Contents
2,mark / par_mark / mark_range / par_mark_range / mark_large_range / par_mark_large_range
3,isMarked / par_isMarked / isUnmarked /isAllClear
4,par_clear / clear_range / par_clear_range / clear_large_range / par_clear_large_range /clear_all
5,getNextMarkedWordAddress / getNextUnmarkedWordAddress / getAndClearMarkedRegion
6,iterate / dirty_range_iterate_clear
1. Construction method and allocate
2,pop / push / par_pop / par_push
This blog explains the implementation of the related basic classes of concurrentmarksweetgeneration, which represents the old age of CMS.
1, CardGeneration
CardGeneration refers to the generation that uses card table to mark object modification and BlockOffsetArray to record the starting position of memory block. It inherits from generation and is defined in generation.hpp. The following attributes are added:
- GenRemSet* _rs; / / implementation instance of card table shared with other Generation instances
- BlockOffsetSharedArray* _bts; / / the implementation of BlockOffsetArray exclusive to current Generation
- Size? Shrink? Factor; / / the first time is 0, the second time is 10, the third time is 40, and the fourth time is 100. If there is an expansion in the middle, it will be reset to 0. Start to accumulate again to avoid frequent expansion.
- Size ﹐ t ﹐ min ﹐ heap ﹐ Delta ﹐ bytes; / / the lowest memory value when memory expands or shrinks in the old age
- Size? T? Capacity? At? Prologue; / / memory capacity at the beginning of GC
- Size? T? Used? At? Prologue; / / memory usage at the beginning of GC
Focus on the implementation of the following methods.
1. Constructor
CardGeneration::CardGeneration(ReservedSpace rs, size_t initial_byte_size,
int level,
GenRemSet* remset) :
Generation(rs, initial_byte_size, level), _rs(remset),
_shrink_factor(0), _min_heap_delta_bytes(), _capacity_at_prologue(),
_used_at_prologue()
{
HeapWord* start = (HeapWord*)rs.base();
size_t reserved_byte_size = rs.size();
//start address and reserved byte size must be integral multiples of 4
assert((uintptr_t(start) & 3) == 0, "bad alignment");
assert((reserved_byte_size & 3) == 0, "bad alignment");
MemRegion reserved_mr(start, heap_word_size(reserved_byte_size));
//Initialize bts
_bts = new BlockOffsetSharedArray(reserved_mr,
heap_word_size(initial_byte_size));
MemRegion committed_mr(start, heap_word_size(initial_byte_size));
//Reset memory area corresponding to card table
_rs->resize_covered_region(committed_mr);
if (_bts == NULL)
vm_exit_during_initialization("Could not allocate a BlockOffsetArray");
//Verify that the start address and end address correspond to the start address of a card table entry
guarantee(_rs->is_aligned(reserved_mr.start()), "generation must be card aligned");
if (reserved_mr.end() != Universe::heap()->reserved_region().end()) {
guarantee(_rs->is_aligned(reserved_mr.end()), "generation must be card aligned");
}
//The value of MinHeapDeltaBytes is 128k, indicating the minimum memory during expansion
_min_heap_delta_bytes = MinHeapDeltaBytes;
_capacity_at_prologue = initial_byte_size;
_used_at_prologue = 0;
}2,expand
Expand is used to expand the memory. The first parameter indicates the memory space to be expanded, and the second parameter indicates the minimum memory space to be expanded. If a part of the memory space is expanded, even if it is less than the minimum memory space, then true is returned. The bottom layer will call grow by to complete the expansion, and if the expansion fails, try grow to reserve. It is as follows:
//The first parameter, bytes, indicates the memory size of the expected expansion, and the second parameter indicates the minimum memory size of the expected expansion
bool CardGeneration::expand(size_t bytes, size_t expand_bytes) {
assert_locked_or_safepoint(Heap_lock);
if (bytes == 0) {
return true; // That's what grow_by(0) would return
}
//Do memory alignment
size_t aligned_bytes = ReservedSpace::page_align_size_up(bytes);
if (aligned_bytes == 0){
