Some time ago, fengjunhao's "parasites" won many awards at the Oscars. I also like watching movies. After watching the movie, I was curious about other people's opinions on the movie. So I used R to climb some Douban movie reviews, and jieba got the word cloud to understand. But if I didn't log in to Douban to climb directly to the movie reviews, I could only get ten short reviews. I think that's the amount of data In order to be a little less, I sorted out the method of python's simulated Login to Douban, batch crawling data, and making special style word cloud.
###1, Python library used
import os ##Provides access to operating system services import re ##regular expression import time ##Standard library of processing time import random ##Use random number standard library import requests ##Login import numpy as np ##Scientific computing library is a powerful N-dimensional array object, ndarray import jieba ##jieba Thesaurus from PIL import Image ##python image library, python3 multi-purpose Pilot Library import matplotlib.pyplot as plt ##Mapping plt.switch_backend('tkagg') from wordcloud import WordCloud, ImageColorGenerator##Word cloud production
I have to be familiar with the use of each library for a long time, and I am only at the entry level
###2, Thinking
1. Simulated Login Douban
2. Take a page of reviews
3. Get movie reviews in batch
4. Making common words cloud
5. Create the word cloud of picture shape background
###3, Code implementation
1. Simulated Login Douban
First of all, we need to analyze the login page of Douban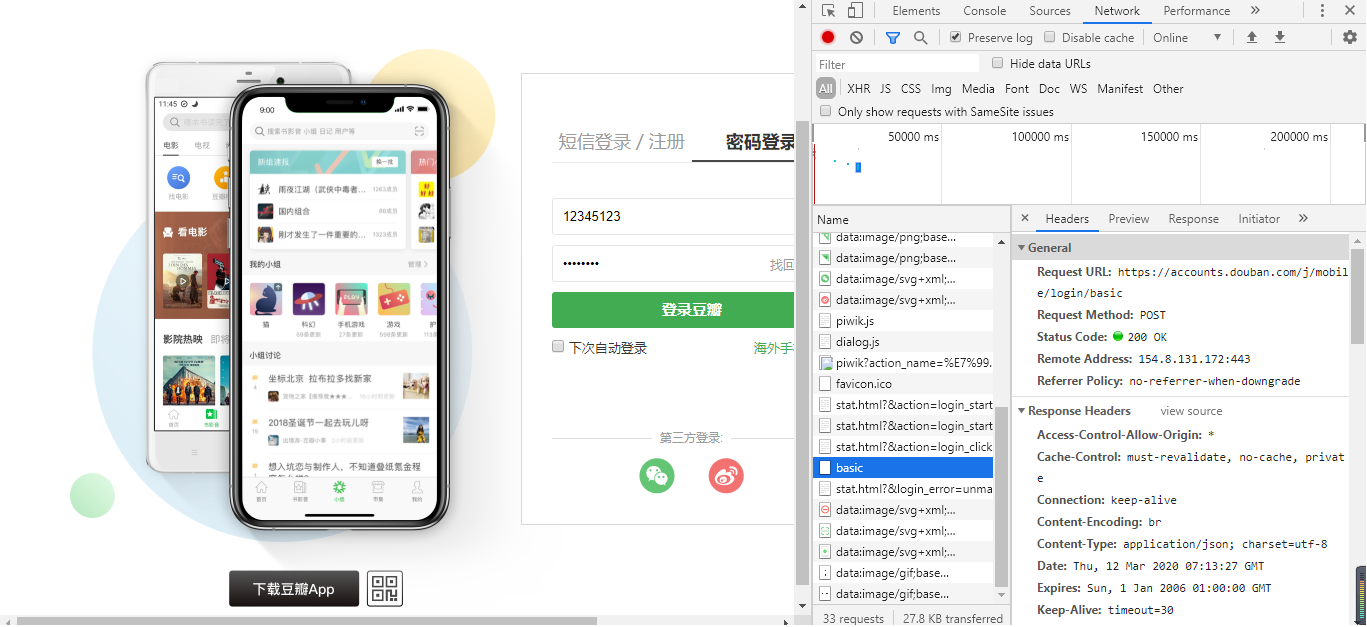
Click the right mouse button to enter "check", enter the wrong login information in the login window, and enter the Network named basic. Here are many useful information, such as
Request URL, user agent, accept encoding, etc
You also need to look at the parameters carried when you request to log in, and pull down the debugging window to view Form Data.
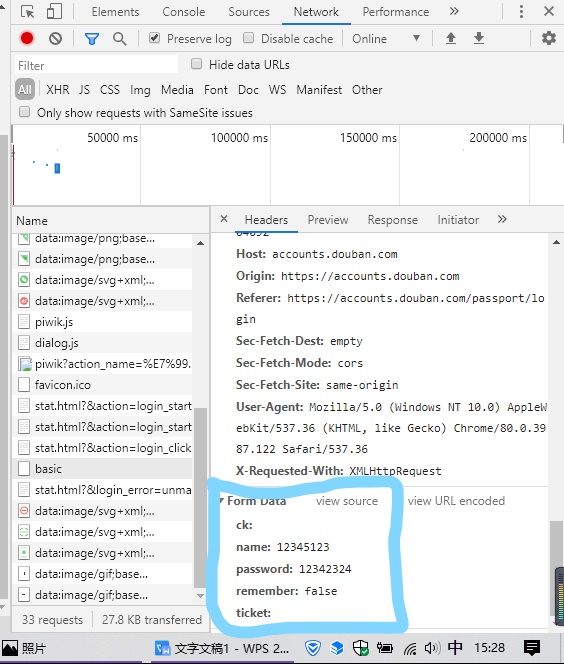
Code simulation login:
# Generate Session object to save cookies s = requests.Session() # Review data save file COMMENTS_FILE_PATH = 'douban_comments.txt' # Word cloud font WC_FONT_PATH = 'C:/Windows/Fonts/SIMLI.TTF' def login_douban(): """ //Log bean :return: """ # Login URL login_url = 'https://accounts.douban.com/j/mobile/login/basic' # Request header headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36', 'Host': 'accounts.douban.com', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9', 'Referer': 'https://accounts.douban.com/passport/login?source=main', 'Connection': 'Keep-Alive'} # Pass user name and password data = {'name': '12345125',##Change your login name here 'password': '12342324',##Here is your correct login password 'remember': 'false'} try: r = s.post(login_url, headers=headers, data=data) r.raise_for_status() except: print('Login request failed') return 0 print(r.text) return 1
2. Take a page of reviews
Enter the short review page of the movie, analyze the web page, get the URL of the web page, then analyze the source code of the web page, check which tag the movie review is in and what features it has, and then use regular expression to match the desired tag content.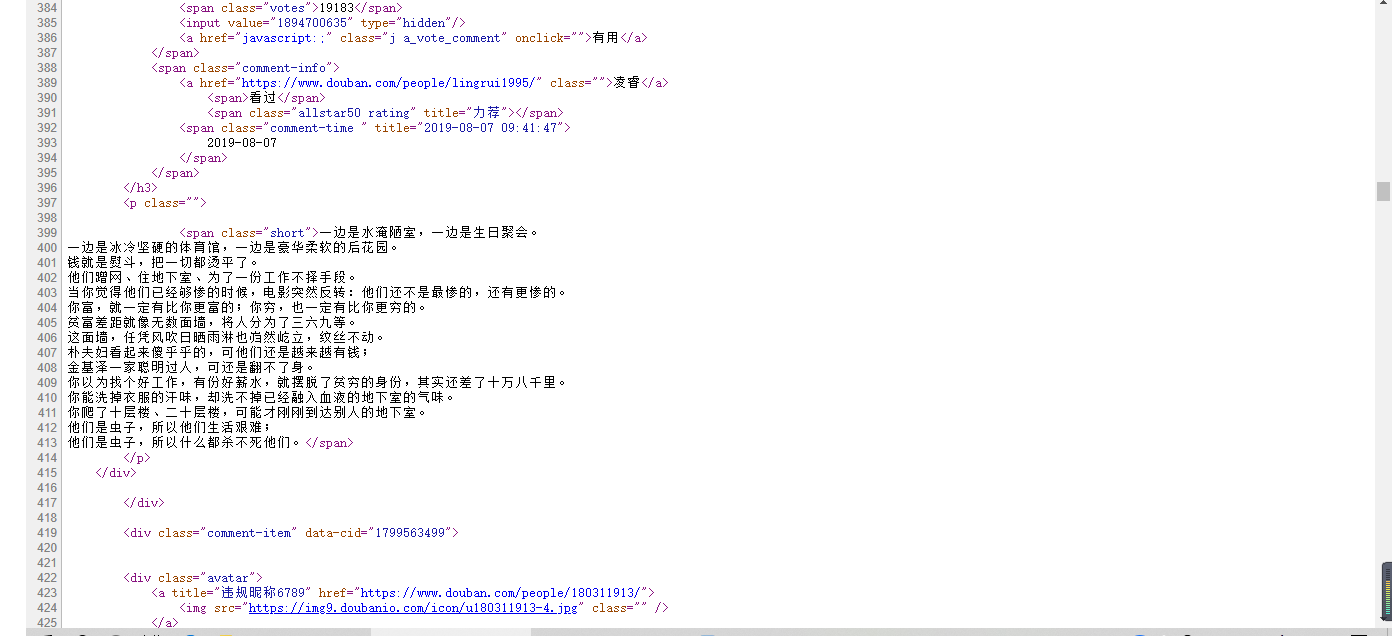
It can be found that the film reviews are all in the label of.
Code:
def spider_comment(page=0): """ //Crawl a page of reviews :param page: Paging parameters :return: """ print('Start crawling%d page' % int(page)) start = int(page * 20) comment_url = 'https://movie.douban.com/subject/27010768/comments?start=%d&limit=20&sort=new_score&status=P' % start # Request header headers = {'user-agent': 'Mozilla/5.0'} try: r = s.get(comment_url, headers=headers)#s.get() r.raise_for_status() except: print('The first%d Page crawl request failed' % page) return 0 # Extract movie reviews using regular comments = re.findall('<span class="short">(.*)</span>', r.text)##Regular Expression Matching if not comments: return 0 # write file with open(COMMENTS_FILE_PATH, 'a+', encoding=r.encoding) as file: file.writelines('\n'.join(comments)) return 1
3. Get movie reviews in batch
In the short comment url of Douban, the start parameter is the parameter to control paging.
def batch_spider_comment(): """ //Film review of batch crawling for Douban :return: """ # Clear previous data before writing data if os.path.exists(COMMENTS_FILE_PATH): os.remove(COMMENTS_FILE_PATH)##If the system already has this file, delete it page = 0 while spider_comment(page): page += 1 # Simulate user browsing and set a crawler interval to prevent ip from being blocked time.sleep(random.random() * 3) print('Crawl finish') if login_douban():##If the login is successful, it will be crawled in batch batch_spider_comment()
If you log in successfully, you will perform batch crawling. Only 25 pages of short comments can be viewed on Douban webpage

4. Making common words cloud
After all the reviews are obtained, you can use jieba to segment words and wordcloud to create word cloud. The most common word cloud can be made in this way:
####Making word clouds f = open(COMMENTS_FILE_PATH,'r',encoding='UTF-8').read() wordlist = jieba.cut(f, cut_all=True) wl = " ".join(wordlist) # List of data cleaning words stop_words = ['Namely', 'No', 'however', 'still', 'just', 'such', 'this', 'One','everything','A field','One part','This part', 'If', 'such','Think','What', 'Film', 'No,'] # Set some configuration of word cloud, such as font, background color, word cloud shape and size wc = WordCloud(background_color="white", scale=4,max_words=300, max_font_size=50, random_state=42, stopwords=stop_words, font_path=WC_FONT_PATH) # Generative word cloud wc.generate(wl) # If you only set mask, you will get a word cloud with image shape plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.show()

5. Create the word cloud of picture shape background
It's common to be able to make ordinary word clouds. We can also make word clouds with picture shape and background, and the color of words is the same as that of pictures.
##Generate word cloud of picture shape background def GetWordCloud(): path_img = "C://Users/Administrator/Desktop/Blonde-girl.jpg"##Picture path f = open(COMMENTS_FILE_PATH,'r',encoding='UTF-8').read() wordlist = jieba.cut(f, cut_all=True) wl = " ".join(wordlist) background_image = np.array(Image.open(path_img))##Conversion between Image object and array # If you don't use word segmentation, you can't directly generate the correct Chinese word cloud. If you are interested in it, you can check it. There are many word segmentation modes # #The Python join() method is used to connect elements in a sequence with the specified character to generate a new string. # List of data cleaning words stop_words = ['Namely', 'No', 'however', 'still', 'just', 'such', 'this', 'One','everything','A field','One part','This part', 'If', 'such','Think','What', 'Film', 'No,'] # Set some configuration of word cloud, such as font, background color, word cloud shape and size wc = WordCloud(background_color="white", scale=4,max_words=300,##Max ABCD words default 200 max_font_size=50, random_state=42, stopwords=stop_words, font_path=WC_FONT_PATH,mask= background_image) # Generative word cloud wc.generate(wl) # If you only set mask, you will get a word cloud with image shape # Generate color values image_colors = ImageColorGenerator(background_image) # The following code shows the display picture plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear") plt.axis("off") plt.show() if __name__ == '__main__': GetWordCloud()


At the end of the above, we simulated web page login, extracted reviews from web pages, crawled in batches, and created word cloud and special shape word cloud.
The whole process will roughly understand the structure of the web page, the idea of crawler, and the utility of the requests library. Compared with R, python crawler is indeed more beautiful and convenient. The regular expression extraction part of the movie review is also very direct. Data cleaning, word cloud production, is also very common and easy to understand. Python is indeed one of the tools that have to learn.

