- Data Acquisition Section
- Information Records of Users Browsing Items
User Id Commodity Id Commodity types Add time userId itemId itemType time - Information Record of User Collections
User Id Id of Collection Goods Collection time userId collerctId collectTime - Information Record of User Adding Items to Shopping Cart
User Id Id added to shopping cart Add time userId cartId cartTime -
Information Record of User's Purchase Items
User Id Goods Id Purchased Add time userId consumeId consumeTime When the user performs the above actions, the corresponding log records are generated, the contents of the generated log files are merged into a log file, and then the log files are monitored by flume and uploaded to hdfs.
-
Note: flume is used to monitor the directory generated by each log. Whether a new log file is uploaded to hdfs or merged into a log file and uploaded to hdfs is not well considered. The format of merging and uploading is adopted first.
2.flume configuration
# Name the agent component score_agent.sources = r2 score_agent.sinks = k2 score_agent.channels = c2 #Monitoring Documents score_agent.sources.r2.type = exec #Configuration listener file path score_agent.sources.r2.command = tail -F /usr/local/flume1.8/test/recommend/score/score_test.log score_agent.sources.r2.shell = /bin/bash -c # File Output Location score_agent.sinks.k2.type = hdfs #HDFS paths, stored in the form of years, months, days, and hours score_agent.sinks.k2.hdfs.path = hdfs://ns/flume/recommend/score/%Y%m%d/%H #Prefix for uploading files score_agent.sinks.k2.hdfs.filePrefix = events- #Whether to scroll folders according to time score_agent.sinks.k2.hdfs.round = true #How much time to create a new folder score_agent.sinks.k2.hdfs.roundValue = 1 #Redefining unit of time score_agent.sinks.k2.hdfs.roundUnit = hour #Whether to use local timestamp score_agent.sinks.k2.hdfs.useLocalTimeStamp = true #How many Event s are saved to flush to HDFS once score_agent.sinks.k2.hdfs.batchSize = 1000 #Set file type to support compression score_agent.sinks.k2.hdfs.fileType = DataStream #How often to generate a new file, per second score_agent.sinks.k2.hdfs.rollInterval = 600 #Set the scroll size of each file to 128M in kb score_agent.sinks.k2.hdfs.rollSize = 134217728 #File scrolling is independent of the number of Event s score_agent.sinks.k2.hdfs.rollCount = 0 #Minimum Redundancy Number score_agent.sinks.k2.hdfs.minBlockReplicas = 1 # Use memory to save data score_agent.channels.c2.type = memory score_agent.channels.c2.capacity = 500000 score_agent.channels.c2.transactionCapacity = 600 # Binding source and sinks associations score_agent.sources.r2.channels = c2 score_agent.sinks.k2.channel = c2
3.MapReduce
3.1pom.xml
<dependencies> <!-- hadoop dependencies --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.7.3</version> </dependency> </dependencies>
3.2 StartRun