aligned_bytes = ReservedSpace::page_align_size_down(bytes);
}
size_t aligned_expand_bytes = ReservedSpace::page_align_size_up(expand_bytes);
bool success = false;
if (aligned_expand_bytes > aligned_bytes) {
//Expand memory space. Normally, aligned_bytes is larger than aligned_expand_bytes
success = grow_by(aligned_expand_bytes);
}
if (!success) {
success = grow_by(aligned_bytes);
}
if (!success) {
//If it still fails to expand, try to expand to the maximum memory
success = grow_to_reserved();
}
if (PrintGC && Verbose) {
if (success && GC_locker::is_active_and_needs_gc()) {
gclog_or_tty->print_cr("Garbage collection disabled, expanded heap instead");
}
}
return success;
}
The call chain is as follows:
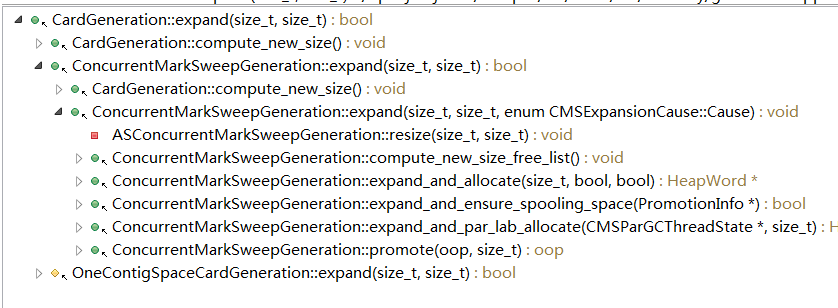
3,compute_new_size
This method is to recalculate the expected capacity according to the parameters MinHeapFreeRatio and MaxHeapFreeRatio and the current memory usage after GC, and do appropriate expansion or reduction processing, as shown below:
void CardGeneration::compute_new_size() {
assert(_shrink_factor <= 100, "invalid shrink factor");
size_t current_shrink_factor = _shrink_factor;
//Set the "shrink" factor to 0, and it will be reassigned when the volume is reduced later
_shrink_factor = 0;
//MinHeapFreeRatio indicates the lowest percentage of free memory in the total memory of the elderly. The default value is 80
//Calculate the minimum idle percentage and the maximum used percentage
const double minimum_free_percentage = MinHeapFreeRatio / 100.0;
const double maximum_used_percentage = 1.0 - minimum_free_percentage;
//Get capacity and used after GC
const size_t used_after_gc = used();
const size_t capacity_after_gc = capacity();
//Calculate the expected minimum capacity, which must be greater than the initial value
const double min_tmp = used_after_gc / maximum_used_percentage;
size_t minimum_desired_capacity = (size_t)MIN2(min_tmp, double(max_uintx));
minimum_desired_capacity = MAX2(minimum_desired_capacity,
spec()->init_size());
assert(used_after_gc <= minimum_desired_capacity, "sanity check");
if (PrintGC && Verbose) {
const size_t free_after_gc = free();
const double free_percentage = ((double)free_after_gc) / capacity_after_gc;
gclog_or_tty->print_cr("TenuredGeneration::compute_new_size: ");
gclog_or_tty->print_cr(" "
" minimum_free_percentage: %6.2f"
" maximum_used_percentage: %6.2f",
minimum_free_percentage,
maximum_used_percentage);
gclog_or_tty->print_cr(" "
" free_after_gc : %6.1fK"
" used_after_gc : %6.1fK"
" capacity_after_gc : %6.1fK",
free_after_gc / (double) K,
used_after_gc / (double) K,
capacity_after_gc / (double) K);
gclog_or_tty->print_cr(" "
" free_percentage: %6.2f",
free_percentage);
}
if (capacity_after_gc < minimum_desired_capacity) {
//The current capacity is less than the expected capacity and needs to be expanded
//Calculate the expected capacity expansion
size_t expand_bytes = minimum_desired_capacity - capacity_after_gc;
if (expand_bytes >= _min_heap_delta_bytes) {
//The capacity expansion must be greater than the minimum capacity
expand(expand_bytes, 0); // safe if expansion fails
}
if (PrintGC && Verbose) {
gclog_or_tty->print_cr(" expanding:"
" minimum_desired_capacity: %6.1fK"
" expand_bytes: %6.1fK"
" _min_heap_delta_bytes: %6.1fK",
minimum_desired_capacity / (double) K,
expand_bytes / (double) K,
_min_heap_delta_bytes / (double) K);
}
return;
}
//The current capacity is larger than the expected capacity, so it needs to be reduced
size_t shrink_bytes = 0;
//Calculate the capacity of shrinkage
size_t max_shrink_bytes = capacity_after_gc - minimum_desired_capacity;
//MaxHeapFreeRatio represents the maximum percentage of free heap memory, which is 70% by default. It is used to avoid shrink. It is usually used for the elderly, but it is used for the whole heap under G1 and ParallelGC
if (MaxHeapFreeRatio < 100) {
//Calculate the expected maximum memory capacity according to MaxHeapFreeRatio and used after GC
