This article is based on OpenJDK 8 ~ 14
JEP 142 content
It is used to fill a cache row with one or some field s that need to be read and modified by multiple threads. At the same time, due to the way of filling cache rows before Java 8, which is cumbersome and not elegant enough, there may be different sizes of cache rows, so the @ contented annotation is introduced in this JEP.
What is cache row padding and False Sharing
CPU cache structure:
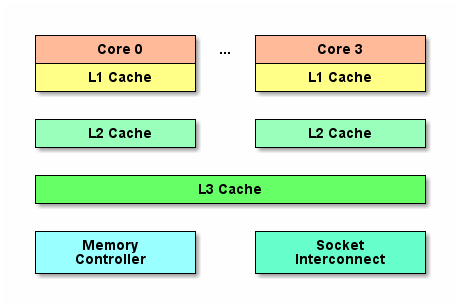
The CPU can only process the data in the register directly. To read from the above caches is to copy the data from these caches to the register. Just like the relationship between database and cache, there are L1 cache, L2 cache and L3 cache to cache the data in memory. The lower the level, the faster CPU access:
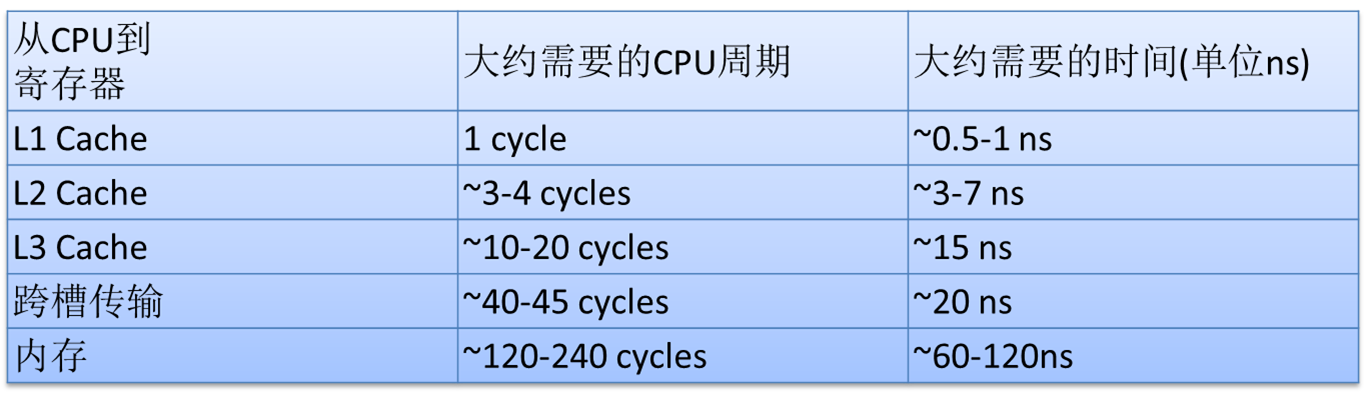
The above said reading is actually copying data from these caches to registers. The same is true for reading data from memory, copying data from memory to caches. But this copy is not a byte by byte copy, but a line by line copy, this line is the Cache Line. Cache Line: CPU cache does not cache memory data one by one, but takes one line of memory out of memory each time, which is called Cache Line. For my computer, the Cache Line length is 64 Bytes:
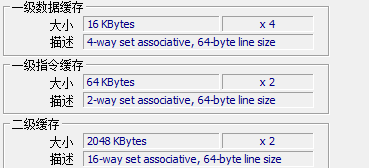
For Java, for example, suppose that X and y are two volatile long variables (8 Bytes in Java). They are adjacent to each other in memory and the total length is less than 64 Bytes. Then they are likely to be loaded in the same cache line at the same time. The function of volatile is that when a thread updates a variable declared by volatile, it will inform other CPUs to invalidate the cache, so that when other CPUs want to do update operations, they need to read data from memory again. Moreover, Java takes the cache row size into account and makes 8 Bytes alignment, so basically there will be no problem that the cache row load is not enough for the size of X or Y variables. When x and y are loaded into the same cache row, False Sharing will occur, resulting in performance degradation.
