brief introduction
Pandas is an open-source Python library for data analysis, and also the most important Open-Source Library for data analysis at present. It can process data similar to spreadsheets, used for fast data loading, operation, alignment, merging, etc. These enhancements are provided for Python, and the data types of pandas are: Series and DataFrame. DataFrame is the entire spreadsheet or rectangular data, while Series is the column of DataFrame. DataFrame can also be considered a collection of dictionaries or Series.
Loading data
load.py
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # qq group: 144081101 591302926 567351477 # CreateDate: 2018-06-07 # load.py import pandas as pd df = pd.read_csv(r"../data/gapminder.tsv", sep='\t') print("\n\n View the first five lines") print(df.head()) print("\n\n View type") print(type(df)) print("\n\n View size") print(df.shape) print("\n\n Check column names") print(df.columns) print("\n\n See dtypes(Column based)") print(df.dtypes) print("\n\n View statistics") print(df.info())
results of enforcement
$ ./load.py //View the first five lines country continent year lifeExp pop gdpPercap 0 Afghanistan Asia 1952 28.801 8425333 779.445314 1 Afghanistan Asia 1957 30.332 9240934 820.853030 2 Afghanistan Asia 1962 31.997 10267083 853.100710 3 Afghanistan Asia 1967 34.020 11537966 836.197138 4 Afghanistan Asia 1972 36.088 13079460 739.981106 //View type <class 'pandas.core.frame.DataFrame'> //View size (1704, 6) //Check column names Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object') //View dtypes (column based) country object continent object year int64 lifeExp float64 pop int64 gdpPercap float64 dtype: object //View statistics <class 'pandas.core.frame.DataFrame'> RangeIndex: 1704 entries, 0 to 1703 Data columns (total 6 columns): country 1704 non-null object continent 1704 non-null object year 1704 non-null int64 lifeExp 1704 non-null float64 pop 1704 non-null int64 gdpPercap 1704 non-null float64 dtypes: float64(2), int64(2), object(2) memory usage: 80.0+ KB None
| Pandas type | Python type |
|---|---|
| object | string |
| int64 | int |
| float64 | float |
| datetime64 | datetime |
Columns and cells
col.py
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # qq group: 144081101 591302926 567351477 # CreateDate: 2018-06-07 # col.py import pandas as pd df = pd.read_csv(r"../data/gapminder.tsv", sep='\t') # Column operation country_df = df['country'] # Column name selection single column print("\n\n The first 5 lines") print(country_df.head()) print("\n\n Row and tail 5 rows") print(country_df.tail()) country_df_dot = df.country # Select column by point number print("\n\n Select column by point number") print(country_df_dot.head()) subset = df[['country', 'continent', 'year']] # Select multiple columns print("\n\n Select multiple columns") print(subset.head())
results of enforcement
$ ./col.py
The first 5 lines
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
Name: country, dtype: object
Row and tail 5 rows
1699 Zimbabwe
1700 Zimbabwe
1701 Zimbabwe
1702 Zimbabwe
1703 Zimbabwe
Name: country, dtype: object
Select column by point number
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
Name: country, dtype: object
Select multiple columns
country continent year
0 Afghanistan Asia 1952
1 Afghanistan Asia 1957
2 Afghanistan Asia 1962
3 Afghanistan Asia 1967
4 Afghanistan Asia 1972
row.py