package com.htkj.recommend; import com.htkj.recommend.mapreduce.*; import org.apache.hadoop.conf.Configuration; import java.util.HashMap; import java.util.Map; public class StartRun { public static void main(String[] args){ Configuration conf=new Configuration(); // conf.set("mapreduce.app-submission.corss-paltform", "true"); // conf.set("mapreduce.framework.name", "local"); Map<String, String> paths = new HashMap<String, String>(); //The first step is to clean the data and repeat it. paths.put("CleanInput", "/test/recommend/input/"); paths.put("CleanOutput", "/test/recommend/output/clean"); //Step 2 Score Matrix of User Grouping User's Favor for Items paths.put("UserGroupingInput",paths.get("CleanOutput")); paths.put("UserGroupingOutput","/test/recommend/output/user_grouping"); //Step 3 Cooccurrence Matrix of Items Counting paths.put("ItemCountInput",paths.get("UserGroupingOutput")); paths.put("ItemCountOutput","/test/recommend/output/item_count"); //The fourth step is to multiply the co-occurrence matrix with the score matrix. paths.put("ScoreInput1", paths.get("UserGroupingOutput")); paths.put("ScoreInput2", paths.get("ItemCountOutput")); paths.put("ScoreOutput", "/test/recommend/output/score"); //The fifth step is to add the multiplied matrices to get the result matrix. paths.put("AllScoreInput", paths.get("ScoreOutput")); paths.put("AllScoreOutput", "/test/recommend/output/all_score"); //Step 6 Sort to get the top ten items paths.put("ResultSortInput", paths.get("AllScoreOutput")); paths.put("ResultSortOutput", "/test/recommend/output/result_sort"); // paths.put("CleanInput", "D:\\test\\user_bought_history.txt"); // paths.put("CleanInput", "D:\\test\\1.txt"); // paths.put("CleanOutput", "D:\\test\\test1"); // paths.put("UserGroupingInput",paths.get("CleanOutput")+"\\part-r-00000"); // paths.put("UserGroupingOutput","D:\\test\\test2"); // paths.put("ItemCountInput",paths.get("UserGroupingOutput")+"\\part-r-00000"); // paths.put("ItemCountOutput","D:\\test\\test3"); // paths.put("ScoreInput1", paths.get("UserGroupingOutput")+"\\part-r-00000"); // paths.put("ScoreInput2", paths.get("ItemCountOutput")+"\\part-r-00000"); // paths.put("ScoreOutput", "D:\\test\\test4"); // paths.put("AllScoreInput", paths.get("ScoreOutput")+"\\part-r-00000"); // paths.put("AllScoreOutput", "D:\\test\\test5"); // paths.put("ResultSortInput", paths.get("AllScoreOutput")+"\\part-r-00000"); // paths.put("ResultSortOutput", "D:\\test\\test6"); Clean.run(conf,paths); UserGrouping.run(conf,paths); ItemCount.run(conf,paths); Score.run(conf,paths); AllScore.run(conf,paths); ResultSort.run(conf,paths); } public static Map<String,Integer> action=new HashMap<String, Integer>(); static { action.put("click",1);//Click to count 1 point action.put("collect",2);//Collection calculates 2 points action.put("cart",3);//Add a shopping cart and count three points. action.put("alipay",4);//Payment calculates 4 points } }
3.3Clean
package com.htkj.recommend.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Map; public class Clean { public static boolean run(Configuration config, Map<String,String> paths){ try { FileSystem fs=FileSystem.get(config); Job job=Job.getInstance(config); job.setJobName("Clean"); job.setJarByClass(Clean.class); job.setMapperClass(CleanMapper.class); job.setReducerClass(CleanReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); FileInputFormat.addInputPath(job,new Path(paths.get("CleanInput"))); Path outpath=new Path(paths.get("CleanOutput")); if (fs.exists(outpath)){ fs.delete(outpath,true); } FileOutputFormat.setOutputPath(job,outpath); boolean f=job.waitForCompletion(true); return f; } catch (Exception e) { e.printStackTrace(); } return false; } static class CleanMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //The first line does not read here. The first line can be set to the header. if (key.get()!