Ajax crawls to the top of today's street shooting improvement -- various minefield solutions including data:none problem
This BUG is self-taught crawler to prepare for big data. Due to the progress of the times, all websites have strengthened anti climbing measures, and the teaching of books in the learning process is no longer applicable. This BUG slightly improves the code in the learning process, but there is BUG, and I hope you guys can give us more advice.
Web analysis:
Enter the page, open F12, click XHR (the data loaded by Ajax can be found here), try to click on the data, and then click Preview to find that the data of the first data has the data we want, and click on the analysis code.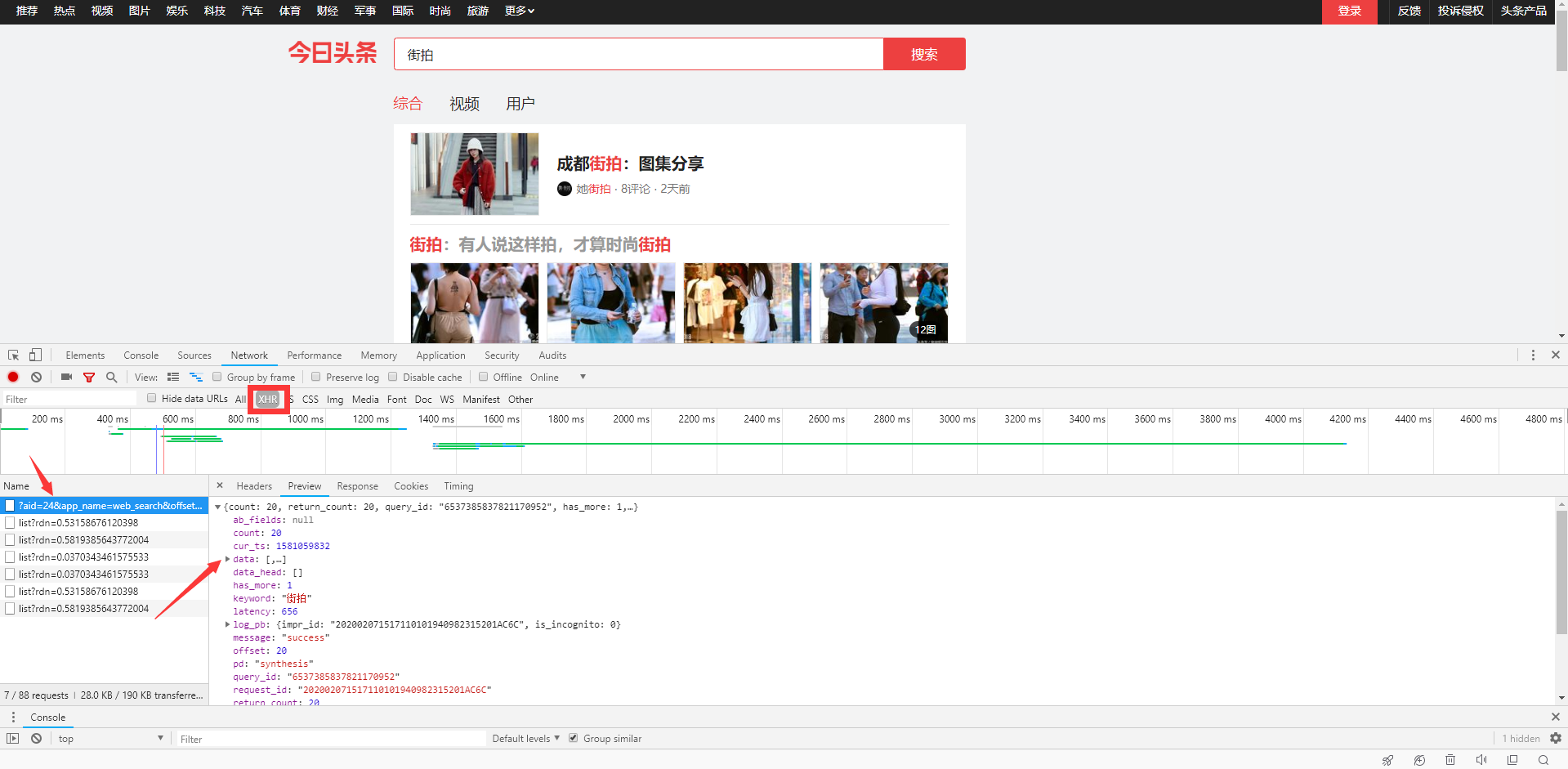 There is a lot of data in data, but now we can see that the data in 0 is not what we want. When we write the code, we can skip it, and then continue to look at the rest of the code. We can see that the image list contains the url of the image we are looking for
There is a lot of data in data, but now we can see that the data in 0 is not what we want. When we write the code, we can skip it, and then continue to look at the rest of the code. We can see that the image list contains the url of the image we are looking for
