Preface
The text and pictures of the article are from the Internet, only for learning and communication, and do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: carrot sauce
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
Reptile
First of all, the author positions Chengdu as "hot pot" for food type selection, unlimited for specific types of hot pot, unlimited for regional selection, intelligent for sorting selection, as shown in the figure below: 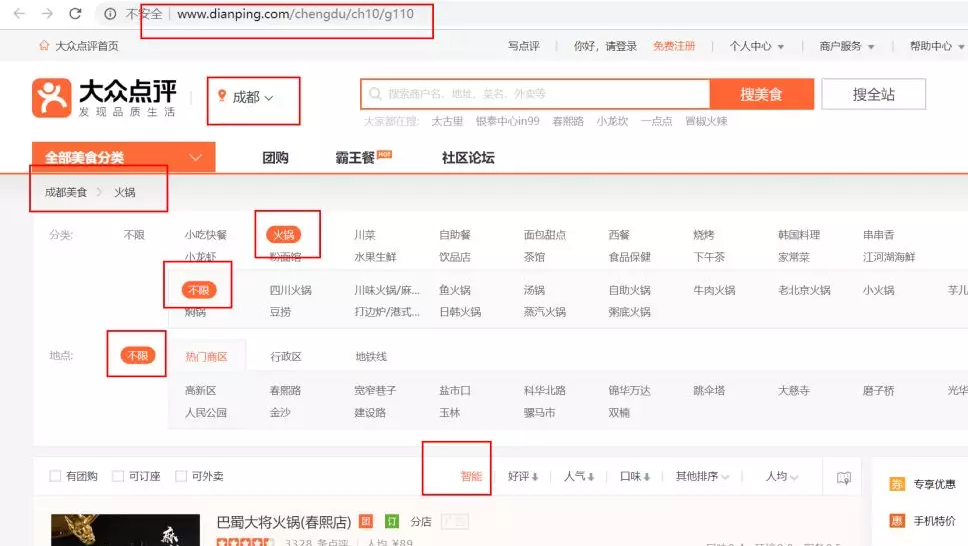
You can also choose other options, just pay attention to the URL changes. This article is crawling data according to the above options. Next, turn the page to observe the change of URL:
Second pages:

Third pages:

It's easy to observe the numbers behind the knowledge p of page turning changes, push back to the first page, and find the same display content. Therefore, write a cycle, and you can crawl all pages.
However, public comments only provide the first 50 pages of data, so we can only crawl the first 50 pages.
This time, the author uses pyquery to analyze web pages, so we need to locate the location of the data we crawled, as shown in the figure: 
In the specific analysis of the web page, I was shocked. The anti crawling of the public comment was too much. Its numbers and some words were not displayed in plain text, but in code. You still don't know how to analyze it. As shown in the picture:
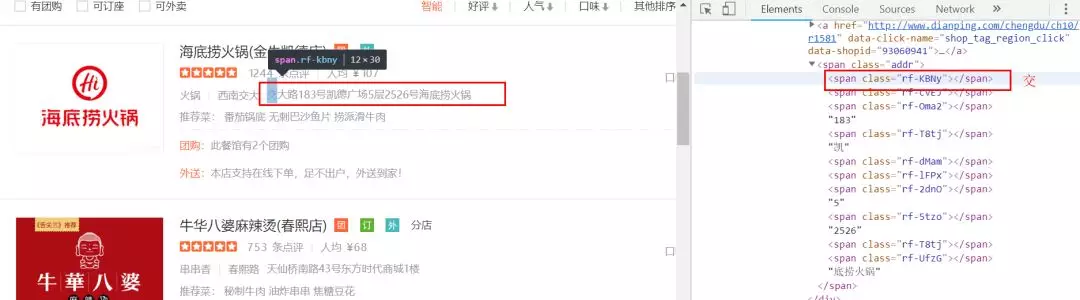
Very annoying, some of the text can be displayed, some of the code. Some numbers are the same, but the good thing is that there are only nine numbers. If you look at them a little, you can see what the code is. Here I list it {'hs-OEEp': 0, 'hs-4Enz': 2, 'hs-GOYR': 3, 'hs-61V1': 4, 'hs-SzzZ': 5, 'hs-VYVW': 6, 'hs-tQlR': 7, 'hs-LNui': 8, 'hs-42CK': 9}. It is worth noting that the number 1 is in clear text.
