1. Introduction to zookeeper
Zookeeper is a distributed service framework, which used to be a sub project of Apache Hadoop. Now it is an independent top-level project of Apache. It is mainly used to solve some data management problems often encountered in distributed applications, such as unified naming service, state synchronization service, cluster management, distributed application configuration item management, etc. For questions about distribution, please refer to the previous blog: Distributed system problems and Solutions
2. Design objectives
- ZooKeeper is simple. ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchical namespace, which is organized like a standard file system. Namespaces consist of data registers (known as znode in ZooKeeper's view) that are similar to files and directories. Unlike a typical file system designed for storage, ZooKeeper data is kept in memory, which means ZooKeeper can achieve high throughput and low latency.
ZooKeeper features include high performance, high availability and strict order. The performance aspect of ZooKeeper means that it can be used in large distributed systems. The reliability aspect makes it not a single point of failure. Strict ordering means that complex synchronization primitives can be implemented on the client side.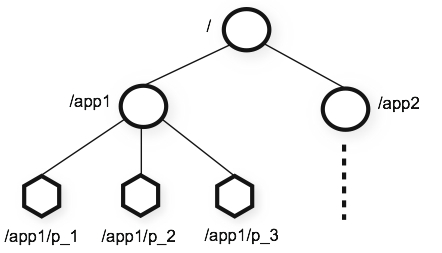
- ZooKeeper can be copied. Like the distributed processes it coordinates, ZooKeeper itself can replicate on a set of hosts called collections. The servers that make up the ZooKeeper service must know each other. They maintain state images in memory, as well as transaction logs and snapshots in persistent storage. The ZooKeeper service will be available as long as most servers are available. The client connects to a single ZooKeeper server. The client maintains a TCP connection through which requests are sent, responses are obtained, monitoring events are obtained, and heartbeat is sent. If the TCP connection to the server is lost, the client will connect to another server.
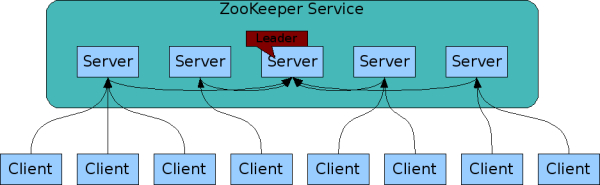
- ZooKeeper is in order. ZooKeeper marks each update with a number that reflects the order of all ZooKeeper transactions. Subsequent operations can use this command to achieve a higher level of abstraction, such as synchronization primitives.
- ZooKeeper is fast. It's particularly fast in a read based workload. The ZooKeeper application runs on thousands of computers and performs best at a rate of about 10:1 when reading is more common than writing.
For more details, please refer to the official documents: http://zookeeper.apache.org/doc/r3.6.0/zookeeperOver.html
3. Zookeeper download and install
3.1 download
Download address: http://zookeeper.apache.org/releases.html , click the link to enter the interface, and you can directly select the latest version to download.
3.2 decompress to your own path
3.3 modify configuration
Enter the conf directory and copy a copy of zoo sample.cfg to zoo.cfg
# This time is used as the time interval between Zookeeper servers or between clients and servers to maintain the heartbeat, that is, each tick time interval will send a heartbeat, in milliseconds. tickTime=2000 # This configuration item is used to configure the maximum number of heartbeat time intervals that Zookeeper Leader can tolerate when accepting Follower's initial connection. If the Zookeeper Leader has not received the follow's return information after the time of more than 10 heartbeat (i.e. tickTime), then the follow connection fails. The total length of time is 10 * 2000 = 20 seconds initLimit=10 # This configuration item identifies the time length of sending messages, requests and replies between the Leader and Follower. The maximum time length cannot exceed how many ticktimes. The total time length is 5 * 2000 = 10 seconds syncLimit=5 # As the name implies, it is the directory in which Zookeeper saves data. By default, Zookeeper also saves the log files that write data in this directory. dataDir=/FreeofInstallation/apache-zookeeper-3.6.0-bin/data # This port is the port where the client connects to the zookeeper server. Zookeeper will listen to this port and accept the client's access request. clientPort=2181 #The limit of the number of connections between a single client and a single server is IP level. The default value is 60. If it is set to 0, then there is no limit. Please note that the scope of this restriction is only the limit of the number of connections between a single client machine and a single ZK server, not for the specified client IP, the connection number of ZK cluster, or the connection number of all clients for a single ZK. #maxClientCnxns=60 #This parameter is used with the following parameter, which specifies the number of files to keep. The default is to keep three, which is only available after 3.4. #autopurge.snapRetainCount=3 #In version 3.4.0 and later, ZK provides the function of automatically cleaning transaction logs and snapshot files. This parameter specifies the cleaning frequency in hours. You need to configure an integer of 1 or greater. The default value is 0, which means that the automatic cleaning function is not enabled. #autopurge.purgeInterval=1
3.4 start and stop services
Enter the bin directory of the zookeeper decompression package, or add the path to the environment variable, which is more convenient to use (for windows environment, please use the script with the suffix of. cmd).
Startup service
./zkServer.sh start #After the startup is successful, the following message will be displayed #Starting zookeeper ... STARTED
Out of Service
./zkServer.sh stop #Print information after stopping service #Stopping zookeeper ... STOPPED
Start client
./zkCli.sh #Successful connection will enter shell terminal #[zk: localhost:2181(CONNECTED) 0]
4. Build Zookeeper cluster on a single machine
4.1 build clusters
Enter the conf directory and copy three configuration files
cp zoo.cfg zoo-1.cfg cp zoo.cfg zoo-2.cfg cp zoo.cfg zoo-3.cfg
Create data directory
mkdir /FreeofInstallation/zookeeper/data-1 -p mkdir /FreeofInstallation/zookeeper/data-2 -p mkdir /FreeofInstallation/zookeeper/data-3 -p
Create log directory
mkdir /FreeofInstallation/zookeeper/log-1 -p mkdir /FreeofInstallation/zookeeper/log-2 -p mkdir /FreeofInstallation/zookeeper/log-3 -p
Create myid
echo "1" > /FreeofInstallation/zookeeper/data-1/myid echo "1" > /FreeofInstallation/zookeeper/data-2/myid echo "1" > /FreeofInstallation/zookeeper/data-3/myid
Modify three configuration files: zoo-1.cfg, zoo-2.cfg, zoo-3.cfg
tickTime=2000 initLimit=10 syncLimit=5 #Data path dataDir=/FreeofInstallation/zookeeper/data-1 #Log path dataLogDir=/FreeofInstallation/zookeeper/log-1 clientPort=2181 #x in server.x should be consistent with the content of the myid file just set; #The front port is used for synchronous data communication, and the back port is used for voting communication server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:3889
tickTime=2000 initLimit=10 syncLimit=5 #Data path dataDir=/FreeofInstallation/zookeeper/data-2 #Log path dataLogDir=/FreeofInstallation/zookeeper/log-2 clientPort=2182 #x in server.x should be consistent with the content of the myid file just set; #The front port is used for synchronous data communication, and the back port is used for voting communication server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:3889
tickTime=2000 initLimit=10 syncLimit=5 #Data path dataDir=/FreeofInstallation/zookeeper/data-3 #Log path dataLogDir=/FreeofInstallation/zookeeper/log-3 clientPort=2183 #x in server.x should be consistent with the content of the myid file just set; #The front port is used for synchronous data communication, and the back port is used for voting communication server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:3889
Start cluster
./zkServer.sh start ../conf/zoo-1.cfg ./zkServer.sh start ../conf/zoo-2.cfg ./zkServer.sh start ../conf/zoo-3.cfg
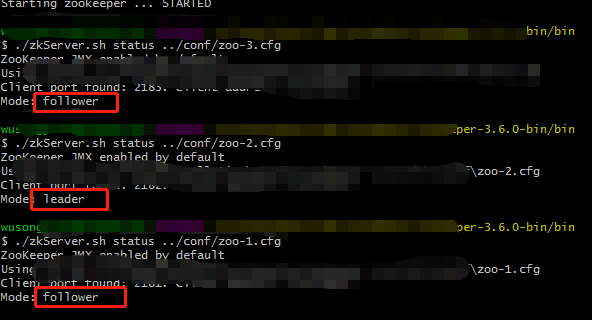
Verify the status of viewing nodes (2 is Leader, 1, 3 is Follower)
./zkServer.sh status../conf/zoo-1.cfg ./zkServer.sh status../conf/zoo-2.cfg ./zkServer.sh status../conf/zoo-3.cfg
Add Observer node
The other steps are the same, but the configuration file (zoo-ob.cfg) is a little different
tickTime=2000 initLimit=10 syncLimit=5 #Data path dataDir=/FreeofInstallation/zookeeper/data-4 #Log path dataLogDir=/FreeofInstallation/zookeeper/log-4 clientPort=2184 #Specify the observer node peerType=observer #x in server.x should be consistent with the content of the myid file just set; #The front port is used for synchronous data communication, and the back port is used for voting communication server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:3889 server.4=localhost:2886:3886:observer
Start the node directly in the same way and view the node status
4.2 roles in clusters
- leader is the core of zookeeper cluster, which is responsible for voting initiation and decision-making, processing client requests and final decisions.