=0){ context.write(value,NullWritable.get()); } } } static class CleanReduce extends Reducer<Text, IntWritable,Text,NullWritable>{ @Override protected void reduce(Text key , Iterable<IntWritable> i, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } } }
3.4UserGrouping
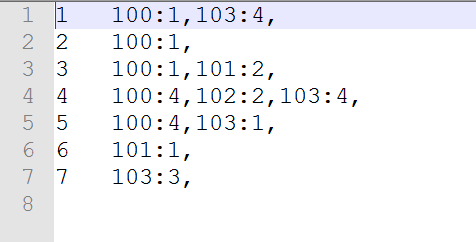
package com.htkj.recommend.mapreduce; import com.htkj.recommend.StartRun; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.HashMap; import java.util.Map; /* * Input data set * userId itemID action * 1 100 click * 1 101 collect * 1 102 cart * 1 103 alipay * * The output is as follows * userId itemID:Fraction * 1 100:1,101:2,102:3,103:4, * 2 100:1,101:1,102:1,103:4, * 3 100:1,101:2,102:2,103:4, * 4 100:4,101:2,102:2,103:4, */ public class UserGrouping { public static boolean run(Configuration config , Map<String,String> paths){ try { FileSystem fs=FileSystem.get(config); Job job=Job.getInstance(config); job.setJobName("UserGrouping"); job.setJarByClass(StartRun.class); job.setMapperClass(UserGroupingMapper.class); job.setReducerClass(UserGroupingReduce.class); job.setMapOutputValueClass(Text.class); job.setMapOutputKeyClass(Text.class); FileInputFormat.addInputPath(job,new Path(paths.get("UserGroupingInput"))); Path outpath=new Path(paths.get("UserGroupingOutput")); if (fs.exists(outpath)){ fs.delete(outpath,true); } FileOutputFormat.setOutputPath(job,outpath); boolean f=job.waitForCompletion(true); return f; } catch (Exception e) { e.printStackTrace(); } return false; } static class UserGroupingMapper extends Mapper<LongWritable, Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); String user = split[0];//1 String item = split[1];//100 String action = split[2];//click Text k=new Text(user);//1 // Integer rv= StartRun.action.get(action); //click=1 Integer rv=4; Text v=new Text(item+":"+rv.intValue());//100:1 context.write(k,v); /* * userId itemId:Fraction * 1 100:1 */ } } static class UserGroupingReduce extends Reducer<Text,Text,Text,Text>{ @Override protected void reduce(Text key, Iterable<Text> i, Context context) throws IOException, InterruptedException { Map<String, Integer> map = new HashMap<String, Integer>(); /* * userId 1 * itmId:Score 100:1 * 101:2 * 102:3 * 103:4 */ for (Text value : i) { String[] split = value.toString().split(":"); String item = split[0];//101 // Integer action = Integer.parseInt(split[1]);//2 Integer action=4; //If there is itemId action = Original Score + current action in the map set //For example, 101 items are clicked, collected, added to the shopping cart and purchased. The score of 101 is 1 + 2 + 3 + 4. if (map.get(item) != null) { action = ((Integer) map.get(item)).intValue() + action; } map.put(item,action);// } StringBuffer stringBuffer = new StringBuffer(); for (Map.Entry<String,Integer> entry:map.entrySet()){ stringBuffer.append(entry.getKey()+":"+entry.getValue().intValue()+",");//100:1, } context.write(key,new Text(stringBuffer.toString()));//1 100:1,101:2,102:3,103:4, } } }
3.5ItemCount