const double maximum_free_percentage = MaxHeapFreeRatio / 100.0;
const double minimum_used_percentage = 1.0 - maximum_free_percentage;
const double max_tmp = used_after_gc / minimum_used_percentage;
size_t maximum_desired_capacity = (size_t)MIN2(max_tmp, double(max_uintx));
maximum_desired_capacity = MAX2(maximum_desired_capacity,
spec()->init_size());
if (PrintGC && Verbose) {
gclog_or_tty->print_cr(" "
" maximum_free_percentage: %6.2f"
" minimum_used_percentage: %6.2f",
maximum_free_percentage,
minimum_used_percentage);
gclog_or_tty->print_cr(" "
" _capacity_at_prologue: %6.1fK"
" minimum_desired_capacity: %6.1fK"
" maximum_desired_capacity: %6.1fK",
_capacity_at_prologue / (double) K,
minimum_desired_capacity / (double) K,
maximum_desired_capacity / (double) K);
}
assert(minimum_desired_capacity <= maximum_desired_capacity,
"sanity check");
if (capacity_after_gc > maximum_desired_capacity) {
//Calculate the memory capacity to be shrunk
shrink_bytes = capacity_after_gc - maximum_desired_capacity;
//In order to avoid one call shrinking to the initial size, the "shrink factor" is set. The first call does not shrink. The second call shrinks by 10%, the third call by 40%, and the fourth call by 100%. If there is one expansion in the middle, it is reset to 0
shrink_bytes = shrink_bytes / 100 * current_shrink_factor;
assert(shrink_bytes <= max_shrink_bytes, "invalid shrink size");
if (current_shrink_factor == 0) {
_shrink_factor = 10;
} else {
_shrink_factor = MIN2(current_shrink_factor * 4, (size_t) 100);
}
if (PrintGC && Verbose) {
gclog_or_tty->print_cr(" "
" shrinking:"
" initSize: %.1fK"
" maximum_desired_capacity: %.1fK",
spec()->init_size() / (double) K,
maximum_desired_capacity / (double) K);
gclog_or_tty->print_cr(" "
" shrink_bytes: %.1fK"
" current_shrink_factor: %d"
" new shrink factor: %d"
" _min_heap_delta_bytes: %.1fK",
shrink_bytes / (double) K,
current_shrink_factor,
_shrink_factor,
_min_heap_delta_bytes / (double) K);
}
}
}
if (capacity_after_gc > _capacity_at_prologue) {
//After GC execution, the capacity in the old age has increased, which may be due to the expansion in the process of promoting. This part of memory needs to be taken into account when reducing the capacity
size_t expansion_for_promotion = capacity_after_gc - _capacity_at_prologue;
expansion_for_promotion = MIN2(expansion_for_promotion, max_shrink_bytes);
shrink_bytes = MAX2(shrink_bytes, expansion_for_promotion);
assert(shrink_bytes <= max_shrink_bytes, "invalid shrink size");
if (PrintGC && Verbose) {
gclog_or_tty->print_cr(" "
" aggressive shrinking:"
" _capacity_at_prologue: %.1fK"
" capacity_after_gc: %.1fK"
" expansion_for_promotion: %.1fK"
" shrink_bytes: %.1fK",
capacity_after_gc / (double) K,
_capacity_at_prologue / (double) K,
expansion_for_promotion / (double) K,
shrink_bytes / (double) K);
}
}
//If the memory required to be shrunk is greater than the minimum requirement, then perform the shrunk
if (shrink_bytes >= _min_heap_delta_bytes) {
shrink(shrink_bytes);
}
}The call chain is as follows:

2, CMSBitMap
CMSBitMap is defined in hotspot\src\share\vm\gc_implementation\concurrentMarkSweep\concurrentMarkSweepGeneration.hpp. It represents a general-purpose BitMap under CMS, which can be used for the mark BitMap and mod union table of CMS. Both scenarios use one part of the methods. The implementation of this class is based on the BitMap class, and the shift attribute under the two scenarios is different . It contains the following attributes:
- Heapword * startword; / / the starting address of the corresponding memory area
- Size ﹐ bmWordSize; / / the size of the corresponding memory area, in word width
- const int _shifter; // shifts to convert HeapWord to bit position
- Virtual space? Virtual? Space; / / a continuous address space used by bitmap itself
- BitMap? bm; / / the dependent BitMap instance
- Mutex * const_lock; / / operate the lock required by bm
Focus on the implementation of the following methods.
