Requirements encountered
Some time ago, we need to quickly make a static display page, which requires a more responsive and beautiful. Because of the short time and the trouble of writing by oneself, I intend to go online to find ready-made words.
In the middle of the way, I found several pages that were good, and then I began to think about how to download the pages. "
Compile a set of Python materials and PDF, Python learning materials can be added to the learning group if necessary: 631441315, anyway, idle is also idle, it is better to learn something!~~
Since I haven't known about crawlers before, I naturally didn't think that crawlers can be used to grab web content. So my approach is:
- Open the chrome console and enter the Application option
- Find the Frames option, find the html file, and right-click Save As...
- Manually create the local js/css/images directory
- Open Images/Scripts/Stylesheets under the Frames option in turn, and right-click Save As for a file.
This was the best way I could think of at that time. However, this artificial method has the following shortcomings:
- Manual operation, troublesome and time-consuming
- If you are not careful, you will forget which file to save.
- It's hard to deal with the relationship between paths, such as a picture a.jpg, which is referenced in html by images/banner/a.jpg, so we have to solve path dependencies manually in the future.
Then just a few days ago, I contacted a little Python and thought that I could write a python crawler to help me automatically crawl static websites. So immediately start, refer to relevant information and so on.
Next, I will share with you the whole process of crawler crawling static websites in detail.
Pre-knowledge Reserve
In the following code practice, we use python knowledge, regular expressions and so on. The core technology is regular expressions.
Let's have a look.
Basic knowledge of Python
If you've ever studied other languages before, I'm sure you can start python soon. For specific learning, you can check the official python documentation or other tutorials.
The concept of reptiles
Crawler, as I understand it, is actually an automatic computer program. In the field of web, the premise of its existence is to simulate the behavior of users in the browser.
Its principle is to simulate the user visiting the web page, get the content of the web page, then analyze the content of the web page, find out what we are interested in, and finally process the data.
The flow chart is as follows:

There are several popular reptilian mainstream implementations:
- Grab the content of the web page by yourself, and then implement the analysis process by yourself
- Crawler frameworks written by others, such as Scrapy
regular expression
concept
Regular expression is a string composed of a series of meta-characters and common characters. Its function is to match the text according to certain rules, and finally make a series of processing for the text.
Metacharacters are reserved characters in regular expressions. They have special matching rules, such as * representing matching 0 to infinite times, ordinary characters are abcd and so on.
For example, in the front-end, a common operation is to determine whether the user's input is empty. At this time, we can match it by regular expression. First, we filter out the blank values on both sides of the user's input. The specific implementation is as follows:
function trim(value) { return value.replace(/^\s+|\s+$/g, '') } // Output = > "Python Reptile" trim(' Python Reptile ');
Let's take a look at the metacharacters in regular expressions.
Metacharacters in Regular Expressions
Above, we said that meta-characters are reserved characters in regular expressions. They have special matching rules, so we should first understand the frequently occurring meta-characters.
Metacharacters matching a single character
- Represents matching an arbitrary character, except for n (newline character), such as matching arbitrary alphanumeric, etc.
- [...] denotes a character group, which can contain any character. It only matches any one of them. For example, [a b c] can match a or b or C. It is worth noting that the meta-characters in a character group are sometimes treated as ordinary characters, such as [-*?] and so on. It represents only - or * or?, not - intervals.* Represents 0 to infinite matches, 0 or 1 matches.
- Contrary to the meaning of [...], it means matching a character that does not belong to [...], not a character that does not match [...]. These two statements are subtle but very different. The former stipulates that a character must be matched, which is a must.
Example: [^ 123] can match 4/5/6, etc., but not 1/2/3
Metacharacters that provide counting
- * Represents matching 0 to infinite times, and can not match any character
- + Represents matching once to infinite times, at least once
- Represents matching 0 or 1 times
- {min, max} represents matching min times to Max times, such as a{3, 5} means that a matches at least 3-5 times.
Metacharacters that provide location
- ^ Represents the beginning of a matching string, such as ^ a indicates that a will appear at the beginning of a string, and bcd does not match.
- $represents the end of the matching string, such as A $indicates that A will appear at the end of the string, and ABAB does not match.
