https://www.hkexnews.hk/sdw/search/searchsdw_c.aspx
The website supports inquiring about the daily holding data of Shanghai and Hong Kong Stock Exchange Stock Holdings Institutions/Securities Firms, which is valid for less than one year. Popularly speaking, it is said in the news that the number of stocks sold and sold by Niu Jin's capital in the north every day can reflect the popularity of foreign capital to the company to a certain extent.
The idea of doing this crawler was actually half a year ago, because the company I own in Yili was bought up by foreign investors. So I want to do some research by analyzing the proportion of foreign capital. But because I did not learn Python at that time, it was a page-by-page manual Ctrl+C plus Ctrl+V. Tired, are tears. Reference to a little information, and get the master's advice, and finally done, thank you.
Good nonsense, first code.
from lxml import etree
import requests
import csv
import os
headers={"User-Agent":"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36"}
url="https://www.hkexnews.hk/sdw/search/searchsdw_c.aspx"
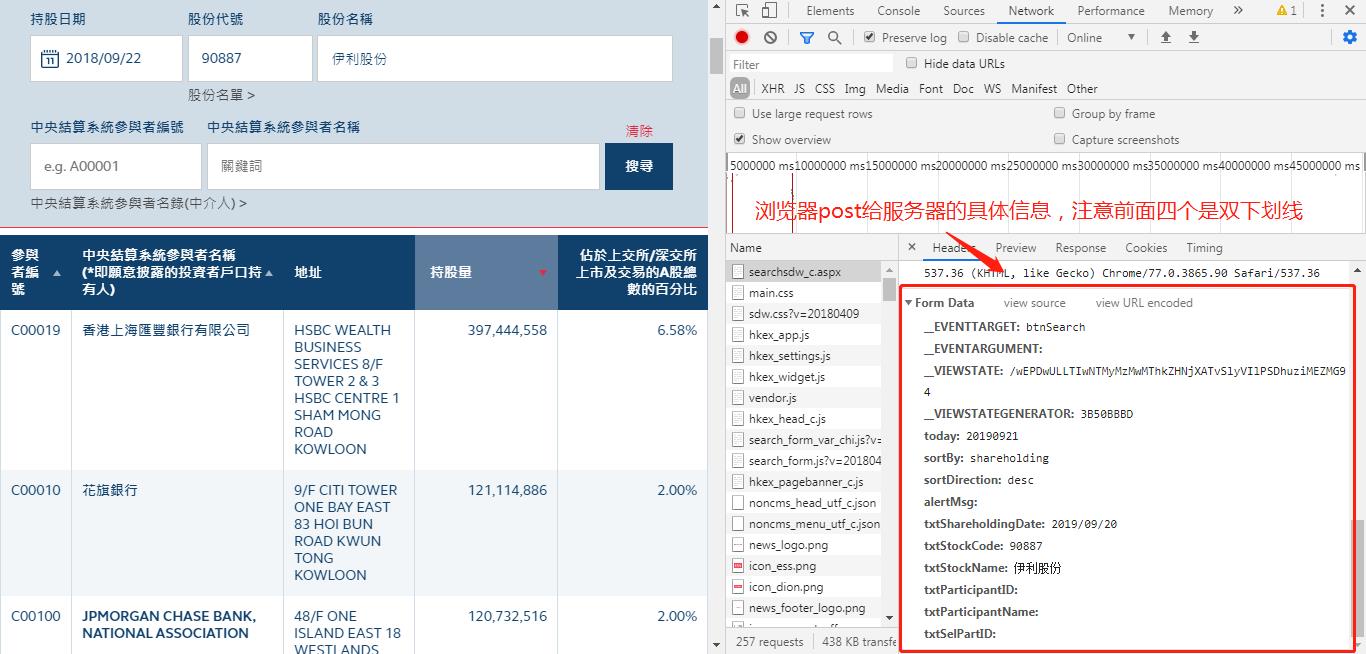
datatime = {'__EVENTTARGET': 'btnSearch',
'__EVENTARGUMENT':'',
'__VIEWSTATE': '/wEPDwULLTIwNTMyMzMwMThkZHNjXATvSlyVIlPSDhuziMEZMG94',
'__VIEWSTATEGENERATOR': '3B50BBBD',
'today': '20190922',
'sortBy': 'shareholding',
'sortDirection': 'desc',
'alertMsg':'',
'txtShareholdingDate': '2019/08/22',
