Preface:
In response to AJAX dynamic loading, users' dynamic information of Jianshu network should be crawled, and the crawled data should be stored in MongoDB database
In order to sort out the code, sort out the ideas and verify the validity of the code -- January 21, 2020
Environmental Science:
Python3(Anaconda3)
PyCharm
Chrome browser
Main module: followed by the instructions in brackets for installing in the cmd window
requests(pip install requests)
lxml(pip install lxml)
pymongo(pip install pymongo )
1
First of all, we briefly introduce the asynchronous loading (AJAX), which is actually a technology that can update some web pages without reloading the whole web page. 1
The embodiment in the web page is shown in the screenshot. After clicking "article" and "dynamic", their url hasn't changed. Here is the so-called use of asynchronous loading (AJAX).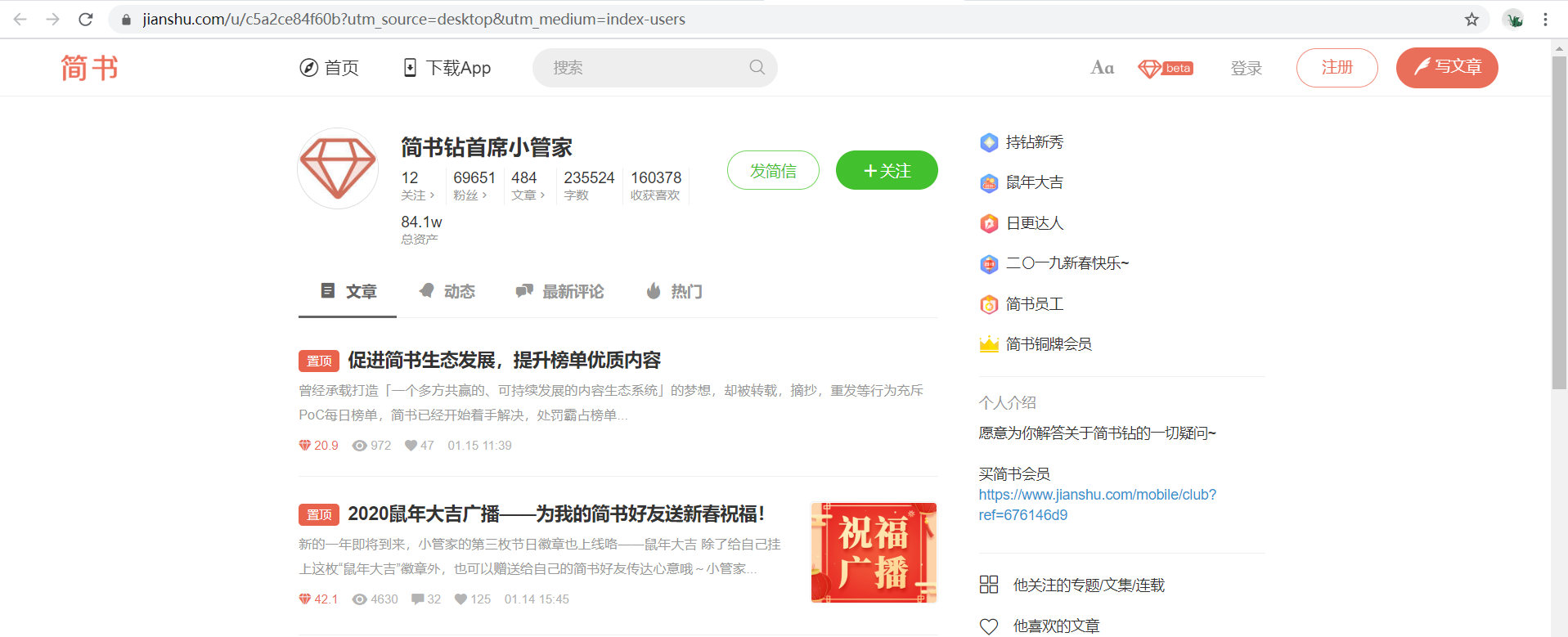
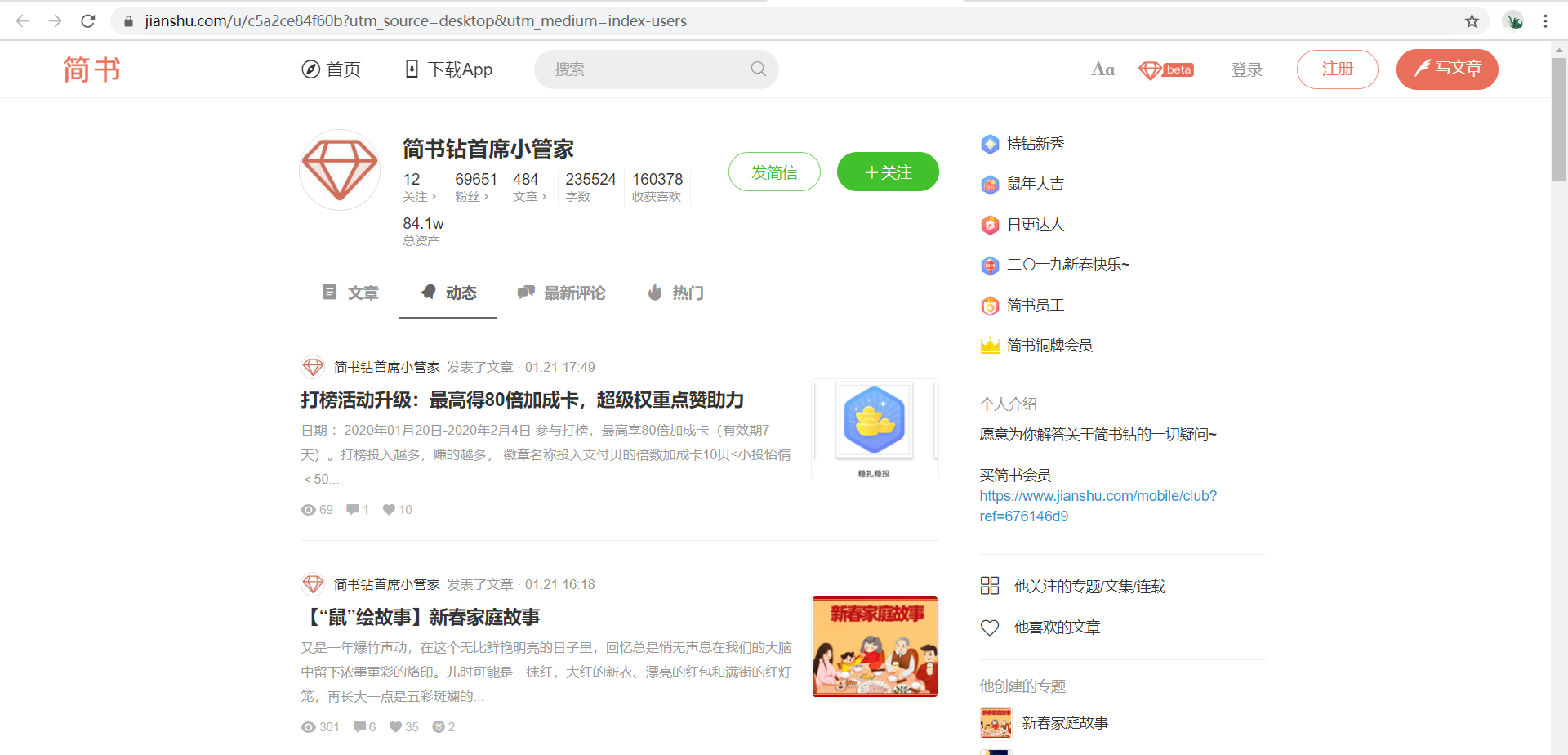
2
When crawling information, how do we deal with it? Open developer tool F12, switch to Network interface and select XHR file, click dynamic, then the developer tool interface should be as shown in the screenshot, and a file named timeline? ﹣ pjax =% 23list container will be generated. This is the first step. Find the dynamic file and get the URL of the real request (box up Now.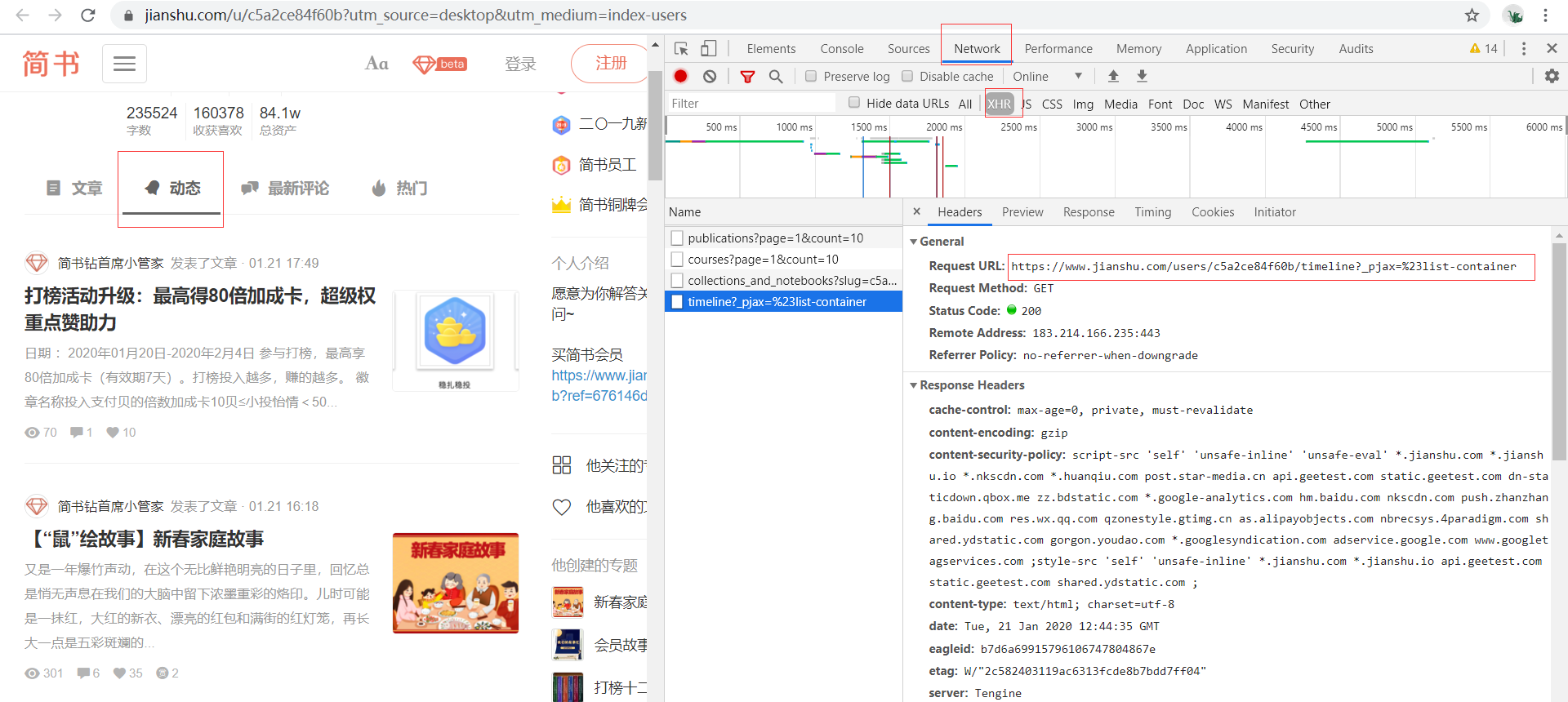
3
At this time, we will try to simplify the deletion of some unnecessary parameters in this URL.
# Original URL https://www.jianshu.com/users/c5a2ce84f60b/timeline?_pjax=%23list-container # After streamlining https://www.jianshu.com/users/c5a2ce84f60b/timeline
In this way, we can construct other URLs through the reduced URLs.
4
When we want to find other pages, we find that there is no paging bar, and the paging of jianshu.com is also realized by asynchronous loading. Let's slide the page to see which files are loaded.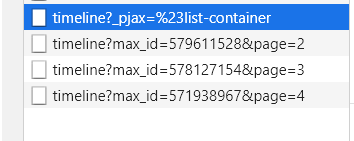
Here, I leave a page parameter for the whimsical first, such as https://www.jianshu.com/users/c5a2ce84f60b/timeline?page=2, but it is not so simple.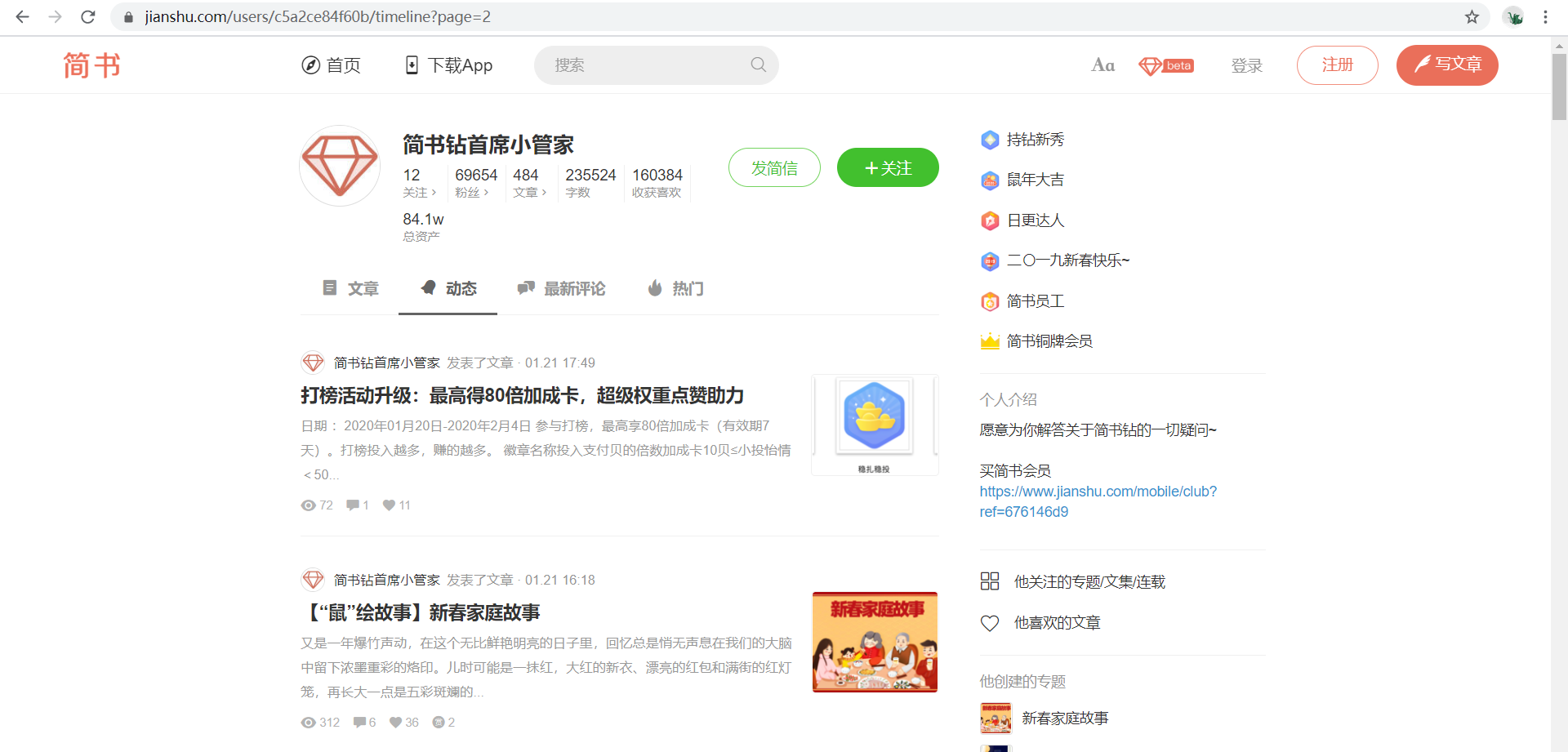
Yes, here is the interface. BUT, this interface is the same as the interface on the first page. It means that the other parameter, Max ㄒ ID, is also an important parameter. Then, we will consider how to obtain Max ㄒ ID.
5
We need a pair of big eyes. Through various searches, we found that the ID attribute value of the last li element tag in these XHR files is the next page's max_id+1. OK, solve the problem smoothly.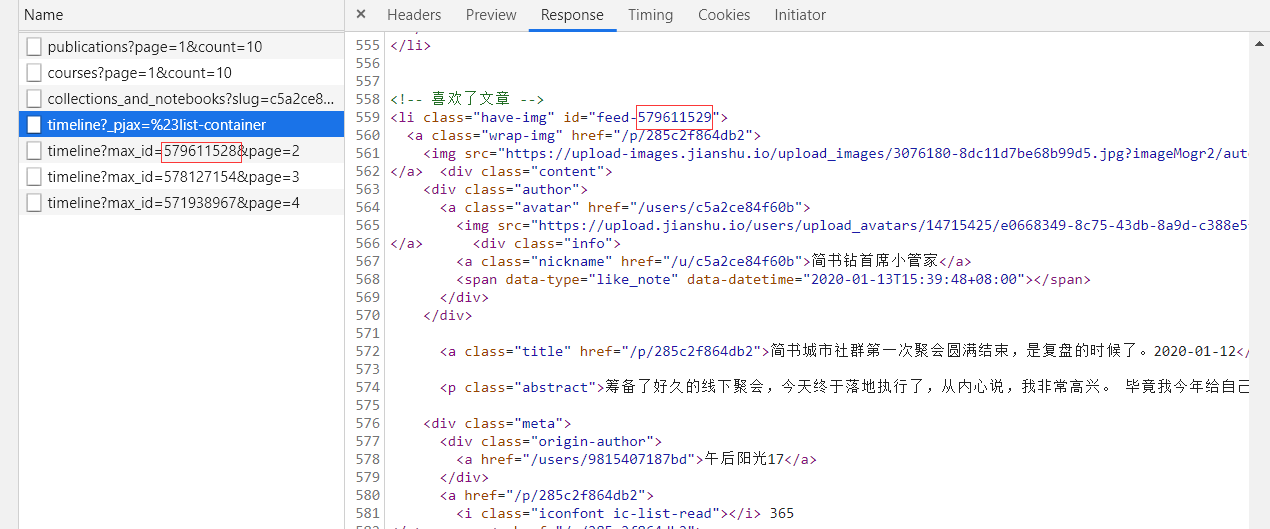
6
The previous 2-6 steps are to deal with the AJAX method of jianshu.com, which is called reverse engineering method. After dealing with this kind of "anti Crawler", the next work is to obtain information and insert it into the MongoDB database.
The information we need to crawl is of dynamic type (below, "like" means "like an article") and dynamic release time.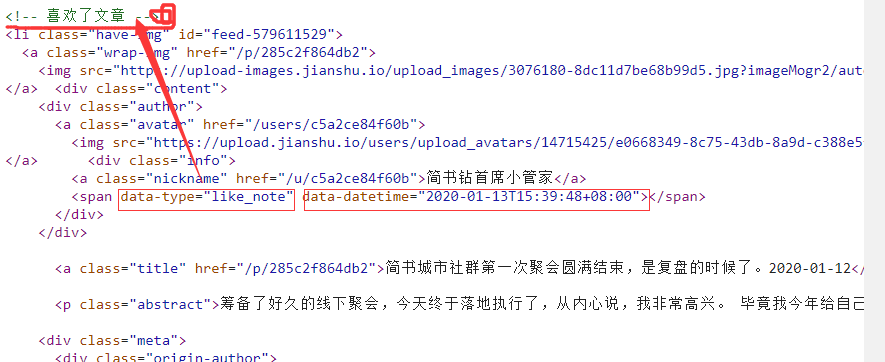
7
I won't talk about the specific web page analysis here. For details, please refer to the complete code. The code is relatively simple, and I have annotated each block. Please leave a message or private message for comments.
Complete code
# url = "https://www.jianshu.com/users/c5a2ce84f60b/timeline?_pjax=%23list-container" # Import library import requests from lxml import etree import pymongo # Connect to MongoDB database client = pymongo.MongoClient('localhost', 27017) # Create databases and data collections mydb = client['mydb'] timeline = mydb['timeline'] # Join request header headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'} def get_time_info(url, page): # Split the url to obtain the user id, for example: https://www.jianshu.com/users/c5a2ce84f60b/timeline user_id = url.split('/') user_id = user_id[4] # If it is the url after the first page, it will contain the words' page = 'and let it turn the page if url.find('page='): page = page+1 html = requests.get(url=url, headers=headers) selector = etree.HTML(html.text) print(url, html.status_code) # Firstly, it is divided into many li blocks to facilitate subsequent data analysis infos = selector.xpath('//ul[@class="note-list"]/li') for info in infos: # time dd = info.xpath('div/div/div/span/@data-datetime')[0] # Dynamic type type = info.xpath('div/div/div/span/@data-type')[0] # Insert data in json or dictionary format timeline.insert_one({'date': dd, 'type': type}) print({'date': dd, 'type': type}) # Get id to construct the url of dynamic page id_infos = selector.xpath('//ul[@class="note-list"]/li/@id') if len(infos) > 1: feed_id = id_infos[-1] # The original feed ID, for example: feed-578127155, needs manual segmentation max_id = feed_id.split('-')[1] # Construct the url of dynamic page next_url = 'http://www.jianshu.com/users/%s/timeline?max_id=%s&page=%s' % (user_id, max_id, page) # Recursive call, crawling the information on the next page get_time_info(next_url, page) if __name__ == '__main__': get_time_info('https://www.jianshu.com/users/c5a2ce84f60b/timeline', 1)