- The follower handles the non transactional requests of the client, and forwards the transactional requests to the leader server to participate in the voting of the leader election at the same time.
- The observer observes the latest state changes in the zookeeper cluster and synchronizes these states to the observer server. It does not participate in the voting process. The working principle of the observer is basically the same as that of the follower role. The only difference between the observer role and the follower role is that the observer does not participate in any form of voting, including the voting of things request Proposal and leader election. In short, the observer server only provides non object request service, which usually improves the non object processing ability of the cluster without affecting the processing ability of the cluster.
- The servers for state synchronization between the learner and the leader are collectively referred to as the learner, and the above follower s and observer s are both learners.
5. What zookeeper can do
- Name Service
Mainly as a distributed naming service, it is easy to create a globally unique path by calling zk's create node api, which can be used as a name. These paht s are hierarchical and easy to understand and manage. - Configuration Management
Configuration management is very common in distributed application environment. For example, the same application system requires multiple servers to run, but some configuration items of the application system are the same. If you want to modify these same configuration items, you must modify the configuration of each Server running the system at the same time, which is very troublesome and prone to errors.
Configuration information like this can be managed by Zookeeper. The configuration information can be saved in a node of Zookeeper, and then all application machines that need to be modified will monitor the status of configuration information. Once the configuration information changes, each application machine will receive notification from Zookeeper, and then get new configuration information from Zookeeper and apply it to the system. - Group Membership
The cluster management of ZooKeeper mainly includes two aspects: monitoring whether there are machines exiting and joining the cluster, and selecting the master.
For the first point, the past practice is usually: the monitoring system regularly detects each machine through some means (such as ping), or each machine regularly reports "I am still alive" to the monitoring system. This method is feasible, but there are two obvious problems: 1) when the machines in the cluster change, there are more things involved in the modification. 2) There is a certain delay.
With zookeeper's two features, you can create another real-time monitoring system of cluster machine storage activity: all machines agree to create temporary directory nodes under the parent directory (such as / GroupMembers), and then listen to the change messages of the child nodes of the parent directory node. Once a machine is hung up, the connection between the machine and zookeeper is broken, the temporary directory node created by the machine is deleted, and all other machines are notified: if a directory is deleted, one machine is hung up. The addition of new machines is similar.
For the second point, in the distributed environment, the same business application is distributed on different machines. Some business logic (such as some time-consuming computing, network I/O processing) often only needs to be executed by one machine in the whole cluster, Other machines can share this result, which can greatly reduce repeated labor and improve performance, so this master election is the main problem encountered in this scenario. With the strong consistency of ZooKeeper, the global uniqueness of node creation can be guaranteed under the condition of high concurrency in distribution, that is, there are multiple client requests to create · / currentMaster node at the same time, and only one client request can be created successfully finally. With this feature, you can easily select clusters in a distributed environment. - Distributed lock
Distributed lock: distributed lock refers to protecting shared resources across processes, hosts and networks, realizing exclusive access and ensuring consistency in a distributed environment. The distributed lock mainly benefits from ZooKeeper to ensure the data consistency for us. That is to say, as long as users fully believe that every moment, the data of the same Znode on any node (a zk server) in the zk cluster must be the same.
For more detailed use scenarios and ideas, please refer to: ZooKeeper (2) what can ZooKeeper do?