Other metacharacters
- | Represents a range that can match arbitrary subexpressions, such as abc|def, abc or def, and abd
- (...) Represents grouping. It defines the scope of subexpressions and combines them with metacharacters that provide functionality, such as (abc|def) + Represents ABC or def that can match one or more times, such as abcabc, def
- \ i stands for reverse reference, i can be an integer of 1/2/3, which means matching content in the previous (). For example, matching (abc) +(12)* 1 2. If the matching is successful, the content of 1 is abc, and the content of 2 is 12 or empty. Back references are usually used in matching "" or "'
Look around
What I understand is that looping defines what happens to the left and right text of the current matching subexpression. The looping itself does not occupy the matching character. It is the matching rule of the current subexpression but does not count itself into the matching text. The meta-characters mentioned above all represent certain rules and occupy certain characters. Circumference can be divided into four categories: positive sequence circumference, negative sequence circumference, positive reverse sequence circumference and negative reverse sequence circumference. Their workflow is as follows:
- Affirmative sequential lookup: First find the initial position of the text in the lookup on the right, and then start matching characters from the leftmost position of the matched text on the right.
- Negative sequential lookup: First find the initial position of the text in the lookup that does not appear on the right, and then start matching characters from the leftmost position of the matched text on the right.
- Affirmative reverse looping: First find the initial position of the text in the looping on the left, and then start matching characters from the rightmost position of the matched text on the left.
- Negative reverse looping: First find the initial position of the text in the looping that does not appear on the left, and then start matching characters from the rightmost position of the matched text on the left.
Affirmative sequential glance
The condition for successful sequential looping matching is that the current subexpression can match the right text, which is written as (?=...),... Representing the content to be looped. For example, the regular expression (?= he llo) he means to match the text containing hello. It only matches the location, does not match the specific characters. After matching to the location, it really matches the occupied character is he, so it can match LLO and so on.
For (?= hello)he, hello world can match successfully, while hell world fails. The code is as follows:
import re reg1 = r'(?=hello)he' print(re.search(reg1, 'hello world')) print(re.search(reg1, 'hell world hello')) print(re.search(reg1, 'hell world')) # Output result <_sre.SRE_Match object; span=(0, 2), match='he'> <_sre.SRE_Match object; span=(11, 13), match='he'> None
Negative Sequence Looking around
Negative sequential lookup matching succeeds only if the current subexpression does not match the right text. It is written in (?!),... To represent the content to be looped, or in the example above, such as the regular expression (?! hello)he, which means matching the text that is not hello, locating it, and then matching him.
Examples are as follows:
import re reg2 = r'(?!hello)he' print(re.search(reg2, 'hello world')) print(re.search(reg2, 'hell world hello')) print(re.search(reg2, 'hell world')) # Output result None <_sre.SRE_Match object; span=(0, 2), match='he'> <_sre.SRE_Match object; span=(0, 2), match='he'>
Positive Reverse Sequence Looking around
The positive condition for successful reverse looping matching is that the current subexpression can match the left text. It is written as (?<=...),... Representing the content to be looped, such as the regular expression (?<= hello) - Python means to match the subexpression containing - python, and its left side must appear hello, Hello matches only the location, not the same. With specific characters, the real occupied character is the following - python.
Examples are as follows:
import re reg3 = r'(?<=hello)-python' print(re.search(reg3, 'hello-python')) print(re.search(reg3, 'hell-python hello-python')) print(re.search(reg3, 'hell-python')) # Output result <_sre.SRE_Match object; span=(5, 12), match='-python'> <_sre.SRE_Match object; span=(17, 24), match='-python'> None
Negative Reverse Sequence Looking around
Negative reverse looping matching success condition is that the current sub-expression can not match the left text, it is written (?<!),... Representing the content to be looped, such as regular expression (?<! Hello) - Python means to match the sub-expression containing - python, and its left must not appear hello.
Examples are as follows:
import re reg3 = r'(?<=hello)-python' print(re.search(reg3, 'hello-python')) print(re.search(reg3, 'hell-python hello-python')) print(re.search(reg3, 'hell-python')) # Output result <_sre.SRE_Match object; span=(5, 12), match='-python'> <_sre.SRE_Match object; span=(17, 24), match='-python'> None
Looking around is very effective in inserting certain characters into a string. You can use it to match positions and then insert the corresponding characters without replacing the original text.