1. Constructor / allocate
The construction method is mainly to initialize the lock and shift attributes. Other attributes are initialized in the allocate method. The implementation is as follows:
CMSBitMap::CMSBitMap(int shifter, int mutex_rank, const char* mutex_name):
_bm(),
_shifter(shifter),
_lock(mutex_rank >= 0 ? new Mutex(mutex_rank, mutex_name, true) : NULL)
{
_bmStartWord = 0;
_bmWordSize = 0;
}
bool CMSBitMap::allocate(MemRegion mr) {
_bmStartWord = mr.start();
_bmWordSize = mr.word_size();
//A continuous address segment of specified size for bitMap application
ReservedSpace brs(ReservedSpace::allocation_align_size_up(
(_bmWordSize >> (_shifter + LogBitsPerByte)) + 1));
if (!brs.is_reserved()) {
//allocation failed
warning("CMS bit map allocation failure");
return false;
}
//Initialize virtual space
if (!_virtual_space.initialize(brs, brs.size())) {
warning("CMS bit map backing store failure");
return false;
}
assert(_virtual_space.committed_size() == brs.size(),
"didn't reserve backing store for all of CMS bit map?");
//Set the mapping start address of bitMap
_bm.set_map((BitMap::bm_word_t*)_virtual_space.low());
assert(_virtual_space.committed_size() << (_shifter + LogBitsPerByte) >=
_bmWordSize, "inconsistency in bit map sizing");
//Set size
_bm.set_size(_bmWordSize >> _shifter);
// bm.clear(); // can we rely on getting zero'd memory? verify below
assert(isAllClear(),
"Expected zero'd memory from ReservedSpace constructor");
assert(_bm.size() == heapWordDiffToOffsetDiff(sizeInWords()),
"consistency check");
return true;
}The call chain is as follows:


2,mark / par_mark / mark_range / par_mark_range / mark_large_range / par_mark_large_range
Mark and par mark mark mark the corresponding bit of an address in BitMap. Mark range and par mark range mark the corresponding bit of a small range of address in BitMap. Mark large range and par mark large range mark the corresponding bit of a large range of address in BitMap. Generally, the starting address is greater than 32 bits. The implementation is as follows:
inline void CMSBitMap::mark(HeapWord* addr) {
//Verify that the lock has been acquired
assert_locked();
//Verify that addr is within the address range corresponding to CMSBitMap
assert(_bmStartWord <= addr && addr < (_bmStartWord + _bmWordSize),
"outside underlying space?");
_bm.set_bit(heapWordToOffset(addr));
}
inline bool CMSBitMap::par_mark(HeapWord* addr) {
assert_locked();
assert(_bmStartWord <= addr && addr < (_bmStartWord + _bmWordSize),
"outside underlying space?");
return _bm.par_at_put(heapWordToOffset(addr), true);
}
inline size_t CMSBitMap::heapWordToOffset(HeapWord* addr) const {
return (pointer_delta(addr, _bmStartWord)) >> _shifter;
}
inline void BitMap::set_bit(idx_t bit) {
verify_index(bit);
*word_addr(bit) |= bit_mask(bit);
}
bool BitMap::par_at_put(idx_t bit, bool value) {
//The difference between par ﹣ set ﹣ bit and set ﹣ bit is that cmpxchg ﹣ PTR is used to change the value of the specified address. A return of true indicates that the modification is successful, and a return of false indicates that other threads have completed the modification
//The underlying implementation maps bit to the corresponding address in bitMap, and then modifies the specified bit
return value ? par_set_bit(bit) : par_clear_bit(bit);
}
inline void CMSBitMap::mark_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
//The starting address calculated by heapWordToOffset is usually only one bit different
_bm.set_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::small_range);
}
inline void CMSBitMap::par_mark_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
// Range size is usually just 1 bit.