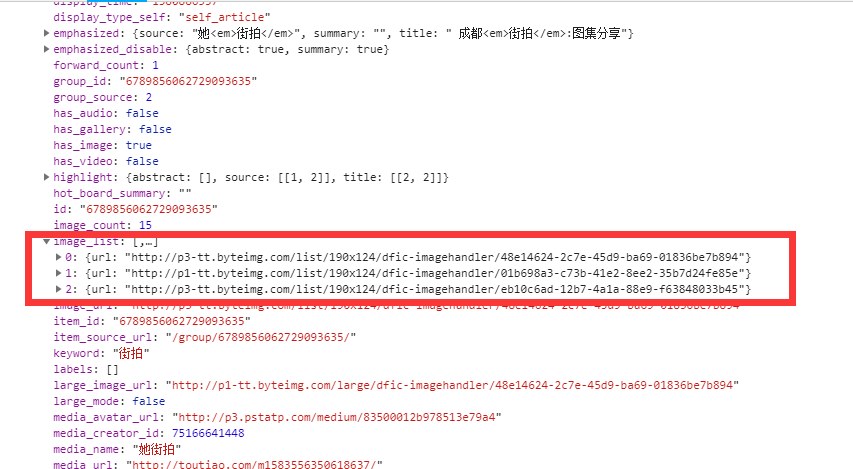 We drag the progress bar to find that more and more data are loaded. We click to find that their basic structure is similar to the data we just saw. By analyzing their URL s, we can know that their offset parameters are different. Then we can see that these data are equivalent to their pages, and we can extract the desired data together!
We drag the progress bar to find that more and more data are loaded. We click to find that their basic structure is similar to the data we just saw. By analyzing their URL s, we can know that their offset parameters are different. Then we can see that these data are equivalent to their pages, and we can extract the desired data together!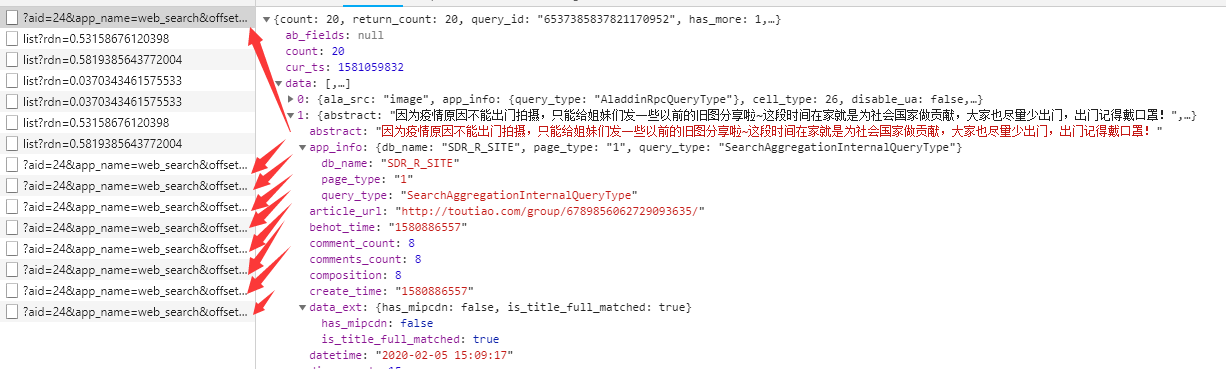
Writing magic code
Some bugs find that they can't request the data by using the code to request the Request URL of the data. I don't know if the bugs find that sometimes there is a graphic verification code when refreshing the page. That's the key. We add more information into the request header, such as cookie s, referer s, etc.
We'll find out if we ask again.
Here, we use from urllib.parse import urlencode to construct URLs. For more security, timestamp on URLs is directly obtained by int(time.time()), so that a complete url can be constructed. It's easy to request!