Capture packet
In regular expressions, grouping can help us extract specific information we want.
It's easy to specify grouping by adding () to both ends of the expression you want to capture. In python, we can use re.search(reg, xx).groups() to get all the groups.
The default () specifies a group whose serial number is I and I is retrieved by re.search(reg, xx).group(i) from 1.
If you don't want to capture a packet, you can use (?:...) to specify it.
Specific examples are as follows:
import re reg7 = r'hello,([a-zA-Z0-9]+)' print(re.search(reg7, 'hello,world').groups()) print(re.search(reg7, 'hello,world').group(1)) print(re.search(reg7, 'hello,python').groups()) print(re.search(reg7, 'hello,python').group(1)) # Output result ('world',) world ('python',) python
Greedy matching
Greedy matching means that regular expressions match as many characters as possible, that is, they tend to match the maximum length.
Regular expressions default to greedy mode.
Examples are as follows:
import re reg5 = r'hello.*world' print(re.search(reg5, 'hello world,hello python,hello world,hello javascript')) # Output result <_sre.SRE_Match object; span=(0, 36), match='hello world,hello python,hello world'>
As you can see from the above, it matches hello world,hello python,hello world, not the first hello world. So if we just want to match the initial Hello world, then we can use the non-greedy pattern of regular expressions.
Non-greedy matching is just the opposite of greedy matching. It means matching as few characters as possible and ending as long as the matching is done. To use the greedy pattern, just add a question mark (?) after the quantifier.
Or just that example:
import re reg5 = r'hello.*world' reg6 = r'hello.*?world' print(re.search(reg5, 'hello world,hello python,hello world,hello javascript')) print(re.search(reg6, 'hello world,hello python,hello world,hello javascript')) # Output result <_sre.SRE_Match object; span=(0, 36), match='hello world,hello python,hello world'> <_sre.SRE_Match object; span=(0, 11), match='hello world'>
As you can see from above, this is the effect we just wanted to match.
Entry into development
With the above basic knowledge, we can enter the development process.
The ultimate effect we want to achieve
Our ultimate goal is to write a simple python crawler, which can download a static web page and download its static resources (such as js/css/images) under the relative path of maintaining the reference resources of the web page. The test website is http://www.peersafe.cn/index.html. The results are as follows:
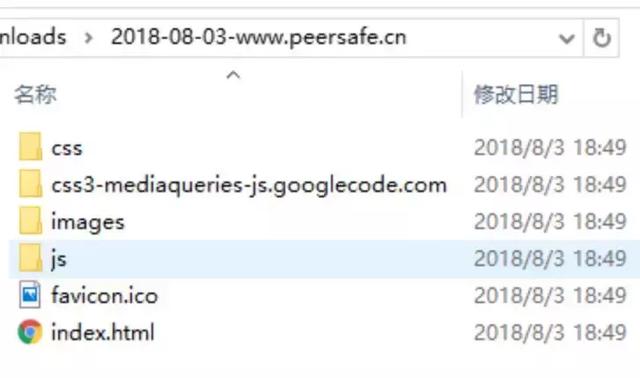
Development process
Our general idea is to get the content of the web page first, then use regular expressions to extract the resource links we want, and finally download the resources.
Getting Web Content
We use urllib.http, which comes with Python 3, to make http requests, or you can use third-party request libraries requests.
Part of the code to get the content is as follows:
url = 'http://www.peersafe.cn/index.html' # Read Web Content webPage = urllib.request.urlopen(url) data = webPage.read() content = data.decode('UTF-8') print('> The content of the website is captured and the length of the content is as follows:', len(content))
After getting the content, we need to save it, that is, write it to the local disk. We define a SAVE_PATH path, which represents a file specifically placed for crawler downloads.
