Article directory
1, Derive built-in immutable types and modify their instantiation behavior
Introduce:
We want to customize a new type of tuple. For the incoming iteratable object, we only keep the elements with int type and value greater than 0. For example:
IntTuple([2,-2,'jr',['x','y'],4]) => (2,4)
How to inherit the built-in tuple to implement IntTuple?
Custom IntTuple:
class IntTuple(tuple): def __init__(self,iterable): for i in iterable: if isinstance(i,int) and i > 0: super().__init__(i) int_t = IntTuple([2,-2,'cl',['x','y'],4]) print(int_t)
Printing
Traceback (most recent call last): File "xxx/demo.py", line 7, in <module> int_t = IntTuple([2,-2,'cl',['x','y'],4]) File "xxx/demo.py", line 5, in __init__ super().__init__(i) TypeError: object.__init__() takes exactly one argument (the instance to initialize)
Question: who created the self object
class A: def __new__(cls, *args, **kwargs): print('A.__new__',cls,args) return object.__new__(cls) def __init__(self,*args): print('A.__init__') a = A(1,2)
Printing
A.__new__ <class '__main__.A'> (1, 2) A.__init__
It's easy to know that the real object is created by the new method, and the self object is created by the new method.
The above example inherits the object by default, or other classes. The \\\\\\\\\\.
class B: pass class A(B): def __new__(cls, *args, **kwargs): print('A.__new__',cls,args) return super().__new__(cls) def __init__(self,*args): print('A.__init__') a = A(1,2)
The results are the same as the former, but it is better to use the first way.
The instantiation of A can be converted into two other lines of equivalent code:
class A: def __new__(cls, *args, **kwargs): print('A.__new__',cls,args) return object.__new__(cls) def __init__(self,*args): print('A.__init__') # a = A(1,2) is equivalent to the following two lines of code a = A.__new__(A,1,2) A.__init__(a,1,2)
Create list conversion equivalent code:
l = list.__new__(list,'abc') print(l) list.__init__(l,'abc') print(l)
Printing
[] ['a', 'b', 'c']
But tuples are different:
t = tuple.__new__(tuple,'abc') print(t) tuple.__init__(t,'abc') print(t)
Printing
('a', 'b', 'c') ('a', 'b', 'c')
The tuple was instantiated and generated when the first step called the new method.
This also explains that when you first customize IntTuple, an error will be reported
When __init__(self,iterable) was called __new__, the tuple was already created and the tuple could not be modified, so it would fail to achieve the desired result.
Code modification:
class IntTuple(tuple): def __new__(cls,iterable): #generator r = (i for i in iterable if isinstance(i,int) and i > 0) return super().__new__(cls,r) int_t = IntTuple([2,-2,'cl',['x','y'],4]) print(int_t)
Printing
(2, 4)
The expected function is realized.
2, Create a large number of instances to save memory
Questions:
In the game, player class is defined. Every online player has an instance of player in the server. When there are many online players, there will be a large number of instances (million level). How to reduce the memory cost of these large instances?
Solution:
Define the "slots" property of the class and declare which properties the instance has (turn off dynamic binding).
class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level class Player2(object): __slots__ = ('uid','name','status','level') def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level p1 = Player1('0001','Tom') p2 = Player2('0002','Tom') print(len(dir(p1))) print(len(dir(p2))) print(dir(p1)) print(dir(p2)) print(set(dir(p1)) - set(dir(p2)))
Printing
30 29 ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'level', 'name', 'status', 'uid'] ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', 'level', 'name', 'status', 'uid'] {'__dict__', '__weakref__'}
Obviously, compared with all the properties of p1 and p2, p2 has fewer properties than p1. Among them, "weakref" is a weak reference, and "dict" is a dynamic binding property. This is the main memory waste.
class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level p1 = Player1('0001','Tom') p1.x = 6 p1.__dict__['y'] = 7 #P1. Dict itself is a dictionary print(p1.__dict__)
Printing
{'uid': '0001', 'name': 'Tom', 'status': 0, 'level': 1, 'x': 6, 'y': 7}
It can be seen that the attributes x and y are added, which means dynamic binding, that is, you can add attributes to objects at will.
Python can add attributes through this dynamic binding, but this way is extremely memory wasting. After adding "slots", dynamic binding can be eliminated and this problem can be solved.
class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level class Player2(object): __slots__ = ('uid','name','status','level') def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level p1 = Player1('0001','Tom') p2 = Player2('0002','Tom') p1.x = 6 p2.y = 7 print(p1.__dict__) print(p2.__dict__)
Printing
Traceback (most recent call last): File "xxx/demo.py", line 73, in <module> p2.y = 7 AttributeError: 'Player2' object has no attribute 'y'
That is, it is not allowed to add any properties to the instance of Player2.
Import sys module to view specific memory:
import sys class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level p1 = Player1('0001','Tom') p1.x = 6 print(p1.__dict__) print(sys.getsizeof(p1.__dict__)) print(sys.getsizeof(p1.uid)) print(sys.getsizeof(p1.name)) print(sys.getsizeof(p1.status)) print(sys.getsizeof(p1.level)) print(sys.getsizeof(p1.x))
Printing
112 53 52 24 28 28
Dynamic modification of instances is not allowed
class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level class Player2(object): __slots__ = ('uid','name','status','level') def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level p1 = Player1('0001','Tom') p2 = Player2('0002','Tom') p1.x = 6 p1.__dict__['y'] = 7 p2.__slots__ = ('uid','name','status','level','y') print(p1.__dict__) print(p2.__dict__)
Printing
Traceback (most recent call last): File "xxx/demo.py", line 74, in <module> p2.__slots__ = ('uid','name','status','level','y') AttributeError: 'Player2' object attribute '__slots__' is read-only
Error is reported, and "slots" are read-only.
Import the tracemalloc library to track the use of memory:
import tracemalloc class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level class Player2(object): __slots__ = ('uid','name','status','level') def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level tracemalloc.start() p1 = [Player1('0001','Tom',2,3) for _ in range(100000)] p2 = [Player1('0001','Tom',2,3) for _ in range(100000)] end = tracemalloc.take_snapshot() top = end.statistics('lineno') for stat in top[:10]: print(stat)
Printing
xxx/demo.py:59: size=21.4 MiB, count=399992, average=56 B xxx/demo.py:74: size=6274 KiB, count=100003, average=64 B xxx/demo.py:73: size=6274 KiB, count=100001, average=64 B xxx/demo.py:75: size=432 B, count=1, average=432 B xxx\Python\Python37\lib\tracemalloc.py:532: size=64 B, count=1, average=64 B
When the parameter of end.statistics() is' lineno ', line by line analysis is performed on the code occupying memory:
Lines 59 and 73 analyze p1, accounting for 21.4 MiB (attribute memory) + 6274 KiB=27.5MiB;
Line 74 is for p2 analysis: 6274 KiB=6.1MiB.
When the parameter of end.statistics() is' filename ', the whole file memory is analyzed:
At this time, we need to analyze p1 and p2 respectively:
For p1:
import tracemalloc class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level class Player2(object): __slots__ = ('uid','name','status','level') def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level tracemalloc.start() p1 = [Player1('0001','Tom',2,3) for _ in range(100000)] # p2 = [Player1('0001','Tom',2,3) for _ in range(100000)] end = tracemalloc.take_snapshot() # top = end.statistics('lineno') top = end.statistics('filename') for stat in top[:10]: print(stat)
Printing
xxx/demo.py:0: size=16.8 MiB, count=299994, average=59 B xxx\Python\Python37\lib\tracemalloc.py:0: size=64 B, count=1, average=64 B
For p2:
import tracemalloc class Player1(object): def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level class Player2(object): __slots__ = ('uid','name','status','level') def __init__(self,uid,name,status=0,level=1): self.uid = uid self.name = name self.status = status self.level = level tracemalloc.start() # p1 = [Player1('0001','Tom',2,3) for _ in range(100000)] p2 = [Player1('0001','Tom',2,3) for _ in range(100000)] end = tracemalloc.take_snapshot() # top = end.statistics('lineno') top = end.statistics('filename') for stat in top[:10]: print(stat)
Printing
xxx/demo.py:0: size=16.8 MiB, count=299994, average=59 B xxx\Python\Python37\lib\tracemalloc.py:0: size=64 B, count=1, average=64 B
3, with statement in Python
Document processing:
try: f = open('test.txt','w') raise KeyError except KeyError as e: print('Key Error') f.close() except IndexError as e: print('Index Error') f.close() except Exception as e: print('Error') f.close() finally: print('end') f.close()
Printing
Key Error end
There are many except s in the code that are redundant and repetitive, so the with statement is introduced:
with open('test.txt','r') as f: f.read()
Class on context handling:
class Sample(object): def demo(self): print('This is a demo') with Sample() as sample: sample.demo()
Printing
Traceback (most recent call last): File "xxx/demo.py", line 105, in <module> with Sample() as sample: AttributeError: __enter__
Error reporting AttributeError (no \\\\\\\\\.
Improve - add "enter" method:
class Sample(object): def __enter__(self): print('start') return self def demo(self): print('This is a demo') with Sample() as sample: sample.demo()
Printing
Traceback (most recent call last): File "xxx/demo.py", line 109, in <module> with Sample() as sample: AttributeError: __exit__
Error reported AttributeError, no exit method.
Improve - add "exit" method:
class Sample(object): #Access to resources def __enter__(self): print('start') return self def demo(self): print('This is a demo') #Release resources def __exit__(self, exc_type, exc_val, exc_tb): print('end') with Sample() as sample: sample.demo()
Printing
start
This is a demo
end
It is running normally at this time.
It is easy to know that in order to use context processor to process a class, you need to add methods such as "enter" and "exit".
The three methods in the class can be compared with open file, process file and close file in file processing, instead of exception handling (try except...) Sentence.
__Parameter exploration of exit:
Normally:
class Sample(object): def __enter__(self): print('start') return self def demo(self): print('This is a demo') def __exit__(self, exc_type, exc_val, exc_tb): print('exc_type:',exc_type) print('exc_val:',exc_val) print('exc_tb:',exc_tb) print('end') with Sample() as sample: sample.demo()
Printing
start This is a demo exc_type: None exc_val: None exc_tb: None end
In case of abnormality:
class Sample(object): def __enter__(self): print('start') return self def demo(self): print('This is a demo') def __exit__(self, exc_type, exc_val, exc_tb): #Exception class print('exc_type:',exc_type) #Outliers print('exc_val:',exc_val) #Tracking information print('exc_tb:',exc_tb) print('end') with Sample() as sample: sample.sample()
Printing
Traceback (most recent call last): start File "xxx/demo.py", line 119, in <module> exc_type: <class 'AttributeError'> sample.sample() exc_val: 'Sample' object has no attribute 'sample' AttributeError: 'Sample' object has no attribute 'sample' exc_tb: <traceback object at 0x00000210286C8388> end
That is, the three parameters "exit" carry information about exception handling.
contextlib library simplified context manager:
import contextlib @contextlib.contextmanager def file_open(filename): #Equivalent to "enter"__ print('file open') yield {} # Equivalent to "exit"__ print('file close') with file_open('test.txt') as f: print('file operation')
Printing
file open file operation file close
This is the context manager protocol;
yield must be used in the file open function, not return, otherwise an error will be reported.
4, Create manageable object properties
In object-oriented programming, we regard methods as interfaces of objects.
Direct access to the properties of an object may not be secure or flexible in design, but the use of call methods is not as concise in form as access to properties.
Call method:
A.get_key() #Accessor A.set_key() #Setter
This way is more troublesome.
Property access:
A.key A.key = 'xxx'
This is not safe.
To find the way to access the formal property and call methods in Shenzhen:
class A: def __init__(self,age): self.age = age def get_age(self): return self.age def set_age(self,age): if not isinstance(age,int): raise TypeError('Type Error') self.age = age a =A(18) a.set_age('20')
Printing
Traceback (most recent call last): File "xxx/demo.py", line 147, in <module> a.set_age('20') File "xxx/demo.py", line 143, in set_age raise TypeError('Type Error') TypeError: Type Error
An exception will be thrown when the age is not set to integer, but it is more troublesome.
There are two ways to call property:
(1)property(fget=None, fset=None, fdel=None, doc=None):
class C(object): def getx(self): return self._x def setx(self, value): self._x = value def delx(self): del self._x x = property(getx, setx, delx, "I'm the 'x' property.")
For example:
class A: def __init__(self,age): self.age = age def get_age(self): return self.age def set_age(self,age): if not isinstance(age,int): raise TypeError('Type Error') self.age = age R = property(get_age,set_age) a =A(18) #set a.R = 20 #get print(a.R)
Printing
20
(2) Add decorator
class C(object): @property def x(self): "I am the 'x' property." return self._x @x.setter def x(self, value): self._x = value @x.deleter def x(self): del self._x
For example:
class A: def __init__(self,age): self.age = age def get_age(self): return self.age def set_age(self,age): if not isinstance(age,int): raise TypeError('Type Error') self.age = age R = property(get_age,set_age) @property def S(self): return self.age @S.setter def S(self,age): if not isinstance(age,int): raise TypeError('Type Error') self.age = age a =A(18) #set a.S = 20 #get print(a.S)
Printing
20
5, Class supports comparison operation
Sometimes we want to compare instances of custom classes by using the symbols >, <, < =, > =, = =,! = for example, when comparing instances of two rectangles, we compare their areas.
a = 1 b = 2 print(a > b) print(a < b) print(a.__ge__(b)) print(a.__lt__(b)) c = 'abc' d = 'abd' print(c > d) print(c < d) print(c.__ge__(d)) print(c.__lt__(d)) e = {1,2,3} f = {1,2} g = {1,4} #Collection is compared to include, including is True, otherwise False print(e > f) print(e > g)
Printing
False True False True False True False True True False
Compare in class:
class Rect(object): def __init__(self,w,b): self.w = w self.b = b def area(self): return self.w * self.b def __str__(self): return '(%s,%s)' % (self.w,self.b) def __lt__(self, other): return self.area() < other.area() def __gt__(self, other): return self.area() > other.area() rect1 = Rect(1,2) rect2 = Rect(3,4) print(rect1 < rect2)
Printing
True
__The lt and gt methods can omit one of them and realize size comparison, such as:
class Rect(object): def __init__(self,w,b): self.w = w self.b = b def area(self): return self.w * self.b def __str__(self): return '(%s,%s)' % (self.w,self.b) def __lt__(self, other): return self.area() < other.area() rect1 = Rect(1,2) rect2 = Rect(3,4) print(rect1 > rect2)
Printing
False
Principle explanation:
In the class Rect, only the less than comparison is implemented, and Python implements the automatic conversion of Rect2 < Rect1. In fact, the inequality is not true, so it is False, so it returns False.
However, to achieve equal or other comparisons, you need to implement the corresponding methods in the class, which is very troublesome.
To import a library to decorate a class:
from functools import total_ordering @total_ordering class Rect(object): def __init__(self,w,b): self.w = w self.b = b def area(self): return self.w * self.b def __str__(self): return '(%s,%s)' % (self.w,self.b) def __lt__(self, other): return self.area() < other.area() def __eq__(self, other): return self.area() == other.area() rect1 = Rect(1,2) rect2 = Rect(3,4) print(rect1 > rect2) print(rect1 < rect2) print(rect1 >= rect2) print(rect1 <= rect2) print(rect1 == rect2) print(rect1 != rect2)
Printing
False True False True False True
That is to say, you only need to implement two methods in the class to realize all types of comparison.
Comparison between two classes:
from functools import total_ordering import math @total_ordering class Rect(object): def __init__(self,w,b): self.w = w self.b = b def area(self): return self.w * self.b def __str__(self): return '(%s,%s)' % (self.w,self.b) def __lt__(self, other): return self.area() < other.area() def __eq__(self, other): return self.area() == other.area() class Cricle(object): def __init__(self,r): self.r = r def area(self): return math.pi * pow(self.r,2) def __lt__(self, other): return self.area() < other.area() def __eq__(self, other): return self.area() == other.area() rect = Rect(1,2) c = Cricle(1) print(rect > c) print(rect < c) print(rect == c)
Printing
False True False
Optimize comparison: simplify code with abstract base classes
from functools import total_ordering import math import abc @total_ordering class Shape(metaclass=abc.ABCMeta): @abc.abstractmethod def area(self): pass def __lt__(self, other): return self.area() < other.area() def __eq__(self, other): return self.area() == other.area() class Rect(Shape): def __init__(self,w,b): self.w = w self.b = b def area(self): return self.w * self.b class Cricle(Shape): def __init__(self,r): self.r = r def area(self): return math.pi * pow(self.r,2) rect = Rect(1,2) c = Cricle(1) print(rect > c) print(rect < c) print(rect == c)
The execution result is the same as before.
6, Management memory in ring data structure
Garbage collection mechanism:
class A(object): #Executed when released def __del__(self): print('del') a = A() print('after a = A()') a2 = a print('after a2 = a') a2 = None print('after a2 = None') a = None print('after a = None')
Printing
after a = A() after a2 = a after a2 = None del after a = None
It is easy to know that when a is changed, the instance of a is released and recycled;
The garbage collection mechanism is for reference counting.
Two way circular list:
class Node: def __init__(self, data): self.data = data self.left = None self.right = None def add_right(self, node): self.right = node node.left = self def __str__(self): return 'Node:<%s>' % self.data def __del__(self): print('in __del__: delete %s' % self) def create_linklist(n): head = current = Node(1) for i in range(2, n + 1): node = Node(i) current.add_right(node) current = node return head #Create nodes 1000 times head = create_linklist(1000) #Release node head = None import time for _ in range(1000): time.sleep(1) print('run...') input('wait...')
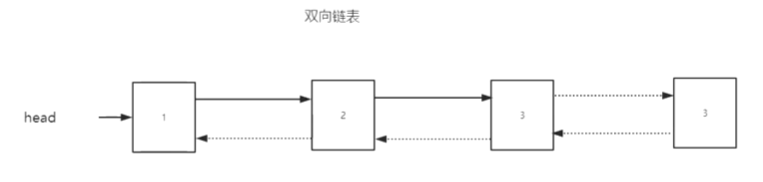
When you execute a Python file on the command line and force the end, it prints
run... run... run... run... run... run... run... Traceback (most recent call last): File "demo.py", line 267, in <module> time.sleep(1) KeyboardInterrupt in __del__: delete Node:<999> in __del__: delete Node:<1000> in __del__: delete Node:<1> in __del__: delete Node:<296> in __del__: delete Node:<297> in __del__: delete Node:<2> ... in __del__: delete Node:<993> in __del__: delete Node:<994> in __del__: delete Node:<995> in __del__: delete Node:<996> in __del__: delete Node:<997> in __del__: delete Node:<998>
That is, del is called on recycle.
Weak references:
import weakref class A(object): def __del__(self): print('del') a = A() print('after a = A()') a2 = weakref.ref(a) print('after a2 = weakref.ref(a)') a3 = a2() print('after a3 = a2()') del a3 print('after del a3')
Printing
after a = A() after a2 = weakref.ref(a) after a3 = a2() after del a3 del
Weak references call del after all execution is completed;
Weak references do not take up reference count, and garbage collection in Python is based on reference count.
a2 is weak reference and a3 is real reference.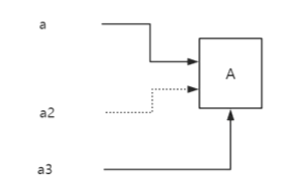
The above two-way list can be modified into a weak reference by a small part of the code:
import weakref class Node: def __init__(self, data): self.data = data self.left = None self.right = None def add_right(self, node): self.right = node # node.left = self node.left = weakref.ref(self) def __str__(self): return 'Node:<%s>' % self.data def __del__(self): print('in __del__: delete %s' % self) def create_linklist(n): head = current = Node(1) for i in range(2, n + 1): node = Node(i) current.add_right(node) current = node return head #Create nodes 1000 times head = create_linklist(1000) #Release node head = None import time for _ in range(1000): time.sleep(1) print('run...') input('wait...')
Printing
in __del__: delete Node:<1> in __del__: delete Node:<2> in __del__: delete Node:<3> in __del__: delete Node:<4> in __del__: delete Node:<5> in __del__: delete Node:<6> ... in __del__: delete Node:<995> in __del__: delete Node:<996> in __del__: delete Node:<997> in __del__: delete Node:<998> in __del__: delete Node:<999> in __del__: delete Node:<1000> run... run... run... run... run... run... ...
At this time, the result is different from the previous run. First, call del release object and then run the following code.