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # qq group: 144081101 591302926 567351477 # CreateDate: 2018-06-07 # row.py import pandas as pd df = pd.read_csv(r"../data/gapminder.tsv", sep='\t') # Line operation, note that df.loc[-1] is illegal print("\n\n first line") print(df.loc[0]) print("\n\n Row number") number_of_rows = df.shape[0] print(number_of_rows) last_row_index = number_of_rows - 1 print("\n\n Last line") print(df.loc[last_row_index]) print("\n\ntail Method to output the last line") print(df.tail(n=1)) subset_loc = df.loc[0] subset_head = df.head(n=1) print("\n\nloc Of type sequence Series") print(type(subset_loc)) print("\n\nhead The type of is data frame DataFrame") print(type(subset_head)) print("\n\nloc Select three columns of data frame type DataFrame") print(df.loc[[0, 99, 999]]) print(type(df.loc[[0, 99, 999]])) print("\n\niloc Select first line") print(df.iloc[0]) print("\n\niloc Select three rows") print(df.iloc[[0, 99, 999]])
results of enforcement
$ ./row.py //first line country Afghanistan continent Asia year 1952 lifeExp 28.801 pop 8425333 gdpPercap 779.445 Name: 0, dtype: object //Row number 1704 //Last line country Zimbabwe continent Africa year 2007 lifeExp 43.487 pop 12311143 gdpPercap 469.709 Name: 1703, dtype: object tail Method to output the last line country continent year lifeExp pop gdpPercap 1703 Zimbabwe Africa 2007 43.487 12311143 469.709298 loc Of type sequence Series <class 'pandas.core.series.Series'> head The type of is data frame DataFrame <class 'pandas.core.frame.DataFrame'> loc Select three columns of data frame type DataFrame country continent year lifeExp pop gdpPercap 0 Afghanistan Asia 1952 28.801 8425333 779.445314 99 Bangladesh Asia 1967 43.453 62821884 721.186086 999 Mongolia Asia 1967 51.253 1149500 1226.041130 <class 'pandas.core.frame.DataFrame'> iloc Select first line country Afghanistan continent Asia year 1952 lifeExp 28.801 pop 8425333 gdpPercap 779.445 Name: 0, dtype: object iloc Select three rows country continent year lifeExp pop gdpPercap 0 Afghanistan Asia 1952 28.801 8425333 779.445314 99 Bangladesh Asia 1967 43.453 62821884 721.186086 999 Mongolia Asia 1967 51.253 1149500 1226.041130
mix.py
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # qq group: 144081101 591302926 567351477 # CreateDate: 2018-06-07 # mix.py import pandas as pd df = pd.read_csv(r"../data/gapminder.tsv", sep='\t') # Mixed selection print("\n\nloc Select coordinates") print(df.loc[42, 'country']) print("\n\niloc Select coordinates") print(df.iloc[42, 0]) print("\n\nloc Select subset") print(df.loc[[0, 99, 999], ['country', 'lifeExp', 'gdpPercap']])
results of enforcement
#!python $ ./mix.py loc Select coordinates Angola iloc Select coordinates Angola loc Select subset country lifeExp gdpPercap 0 Afghanistan 28.801 779.445314 99 Bangladesh 43.453 721.186086 999 Mongolia 51.253 1226.041130
Grouping and aggregation
group.py
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # qq group: 144081101 591302926 567351477 # CreateDate: 2018-06-07 # group.py import pandas as pd df = pd.read_csv(r"../data/gapminder.tsv", sep='\t') print("\n\n Annual per capita output value") print(df.groupby('year')['lifeExp'].mean()) print("\n\n Group by year") grouped_year_df = df.groupby('year') print(type(grouped_year_df)) print(grouped_year_df) print("\n\nlifeExp") grouped_year_df_lifeExp = grouped_year_df['lifeExp'] print(type(grouped_year_df_lifeExp)) print(grouped_year_df_lifeExp) print("\n\n Annual average output value") mean_lifeExp_by_year = grouped_year_df_lifeExp.mean() print(mean_lifeExp_by_year) print("\n\n Group by year and continent") print(df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean()) print("\n\n Count countries per continent") print(df.groupby('continent')['country'].nunique())