'txtStockCode': '90887',
'txtStockName': 'Erie shares',
'txtParticipantID':'',
'txtParticipantName':''
}
repensoe=requests.post(url,headers=headers,data=datatime)
text=repensoe.text
html1 = etree.HTML(text)
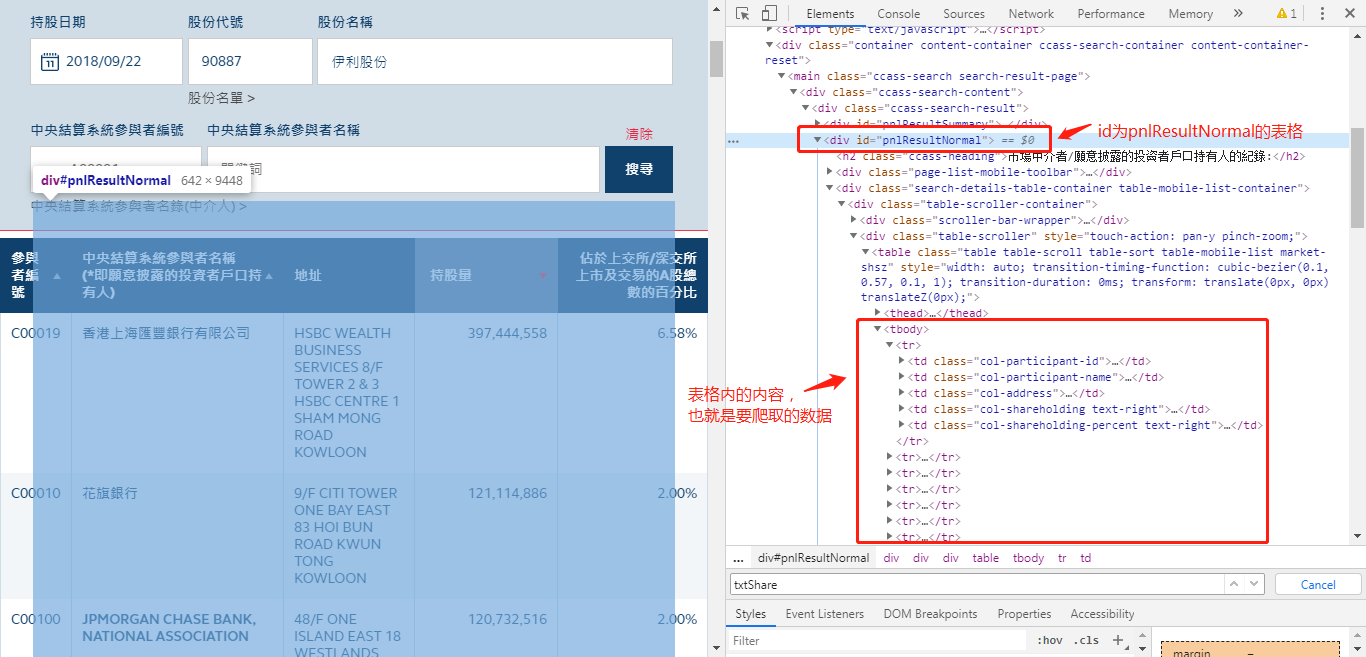
div = html1.xpath("//div[@id='pnlResultNormal']//tbody/tr")
data = []
print("--" * 2)
valuetime = html1.xpath("//input[@id='txtShareholdingDate']/@value")
print(valuetime[0]+"Data available")
for tb in div:
participant_id = tb.xpath("./td[1]/div/text()")[1]
participant_name = tb.xpath("./td[2]/div/text()")[1]
participant_address = tb.xpath("./td[3]/div/text()")[1]
right = tb.xpath("./td[4]/div/text()")[1]
percent = tb.xpath("./td[5]/div/text()")[1]
datadic = {"date": valuetime[0], "Participant number": participant_id, "Central System Participant Name": participant_name, "address": participant_address, "Shareholding": right,"Proportion": percent}
data.append(datadic)
filenme = '20190822' + ".csv"
csvhead = ["date", "Participant number", "Central System Participant Name", "address", "Shareholding","Proportion"]
os.getcwd()
os.chdir("D:\\600887")
with open(filenme, 'w', newline='') as fp:
write = csv.DictWriter(fp, csvhead)
write.writeheader()
write.writerows(data)
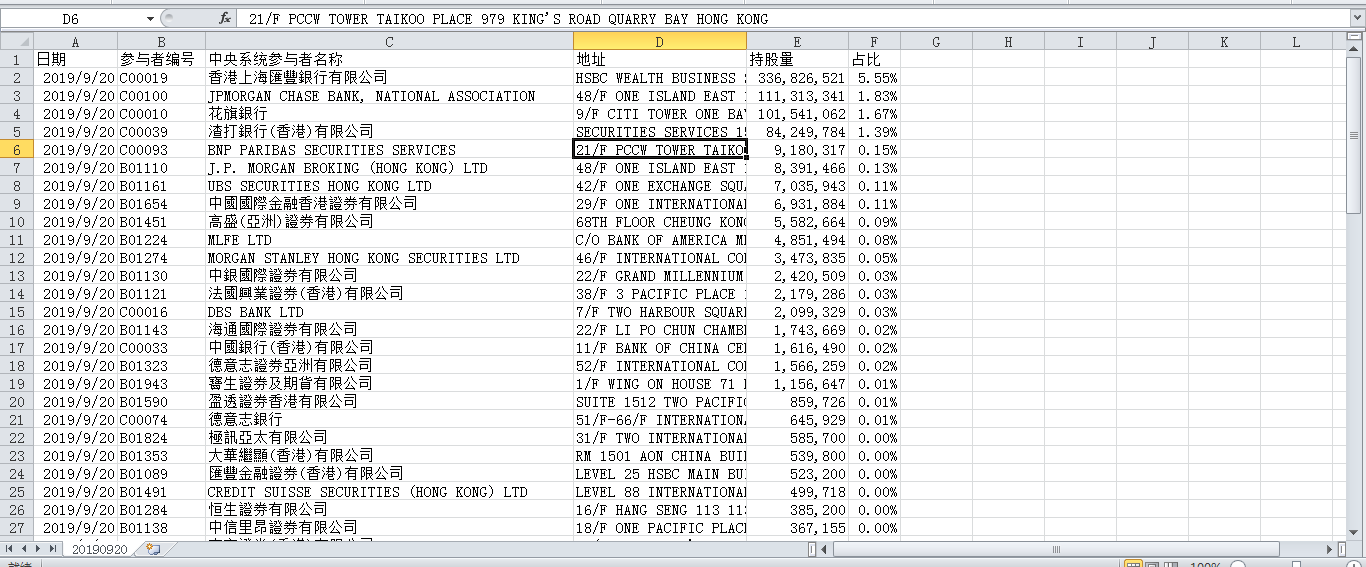
This code automatically retrieves the data of the specified date and automatically saves it as a *. CSV file to the D: 600887 folder.