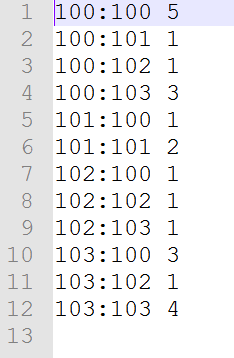
package com.htkj.recommend.mapreduce; import com.htkj.recommend.StartRun; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Map; /* *Counting the list of items combination and establishing the co-occurrence matrix of items *Input data set * userId itemID:Fraction * 1 100:1,101:2,102:3,103:4, * 2 100:1,101:1,102:1,103:4, * 3 100:1,101:2,102:2,103:4, * 4 100:4,101:2,102:2,103:4, *itemA:itemB frequency *100:100 7 *100:101 6 *100:102 6 *100:103 6 *101:100 6 *101:101 7 *101:100 6 * * */ public class ItemCount { private final static Text KEY=new Text(); private final static IntWritable VALUE=new IntWritable(1); public static boolean run(Configuration config , Map<String,String> paths){ try { FileSystem fs=FileSystem.get(config); Job job= Job.getInstance(config); job.setJobName("ItemCount"); job.setJarByClass(StartRun.class); job.setMapperClass(ItemCountMapper.class); job.setReducerClass(ItemCountReduce.class); job.setCombinerClass(ItemCountReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job,new Path(paths.get("ItemCountInput"))); Path outpath=new Path(paths.get("ItemCountOutput")); if (fs.exists(outpath)){ fs.delete(outpath,true); } FileOutputFormat.setOutputPath(job,outpath); boolean f = job.waitForCompletion(true); return f; } catch (Exception e) { e.printStackTrace(); } return false; } static class ItemCountMapper extends Mapper<LongWritable ,Text ,Text,IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { /* * userId itemID:Fraction * 1 100:1,101:2,102:3,103:4, * */ String[] s = value.toString().split("\t"); String[] items = s[1].split(",");//[100:1 101:2 102:3 103:4] for (int i = 0; i < items.length; i++) { String itemA = items[i].split(":")[0];//100 for (int j = 0; j < items.length; j++) { String itemB = items[j].split(":")[0];//The first is 100 and the second is 101. KEY.set(itemA+":"+itemB);//First 100:100 Second 100:101 context.write(KEY,VALUE);//The first 100:100 1 and the second 100:101 1 } } } } static class ItemCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> i, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable v : i) { sum=sum+v.get(); } VALUE.set(sum); context.write(key,VALUE); } } }
3.6Score
package com.htkj.recommend.mapreduce; import com.htkj.recommend.StartRun; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.regex.Pattern; /* *Multiply the co-occurrence matrix of items with the score matrix of users *Co-occurrence matrix A of input data set items *itemA:itemB frequency *100:100 7 *100:101 6 *100:102 6 *100:103 6 *101:100 6 *101:101 7 *101:100 6 * Score Matrix B for Input Data Set Users * userId itemID:Fraction * 1 100:1,101:2,102:3,103:4, * 2 100:1,101:1,102:1,103:4, * 3 100:1,101:2,102:2,103:4, * 4 100:4,101:2,102:2,103:4, * */ public class Score { public static boolean run(Configuration config, Map<String, String> paths) { try { FileSystem fs = FileSystem.get(config); Job job = Job.getInstance(config); job.setJobName("Score"); job.setJarByClass(StartRun.class); job.setMapperClass(ScoreMapper.class); job.setReducerClass(ScoreReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); Path[] inputPaths = {new Path(paths.get("ScoreInput1")), new Path(paths.get("ScoreInput2"))}; FileInputFormat.setInputPaths(job,inputPaths); Path