Source link: http://shiyanjun.cn/archives/1857.html , thanks for sharing.
Broadcast State is an Operator State supported by Flink. Using Broadcast State, you can input data records in a Stream of Flink program, and then broadcast these data records to each Task downstream, so that these data records can be shared by all tasks, such as some data records for configuration. In this way, when each Task processes the records in its corresponding Stream, it reads these configurations to meet the actual data processing needs.
In addition, to a certain extent, Broadcast State can decouple Flink Job from other external systems during operation. For example, Flink usually uses YARN to manage computing resources. Using Broadcast State, you can read relevant configuration information without directly connecting to MySQL database, and do not need to do additional authorization operations on MySQL. Because in some scenarios, Flink on YARN deployment mode will be used to submit the resource application and release of Flink Job to YARN for management, there will be the problem of expanding and shrinking Hadoop cluster nodes. For example, new nodes may need to access some external systems, such as mysql, for connection operation authorization. If you forget to access mysql, Flink Job will be dispatched to a new one There will be errors when you connect and read MySQL configuration information on the new nodes.
Broadcast State API
Generally, we will first create a Keyed or non Keyed Data Stream, then create a Broadcasted Stream, and finally connect (call the connect method) to the Broadcasted Stream through the Data Stream, so as to broadcast the broadcasted state to each Task downstream of the Data Stream.
If the Data Stream is Keyed Stream, after connecting to the Broadcasted Stream, the KeyedBroadcastProcessFunction needs to be used to add processing ProcessFunction. The following is the API of KeyedBroadcastProcessFunction, and the code is as follows:
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}The meanings of the parameters in the above generics are as follows:
- KS: indicates the type of Key that Flink program depends on when calling keyBy when building Stream from the upstream Source Operator;
- IN1: indicates the type of data record in the non Broadcast Data Stream;
- IN2: indicates the type of data record in the Broadcast Stream;
- OUT: indicates the type of output data record after being processed by processElement() and processBroadcastElement() methods of keyedprocessfunction.
If the Data Stream is a non keyed stream, after connecting to the Broadcasted Stream, the broadcasteprocessfunction needs to be used to add processing ProcessFunction. The following is the API of broadcasteprocessfunction, and the code is as follows:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}The meanings of the above generic parameters are the same as the last three in the generic type of keyedboardprocessfunction, except that KS generic parameters are not needed without calling the keyBy operation to partition the original Stream.
How to use the above BroadcastProcessFunction? Next, we will explain it in detail with the example of KeyedBroadcastProcessFunction through actual programming.
Use scenario practice
User shopping path length tracking scenario description
Let's first describe the scenario of using Broadcast State:
According to the event of the user's operation on the mobile App, the specified operation is triggered in real time by tracking the user's operation. Suppose we pay attention to a user's purchase behavior after multiple operations on the App, such as browsing several goods, adding the browsed goods to the shopping cart, removing the goods from the shopping cart, etc., then we define the number of operations from the beginning to the final purchase as the length of the user's shopping path This concept assumes that we can improve the repurchase rate of users by pushing the privilege of discount, or reminding users to use the App and other operation activities in a timely manner. This is the goal we want to achieve.
Events are collected in the specified format in real time. We use JSON format to represent them. For example, we define the following types of user actions on the App:
- VIEW_PRODUCT
- ADD_TO_CART
- REMOVE_FROM_CART
- PURCHASE
It is easy to understand the meaning of each type according to the above event type definition. In the process of the user's final PURCHASE order, there will be a series of operations: view product, add to cart, remove from cart. Each operation can be repeated many times, and finally the PURCHASE type PURCHASE occurs. Then we calculate the length of the user's shopping path, and provide operation or analysis activities for the external business system by calculating the measurement Based on the basic data, the external system can carry out various operation activities for users.
For example, the following are records of several sample events, as follows:
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":196}}
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"ADD_TO_CART","eventTime":"2018-06-12_09:43:18","data":{"productId":126}}
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":126}}
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"PURCHASE","eventTime":"2018-06-12_09:30:28","data":{"productId":196,"price":600.00,"amount":600.00}}In addition, because there are many registered users of the App, it is impossible for all users to meet specific conditions in their shopping behavior paths. Assuming that the length of the shopping path is very short, it is likely that the user has a strong purpose when using the App, and will place an order for purchase soon. For such users, we do not want to do any operation activities for them at the moment, so we need to input the correct value when processing the flow data The configuration value of the expected path length to limit this situation. Moreover, over time, the value may change according to the actual business needs. We hope that the entire Flink computing program can dynamically obtain and update the corresponding configuration value. The configuration string is also in JSON format, as shown in the following example:
{"channel":"APP","registerDate":"2018-01-01","historyPurchaseTimes":0,"maxPurchasePathLength":3}At this time, it is very convenient to use the Broadcast State feature provided by Flink. In addition, we can assume that there are many different channels. Here we will only take APP channel as an example to illustrate the practice.
Assuming that users who meet the maximum configured shopping path length are satisfied, we can calculate the shopping path length of this user, and output it to another designated Kafka Topic at the same time, so that other systems can consume this Topic, so as to carry out personalized operation for these users. For example, the calculated result format, in addition to the length of a shopping path, also counts the number of each operation behavior in the purchase process. The JSON format string is as follows:
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","purchasePathLength":9,"eventTypeCounts":{"ADD_TO_CART":1,"PURCHASE":1,"VIEW_PRODUCT":7}}We haven't considered how to use the result data in the subsequent external systems for the time being.
basic design
Based on the usage scenario described above, in order to intuitively express the technical architecture, basic components and data processing flow of the system, the basic design is shown as follows:
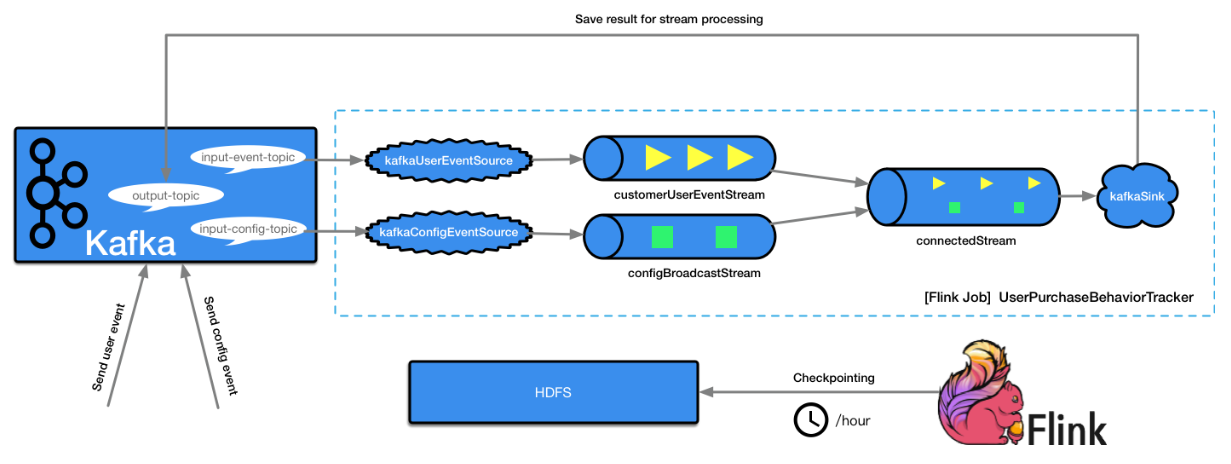
As shown in the figure above, it is our plan to implement the flow processing process. The corresponding key points are described as follows:
- User action events are written to Kafka's Topic in real time and specified by the input event Topic parameter.
- Based on the Topic specified by the input event Topic parameter, create a Flink Source Operator named kafkaUserEventSource.
- Create a Data Stream named customerUserEventStream based on kafkaUserEventSource.
- The channel configuration information is updated according to the actual business needs and written into the Topic of Kafka in real time, which is specified by the input-config-topic parameter.
- Based on the Topic specified by the input config Topic parameter, create a Flink Source Operator named kafkaConfigEventSource.
- Create a Broadcast Stream named configBroadcastStream based on kafkaConfigEventSource.
- Connect the two streams created above to the configBroadcastStream through customerUserEventStream to get a new connectedStream.
- Based on the connectedStream, the ProcessFunction implementation is set to process the data records in the new Stream. The unified configuration information can be obtained in each Task, and then the user events can be processed.
- Send the processing result to the Flink Sink Operator with the name of kafkaSink.
- kafkaSink saves the processed results to Kafka's Topic, and specifies the Topic name through output Topic.
In addition, turn on the Checkpoint function in the Flink Job, and check the status in the Flink Job every hour to ensure that the flow processing process can recover after failure.
Implement Flink Job main process processing
We store the input user action event into a Kafka Topic in real time, and use a Kafka Topic to store the related configuration, so we will build two streams: one is a normal Stream to handle the user action event; the other is a Broadcast Stream to handle and update the configuration information. The final results of the calculation will be saved in another Kafka Topic for consumption processing by other external systems to support operation or analysis activities.
- input parameter
The input parameter format of Flink program is as follows:
LOG.info("Input args: " + Arrays.asList(args));
// parse input arguments
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
if (parameterTool.getNumberOfParameters() < 5) {
System.out.println("Missing parameters!\n" +
"Usage: Kafka --input-event-topic <topic> --input-config-topic <topic> --output-topic <topic> " +
"--bootstrap.servers <kafka brokers> " +
"--zookeeper.connect <zk quorum> --group.id <some id>");
return;
}Corresponding to the three topics described above, the configuration Key is input event Topic, input config Topic and output Topic respectively. In addition, there are two parameters, bootstrap.servers and zookeeper.connect, which are necessary for establishing connection with Kafka cluster. The specific meaning will not be described in detail. Please refer to other documents.
- Configure Flink environment
It is necessary to set the relevant running configuration of Flink, including Checkpoint. The code is as follows:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend(
"hdfs://namenode01.td.com/flink-checkpoints/customer-purchase-behavior-tracker"));
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
config.setCheckpointInterval(1 * 60 * 60 * 1000);
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);Specify that the Checkpoint function is enabled during the operation of the Flink Job, and the Checkpoint data is stored in the specified HDFS path hdfs://namenode01.td.com/flink-checkpoints/customer-purchase-behavior-tracker, and the Checkpoint interval is one hour. For the TimeCharacteristic used in Flink processing, we use TimeCharacteristic.EventTime, that is, we process according to the time of the event itself, which is used to generate Watermark timestamps. For the implementation of generating watermarks, we use the BoundedOutOfOrdernessTimestampExtractor, which is to set a maximum time length to tolerate event disorder. The implementation code is as follows: The following shows:
private static class CustomWatermarkExtractor extends BoundedOutOfOrdernessTimestampExtractor<UserEvent> {
public CustomWatermarkExtractor(Time maxOutOfOrderness) {
super(maxOutOfOrderness);
}
@Override
public long extractTimestamp(UserEvent element) {
return element.getEventTimestamp();
}
}- Create user behavior event Stream
Create a Stream to handle the user's action events on the App, use map for transformation, and use keyBy to partition the Stream. The implementation code is as follows:
// create customer user event stream
final FlinkKafkaConsumer010 kafkaUserEventSource = new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-event-topic"),
new SimpleStringSchema(), parameterTool.getProperties());
// (userEvent, userId)
final KeyedStream<UserEvent, String> customerUserEventStream = env
.addSource(kafkaUserEventSource)
.map(new MapFunction<String, UserEvent>() {
@Override
public UserEvent map(String s) throws Exception {
return UserEvent.buildEvent(s);
}
})
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor(Time.hours(24)))
.keyBy(new KeySelector<UserEvent, String>() {
@Override
public String getKey(UserEvent userEvent) throws Exception {
return userEvent.getUserId();
}
});The above events read from Kafka's Topic are all JSON format strings. We call map to convert them into UserEvent objects, continue to call assignTimestampsAndWatermarks() method to set watermarks, and call keyBy() method to set to partition the data records in the Stream according to the user ID (userId). That is to say, the operation behavior events belonging to the same user will be sent to the same user In this way, the status information related to a user can be saved completely in the Task, so that a calculation can be made after the PURCHASE type shopping operation event arrives. If the configuration conditions are met, the cached event will be processed and the final result will be output.