So, how to use pyquery to locate? It's very simple. You find the data you want to get, right-click → copy → cut selector, and you can copy it into the code. The specific usage of pyquery is available in Baidu.

Finally, we get the data of 50 pages of hotpot, 15 data per page, a total of 750 restaurants.
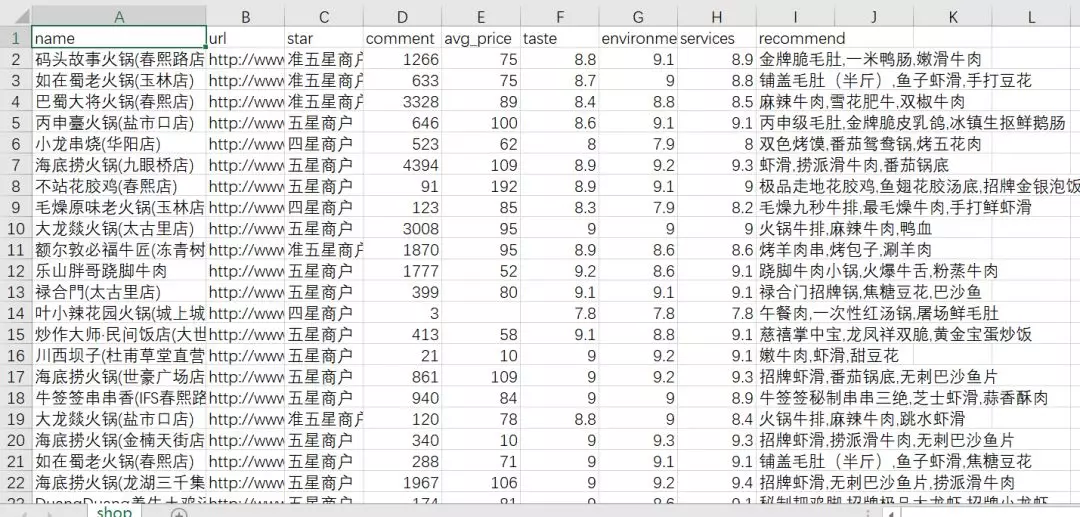
Analysis
Public comment has given star rating, you can see the general trend.
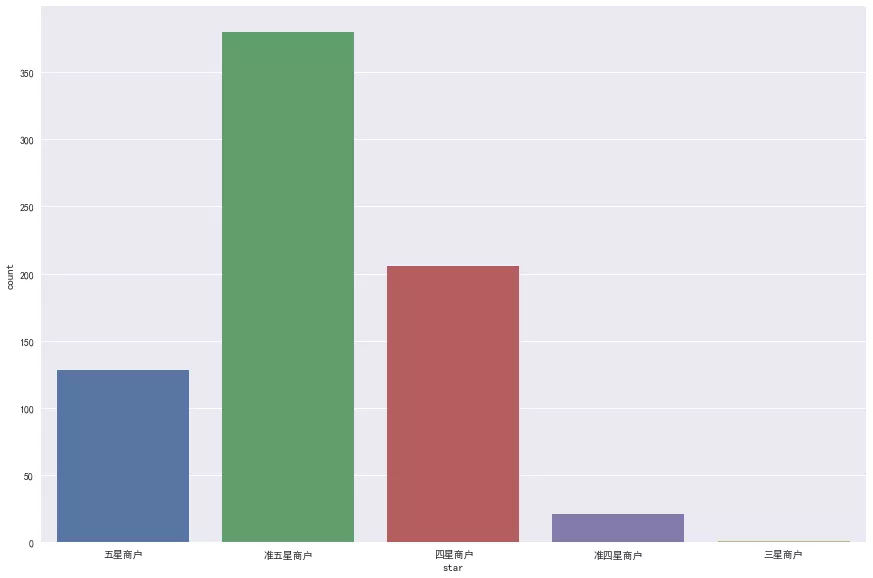
Quasi five star merchants are the most, probably because most diners are used to giving high praise. Only when they are really dissatisfied can they give a low rating. As a result, the rating is generally not low, but nearly the full score is quite small.
In this paper, we assume that the number of comments is the hotness of the hotel, that is, the hotter it is, the more comments it has.
