The chedulingQueue is a pair of pod storage in the kubernetes scheduler responsible for scheduling. Scheduler uses SchedulingQueue to obtain pods waiting to be scheduled in the current system. This paper mainly discusses the design and implementation of SchedulingQueue, and explores its internal implementation and underlying source code. This series of codes is based on the analysis of kubernets 1.1.6.
SchedulingQueue design
Queues and Priorities
Queues and Scenes
| type | describe | Usually implemented |
|---|---|---|
| queue | An ordinary queue is a FIFO data structure that leaves the queue in turn according to the order in which the elements join the queue | Array or Chain List |
| Priority Queue | Priority queues usually refer to high priority being acquired first according to certain priority policies | Array or Tree |
In fact, in most scheduling scenarios, priority queues are mostly used to achieve priority to meet higher priority tasks or needs, thereby reducing subsequent high priority preemption to lower priority, as is the case in scheduler.
Priority Selection
The scheduling unit in k8s is Pod. The priority queue is built in scheduler according to the priority level of the pod. In fact, in the adminission access plug-in of kubernets, the pod created for the user calculates the priority field according to the user's settings.
Level 3 Queue
Active Queue
Active queues store all queues in the current system waiting to be dispatched
Undispatchable Queue
When the pod's resources are not satisfied in the current cluster, they are joined to an unschedulable queue and wait for a later attempt
backoff queue
The backoff mechanism is a common mechanism in concurrent programming, that is, if the repeated execution of tasks still fails, the waiting schedule time will increase step by step, reducing the retry efficiency, thus avoiding repeated failures and wasting scheduling resources
Pods against scheduling failures are stored in the backoff queue first, waiting for subsequent retries
Blocking and Preemption
Blocking Design
When there are no pods waiting to be dispatched in the queue, the scheduler will be blocked from waking up the dispatcher to get the pod to dispatch
Preemption-related
nominatedPods stores the node whose pod is proposed to run and is primarily used to preempt dispatch processes. This section does not analyze
Source Code Analysis
data structure
The default schedulingQueue implementation in kubernetes is PriorityQueue, which is the data structure that this chapter analyzes
type PriorityQueue struct {
stop <-chan struct{}
clock util.Clock
// pod timer storing backoff
podBackoff *PodBackoffMap
lock sync.RWMutex
// cond used to coordinate notifications blocked because dispatch pod could not be obtained
cond sync.Cond
// Active Queue
activeQ *util.Heap
// backoff queue
podBackoffQ *util.Heap
// Undispatchable Queue
unschedulableQ *UnschedulablePodsMap
// Storing pods and nominated nodes is essentially a node that stores pods and suggestions
nominatedPods *nominatedPodMap
// SchdulingCycle is an incremental ordinal of a scheduling cycle that increments when pod pop
schedulingCycle int64
// moveRequestCycle cache schedulingCycle, when an unscheduled pod is added back to activeQueue
// Will save schedulingCycle to moveRequestCycle
moveRequestCycle int64
closed bool
}PriorityQueue as the implementation of SchedulingQueue, its core data structure mainly contains three queues: activeQ, podBackoffQ, unscheduleQ internal through cond to achieve blocking and notification of Pop operations. Next, the core scheduling process is analyzed, and then the specific implementation in util.Heap is analyzed.
activeQ
A queue that stores all pods waiting to be dispatched, defaulting to heap-based, where the priority of the elements is sorted by comparing the creation time of the pod with the priority of the pod
// activeQ is heap structure that scheduler actively looks at to find pods to
// schedule. Head of heap is the highest priority pod.
activeQ *util.HeapPriority comparison function
// activeQComp is the function used by the activeQ heap algorithm to sort pods.
// It sorts pods based on their priority. When priorities are equal, it uses
// PodInfo.timestamp.
func activeQComp(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.PodInfo)
pInfo2 := podInfo2.(*framework.PodInfo)
prio1 := util.GetPodPriority(pInfo1.Pod)
prio2 := util.GetPodPriority(pInfo2.Pod)
// First, the priority is compared, and then, according to the creation time of the pod, the higher priority the pod is, the more priority it is to be scheduled
// The earlier the pod is created, the more preferred it is
return (prio1 > prio2) || (prio1 == prio2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}podbackOffQ
The podBackOffQ mainly stores backOff mechanisms that delay the time to wait for dispatch in cases where dispatch fails in multiple schedulingCycle s
// podBackoffQ is a heap ordered by backoff expiry. Pods which have completed backoff
// are popped from this heap before the scheduler looks at activeQ
podBackoffQ *util.HeappodBackOff
As mentioned above, the podBackOffQ queue does not store specific information about the backOff of the pod, such as the counter of the backoff, the time of the last update, etc. The podBackOff queue acts like a scoreboard to record this information for use by podBackOffQ
// podBackoff tracks backoff for pods attempting to be rescheduled
podBackoff *PodBackoffMap
// PodBackoffMap is a structure that stores backoff related information for pods
type PodBackoffMap struct {
// lock for performing actions on this PodBackoffMap
lock sync.RWMutex
// initial backoff duration
initialDuration time.Duration // The current value is 1 second
// maximal backoff duration
maxDuration time.Duration // Current value is 1 minute
// map for pod -> number of attempts for this pod
podAttempts map[ktypes.NamespacedName]int
// map for pod -> lastUpdateTime pod of this pod
podLastUpdateTime map[ktypes.NamespacedName]time.Time
}
unschedulableQ
Store queues for pod s that have attempted to schedule but are not currently clustered with sufficient resources
moveRequestCycle
When a pod in unschedulableQ is attempted to be transferred to activeQ because of changes in cluster resources, moveRequestCycle is the schedulingCycle that stores resource changes
func (p *PriorityQueue) MoveAllToActiveQueue() {
// Omit other code
p.moveRequestCycle = p.schedulingCycle
}schedulingCycle
schedulingCycle is an incremental sequence that increments every time a pod pop s out of activeQ
func (p *PriorityQueue) Pop() (*v1.Pod, error) {
