In many scenarios of distributed system, in order to ensure the final consistency of data, we need many technical solutions to support, such as distributed transactions, distributed locks and so on.
Sometimes, we need to ensure that a method can only be executed by the same thread at the same time. In the stand-alone environment, Java actually provides a lot of API related to concurrent processing, but these APIs are powerless in the distributed scenario. That is to say, Java Api alone cannot provide the ability of distributed lock.
At present, there are many schemes for the implementation of distributed locks:
- Implementation of distributed lock based on Database
- Implementation of distributed lock based on redis (memcached)
- Implementation of distributed lock based on Zookeeper
Before analyzing these solutions, let's think about what kind of distributed locks we need. (take method lock as an example, and resource lock is the same.)
It can ensure that the same method can only be executed by one thread on one machine at the same time in the application cluster of distributed deployment.
- If this lock is a relocatable lock (avoid deadlock)
- This lock is better to be a blocking lock (consider whether to use this lock according to business requirements)
- Highly available lock acquisition and release functions
- The performance of acquiring lock and releasing lock is better
I. implementation of distributed lock based on Database
1.1 based on database table
The easiest way to implement a distributed lock is to create a lock table directly and then operate the data in the table.
When we want to lock a method or resource, we add a record to the table, and delete the record when we want to release the lock.
Create a database table like this:
CREATE TABLE `methodLock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key',
`method_name` varchar(64) NOT NULL DEFAULT '' COMMENT 'Locked method name',
`desc` varchar(1024) NOT NULL DEFAULT 'Remarks information',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON
UPDATE CURRENT_TIMESTAMP COMMENT 'Save data time and generate automatically',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Method in locking';When we want to lock a method, execute the following SQL:
insert into methodLock(method_name,desc) values ('method_name','desc')Because we have made a uniqueness constraint on method [u name], if there are multiple requests submitted to the database at the same time, the database will ensure that only one operation can succeed, so we can think that the thread that succeeds in the operation has obtained the lock of the method and can execute the method body content.
After the method is executed, if you want to release the lock, you need to execute the following Sql:
delete from methodLock where method_name ='method_name'
The above simple implementation has the following problems:
-
This lock strongly depends on the availability of the database, which is a single point. Once the database is hung up, the business system will not be available.
-
There is no expiration time for this lock. Once the unlocking operation fails, the lock record will remain in the database, and other threads can no longer obtain the lock.
-
This lock can only be non blocking, because once the data insert operation fails, it will directly report an error. A thread that does not acquire a lock does not enter the queue. To acquire a lock again, it needs to trigger the acquire lock operation again.
- This lock is non reentrant. The same thread cannot acquire the lock again without releasing it. Because the data already exists in the data.
Of course, there are other ways to solve the above problems.
To solve the problem that the database is a single point, two databases should be established, and the data should be synchronized in two directions. Once hung up, quickly switch to the standby database.
For no expiration time? Just do a regular task, and clean up the overtime data in the database at regular intervals.
For non blocking? Make a while loop until the insert succeeds and then returns success.
For non reentrant? Add a field in the database table to record the host information and thread information of the current machine that obtains the lock. Query the database first when acquiring the lock next time. If the host information and thread information of the current machine can be found in the database, assign the lock to him directly.
1.2 exclusive lock based on Database
In addition to adding or deleting records in the operation data table, the distributed lock can also be realized by using the lock in the data.
We also use the database table we just created. Distributed lock can be realized by exclusive lock of database. The InnoDB engine based on MySql can use the following methods to implement the lock operation:
public boolean lock(){
connection.setAutoCommit(false)
while(true){
try{
result = select * from methodLock where method_name=xxx
for update;
if(result==null){
return true;
}
}catch(Exception e){
}
sleep(1000);
}
return false;
}Add for update after the query statement, and the database will add an exclusive lock to the database table during the query process. When an exclusive lock is added to a record, other threads cannot add an exclusive lock to the record.
We can think that the thread that obtains the exclusive lock can obtain the distributed lock. After obtaining the lock, it can execute the business logic of the method. After executing the method, it can be unlocked by the following methods:
public void unlock(){
connection.commit();
}Release the lock through the connection.commit() operation.
This method can effectively solve the above mentioned problems of unable to release locks and blocking locks.
Blocking lock? The for update statement will return immediately after the execution is successful, and it will be blocked until it is successful when the execution fails.
After locking, the service is down and cannot be released. In this way, the database will release the lock itself after the service is down.
However, it is still unable to directly solve the single point and reentry problems of the database.
1.3 summary
To summarize the ways of using database to realize distributed lock, both of them depend on a table of database. One is to determine whether there is a lock through the existence of records in the table. The other is to realize distributed lock through exclusive lock of database.
The advantages of database implementation of distributed lock: it is easy to understand with the help of database directly.
Disadvantages of implementing distributed lock in database: there will be various problems, and the whole scheme will become more and more complex in the process of solving the problem.
