Preface
The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: Wang Xiang Qingfeng Python
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
Problems faced by reptiles
-
No longer just data
Most of the websites still request it. Once all the data is stuffed in, it will be returned. But now more websites use asynchronous loading of data, and the crawler is not as convenient as before
Many people say that js asynchronous loading and data analysis can be done by crawlers. Yes, it's just to increase the workload. That's the front end where you haven't met the bull. Most of the solutions can only be grasped by rendering browsers, which is inefficient. Then go down
-
Landing verification of various forms
From 12306, which of the following sugar is milk sugar? To now, the slide puzzles of major websites and the man Click to unlock are all in order to prevent the automatic operation of reptiles.
You said that you can log in to copy cookies first, but cookies also have expiration dates, right?
-
Anti reptile mechanism
What is anti reptile? The sharp explanation is searched everywhere on the Internet. I'll tell you the simple logic. You visited my website a thousand times in a few seconds. I'm sorry. I'll ban your ip address. Don't come for a while.
A lot of people have said that you are too busy, don't you know the open source project ip proxys with crawler ip agent pool? Then I ha ha, a few people have used the free ip proxy pool now. Go to see the free proxy pool now, and several are available!
What's more, you can get the available agents through the IP proxys agent pool to visit people's websites. People's websites won't find the available agents in the same way and seal them up first? And then you have to pay for a paying agent
-
Data source blocking
What do you usually watch crawling Douban movie website? Collect comments of some treasure... These are public data. But now more data are gradually closed-source. Data is becoming more and more valuable. Without the source of data acquisition, what are the problems faced by reptiles?
It said a lot of reptiles are not good, but not good. As a result, the article I published today is really a reptile. Do you hit yourself in the face? In fact, I just want to talk about the skills of data display and Analysis on the website... It happens that Boss has done a good job directly. How nice? A little analysis
-
data sharing
Let's take a look at a picture
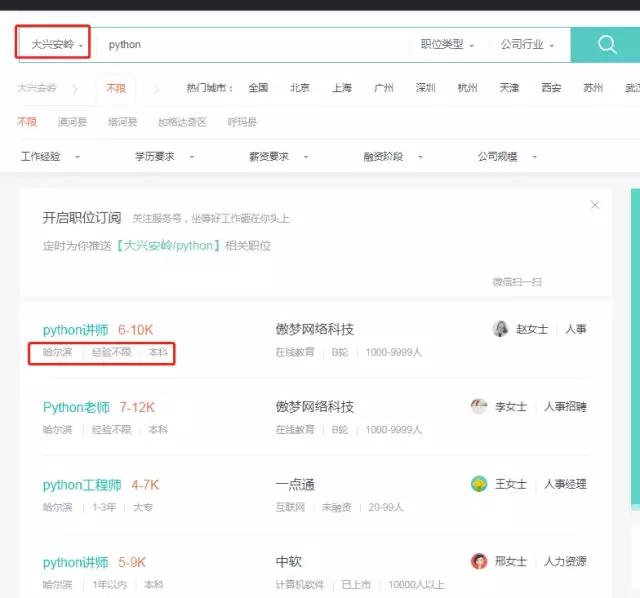
I choose Daxing'anling in Heilongjiang Province to see if there are any Python recruiters there. Most systems will prompt you if they can't find the data, but Boss will quietly show you the python recruitment information in Heilongjiang Province, which is enough to be a thief.
-
Data restriction
There is no python in Daxinganling. Let's go to the whole country to have a look:
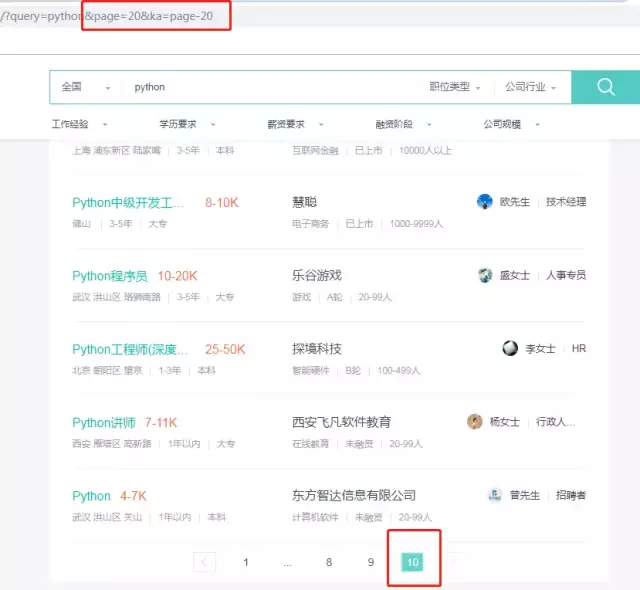
I was almost killed here. I began to think innocently that there were only 300 python Recruitment Information (30 on one page, 10 in total) in China. Then I look back at Xi'an, which is only 10 pages. Then I want to modify his get request parameters. It's useless.