//Omit Others
p.schedulingCycle++
}Concurrent Active Queue
Concurrently get pod from active queue
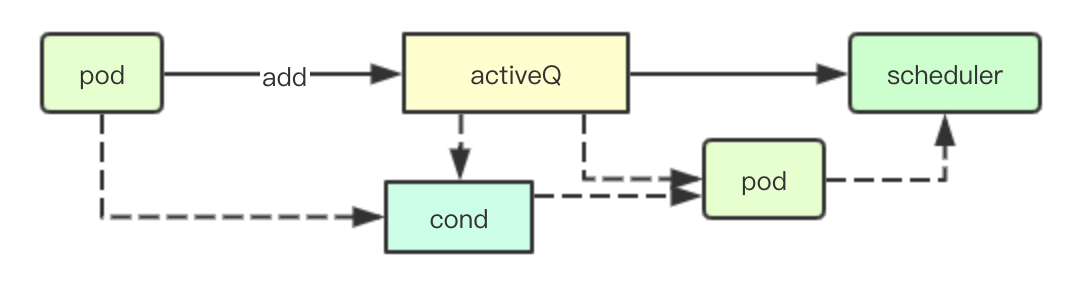
SchedulingQueue provides a Pop interface to get pod s waiting to be dispatched from the current cluster, and its internal implementation is mainly achieved by cond and activeQ above
When there is no dispatchable pod in the current queue, it is blocked by cond.Wait, and then notified by cond.Broadcast when pod is added in forgotten activeQ
func (p *PriorityQueue) Pop() (*v1.Pod, error) {
p.lock.Lock()
defer p.lock.Unlock()
for p.activeQ.Len() == 0 {
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
//
p.cond.Wait()
}
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
pInfo := obj.(*framework.PodInfo)
p.schedulingCycle++
return pInfo.Pod, err
}Join dispatch pod to active queue
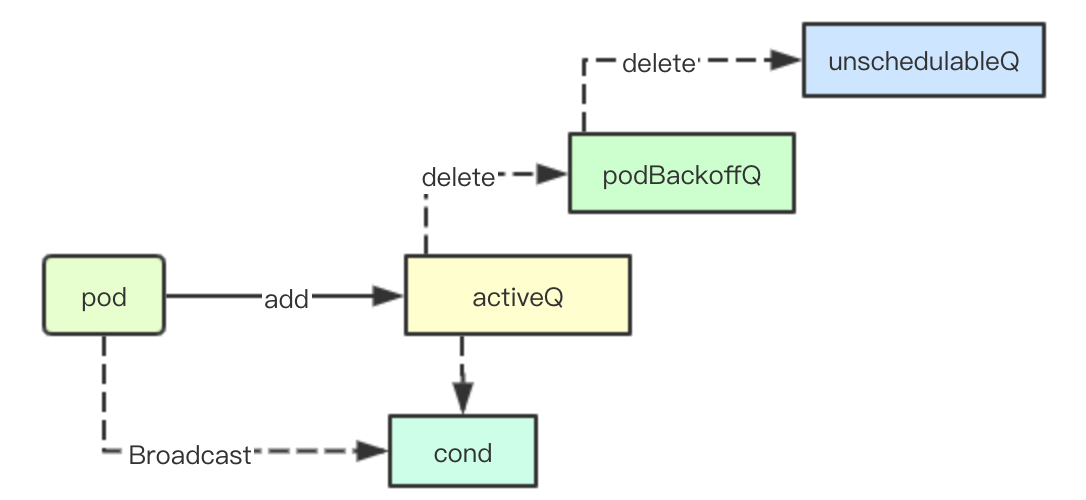
When a pod joins the active queue, in addition to joining the priority queue of activeQ, it also needs to remove the current pod from podBackoffQ and unschedulableQ, and finally block the latest pod acquisition by the scheudler of the Pop operation with broadcast notifications
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
pInfo := p.newPodInfo(pod)
// Join ActeQ
if err := p.activeQ.Add(pInfo); err != nil {
klog.Errorf("Error adding pod %v/%v to the scheduling queue: %v", pod.Namespace, pod.Name, err)
return err
}
// Remove from unschedulableQ
if p.unschedulableQ.get(pod) != nil {
klog.Errorf("Error: pod %v/%v is already in the unschedulable queue.", pod.Namespace, pod.Name)
p.unschedulableQ.delete(pod)
}
// Delete pod from backoffQ if it is backing off
// Remove from podBackoffQ
if err := p.podBackoffQ.Delete(pInfo); err == nil {
klog.Errorf("Error: pod %v/%v is already in the podBackoff queue.", pod.Namespace, pod.Name)
}
// Store pod s and nominated node s
p.nominatedPods.add(pod, "")
p.cond.Broadcast()
return nil
}SchdulingCycle and moveRequestCycle
Timely Retry of Undispatched Queues
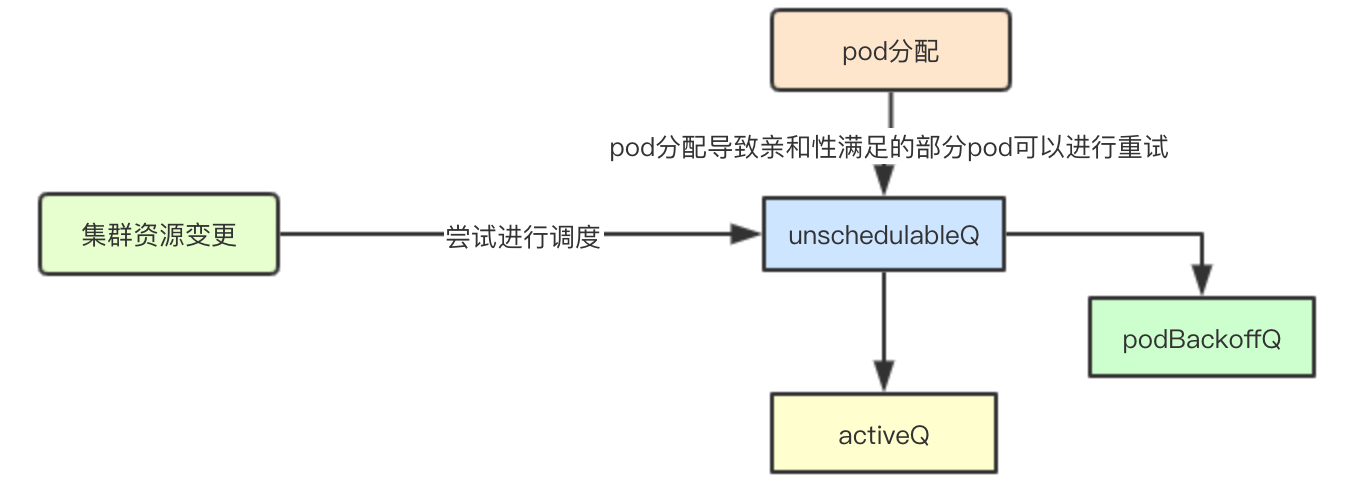
The main factors causing the schedulingCyclye change of the scheduling cycle are as follows:
1. When the cluster resources change, such as adding new resources such as pv, node, etc., the pod in unschedulableQ can be put into activeQ or podBackoffQ to schedule in time because the resources do not meet the needs.