# python-spider-downloads It's the catalogue we want to place. # Recommended here os Module to get the current directory or splice path # Direct use is not recommended'F://Xxx'+'//python-spider-downloads' and so on SAVE_PATH = os.path.join(os.path.abspath('.'), 'python-spider-downloads')
The next step is to create a separate folder for the site. The site folder format is XX xx-xx-xx-domain, such as 2018-08-03-www.peersafe.cn. Before that, we need to write a function to extract a url link domain name, relative path, request file name and request parameters, etc., which will be used in the subsequent creation of the corresponding folder according to the reference mode of the resource file.
For example, if you enter http://www.peersafe.cn/index.html, you will output:
{'baseUrl': 'http://www.peersafe.cn', 'fullPath': 'http://www.peersafe.cn/', 'protocol': 'http://', 'domain
': 'www.peersafe.cn', 'path': '/', 'fileName': 'index.html', 'ext': 'html', 'params': ''}
Part of the code is as follows:
REG_URL = r'^(https?://|//)?((?:[a-zA-Z0-9-_]+\.)+(?:[a-zA-Z0-9-_:]+))((?:/[-_.a-zA-Z0-9]*?)*)((?<=/)[-a-zA-Z0-9]+(?:\.([a-zA-Z0-9]+))+)?((?:\?[a-zA-Z0-9%&=]*)*)$' regUrl = re.compile(REG_URL) # ... ''' //Resolving URL addresses ''' def parseUrl(url): if not url: return res = regUrl.search(url) # Here we put 192.168.1.109:8080 Forms are also resolved into domain names domain,Actual process www.baidu.com Wait is the domain name, 192.168.1.109 just IP address # ('http://', '192.168.1.109:8080', '/abc/images/111/', 'index.html', 'html', '?a=1&b=2') if res is not None: path = res.group(3) fullPath = res.group(1) + res.group(2) + res.group(3) if not path.endswith('/'): path = path + '/' fullPath = fullPath + '/' return dict( baseUrl=res.group(1) + res.group(2), fullPath=fullPath, protocol=res.group(1), domain=res.group(2), path=path, fileName=res.group(4), ext=res.group(5), params=res.group(6) ) ''' //Analytic path eg: basePath => F:\Programs\python\python-spider-downloads resourcePath => /a/b/c/ or a/b/c return => F:\Programs\python\python-spider-downloads\a\b\c ''' def resolvePath(basePath, resourcePath): # Resolving Resource Path res = resourcePath.split('/') # Remove empty directories /a/b/c/ => [a, b, c] dirList = list(filter(lambda x: x, res)) # Catalogue is not empty if dirList: # Stitching out absolute paths resourcePath = reduce(lambda x, y: os.path.join(x, y), dirList) dirStr = os.path.join(basePath, resourcePath) else: dirStr = basePath return dirStr
The above regular expression REG_URL is a bit long. This regular expression can parse all kinds of url forms I encounter at present. If you can't parse them, you can supplement them by yourself. The list of URLs I tested can be viewed in my github.
First of all, for the most complex url links (such as'http://192.168.1.109:8080/abc/images/111/index.html? A=1&b=2'), we want to extract http:/, 192.168.1.109:8080, / abc/images/111/, index.html,?A=1&b=2, respectively. The purpose of extracting / ABC / images / 111 / is to prepare for future directory creation. Index. html is the name of the content written to the web page.
If necessary, we can study the REG_URL in depth. If there is something better or we can't understand it, we can discuss it together.
With the parseUrl function, we can associate what we just got from the web page with what we wrote to the file. The code is as follows:
# First create the folder for this site urlDict = parseUrl(url) print('Analytical domain names:', urlDict) domain = urlDict['domain'] filePath = time.strftime('%Y-%m-%d', time.localtime()) + '-' + domain # If it is 192.168.1.1:8000 Equal form, 192.168.1.1-8000,:Can't appear in the filename filePath = re.sub(r':', '-', filePath) SAVE_PATH = os.path.join(SAVE_PATH, filePath) # Read Web Content webPage = urllib.request.urlopen(url) data = webPage.read() content = data.decode('UTF-8') print('> The content of the website is captured and the length of the content is as follows:', len(content)) # Write down the content of the website pageName = '' if urlDict['fileName'] is None: pageName = 'index.html' else: pageName = urlDict['fileName'] pageIndexDir = resolvePath(SAVE_PATH, urlDict['path']) if not os.path.exists(pageIndexDir): os.makedirs(pageIndexDir) pageIndexPath = os.path.join(pageIndexDir, pageName) print('Address of Home Page:', pageIndexPath) f = open(pageIndexPath, 'wb') f.write(data) f.close()
Extracting useful resource links
The resources we want are image resources, JS files, css files and font files. If we want to parse the content one by one and use grouping to capture the links we want, such as images/1.png and scripts/lib/jquery.min.js.
