The database is a reliable partner for programming where we need storage services. The database provides a very convenient storage function, and can be quickly added, deleted and modified by sql statements. There are many ways to manipulate databases in python, such as MySQLdb, pymysql, py pypyodbc and so on. In fact, they are all similar.
The general process of operating the database is as follows:
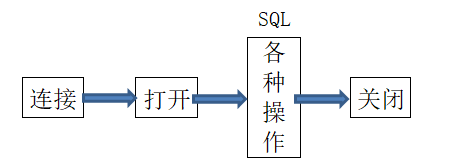
When we open the database after connecting, we can use sql statements to operate the database, remember not to forget to close, otherwise the operation may not be saved.
In many libraries, this process is almost invariable. The key to operate the database is the execution of sql statements. In general, the following points should be noted:
- Use database information path password and other links to database information and path must not be written incorrectly
- Don't Write Wrong Query Statements
pypyodbc installation
Small partners using pycharm can be added directly in file-setting
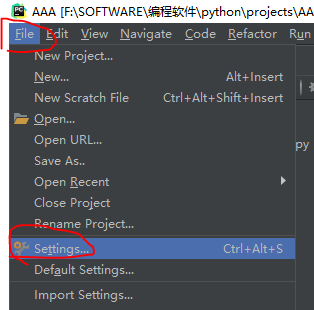
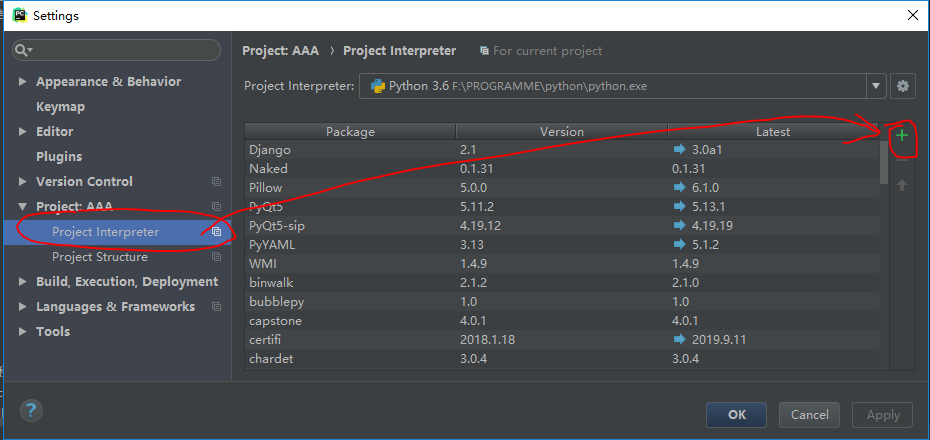
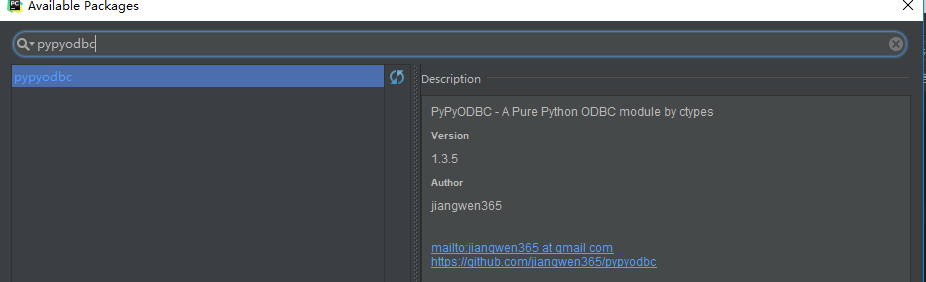
Click on the install installation below. Partners without ide s can be used directly from the command line
pip install pypyodbc
Database Connection and Operation
The operation steps are connection open - get cursor - sql query - close
Here the cursor needs to say that the cursor is actually like a pointer, pointing to the place where the data set is stored in memory, allowing users to manipulate the data set of the database like an array of operations. In short, cursors are used to access database entry information.
The following demonstrates how to operate:
Test the contents of the database

# Different database connection methods are different
# If you need something else, see the connection functions and parameters for other databases
import pypyodbc
import os
# Operating Access database classes
# _ The new_() method is responsible for creating instances, while the _init_() method is only responsible for initializing the attributes of the instances, and the execution order is, first new and then init.
class getdatabase:
# Initialization function connecting database
def __init__(self, db_name, password=""):
if not os.path.exists(db_name):
pypyodbc.win_create_mdb(db_name) # Note that absolute paths such as d:\test_db.mdb
self.db_name = db_name
self.password = password
self.connectDB() # Call the connection function
# Connection Number Database Function
def connectDB(self):
str = 'Driver={Microsoft Access Driver (*.mdb,*.accdb)};PWD=' + self.password + ";DBQ=" + self.db_name
# str = 'Driver={Microsoft Access Driver (*.mdb)};DBQ=self.db_name'
try:
self.conn = pypyodbc.win_connect_mdb(str)
return True
except:
print("The database connection failed! Please check!")
return False
# Get cursor
# Cursor can be visualized as a variable cursor. It is actually a pointer that stores data query result sets or data operation results in an Oracle section.
# In the memory of the set, this pointer can point to any record in the result set. This gives you the data it points to, but initially it points to the first record. This model is very similar to an array in a programming language.
# It is easy to understand that a cursor is a pointer to a result set record, and the cursor can be used to return the row record to which it is currently pointing (only one row record can be returned). If you want to return multiple rows, you need to scroll the cursor constantly and query the data you want. Users can manipulate the records of rows where the cursor is located.
def getCur(self):
try:
return self.conn.cursor() #Get the cursor after opening the database
except:
return
# Execute sql query statement to return all results
def selectDB(self, cur, sql):
try:
cur.execute(sql)
return cur.fetchall() # Returns the query result
except:
return []
# Execute insert statement and update database
def insertDB(self, cur, sql):
try:
cur.execute(sql)
self.conn.commit() # This should not be less than validation or the data will not be updated
return True
except:
return False
# close database
def close(self):
try:
self.conn.close()
except:
return
# Program entry
if __name__ == '__main__':
path = os.path.join("F:\SOFTWARE\programming software\python\projects\AAA", "data.accdb")
# Step 1 Connect to the database
conn = getdatabase(path, "")
# Step 2: Get the cursor
cur = conn.getCur() # The use of cursors allows users to manipulate queried data sets like operational arrays
#Step 3 Query Statement
sql = u"select * from userData where Port = 1234" # Chinese needs to be preceded by u, otherwise you may make mistakes.
data = conn.selectDB(cur, sql) # Use cursors to match query statements
print(str(data[0]["code"])) # A field of an item in the output
#Step 3 Insert Statement
# SQL = u "INSERT INTO user data (id, port, code, type, msg) VALUES (10,12321,'efes','don't know','dadfd')"
# data = conn.insertDB(cur, sql) # Use cursors to match query statements
#Step 4 Close the cursor and database
cur.close()
conn.close()
# The output is
QYRWBBIWFRAfter opening and manipulating the database, the second key part is what is the result of the return? Only when we understand the structure of the returned data can we further process the data. Let's look at the data content in the data (the result of the query statement) variable.


You can see that the data reached is a list, each element is a row of data, and each data is a row. The cursor describes the name and type of each field. It supports us to access the field in a dictionary like way. Note that there is no case difference between the field names here.
data[0]["code"] #Get the code field value of the first row and traverse using len(data) to know the number of returned entries # Result QYRWBBIWFR