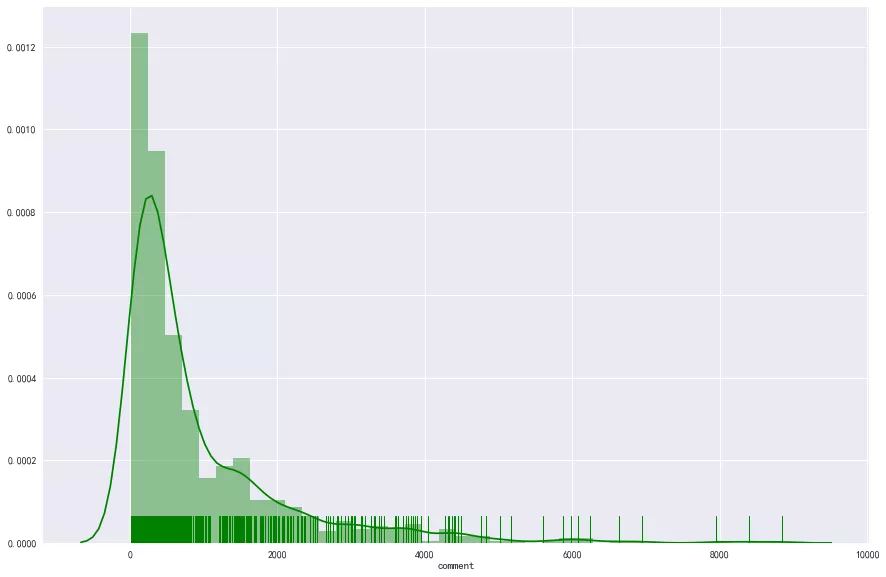
Most of the reviews are within 1000, but there are still some above 2000, even above 4000. These hotels should be some online Red shops. Restricted by 5000, the hotels are all famous hotpot shops of Xiaolongkan and shudaxia. So is the number of comments related to the star rating? See below: 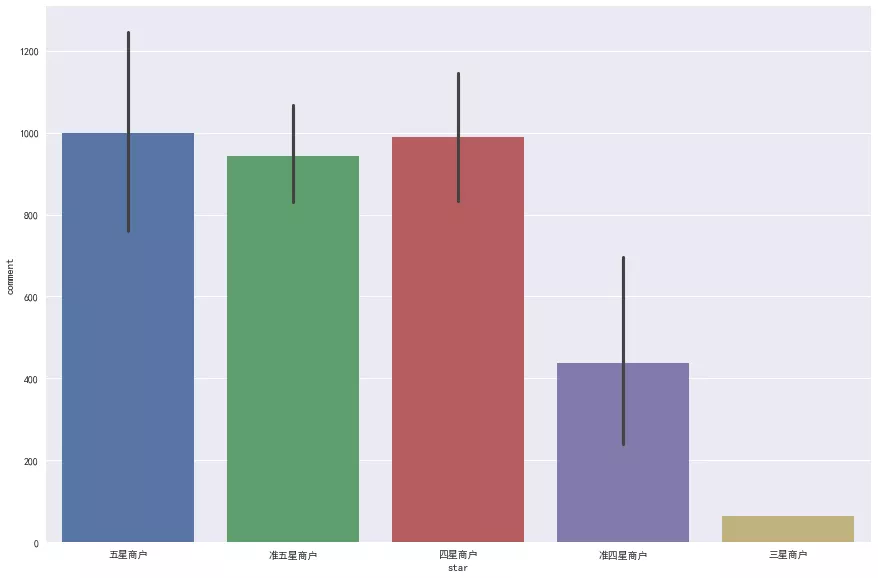
Taking the average number of reviews, it is found that for merchants with more than four stars, the number of reviews is not related to the star level, but the sales volume of Hotels with less than four stars is better. This shows that after more than four stars, people choose Hotels with little difference, but they are generally reluctant to accept Hotels with poor reviews.
For the student party like the author, the influence is greater and the per capita consumption is also the case.