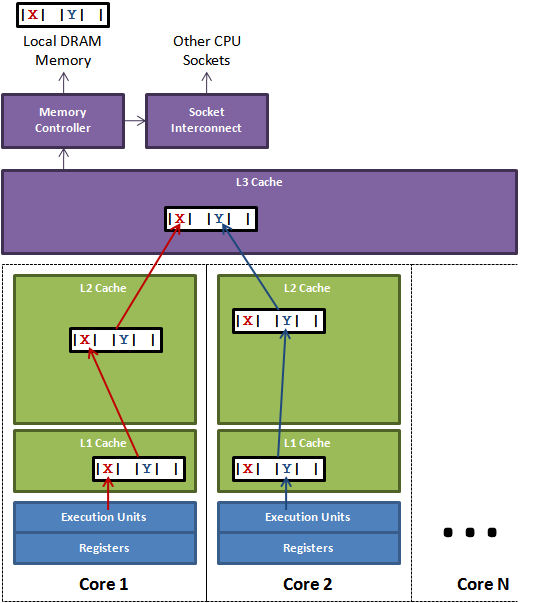
Suppose two threads access and modify the variables X and Y respectively. X and Y happen to be on the same cache line, and the two threads execute on different CPUs respectively. When each CPU updates X and Y respectively and brushes the cache line into memory, it is found that there is another modification to the data in the respective cache line. At this time, the cache line will be invalid and retrieved from L3. In this way, the efficiency of program execution is obviously reduced. In order to reduce this situation, in fact, to avoid X and Y in the same cache line, you can actively add some irrelevant variables to fill the cache line, such as adding some variables to the X object, so that it is as large as 64 bytes, just occupying a cache line. This operation is called cache row filling
General frame filling methods and scenarios requiring cache row filling
There are many frameworks that can be referred to. Here are two examples. One is the high-performance cache framework Disruptor, the other is the high-performance cache framework Caffeine. They are all aimed at the use of cache queues, one is ring queues, the other is ordinary queues. Use these two frameworks to understand the use of cache row padding.
An example of the application of interrupter to cache line filling
Disruptor structure:
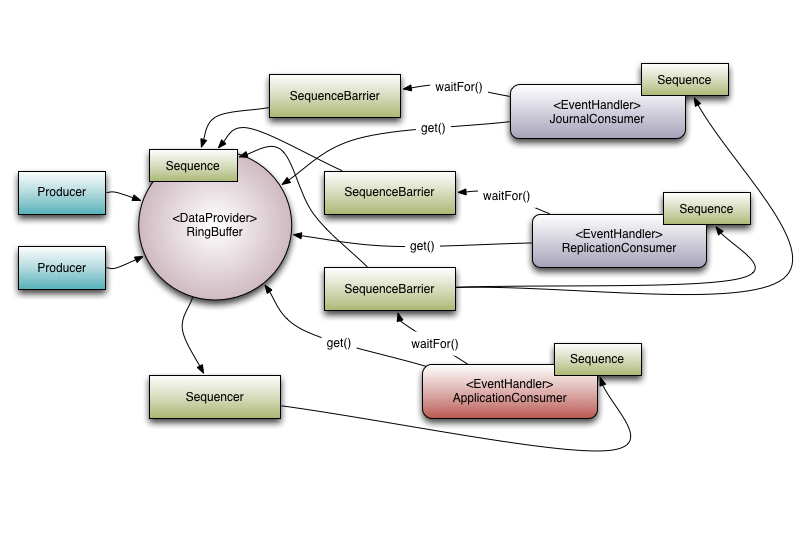
Each ringbuffer is a circular queue, and each element in the queue can be understood as a slot. During initialization, ringbuffer specifies the total size, which is the maximum number of slots the ring can hold. Here, the Disruptor specifies that the ringbuffer size must be the nth power of 2. Here we use a little skill, that is, to change the modulo into the operation of taking and calculating. In memory management, we often use the residual location operation. If we want to locate the ringbuffer, we usually use a number to take the remainder of the ringbuffer size. If the n-th power of 2 is redundant, it can be simplified as:
m % 2^n = m & ( 2^n - 1 )
Producer will fill the RingBuffer with elements. The process of filling elements is to first read the next Sequence from RingBuffer, then fill the data in the slot at the Sequence location, and then publish. The Sequence class, the value field, is the value stored in it. The modification of this value involves the problem of false sharing. Because:
- The adjacent Sequence memory address in the ring Buffer is also adjacent, because the underlying implementation is like an array.