_bm.par_set_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::small_range);
}
inline void CMSBitMap::mark_large_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
//The starting address calculated by heapWordToOffset usually differs by at least 32 bits
_bm.set_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::large_range);
}
inline void CMSBitMap::par_mark_large_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
// Range size must be greater than 32 bytes.
_bm.par_set_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::large_range);
}
void CMSBitMap::region_invariant(MemRegion mr)
{
assert_locked();
// mr = mr.intersection(MemRegion(_bmStartWord, _bmWordSize));
assert(!mr.is_empty(), "unexpected empty region");
assert(covers(mr), "mr should be covered by bit map");
// convert address range into offset range
size_t start_ofs = heapWordToOffset(mr.start());
//Verify that the end address of mr is aligned
assert(mr.end() == (HeapWord*)round_to((intptr_t)mr.end(),
((intptr_t) 1 << (_shifter+LogHeapWordSize))),
"Misaligned mr.end()");
size_t end_ofs = heapWordToOffset(mr.end());
//Verification end address is greater than start address
assert(end_ofs > start_ofs, "Should mark at least one bit");
}
//Judge whether mr is in the memory area corresponding to BitMap
bool CMSBitMap::covers(MemRegion mr) const {
// assert(_bm.map() == _virtual_space.low(), "map inconsistency");
assert((size_t)_bm.size() == (_bmWordSize >> _shifter),
"size inconsistency");
return (mr.start() >= _bmStartWord) &&
(mr.end() <= endWord());
}
HeapWord* endWord() const { return _bmStartWord + _bmWordSize; }
inline void BitMap::set_range(idx_t beg, idx_t end, RangeSizeHint hint) {
if (hint == small_range && end - beg == 1) {
set_bit(beg);
} else {
if (hint == large_range) {
set_large_range(beg, end);
} else {
set_range(beg, end);
}
}
}3,isMarked / par_isMarked / isUnmarked /isAllClear
isMarked and par_isMarked are used to determine whether an address has been marked. In contrast, isMarked is not marked. isAllClear is used to determine whether all the marks have been cleared. Its implementation is as follows:
inline bool CMSBitMap::isMarked(HeapWord* addr) const {
assert_locked();
assert(_bmStartWord <= addr && addr < (_bmStartWord + _bmWordSize),
"outside underlying space?");
return _bm.at(heapWordToOffset(addr));
}
inline bool CMSBitMap::par_isMarked(HeapWord* addr) const {
//Compared with isMarked, there is no need to check the lock
assert(_bmStartWord <= addr && addr < (_bmStartWord + _bmWordSize),
"outside underlying space?");
return _bm.at(heapWordToOffset(addr));
}
inline bool CMSBitMap::isUnmarked(HeapWord* addr) const {
assert_locked();
assert(_bmStartWord <= addr && addr < (_bmStartWord + _bmWordSize),
"outside underlying space?");
return !_bm.at(heapWordToOffset(addr));
}
bool at(idx_t index) const {
verify_index(index);
//Determine whether the corresponding bit of the corresponding mapping address in BitMap is 1. If it is 1,1! = 0, return true, indicating that it has been marked
return (*word_addr(index) & bit_mask(index)) != 0;
}
//Return the corresponding mapping address in BitMap. The next 64 bit address has 8 bytes, 64 bits, similar to a slot in HashMap
bm_word_t* word_addr(idx_t bit) const { return map() + word_index(bit); }
//Move the offset further to the right by 6 bits. Under 64 bits, LogBitsPerByte is 3, and LogBitsPerWord is 6
//The accuracy lost by moving 6 bits to the right is compensated by bit mask
static idx_t word_index(idx_t bit) { return bit >> LogBitsPerWord; }
//The returned value is actually an integer multiple of 2. Only 1 bit in 64 bit is 1, and the others are 0
static bm_word_t bit_mask(idx_t bit) { return (bm_word_t)1 << bit_in_word(bit); }
//BitsPerWord is 64 under 64 bit, and the actual value here is bit to 64 redundancy
static idx_t bit_in_word(idx_t bit) { return bit & (BitsPerWord - 1); }
inline size_t CMSBitMap::heapWordToOffset(HeapWord* addr) const {
//Pointer? Delta calculates the offset of addr relative to the starting address, in bytes
return (pointer_delta(addr, _bmStartWord)) >> _shifter;
}
inline bool CMSBitMap::isAllClear() const {
assert_locked();
//Get the next marked address. If the address is greater than or equal to the end address, all the marks will be cleared
return getNextMarkedWordAddress(startWord()) >= endWord();
}
Combined with the analysis of the above marking methods, we can see that the implementation of BitMap is based on that the object address is aligned according to 8 bytes, that is, a word width. The so-called marking is to map an object address to a bit on an address in BitMap memory, and an address is similar to a slot in HashMap, and then set the value on this bit to 1.