What's the use of this? Think about it carefully... On the one hand, we can put our crawlers to get all the data, but this is just your own amorous, this is a business opportunity!
So many businesses publish recruitment information every day. They can't enter the top 100, and others can't see your information unless they search for your name. So how to rank top? The answer is the last two words, money. If you are a direct member of Boss, you will be ahead of others in publishing
-
Changing concepts
Still look at the picture:
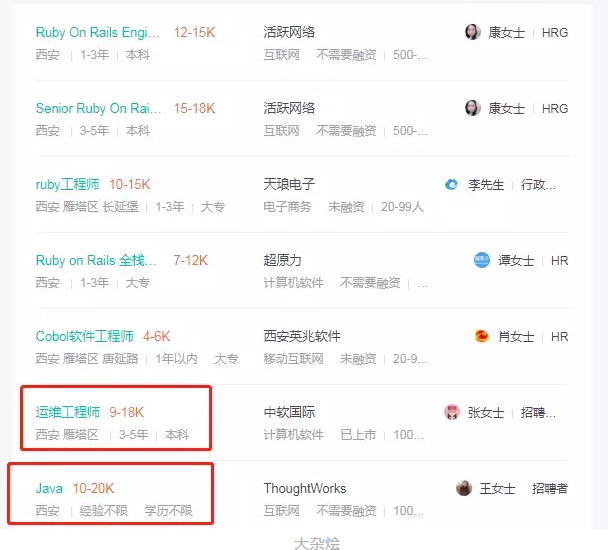
I'm looking for ruby. You don't have enough information. I'm looking for other resources
-
ip analysis
Let's take a look at the old pattern:
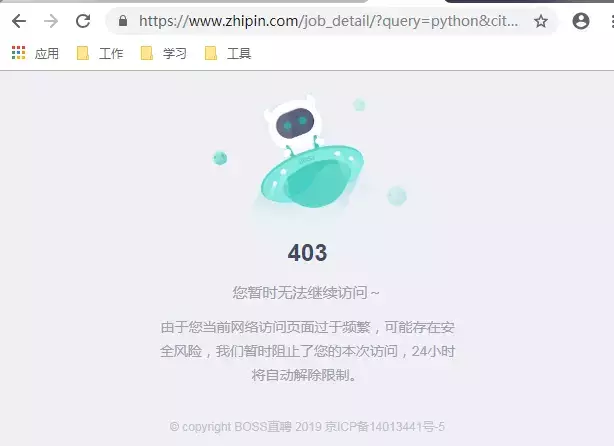
Boss directly hired the server, leaving my traces, what a proud thing. Do you want to be like me? It only takes 3 seconds... Your visit amount can exceed 1000 in 3 seconds. It's properly sealed!
So what should we do
-
Setting up different user agents
Use PIP install fake user agent to get multiple user agents after installation, but actually save dozens locally, which is enough
-
Don't push too hard
If you slow down your speed properly, others won't think it's your food.... don't think it's a person who climbs thousands of times a second than hundreds of times a second.
-
Buying paid agents
Why did I skip talking about free agents? Because now there are too many people who engage in reptiles, the free ones have long been included in the blacklist of major websites.