Program calls, requests library to obtain data, lxml library to parse data, csv and os library to export csv files to the specified folder.
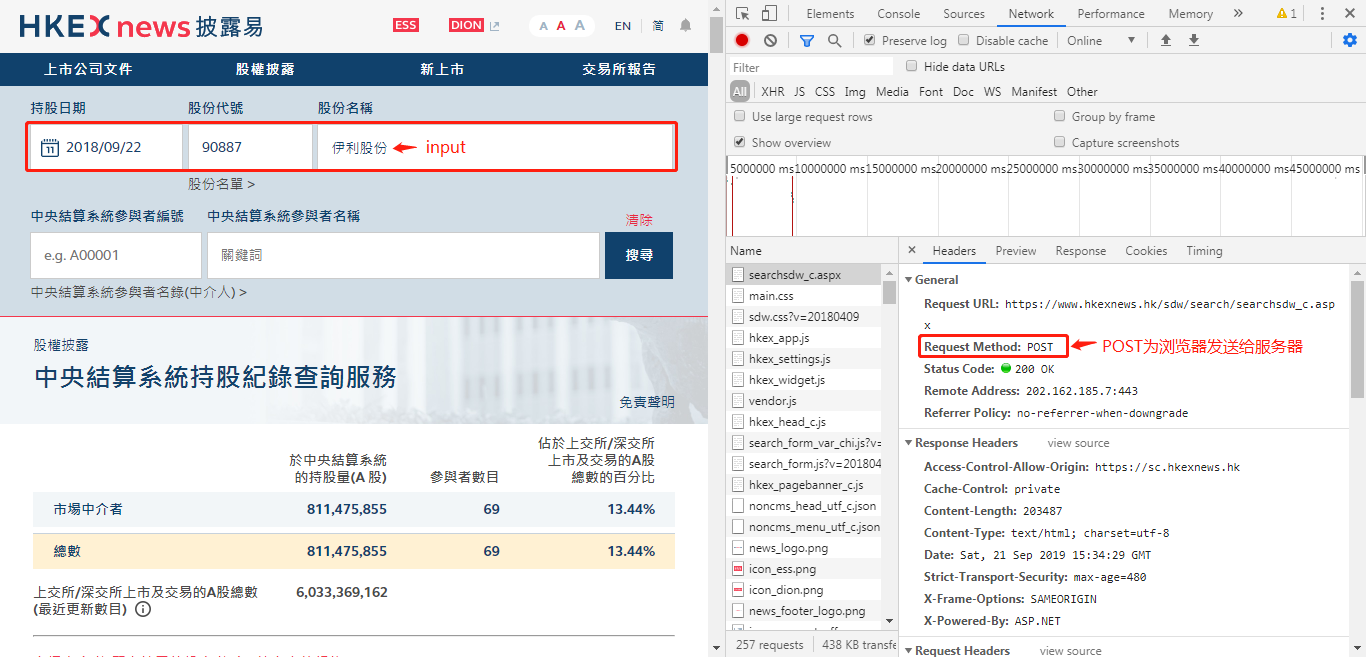
requests.post is the data input and output between the simulated browser and the website server, which is somewhat similar to the control word in industrial control. While working with this crawler, I also learned some of the simplest HTML and CHROME usage knowledge. Know how to run the developer mode through F12 to see exactly what is input and output between the browser and the server when the mouse clicks. At the same time, the original HTML code of the web page is analyzed, and the location of specific data in the code is located. It is convenient to use xpath to parse and query the specific location. Below are some photos of the page parsed: