This is the author's series of online security self-study course, mainly about the online notes of online security tools and practical operations. I'd like to share it with you and make progress together. The previous article shared the first step of Web penetration, involving website information, domain name information, port information, sensitive information and fingerprint information collection. This article will share the application of machine learning in the field of security and reproduce a malicious request recognition based on machine learning (logical regression).
As a small white of network security, the author shares some basic self-study courses for you, I hope you like them. At the same time, I hope you can work with me to make further progress. In the future, I will also learn more about network security and system security and share relevant experiments. In a word, I hope this series of articles will be helpful to Bo you. It's not easy to write. Please fly by. Don't spray if you don't like it. Thank you!
Download address: https://github.com/eastmountyxz/NetworkSecuritySelf-study
Baidu online: https://pan.baidu.com/s/1dsunH8EmOB_tlHYXXguOeA Extraction code: izeb
Article directory
- 1, Machine learning in security field
- 1. Identification and authentication
- 2. social engineering
- 3. Network security
- 4.Web security
- 5. Security vulnerability and malicious code
- 6. Intrusion detection and Prevention
- 2, Malicious code detection based on machine learning
- 1. Traditional malicious code detection
- 2. Malicious code detection based on machine learning
- 3. Characteristics and difficulties of machine learning in the field of safety
- 3, Logical regression to identify website malicious requests
- 1. data set
- 2. Combining n-grams and TF-IDF to construct characteristic matrix
- 3. Training model
- 4. Check whether the new dataset is a malicious request or a normal request
- 5. Complete code
- Four. Conclusion
Previous learning:
[self study of network security] 1. A look at the introduction notes
[self study of network security] II. Entry notes of password retention function penetration analysis and login encryption in Chrome browser
[self study of network security] III. Burp Suite tool installation configuration, Proxy basic usage and example of mob
[self study of network security] 4. Experimental bar: WEB penetration and steganography decryption of CTF practice
[self study of network security] v. IDA Pro disassembly tool preliminary knowledge and reverse engineering decryption practice
[self study of network security] 6. Basic usage of OllyDbg dynamic analysis tool and its reverse cracking
[web security self study] seven. Fast video download Chrome browser Network analysis and Python crawler discussion
8. Nmap, ThreatScan and DirBuster tools for Web vulnerability and port scanning
[network security self study] IX. basic concepts of social engineering, IP acquisition, IP physical location, and file attributes
[self study of network security] 10. Malicious code of host based on machine learning algorithm
[self study of network security] Xi. Introduction to VMware+Kali installation of virtual machine and basic usage of Sqlmap
[self study of network security] 12. Introduction to Wireshark installation and capturing website user name and password (1)
[self study of network security] XIII. Wireshark packet capturing principle (ARP hijacking, MAC flooding), data flow tracking and image capturing (2)
[self study of network security] 14. Basic knowledge, regular expression, Web programming and socket communication of Python attack and defense (1)
[self study of network security] 15. Multithreading, C-scan and database programming in Python attack and defense (2)
[self study of network security] 16. Weak password of Python attack and defense, generation of custom dictionary and protection of website database
[self study of network security] 17. Building Web directory scanner and ip proxy pool for Python attack and defense (4)
[self study of network security] 18. XSS cross site script attack principle and code attack and defense demonstration (1)
[self study on network security] 19. Basic introduction and common usage of Powershell (1)
[self study of network security] 20. Basic introduction and common usage of Powershell (2)
[self study of network security] 21. Summary and ShowTime of security attack and Defense Technology in GeekPwn geek contest
[self study of network security] 22. Collection of Web penetration website information, domain name information, port information, sensitive information and fingerprint information
Previous appreciation:
[penetration & attack and Defense] 1. Learning network attack and defense from database principles and preventing SQL injection
[penetration & attack and Defense] II. SQL MAP tool unscrambles database and basic usage from zero
[penetration & attack and Defense] 3. Database differential backup and Caidao
[penetration & attack and Defense] IV. detailed explanation of MySQL database attack and defense and Fiddler artifact analysis data package
This article refers to the following literature, and it is highly recommended that you read these articles and videos of Daniel:
Application and analysis of machine learning in security attack and defense scenarios
Security defense thinking caused by invasion of a website
Use machine learning to play malicious URL detection - Tencent cloud FreeBuf official
https://github.com/exp-db/AI-Driven-WAF
https://github.com/foospidy/payloads
http://www.secrepo.com/
https://github.com/eastmountyxz
Zhang Sisi, Zuo Xin, Liu Jianwei. Confrontation sample problem in deep learning [J]. Journal of computer science, 2019 (8)
http://fsecurify.com/fwaf-machine-learning-driven-web-application-firewall/
Black production uses "future weapons" to crack the verification code, and the small workers are crying - FreeBuf
[reprint] popular article on machine learning: "machine learning for one text reading, big data / natural language processing / algorithm all available"
Https://www.bilibilibili.com/video/av60018118 (white hat hacker tutorial of station B)
Https://www.bilibilibili.com/video/av63038037 (HACK learning in station B)
Statement: I firmly oppose the use of teaching methods for criminal behavior, all criminal behavior will be severely punished, green network needs our common maintenance, more recommend you understand the principles behind them, better protection.
1, Machine learning in security field
Machine learning method is a method that the computer uses the existing data (experience) to train a certain model and use this model to predict the future. Machine learning integrates many fields of mathematics, including statistics, probability theory, linear algebra and mathematical calculation. The "training" and "prediction" processes in machine learning can correspond to human "induction" and "speculation" processes, as shown in the figure below.
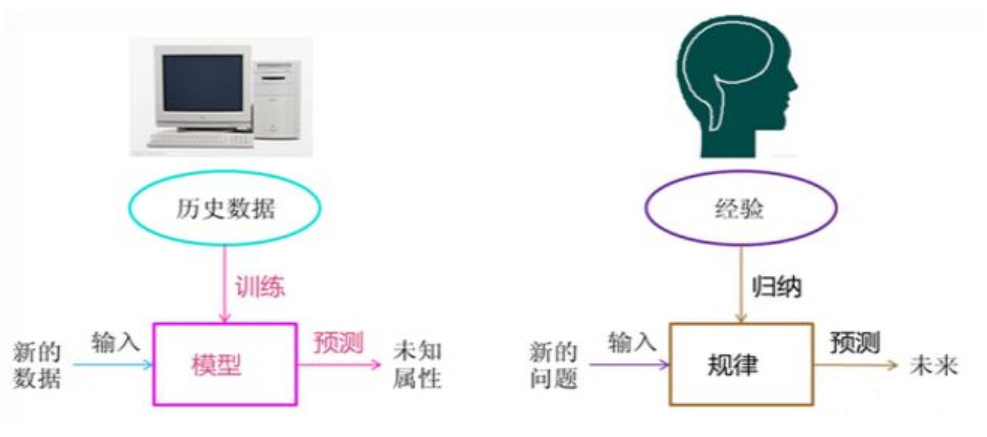
Machine learning is closely related to pattern recognition, statistical learning, data mining, computer vision, speech recognition, natural language processing and other fields. In terms of scope, machine learning is similar to pattern recognition, statistical learning and data mining. At the same time, the combination of machine learning and other processing technologies in other fields forms interdisciplinary subjects such as computer vision, speech recognition and natural language processing. Generally speaking, data mining can be equated with machine learning. The machine learning application we usually call should be universal, not only limited to structured data, but also applications such as image, audio, video, etc.
- Pattern recognition ≈ machine learning + industrial application
- Data mining ≈ machine learning + Database
- Statistical learning ≈ machine learning + mathematical statistics
- Computer vision ≈ machine learning + image processing + video processing
- Speech recognition ≈ machine learning + speech processing
- Natural language processing ≈ machine learning + text processing

Machine learning can deeply mine the value of big data, which is widely used in various fields. At the same time, it has related applications in the field of network security. In order to explain the practical application and solution of machine learning in the field of security attack and defense more clearly, as shown in the figure below, FreeBuf official website summarizes six security fields, namely identity recognition and authentication, social engineering, network security, Web security, security vulnerability and malicious code, intrusion detection and defense, and lists typical application cases in each field.
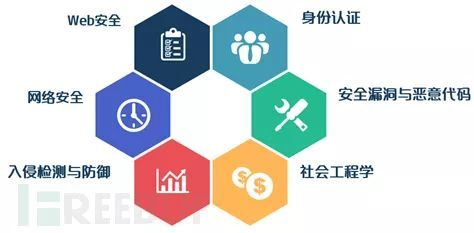
PS: the following small part of the content refers to the article of FreeBuf, which is recommended for you to read. The author also tried to summarize it, but it was not satisfactory. Let's see Daniel's writing!
1. Identification and authentication
Identity recognition and authentication are the fields in which AI is widely used. In addition to various existing AI applications such as face image recognition, voice sound recognition and abnormal behavior detection, this part will list two examples of "verification code cracking" and "malicious user recognition".
Identity authentication -- verification code cracking
In June 2017, the security team of Tencent Guardian plan assisted the police to knock down the "quick answer" platform, the largest coding platform on the market, and dug out a whole chain of illegal production, ranging from the collision of database numbers, the cracking of verification codes to the sale of citizen information and the implementation of network fraud. In the process of identification during verification, the black production uses AI, which greatly improves the number of identification verification codes per unit time. In the first quarter of 2017, the number of coding reached 25.9 billion times, and the accuracy of identification verification codes exceeded 80%.
In the network black production, after the lawbreakers steal the website database, they need to confirm whether the password corresponding to the account number is correct, and use the collision database to screen out the valuable data through verification. In this process, the core obstacle is the verification code security system. The AI system of the coding platform can take a picture of the verification code as a whole, and convert the recognition of a single word into a picture with multiple labels, and recognize all the characters in the verification code end-to-end. In addition, we can train and update the recognition network in real time by collecting the failure samples and the calibration data of manual coding, and optimize the iterative training continuously, so as to further improve the recognition ability of the neural network model. Therefore, in the face of website verification, there are many different types of verification methods, such as picture selection, text selection, picture filling and so on, in order to deal with hackers' changing attack and cracking methods.
Behavior analysis - malicious user identification
In the analysis of user behavior, malicious user requests are analyzed from user click stream data. In particular, Isolation Forest algorithm can be used for classification and recognition. In the user click stream data, including request time, IP, platform and other characteristics. In the isolated forest model, firstly, a feature of user behavior samples is randomly selected, then a value in the value range of the feature is randomly selected, the sample set is split, and the process is iterated to generate an isolated tree; the closer the leaf node is to the root node, the higher its abnormal value is. In the process of recognition, the results of multiple trees are fused to form the final behavior classification results.
Because malicious users only account for a small part of the total users, which has two characteristics of "small amount" of abnormal samples and "different performance from normal samples", and does not rely on probability density, this anomaly detection model will not lead to the down overflow problem of high-dimensional input. The model can identify abnormal user's stealing number, LBS / adding friends, fraud and other behaviors. With the increase of samples, the uin, type and occurrence time of malicious requests can be detected effectively through offline manual analysis and online attack at the analysis end.
2. social engineering
Social engineering refers to the behavior that attackers use some means to deceive others. In addition to existing AI applications such as credit card fraud and credit risk assessment, this section will list two examples of "spear phishing" and "fraud phone identification".
Anti phishing -- spear phishing
In May 2017, Google used machine learning technology, and its spam and phishing email recognition rate has reached 99.9%. Google built a system. The system can delay the time of Gmail information to perform more detailed phishing analysis. When users browse email, information about phishing will be detected more quickly. Using Google's machine learning, the system can also update the algorithm in real time over time, so that data and information can be further analyzed. However, the system is only applicable to 0.05% of information.