- Create configuration event Stream
Create a Broadcast Stream to dynamically read the configuration in Kafka Topic. It is based on Flink's Broadcast State feature. The implementation code is as follows:
// create dynamic configuration event stream
final FlinkKafkaConsumer010 kafkaConfigEventSource = new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-config-topic"),
new SimpleStringSchema(), parameterTool.getProperties());
final BroadcastStream<Config> configBroadcastStream = env
.addSource(kafkaConfigEventSource)
.map(new MapFunction<String, Config>() {
@Override
public Config map(String value) throws Exception {
return Config.buildConfig(value);
}
})
.broadcast(configStateDescriptor);In the above code, the last line calls the broadcast() method to specify the state variable to be broadcast. It will be sent to each Task downstream when the Flink program is running for the Task to read and use the corresponding configuration information. The downstream Task can get the corresponding configuration value according to the state variable. The parameter value configStateDescriptor is an object of MapStateDescriptor type, which is defined and initialized. The code is as follows:
private static final MapStateDescriptor<String, Config> configStateDescriptor =
new MapStateDescriptor<>(
"configBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint<Config>() {}));It uses the channel field in the event as the Key, that is to say, the corresponding configuration of different channels is different, which realizes the flexibility of channel configuration. The corresponding Value is Config defined by us. The following properties are specified in this class:
private String channel; private String registerDate; private int historyPurchaseTimes; private int maxPurchasePathLength;
The specific meaning can be learned from the property name naming. After broadcasting, each Task downstream can read these configuration property values.
- Connecting two streams and realizing calculation processing
We need to save the final calculation results to an output Kafka Topic, so first create a FlinkKafkaProducer010, the code is as follows:
final FlinkKafkaProducer010 kafkaProducer = new FlinkKafkaProducer010<>(
parameterTool.getRequired("output-topic"),
new EvaluatedResultSchema(),
parameterTool.getProperties());Then, call the connect() method of customerUserEventStream to connect to configBroadcastStream to obtain the corresponding configuration information in configBroadcastStream, and then process the actual business logic. The code is as follows:
// connect above 2 streams
DataStream<EvaluatedResult> connectedStream = customerUserEventStream
.connect(configBroadcastStream)
.process(new ConnectedBroadcastProcessFuntion());
connectedStream.addSink(kafkaProducer);
env.execute("UserPurchaseBehaviorTracker");The user action event Stream calls the connect() method, and the parameter is Broadcast Stream. Then a new Stream of broadcastconnectidstream type can be generated. The process() method is called, and the logic of data record processing in the Stream is added.
Process BroadcastConnectedStream
BroadcastConnectedStream calls the process() method. The parameter type is KeyedBroadcastProcessFunction or BroadcastProcessFunction. Our implementation class here is connectedbroadcastprocessfunction, which inherits from the abstract KeyedBroadcastProcessFunction class. Through the previous Broadcast State API part, we have learned that two processing methods, processbroadelement() and processElement(), need to be implemented. One is to process the Broadcast Stream, and the other is to process the user action action event Stream. First, we define a state variable in connectedbroadcastprocessfunction to store user action action action events. The code is as follows:
// (channel, Map<uid, UserEventContainer>)
private final MapStateDescriptor<String, Map<String, UserEventContainer>> userMapStateDesc =
new MapStateDescriptor<>(
"userEventContainerState",
BasicTypeInfo.STRING_TYPE_INFO,
new MapTypeInfo<>(String.class, UserEventContainer.class));In the above code, userMapStateDesc is a Map structure, Key is a channel, and Value is a Map structure containing userId and UserEventContainer. The UserEventContainer internally encapsulates a List to save the UserEvent List belonging to the same user.