2. The pod is successfully dispatched: previously it was put into unschedulableQ due to lack of affinity, so you can try it instead of waiting for a timeout before adding it
MoveAllToActiveQueue and movePodsToActiveQueue will be triggered to change moveRequestCycle to equal schedulingCycle in either case
Impact on retry mechanism
When a pod currently fails, there are two choices: one is to join podBackoffQ, the other is to join unschedulableQ. How do you choose which queue to enter for a failed pod?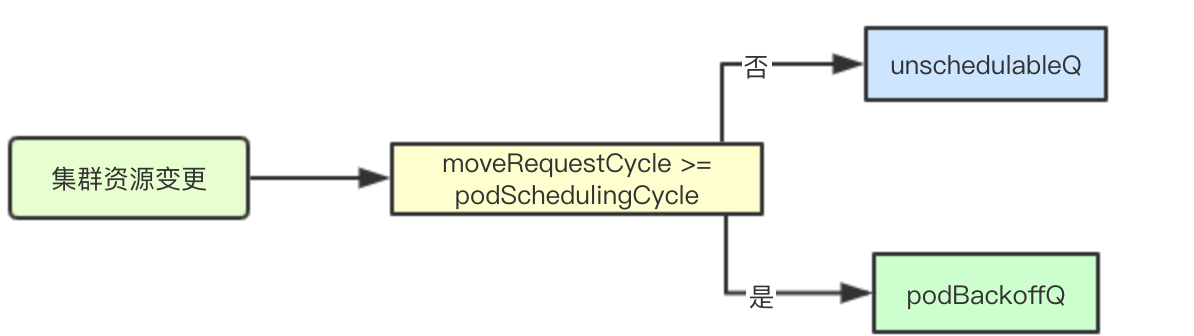
When will moveRequestCycle be greater than or equal to podScheduling Cycle when combined with the above moveRequestCycle change timing?The answer is that there have been changes to cluster resources in the current cluster or the pod has been successfully allocated. At this time, if we retry a failed schedule, we may succeed because the cluster resources may have changed and new resources may have joined
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)
}
} else {
p.unschedulableQ.addOrUpdate(pInfo)
}Injection of failure handling logic
Injection Scheduling Failure Logical Processing
A failure handler is injected through MakeDefaultErrorFunc when a scheduler Config is created and called during scheduler scheduling
kubernetes/pkg/scheduler/factory/factory.go: MakeDefaultErrorFunc will reposition pod s not scheduled to any node back into the priority queue
podSchedulingCycle := podQueue.SchedulingCycle()
// Omit non-core code
if len(pod.Spec.NodeName) == 0 {
//Re-Play Queue
if err := podQueue.AddUnschedulableIfNotPresent(pod, podSchedulingCycle); err != nil {
klog.Error(err)
}
}Callbacks for failure handling
When a dispatch pod fails, the scheduler also calls sched.Error, which is the failure handling logic injected above, to rejoin the pod node of the dispatch failure unassigned node to the queue clock
kubernetes/pkg/scheduler/scheduler.go
func (sched *Scheduler) recordSchedulingFailure(pod *v1.Pod, err error, reason string, message string) {
// Error Callback
sched.Error(pod, err)
sched.Recorder.Eventf(pod, nil, v1.EventTypeWarning, "FailedScheduling", "Scheduling", message)
if err := sched.PodConditionUpdater.Update(pod, &v1.PodCondition{
Type: v1.PodScheduled,
Status: v1.ConditionFalse,
Reason: reason,
Message: err.Error(),
}); err != nil {
klog.Errorf("Error updating the condition of the pod %s/%s: %v", pod.Namespace, pod.Name, err)
}
}PodBackoffMap
PodBackoffMap is used to store the last failed update time and number of implementations of a pod, from which the backoffTime of a pod is calculated
Data structure design
type PodBackoffMap struct {
// lock for performing actions on this PodBackoffMap
lock sync.RWMutex
// Initialize backoff duration
initialDuration time.Duration // The current value is 1 second
// Maximum backoff duration
maxDuration time.Duration // Current value is 1 minute
// Record the number of pod retries
podAttempts map[ktypes.NamespacedName]int
// Record last update time of pod
podLastUpdateTime map[ktypes.NamespacedName]time.Time
}backoffTime calculation algorithm
Set initialDuration and maxDuration back at initialization time. In the current version, 1s and 10s respectively, that is, the pod in backoffQ will rejoin activeQ for up to 10s (waiting for a timer task to assist)
Each time a callback fails, the BackoffPod method is used to update the count. When the backoffTime of a pod is acquired later, only the number of times is needed to calculate the algorithm in conjunction with the initialDuration, and the end time of the backoffTime of a pod is obtained in conjunction with the last update time of the pod.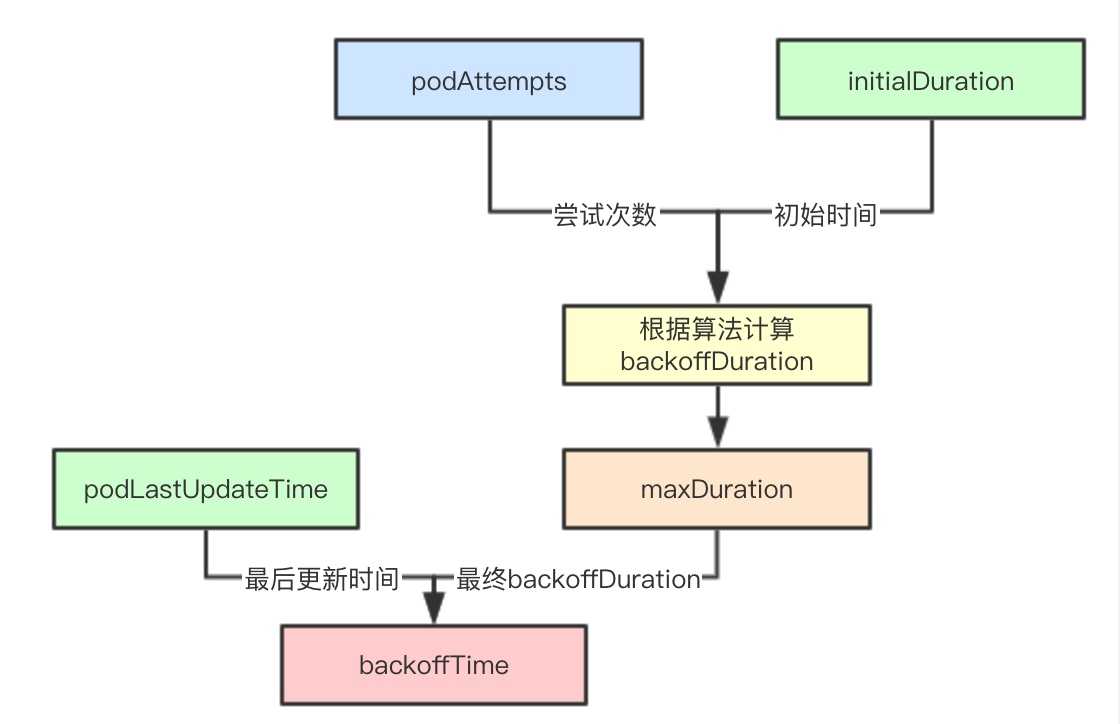
backoffDuration calculation
In fact, the final calculation is simply the N-th power of 2
func (pbm *PodBackoffMap) calculateBackoffDuration(nsPod ktypes.NamespacedName) time.Duration {
// initialDuration is 1s
backoffDuration := pbm.initialDuration
if _, found := pbm.podAttempts[nsPod]; found {
// Number of failed attempts to include pod in podAttempts
for i := 1; i < pbm.podAttempts[nsPod]; i++ {
backoffDuration = backoffDuration * 2
// Maximum 10s
if backoffDuration > pbm.maxDuration {
return pbm.maxDuration
}
}
}
return backoffDuration
}podBackoffQ
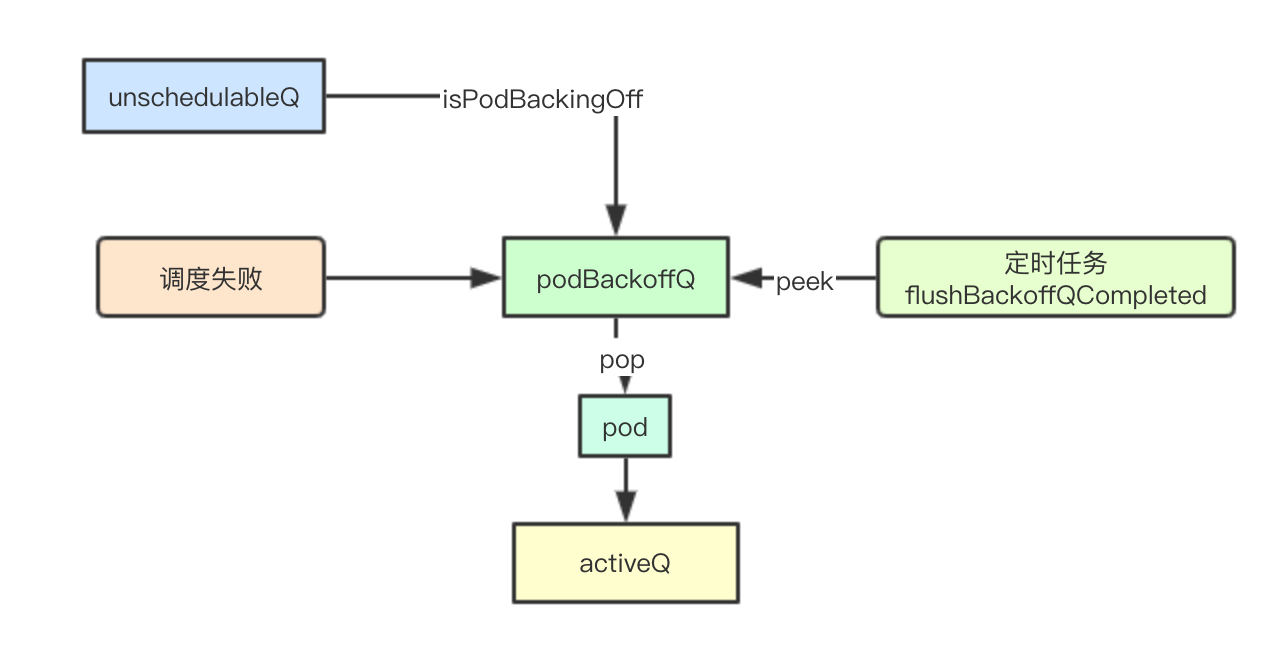
Priority Function
The podBackoffQ actually prioritizes according to the backoffTime of the pod, so the header of the podBackoffQ queue is the last pod to expire
func (p *PriorityQueue) podsCompareBackoffCompleted(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.PodInfo)
pInfo2 := podInfo2.(*framework.PodInfo)
bo1, _ := p.podBackoff.GetBackoffTime(nsNameForPod(pInfo1.Pod))
bo2, _ := p.podBackoff.GetBackoffTime(nsNameForPod(pInfo2.Pod))
return bo1.Before(bo2)
}Scheduling failure joined podBackoffQ
Join podBackfoffQ if the schedule fails and moveRequestCycle=podSchedulingCycle
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pod *v1.Pod, podSchedulingCycle int64) error {
// Omit checking code
// Update backoff information for pod
p.backoffPod(pod)
// moveRequestCycle adds a pod from a dispatch cycle with unscheduledQ greater than pod if the pod's dispatch cycle is less than the current dispatch cycle
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)
}
} else {
p.unschedulableQ.addOrUpdate(pInfo)
}
p.nominatedPods.add(pod, "")
return nil
}Migrate from unschedulableQ
When cluster resources change as described earlier, an attempt to transfer pods from unschedulabelQ is triggered, and if it is found that the current pod has not reached backoffTime, it is added to podBackoffQ
if p.isPodBackingOff(pod) {
if err := p.podBackoffQ.Add(pInfo); err != nil {
klog.Errorf("Error adding pod %v to the backoff queue: %v", pod.Name, err)
addErrorPods = append(addErrorPods, pInfo)
}
} else {
if err := p.activeQ.Add(pInfo); err != nil {
klog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err)
addErrorPods = append(addErrorPods, pInfo)
}
}podBackoffQ Timing Transfer
When PriorityQueue is created, one of the two timer tasks is the transfer after the pod in backoffQ expires, which is attempted every second
func (p *PriorityQueue) run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}Since it's a heap result, all you need to do is take the top element of the heap, determine if it's due, and pop it in to activeQ
func (p *PriorityQueue) flushBackoffQCompleted() {
p.lock.Lock()
defer p.lock.Unlock()
for {
// Get heap top elements
rawPodInfo := p.podBackoffQ.Peek()
if rawPodInfo == nil {
return
}
pod := rawPodInfo.(*framework.PodInfo).Pod
// Get due time
boTime, found := p.podBackoff.GetBackoffTime(nsNameForPod(pod))
if !found {
// If you are no longer in podBackoff, pop out and put into activeQ
klog.Errorf("Unable to find backoff value for pod %v in backoffQ", nsNameForPod(pod))
p.podBackoffQ.Pop()
p.activeQ.Add(rawPodInfo)
defer p.cond.Broadcast()
continue
}
// Not timed out
if boTime.After(p.clock.Now()) {
return
}
// pop out on timeout
_, err := p.podBackoffQ.Pop()
if err != nil {
klog.Errorf("Unable to pop pod %v from backoffQ despite backoff completion.", nsNameForPod(pod))
return
}
// Join ActeQ
p.activeQ.Add(rawPodInfo)
defer p.cond.Broadcast()
}
}unschedulableQ
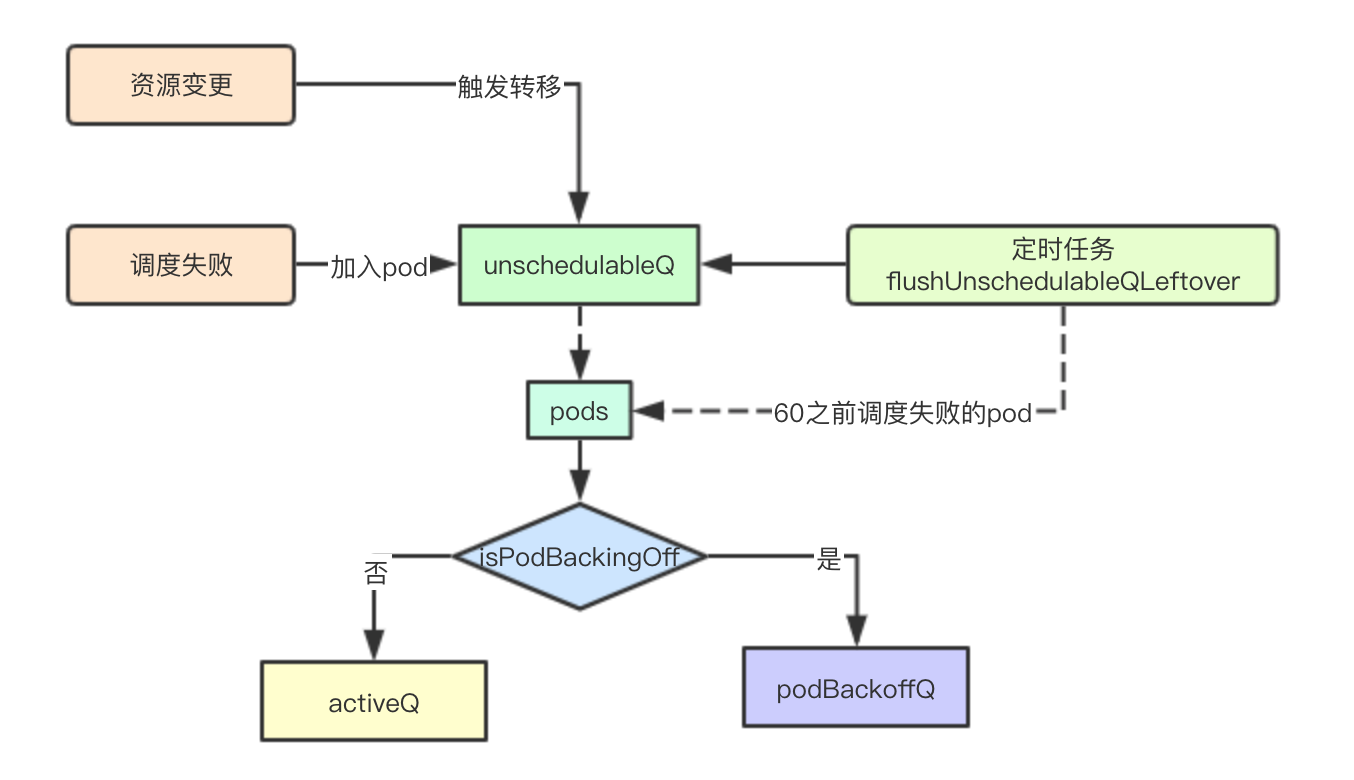
Scheduling Failure
After a schedule failure, join unschedulable if the current cluster resources have not changed, for the reason stated above
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pod *v1.Pod, podSchedulingCycle int64) error {
// Omit checking code
// Update backoff information for pod
p.backoffPod(pod)
// moveRequestCycle adds a pod from a dispatch cycle with unscheduledQ greater than pod if the pod's dispatch cycle is less than the current dispatch cycle
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)
}
} else {
p.unschedulableQ.addOrUpdate(pInfo)
}
p.nominatedPods.add(pod, "")
return nil
}Timed transfer of tasks
Timed tasks execute every 30 seconds
func (p *PriorityQueue) run() {
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}Logic is very simple. If the current time-pod's last schedule time is greater than 60s, it is rescheduled and transferred to podBackoffQ or activeQ
func (p *PriorityQueue) flushUnschedulableQLeftover() {
p.lock.Lock()
defer p.lock.Unlock()
var podsToMove []*framework.PodInfo
currentTime := p.clock.Now()
for _, pInfo := range p.unschedulableQ.podInfoMap {
lastScheduleTime := pInfo.Timestamp
// Join podsToMove if the pod is not scheduled for 1 minute
if currentTime.Sub(lastScheduleTime) > unschedulableQTimeInterval {
podsToMove = append(podsToMove, pInfo)
}
}
if len(podsToMove) > 0 {
// podsToMove moves these pod s to activeQ
p.movePodsToActiveQueue(podsToMove)
}
}Scheduling Queue Summary
Summary of Data Flow Design
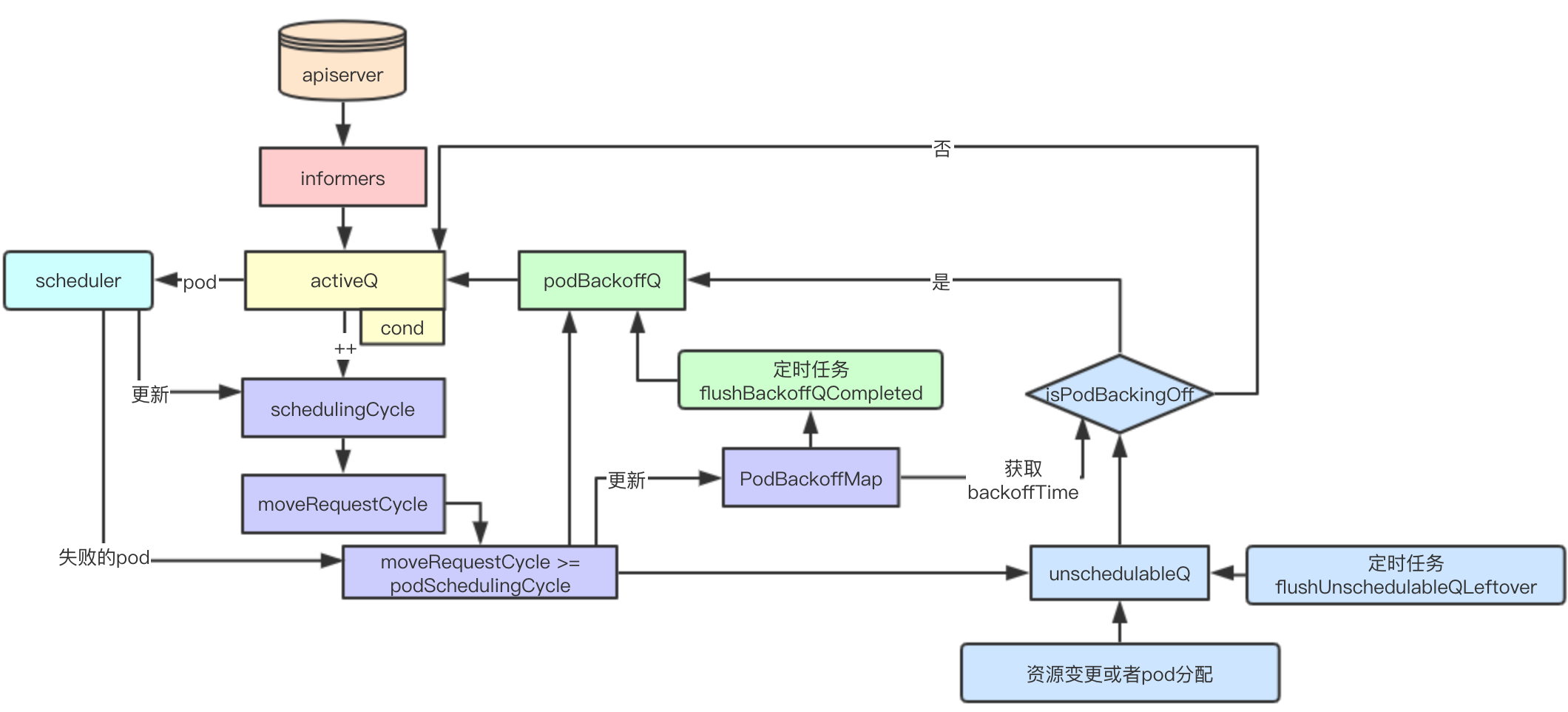
3.1.1 Triple Queues and Background Timer Tasks
The three queues are designed to be stored separately: active queue, bakcoff queue, non-dispatchable queue, where backoff incrementally increases the retry time (up to 10s) based on the failure of the task and unschedulableQ queue is delayed by 60s
The backoffQ queue and unschedulableQ queue are retried by background timer task to join activeQ to speed up the completion of pod's failed retry scheduling
cycle and Priority Scheduling
Two cycle s, schedulingCycle and moveRequestCycle, are essentially designed to speed up the retry scheduling of failed tasks. When cluster resources change, retry immediately and pod s with higher priority and affinity for failures may be scheduled first.
Thread-safe pop with lock and cond
Internally, thread security is guaranteed through lock, and blocking wait is achieved through cond, thereby blocking scheduler worker notifications
Today's analysis is here, in fact, referring to this implementation, we can also abstract some design ideas from it to implement our own priority, fast retry, highly available task queue. First of all, the next component of analysis is Scheduler Cache. Interested in this analysis, you can add me to WeChat to communicate and learn together. After all, the three stinky cobblers can't count on Zhu Geliang.
k8s source reading e-book address: https://www.yuque.com/baxiaoshi/tyado3