So the raw data parsed is as follows:
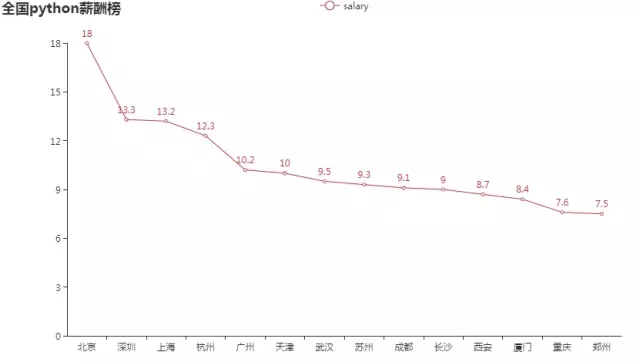
Let's take a look at python's pay list:
Take a look at Xi'an's ranking. The average salary is really low
Code
1 import requests 2 from bs4 import BeautifulSoup 3 import csv 4 import random 5 import time 6 import argparse 7 from pyecharts.charts import Line 8 import pandas as pd 9 10 11 class BossCrawler: 12 def __init__(self, query): 13 14 self.query = query 15 self.filename = 'boss_info_%s.csv' % self.query 16 self.city_code_list = self.get_city() 17 self.boss_info_list = [] 18 self.csv_header = ["city", "profession", "salary", "company"] 19 20 @staticmethod 21 def getheaders(): 22 user_list = [ 23 "Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16", 24 "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14", 25 "Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14", 26 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14", 27 "Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02", 28 "Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00", 29 "Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00", 30 "Opera/12.0(Windows NT 5.2;U;en)Presto/22.9.168 Version/12.00", 31 "Opera/12.0(Windows NT 5.1;U;en)Presto/22.9.168 Version/12.00", 32 "Mozilla/5.0 (Windows NT 5.1) Gecko/20100101 Firefox/14.0 Opera/12.0", 33 "Opera/9.80 (Windows NT 6.1; WOW64; U; pt) Presto/2.10.229 Version/11.62", 34 "Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.10.229 Version/11.62", 35 "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", 36 "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; de) Presto/2.9.168 Version/11.52", 37 "Opera/9.80 (Windows NT 5.1; U; en) Presto/2.9.168 Version/11.51", 38 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; de) Opera 11.51", 39 "Opera/9.80 (X11; Linux x86_64; U; fr) Presto/2.9.168 Version/11.50", 40 "Opera/9.80 (X11; Linux i686; U; hu) Presto/2.9.168 Version/11.50", 41 "Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11", 42 "Opera/9.80 (X11; Linux i686; U; es-ES) Presto/2.8.131 Version/11.11", 43 "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/5.0 Opera 11.11", 44 "Opera/9.80 (X11; Linux x86_64; U; bg) Presto/2.8.131 Version/11.10", 45 "Opera/9.80 (Windows NT 6.0; U; en) Presto/2.8.99 Version/11.10", 46 "Opera/9.80 (Windows NT 5.1; U; zh-tw) Presto/2.8.131 Version/11.10", 47 "Opera/9.80 (Windows NT 6.1; Opera Tablet/15165; U; en) Presto/2.8.149 Version/11.1", 48 "Opera/9.80 (X11; Linux x86_64; U; Ubuntu/10.10 (maverick); pl) Presto/2.7.62 Version/11.01", 49 "Opera/9.80 (X11; Linux i686; U; ja) Presto/2.7.62 Version/11.01", 50 "Opera/9.80 (X11; Linux i686; U; fr) Presto/2.7.62 Version/11.01", 51 "Opera/9.80 (Windows NT 6.1; U; zh-tw) Presto/2.7.62 Version/11.01", 52 "Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.7.62 Version/11.01", 53 "Opera/9.80 (Windows NT 6.1; U; sv) Presto/2.7.62 Version/11.01", 54 "Opera/9.80 (Windows NT 6.1; U; en-US) Presto/2.7.62 Version/11.01", 55 "Opera/9.80 (Windows NT 6.1; U; cs) Presto/2.7.62 Version/11.01", 56 "Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.7.62 Version/11.01", 57 "Opera/9.80 (Windows NT 5.2; U; ru) Presto/2.7.62 Version/11.01", 58 "Opera/9.80 (Windows NT 5.1; U;) Presto/2.7.62 Version/11.01", 59 "Opera/9.80 (Windows NT 5.1; U; cs) Presto/2.7.62 Version/11.01", 60 "Mozilla/5.0 (Windows NT 6.1; U; nl; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 Opera 11.01", 61 "Mozilla/5.0 (Windows NT 6.1; U; de; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 Opera 11.01", 62 "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; de) Opera 11.01", 63 "Opera/9.80 (X11; Linux x86_64; U; pl) Presto/2.7.62 Version/11.00", 64 "Opera/9.80 (X11; Linux i686; U; it) Presto/2.7.62 Version/11.00", 65 "Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.6.37 Version/11.00", 66 "Opera/9.80 (Windows NT 6.1; U; pl) Presto/2.7.62 Version/11.00", 67 "Opera/9.80 (Windows NT 6.1; U; ko) Presto/2.7.62 Version/11.00", 68 "Opera/9.80 (Windows NT 6.1; U; fi) Presto/2.7.62 Version/11.00", 69 "Opera/9.80 (Windows NT 6.1; U; en-GB) Presto/2.7.62 Version/11.00", 70 "Opera/9.80 (Windows NT 6.1 x64; U; en) Presto/2.7.62 Version/11.00", 71 "Opera/9.80 (Windows NT 6.0; U; en) Presto/2.7.39 Version/11.00" 72 ] 73 user_agent = random.choice(user_list) 74 headers = {'User-Agent': user_agent} 75 return headers 76 77 def get_city(self): 78 headers = self.getheaders() 79 r = requests.get("http://www.zhipin.com/wapi/zpCommon/data/city.json", headers=headers) 80 data = r.json() 81 return [city['code'] for city in data['zpData']['hotCityList'][1:]] 82 83 def get_response(self, url, params=None): 84 headers = self.getheaders() 85 r = requests.get(url, headers=headers, params=params) 86 r.encoding = 'utf-8' 87 soup = BeautifulSoup(r.text, "lxml") 88 return soup 89 90 def get_url(self): 91 for city_code in self.city_code_list: 92 url = "https://www.zhipin.com/c%s/" % city_code 93 self.per_page_info(url) 94 time.sleep(10) 95 96 def per_page_info(self, url): 97 for page_num in range(1, 11): 98 params = {"query": self.query, "page": page_num} 99 soup = self.get_response(url, params) 100 lines = soup.find('div', class_='job-list').select('ul > li') 101 if not lines: 102 # It means there's no data. Change to another city 103 return 104 for line in lines: 105 info_primary = line.find('div', class_="info-primary") 106 city = info_primary.find('p').text.split(' ')[0] 107 job = info_primary.find('div', class_="job-title").text 108 # Filter and answer the so-called Recruitment Information 109 if self.query.lower() not in job.lower(): 110 continue 111 salary = info_primary.find('span', class_="red").text.split('-')[0].replace('K', '') 112 company = line.find('div', class_="info-company").find('a').text.lower() 113 result = dict(zip(self.csv_header, [city, job, salary, company])) 114 print(result) 115 self.boss_info_list.append(result) 116 117 def write_result(self): 118 with open(self.filename, "w+", encoding='utf-8', newline='') as f: 119 f_csv = csv.DictWriter(f, self.csv_header) 120 f_csv.writeheader() 121 f_csv.writerows(self.boss_info_list) 122 123 def read_csv(self): 124 data = pd.read_csv(self.filename, sep=",", header=0) 125 data.groupby('city').mean()['salary'].to_frame('salary').reset_index().sort_values('salary', ascending=False) 126 result = data.groupby('city').apply(lambda x: x.mean()).round(1)['salary'].to_frame( 127 'salary').reset_index().sort_values('salary', ascending=False) 128 print(result) 129 charts_bar = ( 130 Line() 131 .set_global_opts( 132 title_opts={"text": "Whole country%s Pay list" % self.query}) 133 .add_xaxis(result.city.values.tolist()) 134 .add_yaxis("salary", result.salary.values.tolist()) 135 ) 136 charts_bar.render('%s.html' % self.query) 137 138 139 if __name__ == '__main__': 140 parser = argparse.ArgumentParser() 141 parser.add_argument("-k", "--keyword", help="Please fill in the key words of the required query") 142 args = parser.parse_args() 143 if not args.keyword: 144 print(parser.print_help()) 145 else: 146 main = BossCrawler(args.keyword) 147 main.get_url() 148 main.write_result() 149 main.read_csv()