outpath = new Path(paths.get("ScoreOutput")); if (fs.exists(outpath)) { fs.delete(outpath, true); } FileOutputFormat.setOutputPath(job, outpath); boolean f = job.waitForCompletion(true); System.out.println(f); return f; } catch (Exception e) { e.printStackTrace(); } return false; } static class ScoreMapper extends Mapper<LongWritable,Text,Text,Text>{ private String flag;//A Co-occurrence Matrix B Score Matrix @Override protected void setup(Context context){ FileSplit split= (FileSplit) context.getInputSplit(); flag=split.getPath().getParent().getName();//Judging Reading Data Set System.out.println(flag+"-------------------"); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] s = Pattern.compile("[\t]").split(value.toString()); if (flag.equals("item_count")){//Co-occurrence matrix//test3 item_count /* * itemA:itemB frequency * 100:101 6 * */ String[] split = s[0].split(":"); String item1 = split[0];//100 String item2 = split[1];//101 String num = s[1];//6 Text k = new Text(item1);//100 Text v = new Text("A:" + item2 + "," + num);//A:101,6 context.write(k,v);//100 A:101,6 }else if (flag.equals("user_grouping")){//Score matrix//test2 user_grouping /* * userId itemID:Fraction * 1 100:1,101:2,102:3,103:4, */ String userId = s[0];//1 String[] vector = s[1].split(",");//[100:1 101:2 102:3 103:4] for (int i = 0; i < vector.length; i++) { String[] split = vector[i].split(":"); String itemId=split[0];//i=0:100 String score = split[1];//1 Text k = new Text(itemId);//100 Text v = new Text("B:" + userId + "," + score);//B:1,1 context.write(k,v);//100 B:1,1 } } } } static class ScoreReduce extends Reducer<Text,Text,Text,Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Map<String,Integer> mapA=new HashMap<String, Integer>();//Item-based co-occurrence matrix A Map<String,Integer> mapB=new HashMap<String, Integer>();//Score Matrix B Based on User for (Text line : values) { String s = line.toString(); if (s.startsWith("A:")){// A:101,6 String[] split = Pattern.compile("[\t,]").split(s.substring(2)); try { mapA.put(split[0],Integer.parseInt(split[1]));//101 6(itemId num) }catch (Exception e){ e.printStackTrace(); } }else if (s.startsWith("B:")){//B:1,1 String[] split = Pattern.compile("[\t,]").split(s.substring(2)); try { mapB.put(split[0],Integer.parseInt(split[1]));//1 1(userId score) }catch (Exception e){ e.printStackTrace(); } } } double result=0; Iterator<String> iter = mapA.keySet().iterator();//Item-based co-occurrence matrix A while (iter.hasNext()){ String mapkey = iter.next();//itemId 101 int num = mapA.get(mapkey).intValue();//num 6 Iterator<String> iterB = mapB.keySet().iterator();//Score Matrix B Based on User while (iterB.hasNext()){ String mapBkey = iterB.next();//userId 1 int socre = mapB.get(mapBkey).intValue();//score 1 result=num*socre;//Matrix Multiplication Multiplication 6*1=6 Text k = new Text(mapBkey);//userId 1 Text v = new Text(mapkey + "," + result);//101,6 context.write(k,v);//1 101,6 } } } } }
3.7AllScore