The code is as follows:
REG_RESOURCE_TYPE = r'(?:href|src|data\-original|data\-src)=["\'](.+?\.(?:js|css|jpg|jpeg|png|gif|svg|ico|ttf|woff2))[a-zA-Z0-9\?\=\.]*["\']' # re.S Represents opening multi-line matching mode regResouce = re.compile(REG_RESOURCE_TYPE, re.S) # ... # Parse the content of web pages to get effective links # content Is the content of the page read in the previous step contentList = re.split(r'\s+', content) resourceList = [] for line in contentList: resList = regResouce.findall(line) if resList is not None: resourceList = resourceList + resList
Download resources
After resolving the resource links, we need to check each resource link and turn it into a url format that meets the HTTP request, such as adding images/1.png to the HTTP header and the just domain, which is http://domain/images/1.png.
The following is the code for processing resource links:
# ./static/js/index.js # /static/js/index.js # static/js/index.js # //abc.cc/static/js # http://www.baidu/com/static/index.js if resourceUrl.startswith('./'): resourceUrl = urlDict['fullPath'] + resourceUrl[1:] elif resourceUrl.startswith('//'): resourceUrl = 'https:' + resourceUrl elif resourceUrl.startswith('/'): resourceUrl = urlDict['baseUrl'] + resourceUrl elif resourceUrl.startswith('http') or resourceUrl.startswith('https'): # No, that's what we want. url format pass elif not (resourceUrl.startswith('http') or resourceUrl.startswith('https')): # static/js/index.js This situation resourceUrl = urlDict['fullPath'] + resourceUrl else: print('> Unknown resource url: %s' % resourceUrl)
Next, parse Url is used to extract the directory and file name of each specification, and then create the corresponding directory.
Here, I also deal with the resources of other sites cited.
# Parse files and view file paths resourceUrlDict = parseUrl(resourceUrl) if resourceUrlDict is None: print('> Error parsing file:%s' % resourceUrl) continue resourceDomain = resourceUrlDict['domain'] resourcePath = resourceUrlDict['path'] resourceName = resourceUrlDict['fileName'] if resourceDomain != domain: print('> This resource is not available on this website. It is also downloaded:', resourceDomain) # If you download it, the root directory will change. # Create a directory to save resources elsewhere resourceDomain = re.sub(r':', '-', resourceDomain) savePath = os.path.join(SAVE_PATH, resourceDomain) if not os.path.exists(SAVE_PATH): print('> The target directory does not exist. Create:', savePath) os.makedirs(savePath) # continue else: savePath = SAVE_PATH # Resolving Resource Path dirStr = resolvePath(savePath, resourcePath) if not os.path.exists(dirStr): print('> The target directory does not exist. Create:', dirStr) os.makedirs(dirStr) # write file downloadFile(resourceUrl, os.path.join(dirStr, resourceName))
The downloadFile function downloads the following code:
''' //Download File ''' def downloadFile(srcPath, distPath): global downloadedList if distPath in downloadedList: return try: response = urllib.request.urlopen(srcPath) if response is None or response.status != 200: return print('> Request exception:', srcPath) data = response.read() f = open(distPath, 'wb') f.write(data) f.close() downloadedList.append(distPath) # print('>>>: ' + srcPath + ': Download successful') except Exception as e: print('Wrong report:', e)
These are the whole process of our development.
Knowledge summary
The technology used in this development
- Using urllib.http to send network requests
- Resolving Resource Links Using Regular Expressions
- Using os system module to deal with file path problem
Experience
This article is also a practical summary of my study of python during this period, by the way, record the knowledge of regular expressions. At the same time, I hope to be able to help those who want to learn regular expressions and crawlers.