The first step. First download the inverted character verification code recognition program of the Great God.
Download address: https://github.com/muchrooms/...
Note: This program relies on the following module packages
Keras==2.0.1
Pillow==3.4.2
jupyter==1.0.0
matplotlib==1.5.3
numpy==1.12.1
scikit-learn==0.18.1
tensorflow==1.0.1
h5py==2.6.0
numpy-1.13.1+mkl
We use Douban Garden to speed up the installation of dependencies such as:
pip install -i https://pypi.douban.com/simple h5py==2.6.0
If it's a win system, there may be a possibility of installation failure. If the package installation fails, then http://www.lfd.uci.edu/~gohlk ... find the corresponding version of win and download it to the local installation, such as:
pip install h5py-2.7.0-cp35-cp35m-win_amd64.whl
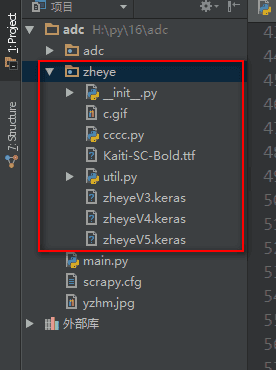
The second step is to put the zheye folder of the validation code recognition program into the project directory.
If you are still confused in the world of programming, you can join our Python Learning button qun: 784758214 to see how our predecessors learned. Exchange of experience. From basic Python script to web development, crawler, django, data mining, zero-base to actual project data are sorted out. To every Python buddy! Share some learning methods and small details that need attention. Click to join us. python learner gathering place
The third step, crawler implementation
The start_requests() method, the start url function, replaces the start_urls
Request() method, get way to request web pages
url = string type url
headers = Dictionary Type Browser Agent
meta = dictionary type data, passed to callback function
Callback = callback function name
scrapy.FormRequest()post submission of data
url = string type url
headers = Dictionary Type Browser Agent
meta = dictionary type data, passed to callback function
Callback = callback function name
formdata = dictionary type, data fields to submit
response.headers.getlist('Set-Cookie') Gets the response Cookies
response.request.headers.getlist('Cookie') Gets the request Cookies
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
class PachSpider(scrapy.Spider): #To define reptiles, you must inherit scrapy.Spider
name = 'pach' #Set the crawler name
allowed_domains = ['zhihu.com'] #Crawling Domain Names
# start_urls = [''] #Crawling Web addresses is only suitable for requests that do not require login, because cookie s and other information cannot be set up.
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #Setting up browser user agent
def start_requests(self): #The start url function replaces start_urls
"""The first time you request the login page, set it to open cookie Make it get cookie,Setting callback function"""
return [Request(
url='https://www.zhihu.com/#signin',
headers=self.header,
meta={'cookiejar':1}, #Open Cookies record and pass Cookies to callback function
callback=self.parse
)]
def parse(self, response):
# Response to Cookies
Cookie1 = response.headers.getlist('Set-Cookie') #Take a look at the response Cookie, which is the Cookie that was written to the browser in the background when you first visited the registration page.
print('Responses written in the background for the first time Cookies: ',Cookie1)
#Get xsrf cipher string
xsrf = response.xpath('//input[@name="_xsrf"]/@value').extract()[0]
print('Obtain xsrf Tandem:' + xsrf)
#Get the authentication code
import time
t = str(int(time.time()*1000))
captcha_url = 'https://Www.zhihu.com/captcha.gif?R={0}&type=login&lang=cn'.format(t)# Constructs a verification code request address
yield Request(url=captcha_url, #Request Verification Code Picture
headers=self.header,
meta={'cookiejar':response.meta['cookiejar'],'xsrf':xsrf}, #Pass Cookies and xsrf cipher strings to callback functions
callback=self.post_tj
)
def post_tj(self, response):
with open('yzhm.jpg','wb') as f: #Open Picture Handle
f.write(response.body) #Write Verification Code Picture Locally
f.close() #Close handle
#Authentication Code Recognition - ---------------------------------------------------------------------------------------------------------------------------------------------
from zheye import zheye #Importer also inverted character verification code recognition module object
z = zheye() #Instance object
positions = z.Recognize('yzhm.jpg') #The local path of the verification code is passed into Recognize method for recognition, and the coordinates of the inverted picture are returned.