Different from general phishing, spear phishing is a customized phishing attack against a specific target. Hackers will use machine learning method to analyze the target information from social media, news reports and other materials, including name, email address, social media account or any content that they have participated in online. The target of attack is usually not ordinary users, but members of specific companies or organizations. The stolen data is not personal data, but other highly sensitive data. In the face of Harpoon phishing, on the one hand, enterprises will strengthen the data protection of the website and prevent all kinds of crawlers. Through reverse analysis and machine learning, they will detect and filter spam / phishing emails. On the other hand, users will improve their security awareness, pay attention to personal privacy disclosure and keep vigilance.
Anti fraud - fraud phone identification
In recent years, the crime of communication fraud has become more and more serious. Only in 2015, the reported data, such as "guess who I am" and "pretend to be a public prosecution law", involved in telephone fraud cases, the national user loss is about 22 billion. In response to communication fraud, there are usually two solutions: post-processing and real-time blocking. Because the timeliness of post-processing is too low, fraud funds are often transferred, which can not play a good role in protecting citizens' property. Therefore, real-time blocking is very necessary. When users receive and make calls, through machine learning, they can find out whether they are fraudulent calls in real time and send out real-time alarms immediately.
Feature extraction is carried out from the aspects of active feature data, social network, event flow, behavior feature, credit degree and abnormal degree of number, and it is detected according to machine learning architecture. In addition, combined with the event model and behavior model correlation analysis, it can more accurately monitor the fraud phone.
3. Network security
Network security means that the software and hardware of the network system are protected and the network service is not interrupted. In addition to existing AI applications such as hidden signal recognition, this section will list two examples: "big data DDoS detection" and "pseudo base station SMS recognition".
Anti DDoS -- big data DDoS detection
In recent years, distributed denial of service (DDoS) attack detection technology based on machine learning algorithm has made great progress. In the aspect of attack perception, we can perceive flooding attack and low rate denial of service (LDoS) method based on IP flow sequence spectrum analysis from the perspective of macro attack awareness and micro detection methods. On this basis, the detection of DDoS attacks is transformed into a two classification problem of machine learning.
From the perspective of probability point discrimination, based on the multi feature parallel hidden Markov model (MFP-HMM) DDoS attack detection method, using the corresponding relationship between HMM hidden state sequence and feature observation sequence, the multi-dimensional feature abnormal changes caused by the attack are transformed into discrete random variables, and the current sliding window sequence and positive are depicted by probability calculation The deviation degree of the regular behavior contour. From the perspective of classification hyperplane discrimination, based on the least squares twin support vector machine (LSTSVM), this paper uses IP packet quintuple entropy, IP identifier, TCP header identifier and packet rate as the multi-dimensional detection feature vector of LSTSVM model to reflect the flow distribution characteristics of DDoS attacks.
Wireless network attack -- SMS identification of pseudo base station
In order to solve the problem of "criminals can obtain the user's account number, password, ID card and other information by sending SMS as 10086, 95533 and other institutions". In 2016, 360 mobile phone, relying on the pseudo base station tracking system developed by 360 company, took the lead in launching the pseudo base station fraud SMS identification function in the world, with the interception accuracy of 98%, which can effectively ensure the safety of users' property. The core value of 360 pseudo base station tracking system is to solve the above-mentioned pseudo base station attack problem. Relying on massive data, efficient data analysis and processing and data visualization, it can provide accurate information and accurate judgment for tracking pseudo base stations.
In December 2015, 360 mobile phones took the lead in launching the function of accurate identification of fake base station garbage and fraud SMS in the world. Because the recognition and classification of spam and fraud SMS involves natural language processing technology and machine learning model, 360 uses the combination of linguistic rules and statistical methods to define the characteristics of pseudo base station SMS, which can accurately identify pseudo base station SMS from massive data, so its recognition accuracy can reach 98%. For the release and deployment of 360 pseudo base station tracking system, as well as its successful application in 360 mobile phones, it can effectively curb the rampant fraud activities of pseudo base stations, and help to maintain the property security of mobile phone users and other people.
4.Web security
Web security means that personal users are not damaged, changed or leaked due to accidental or malicious reasons during web related operations. In addition to existing AI applications such as SQL injection detection and XSS attack detection, this section will list two examples: "malicious URL detection" and "Webshell detection". In the following experiments, the author will describe the process in detail.
Secure website detection - malicious URL detection
On the market, Google's Chrome has combined detection model with machine learning to support safe browsing and alert users of potential malicious web addresses. Combined with thousands of spam, malware, attachments with heuristics and signatures of senders, new threats are identified and classified.
At present, most of the website detection methods are based on the database matching of URL black-and-white list. Although it has a certain detection effect, it has a certain lag and can not identify URLs that are not recorded. Based on machine learning, the association analysis of URL features, domain name features and Web features makes the malicious URL recognition with high accuracy and the ability of learning and inference. Some open-source tools such as phinn provide another way to detect. If a page looks like a Google login page, it should be hosted in the Google domain name. Phinn uses the convolutional neural network algorithm in machine learning to generate and train a custom Chrome extension, which can analyze the visual similarity between the pages presented in the user's browser and the real login page, so as to identify malicious URLs (phishing sites).
Injection attack detection -- Webshell detection
Webshell is often called anonymous user's (intruder's) permission to operate the web server to some extent through the web port. Because Web shell mostly appears in the form of dynamic script, it is also called the backdoor tool of website. In the attack chain model, the whole attack process is divided into: stampede, assembly, delivery, attack, implantation, control, action. In the attack against website, it is usually to use upload vulnerability to upload webshell, and then further control the web server through webshell.
Traditional web shell detection methods include static detection, dynamic detection, syntax detection, statistical detection and so on. With the rise of AI, the technology of Web SHELL file feature detection based on AI is better than the traditional technology. Through word bag & TF-IDF model, Opcode & N-gram model, Opcode call sequence model and other feature extraction methods, the appropriate model, such as naive Bayes and MLP of deep learning, CNN, etc., is adopted to realize the detection of Web shell. Similarly, SQL injection and XSS attack detection can also be performed.