- If there is no cache line filling, it is very possible to update the cache line corresponding to the thread of the current Sequence, and read out the values in other adjacent sequences, which causes other producer threads to need to read other sequences again. This is common in multi producer scenarios
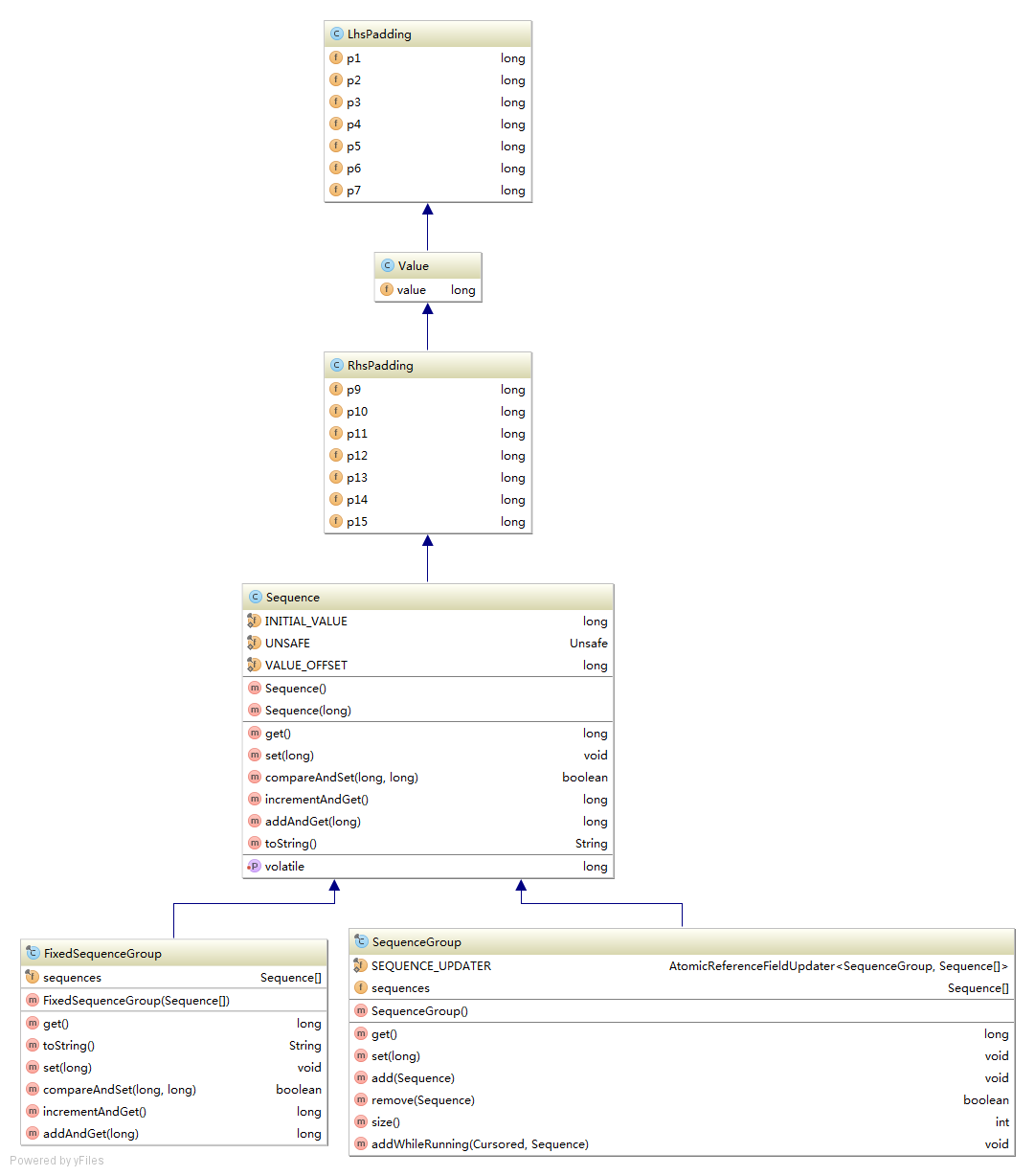
Therefore, you need to fill in the cache row for the value in this Sequence. How is it implemented in the code? You can see from the following class inheritance diagram:
An example of Caffeine application
Caffeine is a high-performance local caching framework with new Java 8 features. In Spring Boot 2.0 and above, caffeine has even been used as a standard caching framework. In most scenarios, you can replace guava cache as the preferred local cache scheme. At the same time, it also provides a tool class for the local cache task queue, for the task queue of multiple producers and one consumer. This class is the SingleConsumerQueue we are going to discuss now
When a queue involves concurrent modification, it is sure that the queue header and the queue tail are the places that need concurrent modification and access. As for value, because each time is a newly generated packing object, the memory will not be together and will not be considered. But the head and tail of the queue must be stored together. In order to improve efficiency, the cache line filling is used to avoid the head and tail of the queue in the same cache line:
final class SCQHeader { abstract static class PadHead<E> extends AbstractQueue<E> { long p00, p01, p02, p03, p04, p05, p06, p07; long p10, p11, p12, p13, p14, p15, p16; } /** Enforces a memory layout to avoid false sharing by padding the head node. */ abstract static class HeadRef<E> extends PadHead<E> { //Queue header @Nullable Node<E> head; } abstract static class PadHeadAndTail<E> extends HeadRef<E> { long p20, p21, p22, p23, p24, p25, p26, p27; long p30, p31, p32, p33, p34, p35, p36; } /** Enforces a memory layout to avoid false sharing by padding the tail node. */ abstract static class HeadAndTailRef<E> extends PadHeadAndTail<E> { static final long TAIL_OFFSET = UnsafeAccess.objectFieldOffset(HeadAndTailRef.class, "tail"); //Queue tail @Nullable volatile Node<E> tail; void lazySetTail(Node<E> next) { UnsafeAccess.UNSAFE.putOrderedObject(this, TAIL_OFFSET, next); } boolean casTail(Node<E> expect, Node<E> update) { return UnsafeAccess.UNSAFE.compareAndSwapObject(this, TAIL_OFFSET, expect, update); } } }
@Content annotation and JVM source code analysis
Through the above example, we find that every time we fill in the cache row, we need to generate a lot of useless fields, which will affect the code cleanliness. In the future, we may modify the field reordering rules, which will affect our upgrade. Therefore, in JEP 142, we provide @ contented annotation, which is also widely used in the source code of JDK library, for example Each field in the WorkQueue task queue of the ForkJoinPool needs to be filled in for high concurrent access. However, it should be noted that the @ contented annotation in the source code of the JDK library is effective, and the default startup parameters in your application are not effective. You need to add:
-XX:-RestrictContended
Use this parameter to turn off the restrictcontained status bit.
Considering that this is not elegant, Caffeine takes advantage of the new features of Java 8, but does not use this annotation.
@Contented annotation Code:
@Retention(RetentionPolicy.RUNTIME) @Target({ElementType.FIELD, ElementType.TYPE}) public @interface Contended { /** * The (optional) contention group tag. * This tag is only meaningful for field level annotations. * * @return contention group tag. */ String value() default ""; }
You can see that we can use this annotation on the class. Each field representing this class needs to be filled with a separate cache row to prevent false sharing with each other. It can also be used on a field, and only cache rows are filled for this field. When used on a field, you can specify a group. All fields under the same group will be filled to read as much as possible from the same cache row. For example, filed1 and field2 will be modified and accessed together, field 3 and field 4 will be modified and accessed together, so field 1 and field 2 will use the same group, field 3 and field 4 will use the same group, and there will be no false sharing between the read modification of field 1 and field 2 and the read modification of field 3 and field 4
Corresponding JDK source src/hotspot/share/classfile/classFileParser.cpp:
AnnotationCollector::ID AnnotationCollector::annotation_index(const ClassLoaderData* loader_data, const Symbol* name) { const vmSymbols::SID sid = vmSymbols::find_sid(name); // For system class loader and system anonymous class, set privileged to true const bool privileged = loader_data->is_the_null_class_loader_data() || loader_data->is_platform_class_loader_data() || loader_data->is_anonymous(); //... switch (sid) { //... case vmSymbols::VM_SYMBOL_ENUM_NAME(jdk_internal_vm_annotation_Contended_signature): { if (_location != _in_field && _location != _in_class) { break; } //If contented is not enabled, or restrictcontented, the JVM Boolean Flag (which corresponds to the startup parameter mentioned above) is true and is not a JDK internal class, the @ contented field will not be processed if (!EnableContended || (RestrictContended && !privileged)) { break; // honor privileges } return _jdk_internal_vm_annotation_Contended; //... } } } static void parse_annotations(const ConstantPool* const cp, const u1* buffer, int limit, AnnotationCollector* coll, ClassLoaderData* loader_data, TRAPS) { // Specify a contented group if (AnnotationCollector::_jdk_internal_vm_annotation_Contended == id) { //Default group index is 0 u2 group_index = 0; // default contended group if (count == 1 && s_size == (index - index0) // match size && s_tag_val == *(abase + tag_off) && member == vmSymbols::value_name()) { group_index = Bytes::get_Java_u2((address)abase + s_con_off); if (cp->symbol_at(group_index)->utf8_length() == 0) { group_index = 0; // default contended group } } coll->set_contended_group(group_index); } }
Through the compiled structure, compare @ contented with variable filling
Define a class:
@Data @AllArgsConstructor public class VolatileLong { @Contended("group1") private volatile long value1; @Contended("group2") private volatile long value2; @Contended("group3") private volatile long value3; @Contended("group4") private volatile long value4; }
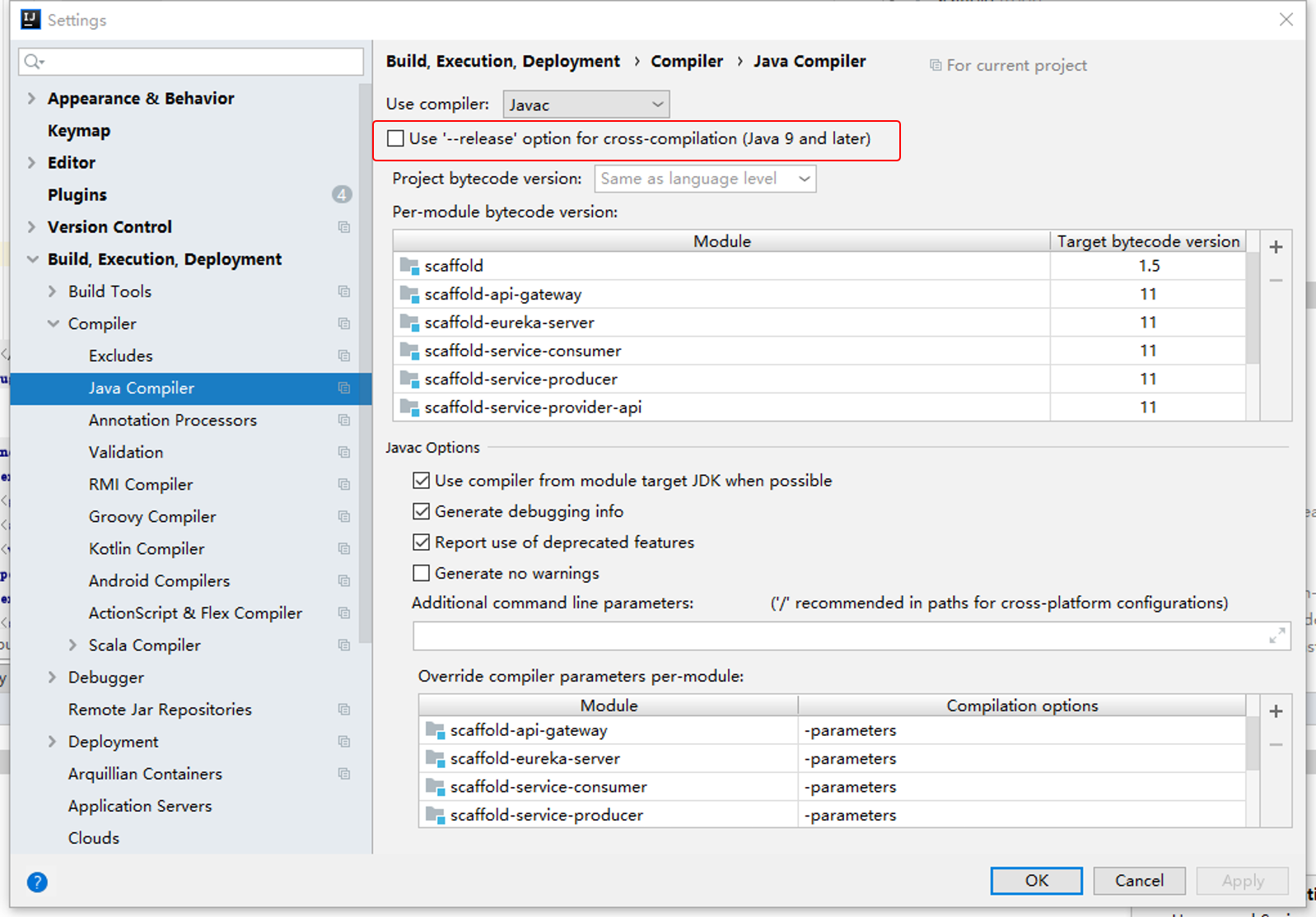
Note that for Java 9 and above, parameters need to be added during compilation and Runtime:
--add-exports=java.base/jdk.internal.vm.annotation=ALL-UNNAMED
Expose the module where @ contented annotation is located. At the same time, if you are using IDEA, because the parameter -- release will be added automatically after javac when IDEA is compiled, this parameter does not allow all parameters that break Java modularization, such as -- add export, etc., so you need to turn off the parameter of IDEA delivery, and turn it off through the following configuration:
Set - XX: + restrictcontented (this is actually the default, you can add it or not). Ignore contented to view the compiled object memory structure:
OFFSET SIZE TYPE DESCRIPTION VALUE 0 12 (object header) N/A 12 4 (alignment/padding gap) 16 8 long VolatileLong.value1 N/A 24 8 long VolatileLong.value2 N/A 32 8 long VolatileLong.value3 N/A 40 8 long VolatileLong.value4 N/A Instance size: 48 bytes Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
Set - XX: - restrictcontented, do not ignore contented to view the compiled object memory structure:
OFFSET SIZE TYPE DESCRIPTION VALUE 0 12 (object header) N/A 12 4 (alignment/padding gap) 16 120 long VolatileLong.value1(contended, group = group1) N/A 136 120 long VolatileLong.value2(contended, group = group2) N/A 256 120 long VolatileLong.value3(contended, group = group3) N/A 376 120 long VolatileLong.value4(contended, group = group4) N/A Instance size: 596 bytes Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
Each value field is filled in this way:

In this way, even in the worst case, for example, if the cache line starts from p1, or the cache line starts from a certain value, as shown in the figure above, no other value will be loaded.
Compare and test @ contented performance
private static final int ITER = 1000000000; public static void main(String[] args) throws RunnerException, InterruptedException { VolatileLong volatileLong = new VolatileLong(0, 0, 0, 0); Runnable update1 = () -> { for (int i = 0; i < ITER; i++) { volatileLong.setValue1(i); } }; Runnable update2 = () -> { for (int i = 0; i < ITER; i++) { volatileLong.setValue2(i); } }; Runnable update3 = () -> { for (int i = 0; i < ITER; i++) { volatileLong.setValue3(i); } }; Runnable update4 = () -> { for (int i = 0; i < ITER; i++) { volatileLong.setValue4(i); } }; Thread[] threads = new Thread[10]; long start = System.currentTimeMillis(); for (int i = 0; i < threads.length; i++) { threads[i] = (i & 2) == 0 ? new Thread(update1) : new Thread(update2); threads[i].start(); } for (int i = 0; i < threads.length; i++) { threads[i].join(); } System.out.println("1 elapsed: " + (System.currentTimeMillis() - start)); start = System.currentTimeMillis(); for (int i = 0; i < threads.length; i++) { threads[i] = (i & 2) == 0 ? new Thread(update3) : new Thread(update4); threads[i].start(); } for (int i = 0; i < threads.length; i++) { threads[i].join(); } System.out.println("2 elapsed: " + (System.currentTimeMillis() - start)); start = System.currentTimeMillis(); for (int i = 0; i < threads.length; i++) { threads[i] = (i & 2) == 0 ? new Thread(update1) : new Thread(update3); threads[i].start(); } for (int i = 0; i < threads.length; i++) { threads[i].join(); } System.out.println("3 elapsed: " + (System.currentTimeMillis() - start)); start = System.currentTimeMillis(); for (int i = 0; i < threads.length; i++) { threads[i] = (i & 2) == 0 ? new Thread(update2) : new Thread(update4); threads[i].start(); } for (int i = 0; i < threads.length; i++) { threads[i].join(); } System.out.println("4 elapsed: " + (System.currentTimeMillis() - start)); }
For the result of opening content:
1 elapsed: 13140 2 elapsed: 11185 3 elapsed: 10124 4 elapsed: 11749
If the content is not enabled, the result of false sharing appears:
1 elapsed: 19021 2 elapsed: 18758 3 elapsed: 19140 4 elapsed: 19287
Obviously, there are significant differences in performance.
conclusion
- When multiple threads modify different field s adjacent to memory, false sharing may occur, affecting performance.
- You can use class inheritance and useless field to fill in the cache row to avoid false sharing. However, in this way, it is limited that the cache line must be less than or equal to 64 bytes (this can be implemented by itself, most cache lines are 64 bytes). At the same time, a lot of useless code is generated
- Java 8 introduces @ Contended, which simplifies code, flexibly configures cache lines and adapts to different cache line sizes
- However, this annotation must add additional JVM startup parameters, otherwise it will not take effect. Therefore, the common framework class code still implements cache line filling by itself. We can consider using this annotation when using our project.