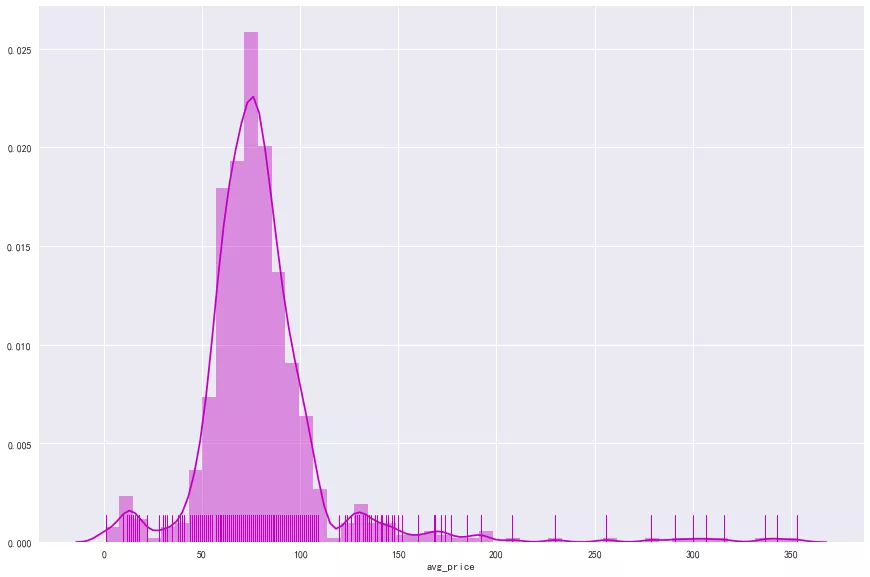
Most of the hot pot stores in Chengdu consume 50-100 yuan per capita, and some of them are higher than 150 yuan. For the author, it's acceptable to eat a hot pot at 50-100 per capita. If it's higher than 100, you have to look down at your wallet (). In terms of expansion, is the per capita consumption related to the number of stars and reviews? 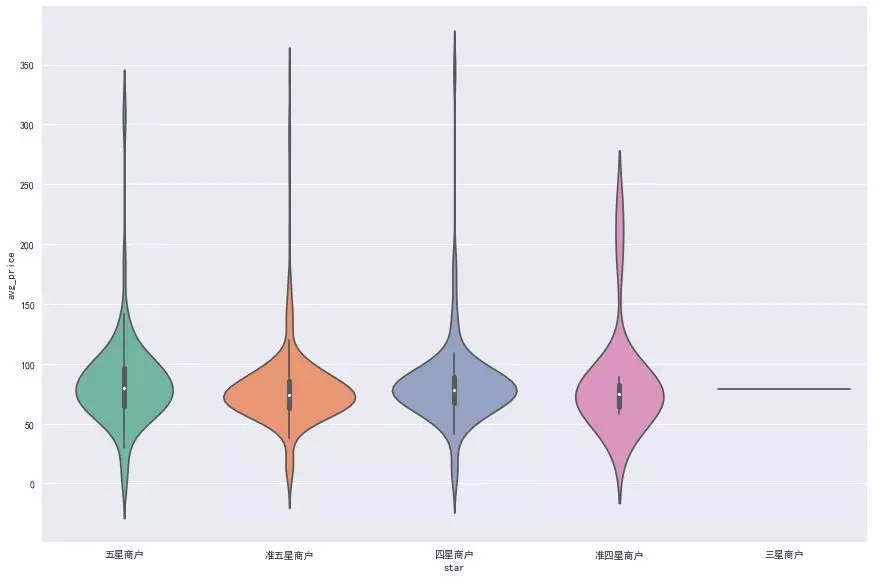
The above figure shows the relationship between per capita consumption and star rating, which seems to have nothing to do with it. It shows that some well-known hotpot stores are not expensive per capita. Let's look at the relationship between per capita and the number of comments.

By comparison, it is found that the number of comments is less than 500, and the average is the most in the range of 50-100. Of course, it must be related to the number of comments and the concentration of per capita consumption in this stage.
Eating hot pot, a shop's business is good or bad, it must also be related to its special dishes. Through the jieba participle, the author makes a word cloud map of the recommended dishes crawled to, as follows. 
My favorite beef is the most special dish, especially spicy beef. As long as you go to hot pot, you have to serve it, followed by tripe, shrimp slide, goose intestines and so on.
Next, we are all concerned about the taste, environment and service.