5. Security vulnerability and malicious code
Security vulnerability refers to the defect in the specific implementation of hardware, software, protocol or system security policy; malicious code refers to the code with security threat. In addition to existing AI applications such as malware detection and identification, this section will list two examples: "malicious code classification" and "system automation vulnerability repair".
Code security - malicious code classification
In the early anti-virus software, whether it is signature scanning, searching for broad-spectrum features, heuristic scanning, these three killing methods do not actually run binary files, so they can be classified as malicious code static detection methods. With the gradual development of anti malicious code technology, active defense technology and cloud killing technology have been used by more and more security vendors, but the static detection method of malicious code is still the most efficient and widely used malicious code killing technology.
In 2016, Microsoft launched a malicious code classification competition on Kaggle, and the champion team adopted a malicious code image rendering method. A binary file is transformed into a matrix (the matrix element corresponds to each byte in the file, and the size of the matrix can be adjusted according to the actual situation). The matrix can be easily converted into a gray-scale image. Then based on N-gram, statistical probability model. Finally, it is put into decision tree and random forest for training and testing. This method can find some variants that static methods can't find, and can also be applied to malicious code detection on Android and IOS platforms.
Bug fix system automation bug fix
In August 2016, DARPA held the Cyber Grand Challenge challenge at the DEFCON hacking conference, which required participants to build a set of intelligent system in the contest, not only to detect vulnerabilities, but also to automatically write patches and complete deployment. Today, the average discovery cycle of software vulnerabilities is up to 312 days. After the discovery, it is necessary to research and develop patches for vulnerabilities until the final announcement. During this period, attackers are likely to have used this vulnerability to launch network attacks. Therefore, it is necessary to repair the system automation vulnerabilities.
In October 2017, MIT research team developed a system called "Genesis", which can automatically learn previous patches, generate patch templates, and evaluate candidate patches. According to the researchers, "Genesis is the first system that automatically infers patch generation and transformation or searches for candidate patch space based on previously successful patches." it fixes almost twice as many bug s as the best hand-made template system, and is more accurate. These templates are "customized" based on specific types of real patches, so they do not produce as many useless alternatives as possible.
6. Intrusion detection and Prevention
Intrusion detection and defense refers to the discovery of intrusion and corresponding defense actions. In addition to existing AI applications such as intranet intrusion detection, this section will list two examples: "APT detection and prevention" and "C2 link analysis".
Advanced Attack intrusion detection -- APT detection and Prevention
The attacker of APT attack can detect the target, make attack tools, deliver attack tools, use loopholes or weaknesses to break through, take down the running tools of the whole line, and maintain the tools remotely in the later stage, and finally achieve the goal of long-term control. In response to this increasingly widespread APT attack, Threat Intelligence exists in all aspects of the attack.
Threat Intelligence is a group of related information that describes threats based on evidence, including threat related environmental information, such as specific attack organizations and malicious domain names. The malicious domain name also includes the remote-controlled IOC, the HASH and URL of malicious files, and the correlation between threat indicators, as well as the change of attack methods in time and latitude. This information is combined to form high-level Threat Intelligence. In addition, the intelligence concerned also includes the expansion of traditional threat types, including Trojan remote control, Botnet, spyware, Web backdoor, etc. Using machine learning to deal with threat intelligence, detect and identify the malicious load in APT attack, improve the efficiency and accuracy of apt attack threat perception system, and enable security researchers to find and trace the source of apt attack faster.
DGA domain name detection -- C2 link analysis
DGA (domain name generation algorithm) is a technology which uses random characters to generate C2 domain name, so as to avoid the detection of domain name blacklist. With DGA domain name generation algorithm, attackers can use it to generate pseudo-random strings for domain names, which can effectively avoid the detection of blacklist. Pseudo-random means that the string sequence seems to be random, but because its structure can be determined in advance, it can be generated and copied repeatedly. This algorithm is often used in remote control software.
First, the attacker runs the algorithm and randomly selects a small number of domains (possibly only one), then the attacker registers the domain and points it to its C2 server. Run DGA on the victim side and check whether the output domain exists. If it is detected that the domain is registered, the malware will choose to use the domain as its command and control (C2) server. If the current domain is detected as unregistered, the program will continue to check for other domains. Therefore, security personnel can predict which domains will be generated, pre registered and blacklisted in the future by collecting samples and reversing DGA.
2, Malicious code detection based on machine learning
1. Traditional malicious code detection
Traditional malicious code detection includes signature based detection and heuristic based detection. When dealing with a large number of unknown malicious code, it is facing more and more challenges.
(1) Detection based on signature signature signature
Signature signature signature signature detection method maintains a known malicious code base, and compares the signature of the code sample to be detected with the signature in the malicious code base. If the signature signature matches, the sample is malicious code. This method needs a lot of manpower and material resources to study the malicious code and requires users to update the malicious code base in time. The detection efficiency and effect are more and more inadequate, and it is difficult to effectively resist the unknown malicious code.
(2) Detection based on heuristic rules
Heuristic rule detection method extracts the existing malicious code rules by professional analysts, and detects the code samples according to the extracted rules. However, in the face of the explosive growth trend of malicious code at this stage, only relying on human malicious code analysis, it becomes more and more difficult to implement.
2. Malicious code detection based on machine learning
The protection technology based on machine learning algorithm provides an effective technical way to achieve high accuracy and automation of unknown malicious code detection, which has gradually become a research hotspot in the industry. According to the different angle of sample data collection in the detection process, the detection can be divided into static analysis and dynamic analysis.
Static analysis does not run the program to be tested, but obtains the data characteristics through the analysis of the program (such as the disassembled code), while dynamic analysis executes the program in the virtual machine or the emulator, and obtains the data (such as behavior characteristics) generated in the process of program execution for detection and judgment.
