1, Background
This paper mainly introduces the implementation of presto with keepalive
Experimental environment: CentOS 6 64 bit
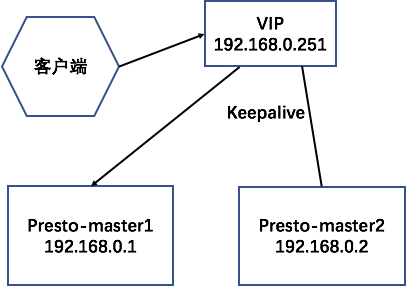
2, Experimental steps
1. Software installation
Install keepalive package
sudo yum install -y keepalived
presto deployment and configuration are omitted, assuming that the process has been started and port monitoring is in 8083.
2. Write Presto master service survival detection script (required for both machines)
$sudo vim /usr/bin/check_presto_alive.sh
#!/bin/sh
PATH=/bin:/sbin:/usr/bin:/usr/sbin
port_test=`nc -z -v localhost 8083|grep succeeded -c`;
if [ $port_test -eq 0 ]
then
echo 'presto server is died'
killall keepalived
fi$sudo chmod +x /usr/bin/check_presto_alive.sh
2. Configuration of Presto-master1
$sudo vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
vrrp_script check_presto_alive {
script "/usr/bin/check_presto_alive.sh"
interval 3
weight -10
}
global_defs {
router_id LVS_PRESTO #An identification of the machine running keepalived
}
vrrp_instance VI_1 {
interface eth0 #Set the network card bound by the instance
state MASTER #Specify which is the master and which is the backup
virtual_router_id 92 #VPID flag, the primary and secondary must be the same
priority 180 #Priority, high priority campaign as master
vrrp_unicast_bind 192.168.0.1
vrrp_unicast_peer 192.168.0.2
authentication {
auth_type PASS #Authentication method
auth_pass nenad #Authentication password
}
virtual_ipaddress {
## Set VIP, must be virtual IP of the same network segment
192.168.0.251
}
track_script {
check_presto_alive #presto survival test
}
}
virtual_server 192.168.0.251 8083 {
delay_loop 5 #Interval of health examination
lb_algo rr #LVS scheduling algorithm rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT #Load balancing forwarding rule NAT|DR|RUN
persistence_timeout 5 #Session hold time
protocol TCP #Protocol used
##Real IP address of RS
real_server 192.168.0.1 8083 {
weight 1 #Default is 1, 0 is invalid
TCP_CHECK{
connect_timeout 3 #Connection timeout
nb_get_retry 3 #Reconnection number
delay_before_retry 3 #Reconnection interval
connect_port 8083 #Health check port
}
}
}3. Configuration of Presto-master2
$sudo vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
vrrp_script check_presto_alive {
script "/usr/bin/check_presto_alive.sh"
interval 3
weight -10
}
global_defs {
router_id LVS_PRESTO #An identification of the machine running keepalived
}
vrrp_instance VI_1 {
interface eth0 #Set the network card bound by the instance
state BACKUP #Specify which is the master and which is the backup
virtual_router_id 92 #VPID flag, the primary and secondary must be the same
priority 170 #Priority, high priority campaign as master
vrrp_unicast_bind 192.168.0.2
vrrp_unicast_peer 192.168.0.1
authentication {
auth_type PASS #Authentication method
auth_pass nenad #Authentication password
}
virtual_ipaddress {
## Set VIP, must be virtual IP of the same network segment
192.168.0.251
}
track_script {
check_presto_alive #presto survival test
}
}
virtual_server 192.168.0.251 8083 {
delay_loop 5 #Interval of health examination
lb_algo rr #LVS scheduling algorithm rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT #Load balancing forwarding rule NAT|DR|RUN
persistence_timeout 5 #Session hold time
protocol TCP #Protocol used
##Real IP address of RS
real_server 192.168.0.2 8083 {
weight 1 #Default is 1, 0 is invalid
TCP_CHECK{
connect_timeout 3 #Connection timeout
nb_get_retry 3 #Reconnection number
delay_before_retry 3 #Reconnection interval
connect_port 8083 #Health check port
}
}
}4. Restart keepalive to take effect (both machines execute)
$sudo /etc/init.d/keepalived restart
5. validation
Use the following command to view that the VIP has been bound to a specific network card.
$ ip a
This experiment verifies the automatic drift of VIP and realizes the automatic switch between the master and the backup of Presto master
Note: after repairing the failed service, you must restart the keepalive service of the machine, otherwise keepalive cannot perceive the service recovery!