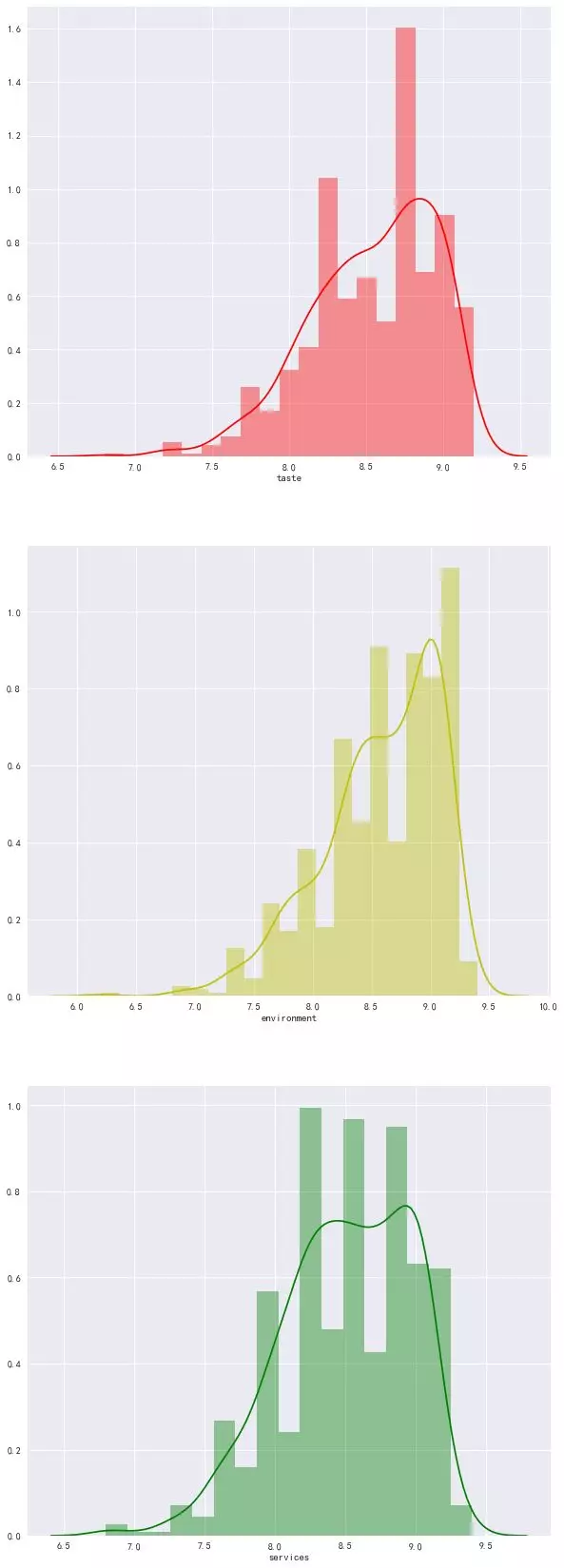
Most of the three scores are concentrated in the stage of 8.0-9.2. The author thinks that Hotels with scores lower than 7.5 should not try. At the same time, the star rating should also be generated by these three scores.
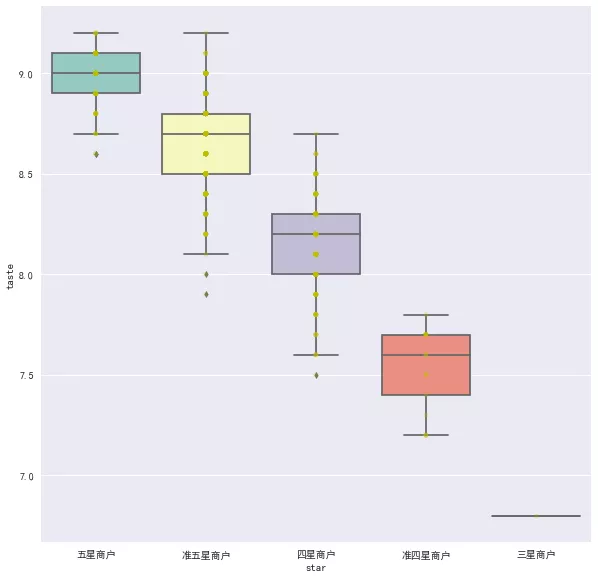


As expected, the better the star rating, the higher the score in taste, environment and service. So is there a relationship between taste, environment, service scores and the number of comments, and the average price?