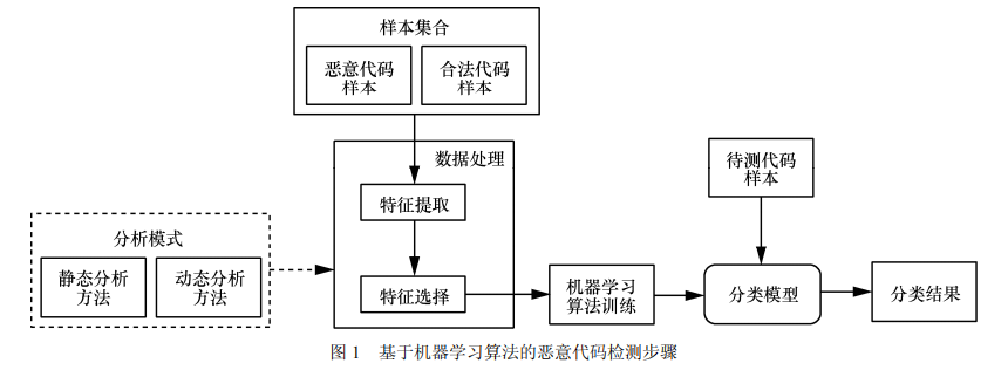
According to Cohen's research results on malicious code, the essence of malicious code detection is a classification problem, that is, to distinguish the samples to be detected into malicious or legitimate programs. The core steps are:
- Collect a sufficient number of malicious code samples
- Effective data processing and feature extraction for samples
- Further select the main data features for classification
- Combined with the training of machine learning algorithm, a classification model is established
- Detection of unknown samples by trained classification model
See the author's article for details: [self study of network security] 10. Malicious code of host based on machine learning algorithm
3. Characteristics and difficulties of machine learning in the field of safety
Machine learning is a multi-disciplinary, its essence is to learn in data, through the appropriate algorithm modeling, and finally achieve classification, clustering or prediction in the case of no rules. From the first part of the case, we can see that machine learning is most commonly used in three directions: malicious code identification, social workers' security and intrusion detection.
- In the aspect of malicious code identification: distinguish the traditional black and white list database, feature detection, heuristics and other methods of machine learning from anti-virus code classification, malicious file detection, malicious URL web page code identification, etc
- In the aspect of social workers' security prevention: different from traditional technology and business experience analysis, security publicity, financial model and other evaluation methods, the security applications of machine learning range from harpoon phishing detection, malicious user click stream identification, fraud phone and SMS analysis, to financial credit fraud, etc
- In the aspect of intrusion detection: different from the traditional rule-based and policy based, regular matching and so on, machine learning security applications from DDoS Defense, webshell detection, DGA prevention to APT detection and so on.
On the whole, even though machine learning can not achieve 100% effect after training model, compared with traditional means, the detection effect is improved to some extent.
Although machine learning technology has been applied in many scenarios in the field of security, it provides a new perspective for the existing user security protection strategy. It is easy to see from the above cases that the application difficulties of machine learning in safety and risk control mainly include:
- Machine learning needs to balance high-quality data sets as much as possible. In the field of security, whether it is risk fraud, phishing, malware, etc., it usually contains a large number of normal samples and a very small number of security risks. Therefore, the insufficient malicious access and attack samples lead to the detection accuracy after model training to be improved.
- The models of machine learning are generally black box analysis, which can not get enough information. Unlike other AI applications (such as commodity recommendation system), model classification errors in the field of application security have a high cost, and in the face of network threats and hidden dangers, security analysts hope to obtain the understanding of the situation and intelligence in the network confrontation, so as to make corresponding human intervention.
- At present, all machine learning models that need supervised learning need to input reasonable and highly relevant feature sets, that is, feature engineering that needs to map from source data to feature space. In the field of security, there will be an abstract cost between the network monitoring and the actual detection objects. For example, the corresponding relationship between software defects and the underlying implementation code and structure has an abstract and translation difficulty.
At the same time, machine learning as a new frontier technology, even if it solves or overcomes the problems and difficulties of traditional security attack and defense technology, in some scenarios and environments, there are still unavoidable defects or even if it solves the problems, it can not meet the actual needs, that is, it can not use machine learning algorithm for security attack and defense blind spots.
- Unable to discover malicious behavior for unknown mode
- Misreport the normal behavior of a large number of abnormal tests
- Strong dependence on data quantity and quality
3, Logical regression to identify website malicious requests
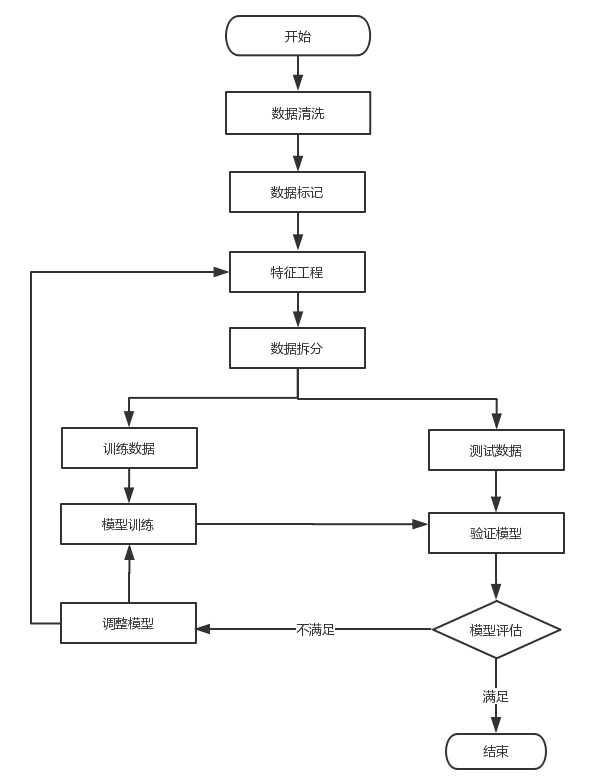
Next, the author repeats the code of exp DB God on Github, and recommends you to read the works of God in the previous references. The basic idea of the code is to establish a detection model through machine learning (logical regression), so as to identify malicious and normal requests of the website. The basic process is as follows:
- Read the normal and malicious request data sets, preprocess and set the class y and data set x
- The data set is processed by N-grams, and TF-IDF characteristic matrix is constructed. Each request corresponds to a row of data in the matrix
- Data set is divided into training data and test data
- Using machine learning logic regression algorithm to train the feature matrix, the corresponding model is obtained
- The training model is used to detect the unknown URL request and judge whether it is a malicious request or a normal request
1. data set
stay https://github.com/foospidy/payloads Common malicious requests such as SQL injection, XSS attack and so on are collected in. The experimental data include:
- Normal requests: goodqueries.txt, 1265974 requests from http://secrepo.com
- Malicious requests: badqueries.txt, 44532, payload of XSS, SQL injection and other attacks
Note that resources and energy are limited. The data set assumes that the log requests of http://secrepo.com website are all normal requests. It has energy to reduce noise and remove abnormal tag data.

The core code of this part is:
import os import urllib
#Get the list of requests in the text
def get_query_list(filename):
directory = str(os.getcwd())
print(directory)
filepath = directory + "/" + filename
data = open(filepath, 'r', encoding='UTF-8').readlines()
query_list = []
for d in data:
Decoy decoding
d = str(urllib.parse.unquote(d)) #converting url encoded data to simple string
#print(d)
query_list.append(d)
return list(set(query_list))
Main function
if name == 'main':
<span class="token comment"># Get normal request</span>
good_query_list <span class="token operator">=</span> get_query_list<span class="token punctuation">(</span><span class="token string">'goodqueries.txt'</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>u<span class="token string">"Normal request: "</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>good_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>good_query_list<span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token string">'\n'</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"\n"</span><span class="token punctuation">)</span>
<span class="token comment"># Get malicious request</span>
bad_query_list <span class="token operator">=</span> get_query_list<span class="token punctuation">(</span><span class="token string">'badqueries.txt'</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>u<span class="token string">"Malicious request: "</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>bad_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>bad_query_list<span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token string">'\n'</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"\n"</span><span class="token punctuation">)</span>
<span class="token comment"># Preprocessing good ABCD marked as 0 bad ABCD marked as 1</span>
good_y <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token number">0</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>good_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">]</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>good_y<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
bad_y <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token number">1</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>bad_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">]</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>bad_y<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
queries <span class="token operator">=</span> bad_query_list <span class="token operator">+</span> good_query_list
y <span class="token operator">=</span> bad_y <span class="token operator">+</span> good_y
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
2. Combining n-grams and TF-IDF to construct characteristic matrix
One of the highlights of this code is the combination of N-grams and TF-IDF to construct the feature matrix. Author's previous: [python] use scikit learn tool to calculate text TF IDF value
TF-IDF (term frequency inversdocument frequency) is a weighting technology commonly used in information processing and data mining. This technique uses a statistical method to calculate the importance of a word in the whole corpus according to the number of words appearing in the text and the frequency of documents appearing in the whole corpus. Its advantage is that it can filter out some common but unimportant words, while retaining the important words that affect the whole text. The calculation method is shown in the following formula.
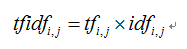
Where, tf idf represents the product of word frequency tf and inverted text word frequency idf. The larger the TF-IDF value, the more important the feature word is to the text. Its basic idea is to transform text into feature matrix, and reduce the weight of common words (such as we, all, www, etc.), so as to better express the value of a text. As shown in the following example:
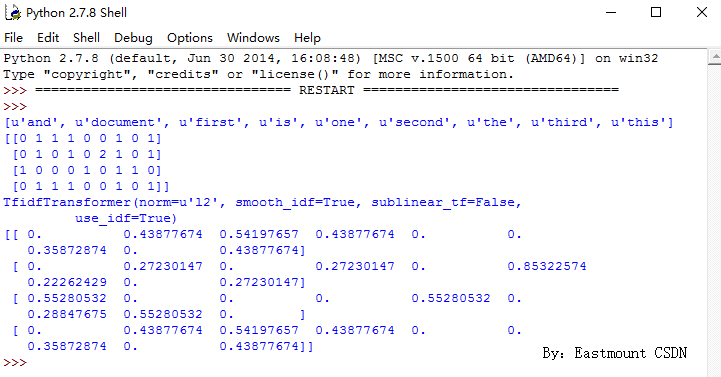
# coding:utf-8 from sklearn.feature_extraction.text import CountVectorizer
Corpus of Chinese Medicine
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
#Convert words in text to word frequency matrix
vectorizer = CountVectorizer()
#Count the number of occurrences of words
X = vectorizer.fit_transform(corpus)
#Get all text keywords in the word bag
word = vectorizer.get_feature_names()
print word
#View word frequency results
print X.toarray()
from sklearn.feature_extraction.text import TfidfTransformer
Call of class
transformer = TfidfTransformer()
print transformer
#Count word frequency matrix X into TF-IDF value
tfidf = transformer.fit_transform(X)
#View the data structure TF IDF [i] [J] to represent TF IDF weight in class I text
print tfidf.toarray()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
No matter the malicious request data set or the normal request data set, they are all indefinite string lists. It is difficult to deal with these irregular data directly with the logic regression algorithm. We need to find the digital characteristics of these texts to train our detection model. Here, TD-IDF is used as the feature of text and output in the form of digital matrix. Before calculating TD-IDF, first of all, we need to segment the content of each document (URL request), that is, we need to define the term length of the document. Here we choose N-grams with the length of 3, which can be adjusted according to the accuracy of the model.
The core code of this part is as follows, see note for details:
from sklearn.linear_model import LogisticRegression from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split
# tokenizer function, this will make 3 grams of each query
#W w W.F o O.C o m/1 is converted to ['www ',' ww. ','w.f', 'fo', 'foo', 'oo.','o.c ',' co ',' com ',' om / ','m / 1]
def get_ngrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0, len(tempQuery)-3):
ngrams.append(tempQuery[i:i+3])
return ngrams
Main function
if name == 'main':
....
#Defining vectorizing converting data to vectors
# TfidfTransformer + CountVectorizer = TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=get_ngrams)
<span class="token comment"># Convert irregular text string list to regular ([i,j], tdidf value) matrix X</span> <span class="token comment"># For the next step of training logical regression classifier</span> X <span class="token operator">=</span> vectorizer<span class="token punctuation">.</span>fit_transform<span class="token punctuation">(</span>queries<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>X<span class="token punctuation">.</span>shape<span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3. Training model
By using the feature matrix as training set and calling logical regression for training and testing, the two core functions of machine learning in Python are fit() and predict(). Here, call the train ﹣ test ﹣ split() function to randomly divide the data set. The core code is as follows:
from sklearn.linear_model import LogisticRegression from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split
Main function
if name == 'main':
....
#Split the X y list with train? Test? Split
#The number of x-train matrices corresponds to the number of y-train lists (one-to-one correspondence) - > > used to train models
#The number of X-test matrices corresponds (one-to-one) -- > > to test the accuracy of the model
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=20, random_state=42)
<span class="token comment"># Theory logic regression model</span>
LR <span class="token operator">=</span> LogisticRegression<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token comment"># Training model</span>
LR<span class="token punctuation">.</span>fit<span class="token punctuation">(</span>X_train<span class="token punctuation">,</span> y_train<span class="token punctuation">)</span>
<span class="token comment"># Using test values to calculate the accuracy of the model</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'Model accuracy:{}'</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>LR<span class="token punctuation">.</span>score<span class="token punctuation">(</span>X_test<span class="token punctuation">,</span> y_test<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"\n"</span><span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4. Check whether the new dataset is a malicious request or a normal request
After the model is trained, it is found that its accuracy is very high, and the real experiment needs to be judged by the accuracy, recall rate and F value. Next, call the Predict() function to judge the new RUL, and check whether it is a malicious request or a normal request
. The core code is as follows:
from sklearn.linear_model import LogisticRegression from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split
Main function
if name == 'main':
....
#Forecast new request list
new_queries = ['www.foo.com/id=1<script>alert(1)</script>',
'www.foo.com/name=admin' or 1=1','abc.com/admin.php',
'"><svg οnlοad=confirm(1)>',
'test/q=<a href="javascript:confirm(1)>',
'q=.../etc/passwd',
'/stylesheet.php?version=1331749579',
'/<script>cross_site_scripting.nasl</script>.idc',
'<img \x39src=x οnerrοr="javascript:alert(1)">',
'/jhot.php?rev=2 |less /etc/passwd']
<span class="token comment"># Matrix transformation</span>
X_predict <span class="token operator">=</span> vectorizer<span class="token punctuation">.</span>transform<span class="token punctuation">(</span>new_queries<span class="token punctuation">)</span>
res <span class="token operator">=</span> LR<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>X_predict<span class="token punctuation">)</span>
res_list <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span>
<span class="token comment"># Result output</span>
<span class="token keyword">for</span> q<span class="token punctuation">,</span>r <span class="token keyword">in</span> <span class="token builtin">zip</span><span class="token punctuation">(</span>new_queries<span class="token punctuation">,</span> res<span class="token punctuation">)</span><span class="token punctuation">:</span>
tmp <span class="token operator">=</span> <span class="token string">'Normal request'</span> <span class="token keyword">if</span> r <span class="token operator">==</span> <span class="token number">0</span> <span class="token keyword">else</span> <span class="token string">'Malicious request'</span>
q_entity <span class="token operator">=</span> html<span class="token punctuation">.</span>escape<span class="token punctuation">(</span>q<span class="token punctuation">)</span>
res_list<span class="token punctuation">.</span>append<span class="token punctuation">(</span><span class="token punctuation">{</span><span class="token string">'url'</span><span class="token punctuation">:</span>q_entity<span class="token punctuation">,</span><span class="token string">'res'</span><span class="token punctuation">:</span>tmp<span class="token punctuation">}</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> n <span class="token keyword">in</span> res_list<span class="token punctuation">:</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>n<span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
The final output results are shown in the figure below, and it can be found that the judgment is more accurate.

5. Complete code
The complete code is as follows, and we recommend you to go to Github to learn a lot of code, and also recommend you to go to FreeBuf, safe guest, CVE and other websites to learn. Author Github has complete code: https://github.com/eastmountyxz/NetworkSecuritySelf-study
# coding: utf-8 import os import urllib import time import html from sklearn.linear_model import LogisticRegression from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split
#Get the list of requests in the text
def get_query_list(filename):
directory = str(os.getcwd())
print(directory)
filepath = directory + "/" + filename
data = open(filepath, 'r', encoding='UTF-8').readlines()
query_list = []
for d in data:
Decoy decoding
d = str(urllib.parse.unquote(d)) #converting url encoded data to simple string
#print(d)
query_list.append(d)
return list(set(query_list))
# tokenizer function, this will make 3 grams of each query
#W w W.F o O.C o m/1 is converted to ['www ',' ww. ','w.f', 'fo', 'foo', 'oo.','o.c ',' co ',' com ',' om / ','m / 1]
def get_ngrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0, len(tempQuery)-3):
ngrams.append(tempQuery[i:i+3])
return ngrams
Main function
if name == 'main':
<span class="token comment"># Get normal request</span>
good_query_list <span class="token operator">=</span> get_query_list<span class="token punctuation">(</span><span class="token string">'goodqueries.txt'</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>u<span class="token string">"Normal request: "</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>good_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>good_query_list<span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token string">'\n'</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"\n"</span><span class="token punctuation">)</span>
<span class="token comment"># Get malicious request</span>
bad_query_list <span class="token operator">=</span> get_query_list<span class="token punctuation">(</span><span class="token string">'badqueries.txt'</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>u<span class="token string">"Malicious request: "</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>bad_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>bad_query_list<span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token string">'\n'</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"\n"</span><span class="token punctuation">)</span>
<span class="token comment"># Preprocessing good ABCD marked as 0 bad ABCD marked as 1</span>
good_y <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token number">0</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>good_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">]</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>good_y<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
bad_y <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token number">1</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>bad_query_list<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">]</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>bad_y<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token number">5</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
queries <span class="token operator">=</span> bad_query_list <span class="token operator">+</span> good_query_list
y <span class="token operator">=</span> bad_y <span class="token operator">+</span> good_y
<span class="token comment"># Defining vectorizing converting data to vectors</span>
<span class="token comment"># TfidfTransformer + CountVectorizer = TfidfVectorizer</span>
vectorizer <span class="token operator">=</span> TfidfVectorizer<span class="token punctuation">(</span>tokenizer<span class="token operator">=</span>get_ngrams<span class="token punctuation">)</span>
<span class="token comment"># Convert irregular text string list to regular ([i,j], tdidf value) matrix X</span>
<span class="token comment"># For the next step of training logical regression classifier</span>
X <span class="token operator">=</span> vectorizer<span class="token punctuation">.</span>fit_transform<span class="token punctuation">(</span>queries<span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>X<span class="token punctuation">.</span>shape<span class="token punctuation">)</span>
<span class="token comment"># Split the X y list with train? Test? Split</span>
<span class="token comment"># The number of x-train matrices corresponds to the number of y-train lists (one-to-one) - & gt; & gt; used to train models</span>
<span class="token comment"># The number of x'u test matrices corresponds (one-to-one correspondence) - & gt; & gt; is used to test the accuracy of the model</span>
X_train<span class="token punctuation">,</span> X_test<span class="token punctuation">,</span> y_train<span class="token punctuation">,</span> y_test <span class="token operator">=</span> train_test_split<span class="token punctuation">(</span>X<span class="token punctuation">,</span> y<span class="token punctuation">,</span> test_size<span class="token operator">=</span><span class="token number">20</span><span class="token punctuation">,</span> random_state<span class="token operator">=</span><span class="token number">42</span><span class="token punctuation">)</span>
<span class="token comment"># Theory logic regression model</span>
LR <span class="token operator">=</span> LogisticRegression<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token comment"># Training model</span>
LR<span class="token punctuation">.</span>fit<span class="token punctuation">(</span>X_train<span class="token punctuation">,</span> y_train<span class="token punctuation">)</span>
<span class="token comment"># Using test values to calculate the accuracy of the model</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'Model accuracy:{}'</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>LR<span class="token punctuation">.</span>score<span class="token punctuation">(</span>X_test<span class="token punctuation">,</span> y_test<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"\n"</span><span class="token punctuation">)</span>
<span class="token comment"># Forecast new request list</span>
new_queries <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token string">'www.foo.com/id=1<script>alert(1)</script>'</span><span class="token punctuation">,</span>
<span class="token string">'www.foo.com/name=admin\' or 1=1'</span><span class="token punctuation">,</span><span class="token string">'abc.com/admin.php'</span><span class="token punctuation">,</span>
<span class="token string">'"><svg οnlοad=confirm(1)>'</span><span class="token punctuation">,</span>
<span class="token string">'test/q=<a href="javascript:confirm(1)>'</span><span class="token punctuation">,</span>
<span class="token string">'q=../etc/passwd'</span><span class="token punctuation">,</span>
<span class="token string">'/stylesheet.php?version=1331749579'</span><span class="token punctuation">,</span>
<span class="token string">'/<script>cross_site_scripting.nasl</script>.idc'</span><span class="token punctuation">,</span>
<span class="token string">'<img \x39src=x οnerrοr="javascript:alert(1)">'</span><span class="token punctuation">,</span>
<span class="token string">'/jhot.php?rev=2 |less /etc/passwd'</span><span class="token punctuation">]</span>
<span class="token comment"># Matrix transformation</span>
X_predict <span class="token operator">=</span> vectorizer<span class="token punctuation">.</span>transform<span class="token punctuation">(</span>new_queries<span class="token punctuation">)</span>
res <span class="token operator">=</span> LR<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>X_predict<span class="token punctuation">)</span>
res_list <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span>
<span class="token comment"># Result output</span>
<span class="token keyword">for</span> q<span class="token punctuation">,</span>r <span class="token keyword">in</span> <span class="token builtin">zip</span><span class="token punctuation">(</span>new_queries<span class="token punctuation">,</span> res<span class="token punctuation">)</span><span class="token punctuation">:</span>
tmp <span class="token operator">=</span> <span class="token string">'Normal request'</span> <span class="token keyword">if</span> r <span class="token operator">==</span> <span class="token number">0</span> <span class="token keyword">else</span> <span class="token string">'Malicious request'</span>
q_entity <span class="token operator">=</span> html<span class="token punctuation">.</span>escape<span class="token punctuation">(</span>q<span class="token punctuation">)</span>
res_list<span class="token punctuation">.</span>append<span class="token punctuation">(</span><span class="token punctuation">{</span><span class="token string">'url'</span><span class="token punctuation">:</span>q_entity<span class="token punctuation">,</span><span class="token string">'res'</span><span class="token punctuation">:</span>tmp<span class="token punctuation">}</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> n <span class="token keyword">in</span> res_list<span class="token punctuation">:</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>n<span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
Four. Conclusion
Write here, a malicious code request recognition based on machine learning finished, I hope the readers like it, don't like it. The highlight of this code is the integration of N-grams into TF-IDF, which can also be replaced by other classification models. Although the code is very basic, it also takes three hours for the author to review and reproduce a large number of web articles (as shown in the figure below).
Step by step, I hope to realize more malicious code identification and confrontation samples through in-depth learning, and prepare to open TensorFlow2.0 and more security foundation series. As a rookie in the field of security, I feel that I have a lot of knowledge to learn, which is very complicated, and a lot of charging materials are very expensive. This series of articles are self-taught by the author and shared for free to the bloggers. I hope you like and like it, and continue to cheer in the future! Because of your reading, I have the power to write, xiuzhang shared.
(By:Eastmount 2019-11-01 2:00 noon in Wuhan http://blog.csdn.net/eastmount/ )
</div>