4,par_clear / clear_range / par_clear_range / clear_large_range / par_clear_large_range /clear_all
Par? Clear is used to clear the corresponding bit of an address in BitMap, clear? Range and par? Clear? Range are used to clear the corresponding bit of a small range of address interval in BitMap, clear? Large? Range and par? Clear? Large? Range are used to clear the corresponding bit of a large range of address interval in BitMap, clear? All is used to clear all the flags in BitMap, and their The implementation is as follows:
inline void CMSBitMap::par_clear(HeapWord* addr) {
assert_locked();
assert(_bmStartWord <= addr && addr < (_bmStartWord + _bmWordSize),
"outside underlying space?");
_bm.par_at_put(heapWordToOffset(addr), false);
}
inline void CMSBitMap::clear_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
// Range size is usually just 1 bit.
_bm.clear_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::small_range);
}
inline void CMSBitMap::par_clear_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
// Range size is usually just 1 bit.
_bm.par_clear_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::small_range);
}
inline void CMSBitMap::clear_large_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
// Range size must be greater than 32 bytes.
_bm.clear_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::large_range);
}
inline void CMSBitMap::par_clear_large_range(MemRegion mr) {
NOT_PRODUCT(region_invariant(mr));
// Range size must be greater than 32 bytes.
_bm.par_clear_range(heapWordToOffset(mr.start()), heapWordToOffset(mr.end()),
BitMap::large_range);
}
inline void BitMap::clear_range(idx_t beg, idx_t end, RangeSizeHint hint) {
if (hint == small_range && end - beg == 1) {
clear_bit(beg);
} else {
if (hint == large_range) {
clear_large_range(beg, end);
} else {
clear_range(beg, end);
}
}
}
inline void CMSBitMap::clear_all() {
assert_locked();
// CMS bitmaps are usually cover large memory regions
_bm.clear_large();
return;
}5,getNextMarkedWordAddress / getNextUnmarkedWordAddress / getAndClearMarkedRegion
All three methods have two overloaded versions, specifying the start and end addresses and only the start and end addresses. The end address defaults to the end address of BitMap. getNextMarkedWordAddress returns the address with the first bit equal to 1 in the specified address range, getNextUnmarkedWordAddress returns the address with the first bit equal to 0 in the specified address range, and getAndClearMarkedRegion is used to clear the flag of the first area marked continuously in the specified address range, which is as follows:
inline HeapWord* CMSBitMap::getNextMarkedWordAddress(HeapWord* addr) const {
return getNextMarkedWordAddress(addr, endWord());
}
inline HeapWord* CMSBitMap::getNextMarkedWordAddress(
HeapWord* start_addr, HeapWord* end_addr) const {
assert_locked();
//Find the next address equal to 1 in the specified address range
size_t nextOffset = _bm.get_next_one_offset(
heapWordToOffset(start_addr),
heapWordToOffset(end_addr));
//Convert address in BitMap to actual address
HeapWord* nextAddr = offsetToHeapWord(nextOffset);
assert(nextAddr >= start_addr &&
nextAddr <= end_addr, "get_next_one postcondition");
assert((nextAddr == end_addr) ||
isMarked(nextAddr), "get_next_one postcondition");
return nextAddr;
}
inline HeapWord* CMSBitMap::offsetToHeapWord(size_t offset) const {
return _bmStartWord + (offset << _shifter);
}
inline HeapWord* CMSBitMap::getNextUnmarkedWordAddress(HeapWord* addr) const {