Operating the database requires some overhead, and performance issues need to be considered.
2. Implementation of distributed lock based on cache
Compared with the implementation of distributed lock based on database, the implementation based on cache will perform better in performance. And many caches can be deployed in clusters, which can solve single point problems.
At present, there are many mature cache products, including Redis, memcached, etc.
There are several key points to pay attention to during implementation:
-
The lock information must expire and time out. A thread cannot hold a lock for a long time, resulting in a deadlock.
- Only one thread can acquire the lock at the same time.
Several redis commands to be used:
setnx(key, value): "set if not exits". If the key value does not exist, the cache will be added successfully and 1 will be returned, otherwise 0 will be returned.
get(key): get the value corresponding to the key. If it does not exist, return nil.
getset(key, value): first get the value value corresponding to the key, if not, return nil, and then update the old value to the new value.
expire(key, seconds): set the validity period of key value to seconds.
Take a look at the flowchart:
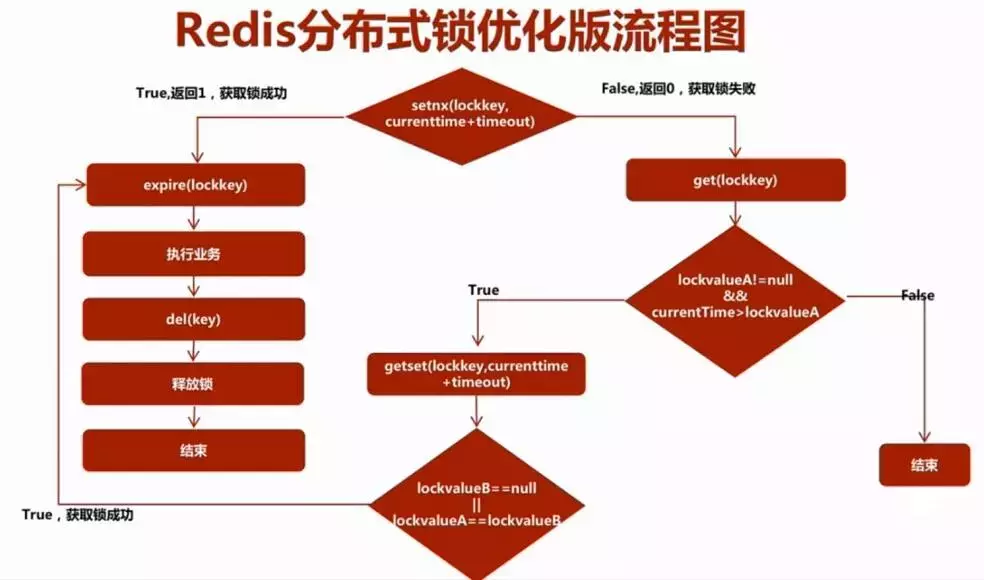
In this process, deadlock will not be caused.
I use Jedis as the api of Redis client. Let's see the specific implementation code.
(1) first, create a Redis connection pool.
public class RedisPool {
private static JedisPool pool;//jedis connection pool
private static int maxTotal = 20;//maximum connection
private static int maxIdle = 10;//Maximum number of idle connections
private static int minIdle = 5;//Minimum free connections
private static boolean testOnBorrow = true;//Test the availability of the connection when taking it
private static boolean testOnReturn = false;//Do not test the availability of a connection when it is reconnected
static {
initPool();//Initialize connection pool
}
public static Jedis getJedis(){
return pool.getResource();
}
public static void close(Jedis jedis){
jedis.close();
}
private static void initPool(){
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(maxTotal);
config.setMaxIdle(maxIdle);
config.setMinIdle(minIdle);
config.setTestOnBorrow(testOnBorrow);
config.setTestOnReturn(testOnReturn);
config.setBlockWhenExhausted(true);
pool = new JedisPool(config, "127.0.0.1", 6379, 5000, "liqiyao");
}
}(2) encapsulate the api of Jedis, encapsulate some operations needed to implement the distributed lock.
public class RedisPoolUtil {
private RedisPoolUtil(){}
private static RedisPool redisPool;
public static String get(String key){
Jedis jedis = null;
String result = null;
try {
jedis = RedisPool.getJedis();
result = jedis.get(key);
} catch (Exception e){
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
return result;
}
}
public static Long setnx(String key, String value){
Jedis jedis = null;
Long result = null;
try {
jedis = RedisPool.getJedis();
result = jedis.setnx(key, value);
} catch (Exception e){
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
return result;
}
}
public static String getSet(String key, String value){
Jedis jedis = null;
String result = null;
try {
jedis = RedisPool.getJedis();
result = jedis.getSet(key, value);
} catch (Exception e){
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
return result;
}
}
public static Long expire(String key, int seconds){
Jedis jedis = null;
Long result = null;
try {
jedis = RedisPool.getJedis();
result = jedis.expire(key, seconds);
} catch (Exception e){
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
return result;
}
}
public static Long del(String key){
Jedis jedis = null;
Long result = null;
try {
jedis = RedisPool.getJedis();
result = jedis.del(key);
} catch (Exception e){
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
return result;
}
}
}(3) distributed lock tools
public class DistributedLockUtil {
private DistributedLockUtil(){
}
public static boolean lock(String lockName){//lockName can be a shared variable
//Name, or method name, mainly used to simulate lock information
System.out.println(Thread.currentThread() + "Start trying to lock!");
Long result = RedisPoolUtil.setnx
(lockName, String.valueOf(System.currentTimeMillis() + 5000));
if (result != null && result.intValue() == 1){
System.out.println(Thread.currentThread() + "Lock successfully!");
RedisPoolUtil.expire(lockName, 5);
System.out.println(Thread.currentThread() + "Execute business logic!");
RedisPoolUtil.del(lockName);
return true;
} else {
String lockValueA = RedisPoolUtil.get(lockName);
if (lockValueA != null && Long.parseLong(lockValueA) >=
System.currentTimeMillis()){
String lockValueB = RedisPoolUtil.getSet(lockName,
String.valueOf(System.currentTimeMillis() + 5000));
if (lockValueB == null || lockValueB.equals(lockValueA)){
System.out.println(Thread.currentThread() + "Lock successfully!");
RedisPoolUtil.expire(lockName, 5);
System.out.println(Thread.currentThread() + "Execute business logic!");
RedisPoolUtil.del(lockName);
return true;
} else {
return false;
}
} else {
return false;
}
}
}
}3. Implementation of distributed lock based on Zookeeper
Based on the distributed locks that can be implemented by the temporary ordered nodes of zookeeper. The general idea is: when each client locks a method, it generates a unique
Instantaneous ordered node. The way to determine whether to acquire locks is very simple. Only the smallest one of the ordered nodes needs to be determined. When releasing the lock, just delete the instantaneous node. At the same time, it can avoid the deadlock problem caused by service downtime.
Let's see if Zookeeper can solve the problems mentioned above.
Lock cannot be released?
Using Zookeeper can effectively solve the problem that the lock cannot be released, because when creating the lock, the client will create a temporary node in the ZK. Once the client gets the lock and suddenly hangs up (Session connection is broken), the temporary node will be deleted automatically. Other clients can get the lock again.
Non blocking lock?
Zookeeper can be used to implement blocking locks. The client can create sequential nodes in ZK and bind listeners on the nodes. Once the nodes change, zookeeper will notify the client. The client can check whether the nodes created by itself have the smallest serial number. If so, it can acquire the locks and execute the business logic.
Non reentrant?
Zookeeper can also be used to effectively solve the problem of non reentrant. When the client creates a node, it directly writes the host information and thread information of the current client to the node. The next time it wants to acquire a lock, it can be compared with the data of the current smallest node. If it is the same as its own information, it obtains the lock directly. If it is different, it creates a temporary sequential node to participate in the queue.
A single question?
Zookeeper can effectively solve single point problems. ZK is deployed in a cluster. As long as more than half of the machines in the cluster survive, it can provide external services.
You can directly use the zookeeper third-party library, the cursor client, which encapsulates a reentrant lock service.
public boolean tryLock(long timeout, TimeUnit unit) throws
InterruptedException {
try {
return interProcessMutex.acquire(timeout, unit);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
public boolean unlock() {
try {
interProcessMutex.release();
} catch (Throwable e) {
log.error(e.getMessage(), e);
} finally {
executorService.schedule(new Cleaner(client, path),
delayTimeForClean, TimeUnit.MILLISECONDS);
}
return true;
}The InterProcessMutex provided by the cursor is the implementation of distributed locks. The acquire method is used by the user to acquire the lock, and the release method is used to release the lock.
The distributed lock implemented with ZK seems to meet all our expectations for a distributed lock at the beginning of this article. However, in fact, there is a disadvantage of the distributed lock implemented by Zookeeper, that is, there may be no cache service in performance.
So tall. Because every time in the process of creating and releasing locks, we need to create and destroy instantaneous nodes dynamically to realize the lock function. The creation and deletion of nodes in ZK can only be performed through the Leader server, and then the data cannot be shared with all the Follower machines.
summary
The advantages of using Zookeeper to implement distributed lock are as follows: effectively solving single point problem, non reentry problem, non blocking problem and lock can not be released. It is easy to realize.
The disadvantage of using Zookeeper to implement distributed locks: the performance is not as good as using cache to implement distributed locks. You need to understand the principle of ZK.
Comparison of three schemes
From the perspective of difficulty (from low to high): Database > cache > zookeeper
From the perspective of implementation complexity (from low to high): zookeeper > = cache > Database
From a performance perspective (from high to low): cache > zookeeper > = database
From a reliability Perspective (from high to low): zookeeper > cache > Database
Therefore, I personally prefer to use cache to implement. In the following articles, we will encapsulate our own distributed lock implementation based on Redis.