# print(positions) #The default inverted text has y coordinates in front and x coordinates in back.
#The inverted text coordinates required by the Web are x-axis in front and y-axis in back, so we need to define a list to change the default inverted text coordinate position.
pos_arr = []
if len(positions) == 2:
if positions[0][1] > positions[1][1]: #Determine if the second element in the first meta-ancestor in the list is greater than the second element in the second meta-ancestor.
pos_arr.append([positions[1][1],positions[1][0]])
pos_arr.append([positions[0][1], positions[0][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
pos_arr.append([positions[1][1], positions[1][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
print('Processed Verification Code Coordinates',pos_arr)
# --------------------------------------------------------------------------------------------------------------------------------------
if len(pos_arr) == 2:
data = { # Set up user login information and grab the fields corresponding to the package
'_xsrf': response.meta['xsrf'],
'password': '279819',
'captcha': '{"img_size":[200,44],"input_points":[[%.2f,%f],[%.2f,%f]]}' %(
pos_arr[0][0] / 2, pos_arr[0][1] / 2, pos_arr[1][0] / 2, pos_arr[1][1] / 2), #Because the verification code recognition defaults to the size of 400X88, divide it by 2
'captcha_type': 'cn',
'phone_num': '15284816568'
}
else:
data = { # Set up user login information and grab the fields corresponding to the package
'_xsrf': response.meta['xsrf'],
'password': '279819',
'captcha': '{"img_size":[200,44],"input_points":[[%.2f,%f]]}' %(
pos_arr[0][0] / 2, pos_arr[0][1] / 2),
'captcha_type': 'cn',
'phone_num': '15284816568'
}
print('Log in and submit data',data)
print('Login in....!')
"""Form for the second time post Request, carry Cookie,Browser agent, user login information, login to Cookie To grant authorization"""
return [scrapy.FormRequest(
url='https://www.zhihu.com/login/phone_num', #real post address
meta={'cookiejar':response.meta['cookiejar']}, #Receive the first Cookies
headers=self.header,
formdata=data,
callback=self.next
)]
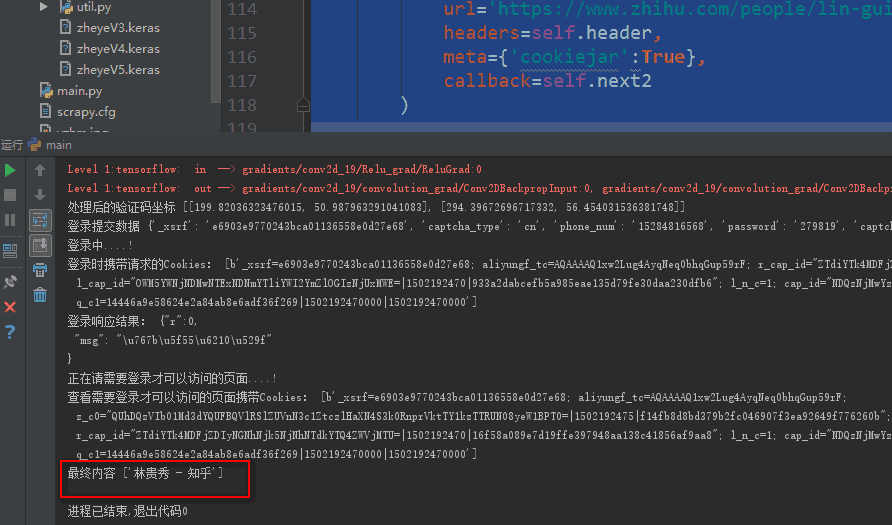
def next(self,response):
# Request Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print('With the request on login Cookies: ',Cookie2)
jieg = response.body.decode("utf-8") #After login, you can check the login response information.
print('Login response results:',jieg)
print('Pages that you need to log in to access....!')
"""A page that requires login to view after login, such as the Personal Center, carries authorized pages. Cookie request"""
yield Request(
url='https://www.zhihu.com/people/lin-gui-xiu-41/activities',
headers=self.header,
meta={'cookiejar':True},
callback=self.next2
)
def next2(self,response):
# Request Cookie
Cookie3 = response.request.headers.getlist('Cookie')
print('View page portability that requires login to access Cookies: ',Cookie3)
leir = response.xpath('/html/head/title/text()').extract() #Get the Personal Center Page
print('Final content',leir)
# print(response.body.decode("utf-8"))