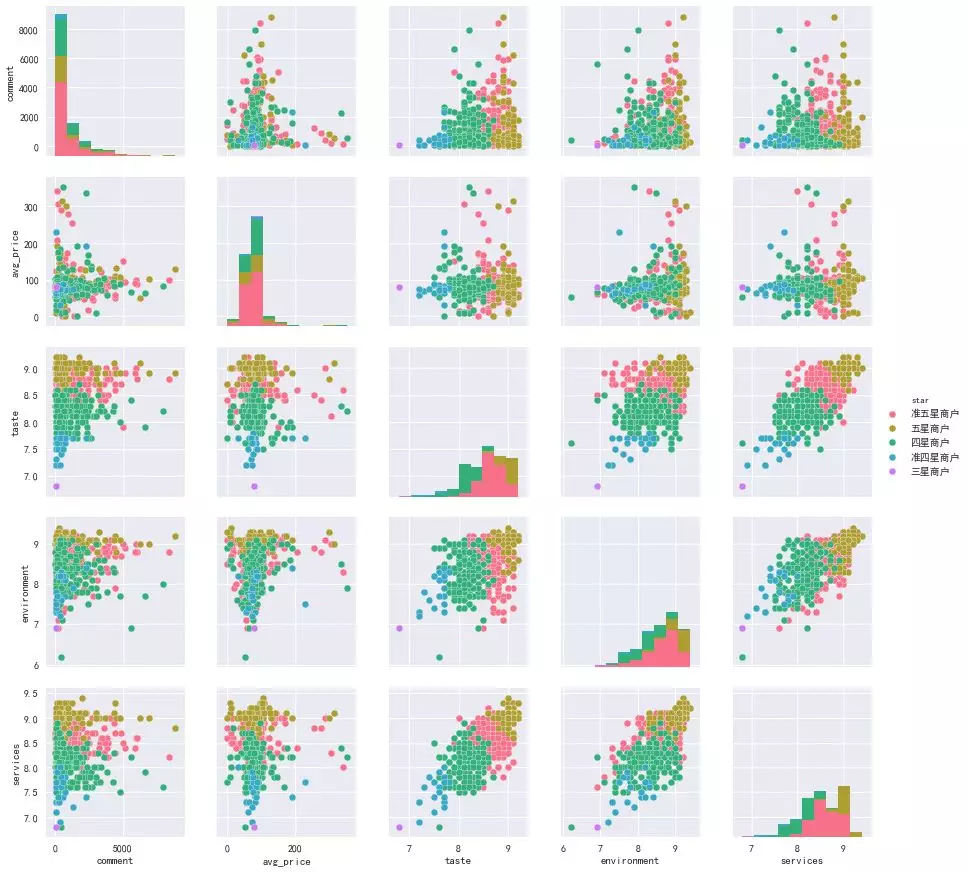
As shown in the figure, there is no direct relationship, but we found that there is a very good linear relationship among taste, environment and service, so we drew a larger figure separately.

We also fit the linear relationship. Because there is only one Samsung merchant, its situation is more special, other stars keep quite consistent in the relationship fitting of taste, environment and service, which also proves our conjecture that there is a linear relationship between these variables. In view of the biggest purpose of this paper is to make recommendations, so we carry out K-means clustering, where k is taken as 3, and the stars are converted into numbers, five stars correspond to 5 points, quasi five stars correspond to 4.5 points, and so on. Finally, we get three categories. Let's see how the clustering is by drawing.
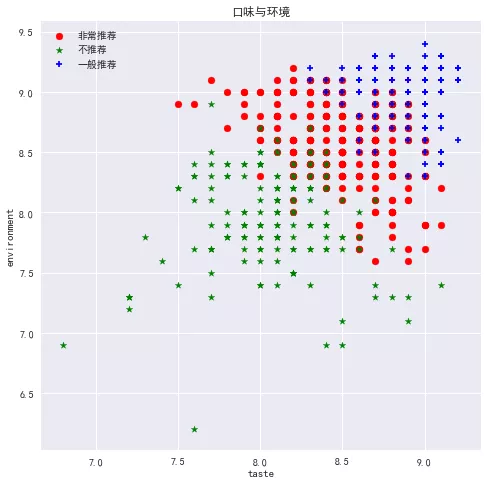
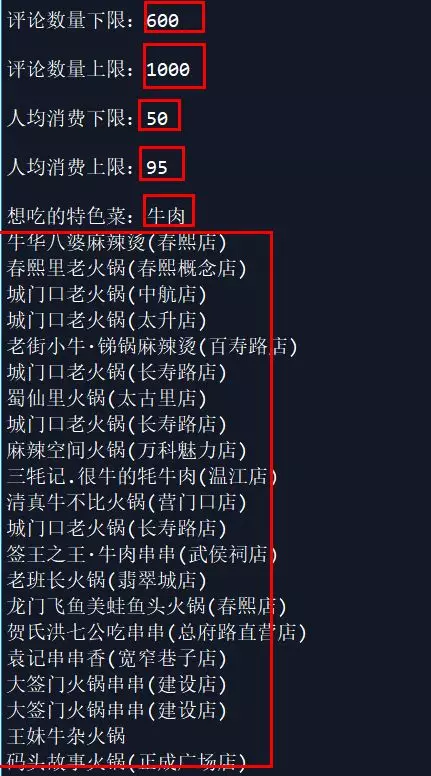
In line with the results we want, the higher we score in taste, environment, service and star rating, the more we recommend. However, there are still many recommended stores. Can we focus on them? Therefore, we recommend by limiting the number of comments, per capita consumption and specialty dishes. Because I like the shop with few people, cheap and beef, here we get the following results:
Code
1 import time 2 import requests 3 from pyquery import PyQuery as pq 4 import pandas as pd 5 6 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} 7 8 def restaurant(url): 9 # Get static source code of web page 10 try: 11 response = requests.get(url, headers=headers) 12 if response.status_code == 200: 13 return response.text 14 except Exception: 15 return None 16 17 name=[] 18 url = [] 19 star = [] 20 comment = [] 21 avg_price = [] 22 taste = [] 23 environment = [] 24 services = [] 25 recommend = [] 26 27 num = {'hs-OEEp': 0, 'hs-4Enz': 2, 'hs-GOYR': 3, 'hs-61V1': 4, 'hs-SzzZ': 5, 'hs-VYVW': 6, 'hs-tQlR': 7, 'hs-LNui': 8, 'hs-42CK': 9} 28 def detail_number(htm): 29 try: 30 a = str(htm) 31 a = a.replace('1<', '<span class="1"/><') 32 a = a.replace('.', '<span class="."