Note: some worm friends will start with the path and parameters on the url. Although they can request data, they are not the person (website) you want already!
def get_page(offset): headers={ 'cookie': 'tt_webid=6788065855508612621; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6788065855508612621; csrftoken=495ae3a5659fcdbdb78e255464317789; s_v_web_id=k66hcay0_qsRG7emW_x2Qj_4R3o_AeAG_iT4JWmz83jzr; __tasessionId=23dn3qk0f1580738708512', 'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'x-requested-with': 'XMLHttpRequest' }#There is invisible image verification, which appears occasionally. cookie is an important parameter, which is the key to solve data: none params={ 'aid': '24', 'app_name': 'web_search', 'offset': offset, 'format': 'json', 'keyword': 'Street pat', 'autoload': 'true', 'count': 20, 'en_qc': 1, 'cur_tab': 1, 'from': 'search_tab', 'pd': 'synthesis', 'timestamp':int(time.time()) #Get timestamp }#The way of constructing url is more concise and easy to modify in the later stage url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params) json = requests.get(url, headers=headers).json() # List 0, 1, 2, 3 return json
I've spent a lot of time here, debugging many times. Because there are a few lists in data that do not have image list, and those lists that do not have image list contain a mess of things, such as user information and so on.
In this case, we will directly obtain the images in the image list, filter them out with conditional statements, and then construct a generator to return them.
def get_image(json): for item in json['data']: if 'image_list' in item: title = item['title'] for image_urls in item['image_list']: image_url = image_urls['url'] yield{ 'image':image_url, 'title':title }
def save_image(content): if not os.path.exists(content['title']): if '|' in content['title']: c_title = content['title'].replace(' | ','')#Some title s contain special symbols that cannot be used to create folders os.mkdir(c_title) else: os.mkdir(content['title']) response = requests.get(content['image']) if response.status_code == 200: file_path = '{0}/{1}.{2}'.format(content['title'].replace(' | ','')if '|' in content['title'] else content['title'],md5(response.content).hexdigest(),'jpg')#The name and address of the file, and the name of the debugging folder with the binocular operator if not os.path.exists(file_path): with open(file_path,'wb')as f: f.write(response.content) else: print('Downloaded',file_path)
if __name__ == '__main__': for i in range(6,8): offset = i*20 #Constructing an Ajax loaded offset print(offset) json=get_page(offset) for content in get_image(json): try: save_image(content) except FileExistsError and OSError: print('Folder creation name format error: contains special characters')#Because of the need of the experiment, I skipped the unnecessary mistakes directly continue
Full code:
import requests from urllib.parse import urlencode import time import os from hashlib import md5 def get_page(offset): headers={ 'cookie': 'tt_webid=6788065855508612621; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6788065855508612621; csrftoken=495ae3a5659fcdbdb78e255464317789; s_v_web_id=k66hcay0_qsRG7emW_x2Qj_4R3o_AeAG_iT4JWmz83jzr; __tasessionId=23dn3qk0f1580738708512', 'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'x-requested-with': 'XMLHttpRequest' }#There is invisible image verification, which appears occasionally. cookie is an important parameter, which is the key to solve data: none params={ 'aid': '24', 'app_name': 'web_search', 'offset': offset, 'format': 'json', 'keyword': 'Street pat', 'autoload': 'true', 'count': 20, 'en_qc': 1, 'cur_tab': 1, 'from': 'search_tab', 'pd': 'synthesis', 'timestamp':int(time.time()) #Get timestamp }#The way of constructing url is more concise and easy to modify in the later stage url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params) json = requests.get(url, headers=headers).json() # List 0, 1, 2, 3 return json def get_image(json): for item in json['data']: if 'image_list' in item: title = item['title'] for image_urls in item['image_list']: image_url = image_urls['url'] yield{ 'image':image_url, 'title':title } def save_image(content): if not os.path.exists(content['title']): if '|' in content['title']: c_title = content['title'].replace(' | ','')#Some title s contain special symbols that cannot be used to create folders os.mkdir(c_title) else: os.mkdir(content['title']) response = requests.get(content['image']) if response.status_code == 200: file_path = '{0}/{1}.{2}'.format(content['title'].replace(' | ','')if '|' in content['title'] else content['title'],md5(response.content).hexdigest(),'jpg')#The name and address of the file, and the name of the debugging folder with the binocular operator if not os.path.exists(file_path): with open(file_path,'wb')as f: f.write(response.content) else: print('Downloaded',file_path) if __name__ == '__main__': for i in range(6,8): offset = i*20 #Constructing an Ajax loaded offset print(offset) json=get_page(offset) for content in get_image(json): try: save_image(content) except FileExistsError and OSError: print('Folder creation name format error: contains special characters') continue
summary
According to the code improvement of "Python 3 web crawler development practice", I hope you guys can point out more deficiencies, and I will continue to refuel! I hope the national epidemic situation is getting better and better. I believe the new coronavirus will be eliminated by us!!! Come on. China!