package com.htkj.recommend.mapreduce; import com.htkj.recommend.StartRun; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.regex.Pattern; public class AllScore { public static boolean run(Configuration config, Map<String,String> paths){ try { FileSystem fs=FileSystem.get(config); Job job=Job.getInstance(config); job.setJobName("AllScore"); job.setJarByClass(StartRun.class); job.setMapperClass(AllScoreMapper.class); job.setReducerClass(AllSCoreReduce.class); job.setMapOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job,new Path(paths.get("AllScoreInput"))); Path outpath=new Path(paths.get("AllScoreOutput")); if (fs.exists(outpath)){ fs.delete(outpath,true); } FileOutputFormat.setOutputPath(job,outpath); boolean f=job.waitForCompletion(true); return f; } catch (Exception e) { e.printStackTrace(); } return false; } static class AllScoreMapper extends Mapper<LongWritable ,Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = Pattern.compile("[\t,]").split(value.toString()); Text k = new Text(split[0]); Text v = new Text(split[1] + "," + split[2]); context.write(k,v); } } static class AllSCoreReduce extends Reducer<Text,Text,Text,Text>{ @Override protected void reduce(Text key, Iterable<Text> values , Context context) throws IOException, InterruptedException { Map<String,Double> map=new HashMap<String, Double>(); for (Text line : values) { String[] split = line.toString().split(","); String itemId = split[0]; Double score = Double.parseDouble(split[1]); if (map.containsKey(itemId)){ map.put(itemId,map.get(itemId)+score);//Matrix Multiplication Sum Computation }else { map.put(itemId,score); } } Iterator<String> iter=map.keySet().iterator(); while (iter.hasNext()){ String itemId = iter.next(); Double score = map.get(itemId); Text v = new Text(itemId + "," + score); context.write(key,v); } } } }
3.8ResultSort
package com.htkj.recommend.mapreduce; import com.htkj.recommend.StartRun; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import java.util.Map; import java.util.regex.Pattern; public class ResultSort { private final static Text K = new Text(); private final static Text V = new Text(); public static boolean run(Configuration config, Map<String,String> paths){ try { FileSystem fs=FileSystem.get(config); Job job = Job.getInstance(config); job.setJobName("ResultSort"); job.setJarByClass(StartRun.class); job.setMapperClass(ResultSortMapper.class); job.setReducerClass(ResultSortRduce.class); job.setSortComparatorClass(SortNum.class); job.setGroupingComparatorClass(UserGroup.class); job.setMapOutputKeyClass(SortBean.class); job.setMapOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(paths.get("ResultSortInput"))); Path outpath = new Path(paths.get("ResultSortOutput")); if (fs.exists(outpath)){ fs.delete(outpath, true); } FileOutputFormat.setOutputPath(job, outpath); boolean f = job.waitForCompletion(true); return f; } catch (Exception e) { e.printStackTrace(); } return false; } static class SortBean implements WritableComparable<SortBean>{ private String userId; private double num; public int compareTo(SortBean o) { int i = this.userId.compareTo(o.getUserId()); if (i==0){ return Double.compare(this.num,o.getNum()); } return i; } public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(userId); dataOutput.writeDouble(num); } public void readFields(DataInput dataInput) throws IOException { this.userId=dataInput.readUTF(); this.num=dataInput.readDouble(); } public String getUserId(){ return userId; } public void