return getNextUnmarkedWordAddress(addr, endWord());
}
inline HeapWord* CMSBitMap::getNextUnmarkedWordAddress(
HeapWord* start_addr, HeapWord* end_addr) const {
assert_locked();
//Find the next address equal to 0 in the specified address range
size_t nextOffset = _bm.get_next_zero_offset(
heapWordToOffset(start_addr),
heapWordToOffset(end_addr));
//Convert address in BitMap to actual address
HeapWord* nextAddr = offsetToHeapWord(nextOffset);
assert(nextAddr >= start_addr &&
nextAddr <= end_addr, "get_next_zero postcondition");
assert((nextAddr == end_addr) ||
isUnmarked(nextAddr), "get_next_zero postcondition");
return nextAddr;
}
inline MemRegion CMSBitMap::getAndClearMarkedRegion(HeapWord* addr) {
return getAndClearMarkedRegion(addr, endWord());
}
inline MemRegion CMSBitMap::getAndClearMarkedRegion(HeapWord* start_addr,
HeapWord* end_addr) {
HeapWord *start, *end;
assert_locked();
//Find the first marked address after start_addr
start = getNextMarkedWordAddress (start_addr, end_addr);
//Find the first unmarked address after start. The area between start and end is a continuous marked area
end = getNextUnmarkedWordAddress(start, end_addr);
assert(start <= end, "Consistency check");
MemRegion mr(start, end);
if (!mr.is_empty()) {
//Remove the flag between start and end
clear_range(mr);
}
return mr;
}6,iterate / dirty_range_iterate_clear
There are two overloaded versions of these two methods. One is in the range of specified starting and ending address, and the other is in the range of address corresponding to the whole BitMap, which is used to traverse the marked bits in the range of specified address. These bits will be converted into real address, and then the real address will be processed as required. The implementation is as follows:
inline void CMSBitMap::iterate(BitMapClosure* cl, HeapWord* left,
HeapWord* right) {
assert_locked();
left = MAX2(_bmStartWord, left);
right = MIN2(_bmStartWord + _bmWordSize, right);
if (right > left) {
//The traversal logic is encapsulated in bm, and bitmapclose will automatically convert the mapping address of BitMap to the real address
_bm.iterate(cl, heapWordToOffset(left), heapWordToOffset(right));
}
}
void iterate(BitMapClosure* cl) {
_bm.iterate(cl);
}
void CMSBitMap::dirty_range_iterate_clear(MemRegion mr, MemRegionClosure* cl) {
HeapWord *next_addr, *end_addr, *last_addr;
assert_locked();
assert(covers(mr), "out-of-range error");
for (next_addr = mr.start(), end_addr = mr.end();
next_addr < end_addr; next_addr = last_addr) {
//Find the next consecutive marked area in BitMap
MemRegion dirty_region = getAndClearMarkedRegion(next_addr, end_addr);
last_addr = dirty_region.end();
if (!dirty_region.is_empty()) {
//Execution traversal
cl->do_MemRegion(dirty_region);
} else {
assert(last_addr == end_addr, "program logic");
return;
}
}
}Three. CMSMarkStack
CMSMarkStack is a stack to store oop based on scalable array. Its definition is also in concurrentmarksweetgeneration.hpp, and its properties are as follows:
- Virtual space? Virtual? Space; / / corresponding memory area
- oop * _base; / / base address of oop array
- Size ﹐ t ﹐ index; / / number of elements in the Stack
- Size ﹐ t ﹐ capacity; / / maximum capacity allowed
- Mutex? Par? Lock; / / concurrently operate the lock of base
- Size? Hit? Limit; / / record the times that the capacity of MarkStack reaches the maximum value
- Size? T? Failed? Double; / / record the number of failed expansion of MarkStack
Focus on the implementation of the following methods.