Let's take a look at the implementation of processBroadcastElement() method. The code is as follows:
@Override
public void processBroadcastElement(Config value, Context ctx, Collector<EvaluatedResult> out)
throws Exception {
String channel = value.getChannel();
BroadcastState<String, Config> state = ctx.getBroadcastState(configStateDescriptor);
final Config oldConfig = ctx.getBroadcastState(configStateDescriptor).get(channel);
if(state.contains(channel)) {
LOG.info("Configured channel exists: channel=" + channel);
LOG.info("Config detail: oldConfig=" + oldConfig + ", newConfig=" + value);
} else {
LOG.info("Config detail: defaultConfig=" + defaultConfig + ", newConfig=" + value);
}
// update config value for configKey
state.put(channel, value);
}By calling ctx.getbroadcast state (configstatedescriptor), you can get the corresponding broadcast state according to the MapStateDescriptor defined above, including channel and Config objects. The above implementation logic includes that if the corresponding configuration change operation is updated, the updated configuration information will be stored in the BroadcastState, which is actually a Map structure, and the corresponding latest configuration Value can be obtained through the Key (here the Key is the channel, and the Value is the Config object).
Take a look at the implementation of processElement() method. Its implementation is the core part of business processing. The code is as follows:
@Override
public void processElement(UserEvent value, ReadOnlyContext ctx,
Collector<EvaluatedResult> out) throws Exception {
String userId = value.getUserId();
String channel = value.getChannel();
EventType eventType = EventType.valueOf(value.getEventType());
Config config = ctx.getBroadcastState(configStateDescriptor).get(channel);
LOG.info("Read config: channel=" + channel + ", config=" + config);
if (Objects.isNull(config)) {
config = defaultConfig;
}
final MapState<String, Map<String, UserEventContainer>> state =
getRuntimeContext().getMapState(userMapStateDesc);
// collect per-user events to the user map state
Map<String, UserEventContainer> userEventContainerMap = state.get(channel);
if (Objects.isNull(userEventContainerMap)) {
userEventContainerMap = Maps.newHashMap();
state.put(channel, userEventContainerMap);
}
if (!userEventContainerMap.containsKey(userId)) {
UserEventContainer container = new UserEventContainer();
container.setUserId(userId);
userEventContainerMap.put(userId, container);
}
userEventContainerMap.get(userId).getUserEvents().add(value);
// check whether a user purchase event arrives
// if true, then compute the purchase path length, and prepare to trigger predefined actions
if (eventType == EventType.PURCHASE) {
LOG.info("Receive a purchase event: " + value);
Optional<EvaluatedResult> result = compute(config, userEventContainerMap.get(userId));
result.ifPresent(r -> out.collect(result.get()));
// clear evaluated user's events
state.get(channel).remove(userId);
}
}By calling ctx.getbroadcast state (configstatedescriptor). Get (channel), the latest configuration Config object of a channel in the Broadcast Stream is obtained, and then the configuration information can be used during event processing. Once the configuration information is changed, the configuration value processed and updated by processBroadcastElement() method will also be obtained in real time. The operation behavior events of each user arriving will be saved in the state variable of MapStateDescriptor type userMapStateDesc first, and the cache will be accumulated continuously. Once a PURCHASE event of type PURCHASE of the user arrives, the result data will be calculated by calling the compute() method, and finally the result data EvaluatedResult will be output to the Task corresponding to Sink Operator, and saved in Ka FKA topic. The compute () method is invoked in the above code, and is implemented as follows:
private Optional<EvaluatedResult> compute(Config config, UserEventContainer container) {
Optional<EvaluatedResult> result = Optional.empty();
String channel = config.getChannel();
int historyPurchaseTimes = config.getHistoryPurchaseTimes();
int maxPurchasePathLength = config.getMaxPurchasePathLength();
int purchasePathLen = container.getUserEvents().size();
if (historyPurchaseTimes < 10 && purchasePathLen > maxPurchasePathLength) {
// sort by event time
container.getUserEvents().sort(Comparator.comparingLong(UserEvent::getEventTimestamp));
final Map<String, Integer> stat = Maps.newHashMap();
container.getUserEvents()
.stream()
.collect(Collectors.groupingBy(UserEvent::getEventType))
.forEach((eventType, events) -> stat.put(eventType, events.size()));
final EvaluatedResult evaluatedResult = new EvaluatedResult();
evaluatedResult.setUserId(container.getUserId());
evaluatedResult.setChannel(channel);
evaluatedResult.setEventTypeCounts(stat);
evaluatedResult.setPurchasePathLength(purchasePathLen);
LOG.info("Evaluated result: " + evaluatedResult.toJSONString());
result = Optional.of(evaluatedResult);
}
return result;
}The above code uses the configuration object Config to determine whether the corresponding calculation result of the user needs to be output. If so, the length of the shopping path is calculated and the number of event types of the user's operation behavior is counted.
