databases to Jushan databases, reduces the cost of development and learning, and also communicates with colleagues in the database circle before, and they are very recognized for the architecture.
The SQL layer here uses MySQL instances, and the storage engine layer consists of three data nodes and coordinating point cataloging nodes. The data node is used to store data. The coordinating node does not store data. It is used to route MySQL requests to the database node. Catalog nodes are used to store cluster system information such as user information/partition information and so on. Here, a container is used to simulate a physical machine or cloud virtual machine. The MySQL instance is set in a container. The catalog and coordination points are placed in a container. The three data nodes are placed in a container. The three data nodes constitute three data groups, and each data group has three copies. Massive data in Web applications is distributed to different data nodes by fragmentation. Data ABC here is fragmented to three machines.
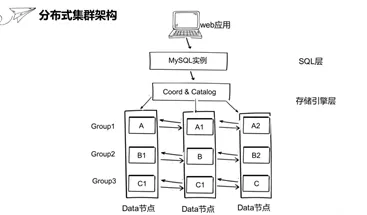
The data fragmentation here is implemented by DHT mechanism of distributed Hash algorithm, which is abbreviated as Distbute Hashing table. When writing data, the record is sent to the coordinating node through the MySQL instance. The coordinating node will hash each record according to the partition key through the distributed Hash algorithm. After hashing, the coordinating node will decide which partition to send according to the partition key, so the data between each partition is completely isolated from each other. Independent. With this method, we can split a large table into smaller tables in different sub-partitions below to achieve data splitting.
mysqldump and mydumper/myloader
Import and Export Tools
SequoiaDB is fully compatible with MySQL, so some users will ask:
"Since it is fully compatible, can MySQL-related tools be used?"
"How does data migrate from MySQL to SequoiaDB work?"
Next, we introduce how SequoiaDB uses mysqldump and mydumper/myloader to import and export data.
- mysqldump
1) Manufacturing test data through stored procedures
#mysql -h 127.0.0.1 -P 3306 -u root
mysql>create database news;
mysql>use news;
mysql>create table user_info(id int(11),unickname varchar(100));
delimiter //
create procedure `news`.`user_info_PROC`()
begin
declare iloop smallint default 0;
declare iNum mediumint default 0;
declare uid int default 0;
declare unickname varchar(100) default 'test';
while iNum <=10 do
start transaction;
while iloop<=10 do
set uid=uid+1;
set unickname=CONCAT('test',uid);
insert into `news`.`user_info`(id,unickname)
values(uid,unickname);
set iloop=iloop+1;
end while;
set iloop=0;
set iNum=iNum+1;
commit;
end while;
end//
delimiter ;
call news.user_info_PROC();2) View the status of manufacturing test data
mysql> use news; Database changed mysql> show tables; +----------------+ | Tables_in_news | +----------------+ | user_info | +----------------+ 1 row in set (0.00 sec) mysql> select count(*) from user_info; +----------+ | count(*) | +----------+ | 121 | +----------+ 1 row in set (0.01 sec)
3) Execute the following mysqldump backup instructions
#/opt/sequoiasql/mysql/bin/mysqldump -h 127.0.0.1 -P 3306 -u root -B news > news.sql
View the corresponding file as news.sql
Then log in to the database to delete the original database data
mysql> drop database news; Query OK, 1 row affected (0.10 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)
4) Importing new data with source
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
Using the complete sql statement exported by mysqldump, you can directly log in to the database to perform the import:
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root mysql>source news.sql mysql> use news; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with-A Database changed mysql> show tables; +----------------+ | Tables_in_news | +----------------+ | user_info | +----------------+ 1 row in set (0.00 sec)
As you can see, the returned results do support mysqldump data export tools and source import tools.
- mydumper and myloader use
This section describes the use of mydumper and myloader tools.
Some students are a little confused about mysqldump and mydumper: mysqldump comes from the original MySQL factory. mydumper/myloader is a set of logical backup and recovery tools developed and maintained by MySQL/Facebook and other companies. DBA is commonly used and needs to be installed separately. The specific installation method can be queried on the network.
For SequoiaDB using mydumper/myloader,
Let's first look at the version number of mydumper
# mydumper --version mydumper 0.9.1, built against MySQL 5.7.17
1) mydumper export data
# mydumper -h 127.0.0.1 -P 3306 -u root -B news -o /home/sequoiadb
Delete the original database
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | news | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) mysql> drop database news; Query OK, 1 row affected (0.13 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)
2) myloader imports data
You can see that the data has been deleted and imported using myloader
#myloader -h 127.0.0.1 -P 3306 -u root -B news -d /home/sequoiadb
Log in to the database to view
# /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | news | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) mysql> use news; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +----------------+ | Tables_in_news | +----------------+ | user_info | +----------------+ 1 row in set (0.00 sec) mysql> select count(*) from user_info; +----------+ | count(*) | +----------+ | 121 | +----------+ 1 row in set (0.00 sec)
Mydumper and myloader have no problem importing data. It seems that Sequoiadb does support MySQL compatible tools mydumper and myloader.
Migrating MySQL database data only needs to use mydumper to export MySQL data, then use myloader to import it into Jushan database in Jushan database.
summary
Jushan database adopts the architecture of separation of computation and storage, and achieves 100% complete compatibility of MySQL. Through this article, we can also see that Jushan database can support all standard MySQL peripheral tools, while distributed scalability will greatly enhance the scalability of existing applications and overall data management capabilities. Therefore, SequoiaDB is a powerful alternative to the traditional single-point MySQL scheme.