1. Construction method and allocate
Both of them are used to initialize the CMSMarkStack, as follows:
CMSMarkStack():
_par_lock(Mutex::event, "CMSMarkStack._par_lock", true),
_hit_limit(0),
_failed_double(0) {}
bool CMSMarkStack::allocate(size_t size) {
//Memory is applied according to the size of oop. oop is actually the alias of oopDesc *
ReservedSpace rs(ReservedSpace::allocation_align_size_up(
size * sizeof(oop)));
if (!rs.is_reserved()) {
//Failed to request memory
warning("CMSMarkStack allocation failure");
return false;
}
//Initialize virtual space
if (!_virtual_space.initialize(rs, rs.size())) {
warning("CMSMarkStack backing store failure");
return false;
}
assert(_virtual_space.committed_size() == rs.size(),
"didn't reserve backing store for all of CMS stack?");
//Use the base address of the requested memory as the starting address of the base array
_base = (oop*)(_virtual_space.low());
_index = 0;
_capacity = size;
NOT_PRODUCT(_max_depth = 0);
return true;
}
The call chain is as follows:
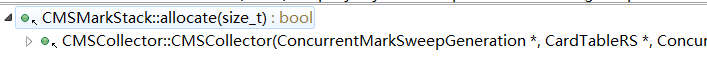
2,pop / push / par_pop / par_push
Pop is to pop up the top of the stack, and push is to push the top of the stack. par version is an additional step to acquire the lock. Its implementation is as follows:
oop pop() {
if (!isEmpty()) {
//The index is reduced by 1 first, and the oop corresponding to the index after one is returned
return _base[--_index] ;
}
return NULL;
}
bool isEmpty() const { return _index == 0; }
bool push(oop ptr) {
if (isFull()) {
return false;
} else {
//Set the element at index to ptr, and then add 1 to index
_base[_index++] = ptr;
NOT_PRODUCT(_max_depth = MAX2(_max_depth, _index));
return true;
}
}
bool isFull() const {
assert(_index <= _capacity, "buffer overflow");
return _index == _capacity;
}
oop par_pop() {
MutexLockerEx x(&_par_lock, Mutex::_no_safepoint_check_flag);
return pop();
}
bool par_push(oop ptr) {
MutexLockerEx x(&_par_lock, Mutex::_no_safepoint_check_flag);
return push(ptr);
}
3,expand
The expand method is used for capacity expansion, which is different from the ArrayList based on the same array implementation. Here, only two times of the original memory area corresponding to MarkStack is reapplied, and the original memory area is released directly. Its implementation is as follows:
void CMSMarkStack::expand() {
//MarkStackSizeMax indicates the maximum size of MarkStack, which is 512M by default under 64 bit
assert(_capacity <= MarkStackSizeMax, "stack bigger than permitted");
if (_capacity == MarkStackSizeMax) {
//If the maximum capacity is reached
if (_hit_limit++ == 0 && !CMSConcurrentMTEnabled && PrintGCDetails) {
gclog_or_tty->print_cr(" (benign) Hit CMSMarkStack max size limit");
}
return;
}
//Doubling capacity
size_t new_capacity = MIN2(_capacity*2, MarkStackSizeMax);
//Application memory
ReservedSpace rs(ReservedSpace::allocation_align_size_up(
new_capacity * sizeof(oop)));
if (rs.is_reserved()) {
//Free up the original memory
_virtual_space.release();
//Retry initialization
if (!_virtual_space.initialize(rs, rs.size())) {
fatal("Not enough swap for expanded marking stack");
}
//Reset attribute
_base = (oop*)(_virtual_space.low());
_index = 0;
_capacity = new_capacity;
} else if (_failed_double++ == 0 && !CMSConcurrentMTEnabled && PrintGCDetails) {
//Failed to request memory
gclog_or_tty->print(" (benign) Failed to expand marking stack from " SIZE_FORMAT "K to "
SIZE_FORMAT "K",
_capacity / K, new_capacity / K);
}
}
The call chain is as follows:

4, ChunkArray
ChunkArray refers to an array that holds Chunk addresses. Its definition is also in concurrentmarksweetgeneration.hpp, which contains the following properties:
- Size ﹐ t ﹐ index; / / number of Chunk addresses contained in chunkarray
- Size t capacity; / / maximum capacity of chunkarray
- Size ﹐ t ﹐ overflow; / / number of times ChunkArray capacity has been reached
- HeapWord** _array; / / save the array base address of Chunk address
Focus on the implementation of the following methods:
ChunkArray(HeapWord** a, size_t c):
_index(0), _capacity(c), _overflows(0), _array(a) {}
HeapWord* nth(size_t n) {
//Return address with index n
assert(n < end(), "Out of bounds access");
return _array[n];
}
void record_sample(HeapWord* p, size_t sz) {
//Save Chunk address p to the array
if (_index < _capacity) {
_array[_index++] = p;
} else {
++_overflows;
assert(_index == _capacity,
err_msg("_index (" SIZE_FORMAT ") > _capacity (" SIZE_FORMAT
"): out of bounds at overflow#" SIZE_FORMAT,
_index, _capacity, _overflows));
}
}