setUserId(String userId){ this.userId=userId; } public double getNum(){ return num; } public void setNum(double num){ this.num=num; } } static class UserGroup extends WritableComparator{ public UserGroup(){ super(SortBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b ){ SortBean o1=(SortBean)a; SortBean o2=(SortBean)b; return o1.getUserId().compareTo(o2.getUserId()); } } static class SortNum extends WritableComparator{ public SortNum(){ super(SortBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b){ SortBean o1=(SortBean)a; SortBean o2=(SortBean)b; int i = o1.getUserId().compareTo(o2.getUserId()); if (i==0){ return -Double.compare(o1.getNum(), o2.getNum()); } return i; } } static class ResultSortMapper extends Mapper<LongWritable,Text, SortBean,Text>{ @Override protected void map(LongWritable key, Text value , Context context) throws IOException, InterruptedException { String[] split = Pattern.compile("[\t,]").split(value.toString()); String userId = split[0]; String item = split[1]; String num = split[2]; SortBean k = new SortBean(); k.setUserId(userId); k.setNum(Double.parseDouble(num)); V.set(item+":"+num); context.write(k,V); } } static class ResultSortRduce extends Reducer<SortBean,Text,Text,Text>{ @Override protected void reduce(SortBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { int i=0; StringBuffer stringBuffer = new StringBuffer(); for (Text v : values) { if (i==10){break;} stringBuffer.append(v.toString()+","); i++; } K.set(key.getUserId()); V.set(stringBuffer.toString()); context.write(K,V); } } }
4. Testing in Local Mode
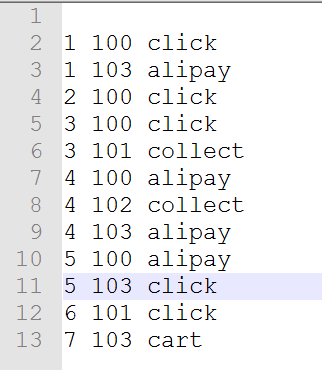
4.1 Test Data Set 1
4.2 Output of each stage
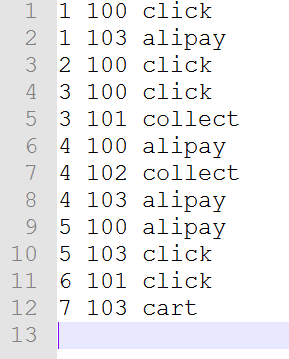
4.2.1 Clean
4.2.2UserGrouping
4.2.3ItemCount
4.2.4Score

4.2.6AllScore
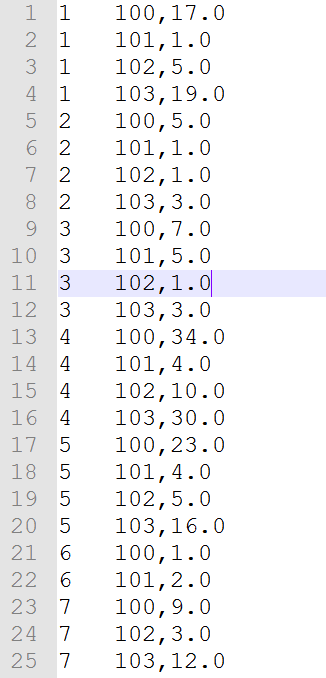
4.2.7ResultSort
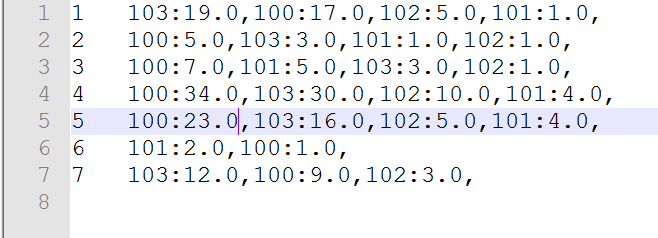
5. Running under Linux
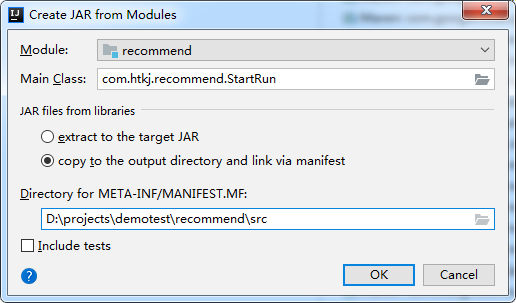
5.1 Put the project in jar package
Select the directory under src
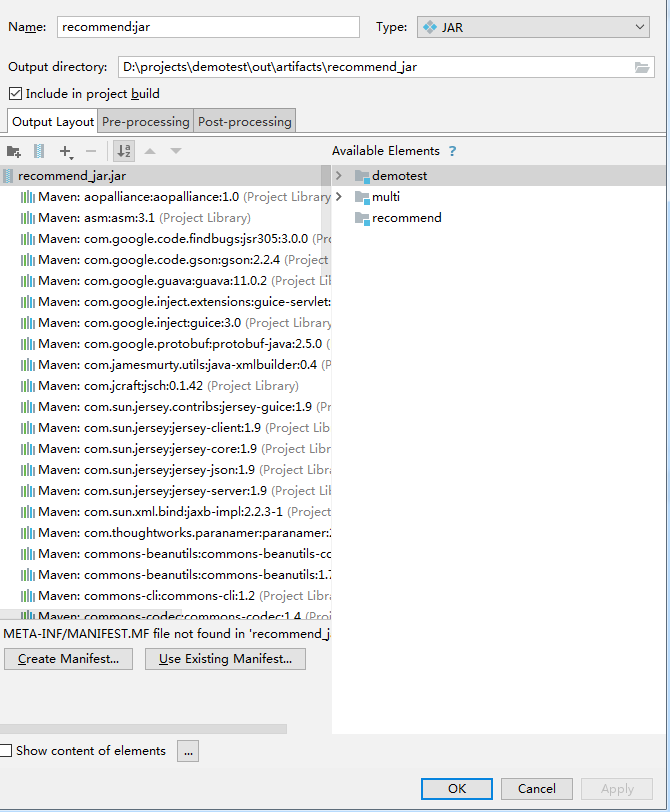
After compiling, find the Jar package file, open it and find recommend.jar, and upload it to Linux after decompression.
Function
Command: hadoop jar recommend.jar
- This command is followed by a parameter to write main, usually specifying the address of the file input, but here because the address has been set, so do not write.
- Later, it may be possible to change the specified input address to be specified by the main method's parameters by setting a timed task and analyzing it regularly once a day.
6. About testing
- How to judge the accuracy of the procedure?
Matrix can be computed manually through simple data sets to see if the results are consistent.
- How to Know the Precision of Recommendation
Extreme data sets can be set up for testing, such as user 1 buying a product with a number of 100, and other users buying a product with a number of 103 at the same time.
See if there are 103 items in the final recommendation.
7. Notes
- Collaborative filtering algorithm requires sparse matrix, that is to say, there is always an empty list of goods not bought.
- It's also very understandable that users can't see all the goods, or do other behavioral operations, or what else do they recommend?