results of enforcement
#!python $ ./group.py //Annual per capita output value year 1952 49.057620 1957 51.507401 1962 53.609249 1967 55.678290 1972 57.647386 1977 59.570157 1982 61.533197 1987 63.212613 1992 64.160338 1997 65.014676 2002 65.694923 2007 67.007423 Name: lifeExp, dtype: float64 //Group by year <class 'pandas.core.groupby.groupby.DataFrameGroupBy'> <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x7f0e2b0c89e8> lifeExp <class 'pandas.core.groupby.groupby.SeriesGroupBy'> <pandas.core.groupby.groupby.SeriesGroupBy object at 0x7f0e151e2f28> //Annual average output value year 1952 49.057620 1957 51.507401 1962 53.609249 1967 55.678290 1972 57.647386 1977 59.570157 1982 61.533197 1987 63.212613 1992 64.160338 1997 65.014676 2002 65.694923 2007 67.007423 Name: lifeExp, dtype: float64 //Group by year and continent lifeExp gdpPercap year continent 1952 Africa 39.135500 1252.572466 Americas 53.279840 4079.062552 Asia 46.314394 5195.484004 Europe 64.408500 5661.057435 Oceania 69.255000 10298.085650 1957 Africa 41.266346 1385.236062 Americas 55.960280 4616.043733 Asia 49.318544 5787.732940 Europe 66.703067 6963.012816 Oceania 70.295000 11598.522455 1962 Africa 43.319442 1598.078825 Americas 58.398760 4901.541870 Asia 51.563223 5729.369625 Europe 68.539233 8365.486814 Oceania 71.085000 12696.452430 1967 Africa 45.334538 2050.363801 Americas 60.410920 5668.253496 Asia 54.663640 5971.173374 Europe 69.737600 10143.823757 Oceania 71.310000 14495.021790 1972 Africa 47.450942 2339.615674 Americas 62.394920 6491.334139 Asia 57.319269 8187.468699 Europe 70.775033 12479.575246 Oceania 71.910000 16417.333380 1977 Africa 49.580423 2585.938508 Americas 64.391560 7352.007126 Asia 59.610556 7791.314020 Europe 71.937767 14283.979110 Oceania 72.855000 17283.957605 1982 Africa 51.592865 2481.592960 Americas 66.228840 7506.737088 Asia 62.617939 7434.135157 Europe 72.806400 15617.896551 Oceania 74.290000 18554.709840 1987 Africa 53.344788 2282.668991 Americas 68.090720 7793.400261 Asia 64.851182 7608.226508 Europe 73.642167 17214.310727 Oceania 75.320000 20448.040160 1992 Africa 53.629577 2281.810333 Americas 69.568360 8044.934406 Asia 66.537212 8639.690248 Europe 74.440100 17061.568084 Oceania 76.945000 20894.045885 1997 Africa 53.598269 2378.759555 Americas 71.150480 8889.300863 Asia 68.020515 9834.093295 Europe 75.505167 19076.781802 Oceania 78.190000 24024.175170 2002 Africa 53.325231 2599.385159 Americas 72.422040 9287.677107 Asia 69.233879 10174.090397 Europe 76.700600 21711.732422 Oceania 79.740000 26938.778040 2007 Africa 54.806038 3089.032605 Americas 73.608120 11003.031625 Asia 70.728485 12473.026870 Europe 77.648600 25054.481636 Oceania 80.719500 29810.188275 //Count countries per continent continent Africa 52 Americas 25 Asia 33 Europe 30 Oceania 2 Name: country, dtype: int64
Basic drawing
import pandas as pd df = pd.read_csv(r"../data/gapminder.tsv", sep='\t') global_yearly_life_expectancy = df.groupby('year')['lifeExp'].mean() print(global_yearly_life_expectancy) global_yearly_life_expectancy.plot()
-
python test development library involved in this article Please like github, thank you!
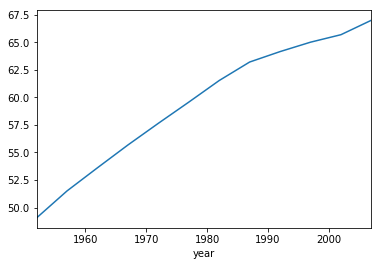
image.png