brief introduction
The previous blog has described how to use selenium to skip webdriver detection and crawl tmall's product data, so we will not talk about it in detail here, and you can view another blog if you need some ideas.
source code
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from time import sleep
import random
#Define a taobao class
class taobao_infos:
#Object initialization
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # Don't load pictures to speed up access
options.add_experimental_option('excludeSwitches', ['enable-automation']) # This step is very important. It is set to developer mode to prevent Selenium from being recognized by major websites
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
self.wait = WebDriverWait(self.browser, 10) #Timeout duration is 10s
#Log on to Taobao
def login(self):
# Open web page
self.browser.get(self.url)
# Adaptive wait, click password login option
self.browser.implicitly_wait(30) #Wait intelligently until the web page is loaded. The maximum waiting time is 30s
self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
# Adaptive waiting, click Weibo to log in and publicize
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
# Self adaptive waiting, enter the account of microblog
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('username').send_keys(weibo_username)
# Adaptive waiting, enter the password of Weibo
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('password').send_keys(weibo_password)
# Adaptive wait, click the confirm login button
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
# Only after obtaining the nickname of Taobao member can it be determined that the login is successful
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# Output Taobao nickname
print(taobao_name.text)
# Simulation slide down browse
def swipe_down(self,second):
for i in range(int(second/0.1)):
#Simulate sliding up and down according to the value of i
if(i%2==0):
js = "var q=document.documentElement.scrollTop=" + str(300+400*i)
else:
js = "var q=document.documentElement.scrollTop=" + str(200 * i)
self.browser.execute_script(js)
sleep(0.1)
js = "var q=document.documentElement.scrollTop=100000"
self.browser.execute_script(js)
sleep(0.1)
# Crawling through the data of Taobao's precious goods I have bought
def crawl_good_buy_data(self):
# Crawled the data of my purchased baby products
self.browser.get("https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm")
# Traverse all pages
for page in range(1,1000):
# Wait for the data of all purchased baby products on this page to be loaded
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#tp-bought-root > div.js-order-container')))
# Get the source code of this page
html = self.browser.page_source
# pq module parsing web source code
doc = pq(html)
# # Store the purchased data of this page
good_items = doc('#tp-bought-root .js-order-container').items()
# Go through all the treasures on this page
for item in good_items:
good_time_and_id = item.find('.bought-wrapper-mod__head-info-cell___29cDO').text().replace('\n',"").replace('\r',"")
good_merchant = item.find('.seller-mod__container___1w0Cx').text().replace('\n',"").replace('\r',"")
good_name = item.find('.sol-mod__no-br___1PwLO').text().replace('\n', "").replace('\r', "")
# Only the purchase time, order number, merchant name and commodity name are listed
# Please get the rest by yourself
print(good_time_and_id, good_merchant, good_name)
print('\n\n')
# Most people are detected as robots because of further simulation of human operations
# Simulate manual downward browsing of goods, i.e. perform simulated sliding operation to prevent being identified as a robot
# Random sliding delay time
swipe_time = random.randint(1, 3)
self.swipe_down(swipe_time)
# Wait for the next button to appear
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.pagination-next')))
# Click Next button
good_total.click()
sleep(2)
if __name__ == "__main__":
# Please check the operating instruction file README.MD under the current directory before using
# Please check the operating instruction file README.MD under the current directory before using
# Please check the operating instruction file README.MD under the current directory before using
chromedriver_path = "/Users/bird/Desktop/chromedriver.exe" #Change to the full path address of your chrome driver
weibo_username = "Change to your Weibo account" #Change to your Weibo account
weibo_password = "Change to your Weibo password" #Change to your Weibo password
a = taobao_infos()
a.login() #Sign in
a.crawl_good_buy_data() #Crawling through the data of Taobao's precious goods I have bought
Using tutorials
- Click here to download Download chrome browser
- Check the version number of the chrome browser, Click here to download chromedriver driver corresponding to version number
- pip installs the following packages
- [x] pip install selenium
- click here Log in to Weibo and bind Taobao account password through Weibo
- Fill in the absolute path of chromedriver in main
- Fill in the password of microblog account in main
#Change to the full path address of your chrome driver
chromedriver_path = "/Users/bird/Desktop/chromedriver.exe"
#Change to your Weibo account
weibo_username = "Change to your Weibo account"
#Change to your Weibo password
weibo_password = "Change to your Weibo password"
Demo pictures
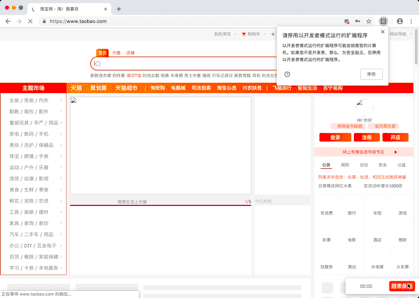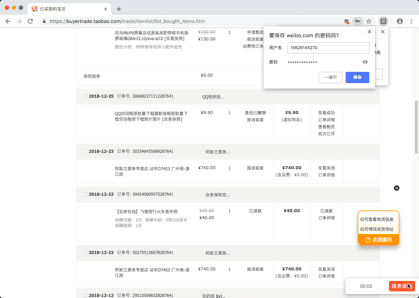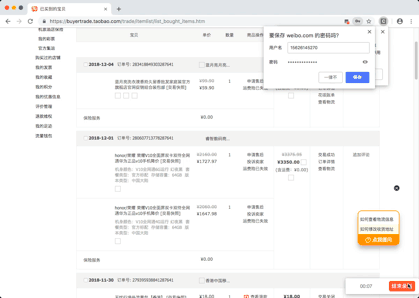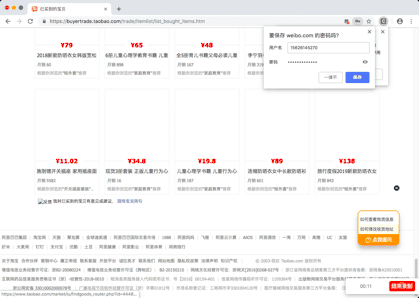

You can't view the picture of the reptile process. Click here
Crawler result image can't be viewed. Click here
Other crawler source code
All the crawler projects are in github. You can go there if you need GitHub warehouse
The project is continuously updated. Welcome star this project