/>') 33 b = pq(a) 34 cn = b('span').items() 35 number = '' 36 for i in cn: 37 attr = i.attr('class') 38 if attr in num: 39 attr = num[attr] 40 number = number + str(attr) 41 number = number.replace('None', '') 42 except: 43 number = '' 44 return number 45 46 def info_restaurant(html): 47 # Get the name and link of the hotel 48 doc = pq(html) 49 for i in range(1,16): 50 #Get hotel name 51 shop_name = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.tit > a:nth-child(1) > h4').text() 52 if shop_name == '': 53 break 54 name.append(shop_name) 55 #Get hotel links 56 url.append(doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.pic > a').attr('href')) 57 try: 58 star.append(doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.comment > span').attr('title')) 59 except: 60 star.append("") 61 #Get number of comments 62 comment_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.comment > a.review-num > b') 63 comment.append(detail_number(comment_html)) 64 #Access to per capita consumption 65 avg_price_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.comment > a.mean-price > b') 66 avg_price.append(detail_number(avg_price_html)) 67 #Get taste score 68 taste_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > span > span:nth-child(1) > b') 69 taste.append(detail_number(taste_html)) 70 #Get environment score 71 environment_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > span > span:nth-child(2) > b') 72 environment.append(detail_number(environment_html)) 73 #Get service score 74 services_html = doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > span > span:nth-child(3) > b') 75 services.append(detail_number(services_html)) 76 #Recommended dishes,It's all three courses 77 try: 78 recommend.append(doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.recommend > a:nth-child(2)').text()+str(',')+\ 79 doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.recommend > a:nth-child(3)').text()+str(',')+\ 80 doc('#shop-all-list > ul > li:nth-child('+str(i)+') > div.txt > div.recommend > a:nth-child(4)').text()) 81 except: 82 recommend.append("") 83 for i in range(1,51): 84 print('Getting{}Page hotel information'.format(i)) 85 hotpot_url = 'http://www.dianping.com/chengdu/ch10/g110p'+str(i)+'?aid=93195650%2C68215270%2C22353218%2C98432390%2C107724883&cpt=93195650%2C68215270%2C22353218%2C98432390%2C107724883&tc=3' 86 html = restaurant(hotpot_url) 87 info_restaurant(html) 88 print ('The first{}Page obtained successfully'.format(i)) 89 time.sleep(12) 90 91 shop = {'name': name, 'url': url, 'star': star, 'comment': comment, 'avg_price': avg_price, 'taste': taste, 'environment': environment, 'services': services, 'recommend': recommend} 92 shop = pd.DataFrame(shop, columns=['name', 'url', 'star', 'comment', 'avg_price','taste', 'environment', 'services', 'recommend']) 93 shop.to_csv("shop.csv",encoding="utf_8_sig",index = False)