Submit to run Flink Job
We need to create the corresponding Topic. The creation command reference is as follows:
./bin/kafka-topics.sh --zookeeper 172.23.4.138:2181,172.23.4.139:2181,172.23.4.140:2181/kafka --create --topic user_events --replication-factor 1 --partitions 1 ./bin/kafka-topics.sh --zookeeper 172.23.4.138:2181,172.23.4.139:2181,172.23.4.140:2181/kafka --create --topic app_config --replication-factor 1 --partitions 1 ./bin/kafka-topics.sh --zookeeper 172.23.4.138:2181,172.23.4.139:2181,172.23.4.140:2181/kafka --create --topic action_result --replication-factor 1 --partitions 1
After the above program is developed, it needs to compile and package, submit Flink Job to Flink cluster, and execute the following command:
bin/flink run -d -c org.shirdrn.flink.broadcaststate.UserPurchaseBehaviorTracker ~/flink-app-jobs.jar --input-event-topic user_events --input-config-topic app_config --output-topic action_result --bootstrap.servers 172.23.4.138:9092 --zookeeper.connect zk01.td.com:2181,zk02.td.com:2181,zk03.td.com:2181/kafka --group.id customer-purchase-behavior-tracker
After Flink Job runs normally, we send configuration event records to Kafka's app config Topic:
./bin/kafka-console-producer.sh --topic app_config --broker-list 172.23.4.138:9092
Enter the following configuration event JSON string:
{"channel":"APP","registerDate":"2018-01-01","historyPurchaseTimes":0,"maxPurchasePathLength":6}Send event records of user operation behavior to Kafka's user events Topic:
./bin/kafka-console-producer.sh --topic app_config --broker-list 172.23.4.138:9092
./bin/kafka-console-producer.sh --topic app_config --broker-list 172.23.4.138:9092
Enter the JSON string of each operation behavior event of the following users in turn:
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_08:45:24","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_08:57:32","data":{"productId":273}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:21:08","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:21:49","data":{"productId":103}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:21:59","data":{"productId":157}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"ADD_TO_CART","eventTime":"2018-06-12_09:43:18","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"PURCHASE","eventTime":"2018-06-12_09:30:28","data":{"productId":126,"price":299.00,"amount":260.00}}
As you can see, each input event will be received and processed in the Task. When inputting to the last user purchase event, the calculation is triggered and the result is output. You can see the result in another output Kafka topic action "result, as shown below:
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","purchasePathLength":9,"eventTypeCounts":{"ADD_TO_CART":1,"PURCHASE":1,"VIEW_PRODUCT":7}}If we change the previous configuration to the following:
{"channel":"APP","registerDate":"2018-01-01","historyPurchaseTimes":0,"maxPurchasePathLength":20}Also input the above user action action event record. Since maxPurchasePathLength=20, the corresponding result calculation and output are not triggered. Because purchasePathLength=9, it can be seen that the configuration dynamic change takes effect.
See github for specific code:

