
In the process of doing crawler, we often encounter the following situations: at first, the crawler runs normally and grabs data normally, but the effort of a cup of tea may make mistakes, such as 403 Forbidden; at this time, the web page may appear the prompt of "your IP access frequency is too high", which may be unsealed after a long time, but this situation will appear later.
So we use some way to camouflage the local IP so that the server cannot recognize the request initiated by the local computer, so that we can successfully prevent the IP from being blocked. So proxy IP is in use.
General thinking of reptiles
1. Determine the url path to crawl, and the headers parameter
2. Send request -- requests simulate browser to send request and get response data
3. Parse data -- parsel is converted to Selector object, which has xpath method and can process the converted data
4. Save data
[environment introduction]:
python 3.6
pycharm
requests
parsel(xpath)
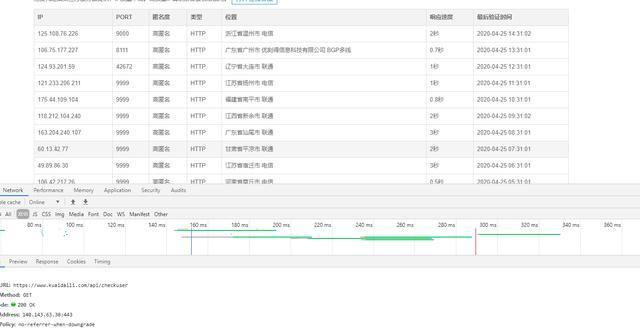
The code is as follows:
import requests import parsel import time def check_ip(proxies_list): """Testing ip Method of""" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'} can_use = [] for proxy in proxies_list: try: response = requests.get('http://www.baidu.com', headers=headers, proxies=proxy, timeout=0.1) # Over reporting error if response.status_code == 200: can_use.append(proxy) except Exception as error: print(error) return can_use import requests import parsel # 1,Determine the climbing url route, headers parameter base_url = 'https://www.kuaidaili.com/free/' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'} # 2,Send request -- requests Simulate browser to send request and get response data response = requests.get(base_url, headers=headers) data = response.text # print(data) # 3,Parse data -- parsel Convert to Selector Object, Selector Object has xpath It can process the transformed data # 3,1 Transformation python Interactive data types html_data = parsel.Selector(data) # 3,2 Parse data parse_list = html_data.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr') # Return Selector object # print(parse_list) # Free Admission IP {"Agreement":"IP:port"} # Loop traversal, secondary extraction proxies_list = [] for tr in parse_list: proxies_dict = {} http_type = tr.xpath('./td[4]/text()').extract_first() ip_num = tr.xpath('./td[1]/text()').extract_first() port_num = tr.xpath('./td[2]/text()').extract_first() # print(http_type, ip_num, port_num) # Build agent ip Dictionaries proxies_dict[http_type] = ip_num + ':' + port_num # print(proxies_dict) proxies_list.append(proxies_dict) print(proxies_list) print("Agent obtained ip number:", len(proxies_list), 'individual')
Call ip
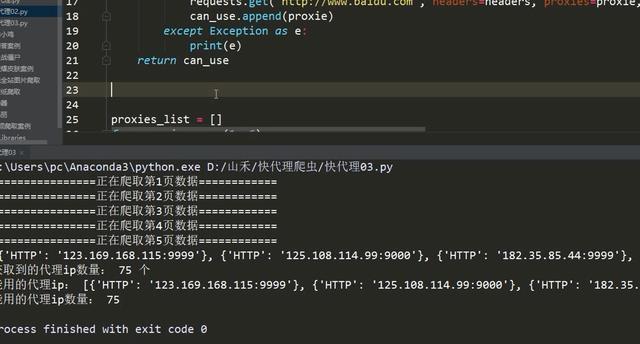
# Detection agent ip usability can_use = check_ip(proxies_list) print("Available agents:", can_use) print("Number of agents available:", len(can_use))
The effect is as follows:
If you want to learn Python or are learning python, there are many Python tutorials, but are they up to date? Maybe you have learned something that someone else probably learned two years ago. Share a wave of the latest Python tutorials in 2020 in this editor. Access to the way, private letter small "information", you can get free Oh!