Preface
It's been a month since I joined the new company, I've finished the work at hand, and the last few days I finally have time to research the code for my old project.During the process of researching the code, I found that Spring Aop was used in the project to separate the database from reading and writing, and to learn in my own way (I don't believe in it myself).) character, decided to write an example project to achieve the effect of spring AOP read-write separation.
Environment Deployment
-
Database: MySql
-
Number of libraries: 2, one master and one slave
For mysql's master-slave environment deployment, you can refer to:
https://juejin.im/post/5dd13778e51d453da86c0e6f
Start Project
First, undoubtedly, start building a SpringBoot project and then introduce the following dependencies in the pom file:
<dependencies> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.2</version> </dependency> <dependency> <groupId>tk.mybatis</groupId> <artifactId>mapper-spring-boot-starter</artifactId> <version>2.1.5</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.16</version> </dependency> <!-- Required dependencies for dynamic data sources ### start--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> <scope>provided</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> <scope>provided</scope> </dependency> <!-- Required dependencies for dynamic data sources ### end--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.4</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> </dependencies>
directory structure
After introducing the basic dependencies, sort out the catalog structure, and the project skeleton is roughly as follows:
Building tables
Create a table user that executes sql statements in the primary library while generating corresponding table data from the library
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `user_id` bigint(20) NOT NULL COMMENT 'user id', `user_name` varchar(255) DEFAULT '' COMMENT 'User Name', `user_phone` varchar(50) DEFAULT '' COMMENT 'User mobile phone', `address` varchar(255) DEFAULT '' COMMENT 'address', `weight` int(3) NOT NULL DEFAULT '1' COMMENT 'Weight, big takes precedence', `created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation Time', `updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Update Time', PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `user` VALUES ('1196978513958141952', 'Test 1', '18826334748', 'Haizhu District, Guangzhou', '1', '2019-11-20 10:28:51', '2019-11-22 14:28:26'); INSERT INTO `user` VALUES ('1196978513958141953', 'Test 2', '18826274230', 'Tianhe District, Guangzhou', '2', '2019-11-20 10:29:37', '2019-11-22 14:28:14'); INSERT INTO `user` VALUES ('1196978513958141954', 'Test 3', '18826273900', 'Tianhe District, Guangzhou', '1', '2019-11-20 10:30:19', '2019-11-22 14:28:30');
Master-Slave Data Source Configuration
application.yml, the main information is the data source configuration of the master-slave database
server: port: 8001 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver master: url: jdbc:mysql://127.0.0.1:3307/user?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&useSSL=false&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true username: root password: slave: url: jdbc:mysql://127.0.0.1:3308/user?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&useSSL=false&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true username: root password:
Since there are two data sources, one master and one slave, we use enumeration classes instead to make it easier for us to use the same data source.
@Getter public enum DynamicDataSourceEnum { MASTER("master"), SLAVE("slave"); private String dataSourceName; DynamicDataSourceEnum(String dataSourceName) { this.dataSourceName = dataSourceName; } }
Data source configuration information class DataSourceConfig, where two data sources are configured, master Db and slaveDb
@Configuration @MapperScan(basePackages = "com.xjt.proxy.mapper", sqlSessionTemplateRef = "sqlTemplate") public class DataSourceConfig { // Main Library @Bean @ConfigurationProperties(prefix = "spring.datasource.master") public DataSource masterDb() { return DruidDataSourceBuilder.create().build(); } /** * From Library */ @Bean @ConditionalOnProperty(prefix = "spring.datasource", name = "slave", matchIfMissing = true) @ConfigurationProperties(prefix = "spring.datasource.slave") public DataSource slaveDb() { return DruidDataSourceBuilder.create().build(); } /** * Master-Slave Dynamic Configuration */ @Bean public DynamicDataSource dynamicDb(@Qualifier("masterDb") DataSource masterDataSource, @Autowired(required = false) @Qualifier("slaveDb") DataSource slaveDataSource) { DynamicDataSource dynamicDataSource = new DynamicDataSource(); Map<Object, Object> targetDataSources = new HashMap<>(); targetDataSources.put(DynamicDataSourceEnum.MASTER.getDataSourceName(), masterDataSource); if (slaveDataSource != null) { targetDataSources.put(DynamicDataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource); } dynamicDataSource.setTargetDataSources(targetDataSources); dynamicDataSource.setDefaultTargetDataSource(masterDataSource); return dynamicDataSource; } @Bean public SqlSessionFactory sessionFactory(@Qualifier("dynamicDb") DataSource dynamicDataSource) throws Exception { SqlSessionFactoryBean bean = new SqlSessionFactoryBean(); bean.setMapperLocations( new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml")); bean.setDataSource(dynamicDataSource); return bean.getObject(); } @Bean public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) { return new SqlSessionTemplate(sqlSessionFactory); } @Bean(name = "dataSourceTx") public DataSourceTransactionManager dataSourceTx(@Qualifier("dynamicDb") DataSource dynamicDataSource) { DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); dataSourceTransactionManager.setDataSource(dynamicDataSource); return dataSourceTransactionManager; } }
Set Route
The purpose of routing is to make it easy to find the corresponding data source. We can use ThreadLocal to save the information of the data source to each thread so that we can get it when we need it
public class DataSourceContextHolder { private static final ThreadLocal<String> DYNAMIC_DATASOURCE_CONTEXT = new ThreadLocal<>(); public static void set(String datasourceType) { DYNAMIC_DATASOURCE_CONTEXT.set(datasourceType); } public static String get() { return DYNAMIC_DATASOURCE_CONTEXT.get(); } public static void clear() { DYNAMIC_DATASOURCE_CONTEXT.remove(); } }
Get Routes
public class DynamicDataSource extends AbstractRoutingDataSource { @Override protected Object determineCurrentLookupKey() { return DataSourceContextHolder.get(); } }
The purpose of AbstractRoutingDataSource is to route to the corresponding data source by finding the key. It maintains a set of target data sources internally, maps the routing key to the target data source, and provides a key-based method of finding the data source.For more springboot articles, check the past: SpringBoot Content Aggregation
Notes for data sources
To make it easy to switch data sources, we can write a comment that contains the corresponding enumeration values for the data sources. By default, it is the main library.
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) @Documented public @interface DataSourceSelector { DynamicDataSourceEnum value() default DynamicDataSourceEnum.MASTER; boolean clear() default true; }
aop switch data source
At this point, aop can finally appear. Here we define an aop class to switch data sources for annotated methods. The code is as follows:
@Slf4j @Aspect @Order(value = 1) @Component public class DataSourceContextAop { @Around("@annotation(com.xjt.proxy.dynamicdatasource.DataSourceSelector)") public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable { boolean clear = true; try { Method method = this.getMethod(pjp); DataSourceSelector dataSourceImport = method.getAnnotation(DataSourceSelector.class); clear = dataSourceImport.clear(); DataSourceContextHolder.set(dataSourceImport.value().getDataSourceName()); log.info("========Switch data source to:{}", dataSourceImport.value().getDataSourceName()); return pjp.proceed(); } finally { if (clear) { DataSourceContextHolder.clear(); } } } private Method getMethod(JoinPoint pjp) { MethodSignature signature = (MethodSignature)pjp.getSignature(); return signature.getMethod(); } }
At this point, we are ready to configure, and we will start testing the results below.For more springboot articles, check the past: SpringBoot Content Aggregation
Write the Service file first, which contains two methods of reading and updating.
@Service public class UserService { @Autowired private UserMapper userMapper; @DataSourceSelector(value = DynamicDataSourceEnum.SLAVE) public List<User> listUser() { List<User> users = userMapper.selectAll(); return users; } @DataSourceSelector(value = DynamicDataSourceEnum.MASTER) public int update() { User user = new User(); user.setUserId(Long.parseLong("1196978513958141952")); user.setUserName("Modified Name 2"); return userMapper.updateByPrimaryKeySelective(user); } @DataSourceSelector(value = DynamicDataSourceEnum.SLAVE) public User find() { User user = new User(); user.setUserId(Long.parseLong("1196978513958141952")); return userMapper.selectByPrimaryKey(user); } }
According to the annotations on the method, we can see that the reading method is from the library and the updating method is from the main library. The updating object is the data of userId 196978513958141953.
Then we'll write a test to see if it works.
@RunWith(SpringRunner.class) @SpringBootTest class UserServiceTest { @Autowired UserService userService; @Test void listUser() { List<User> users = userService.listUser(); for (User user : users) { System.out.println(user.getUserId()); System.out.println(user.getUserName()); System.out.println(user.getUserPhone()); } } @Test void update() { userService.update(); User user = userService.find(); System.out.println(user.getUserName()); } }
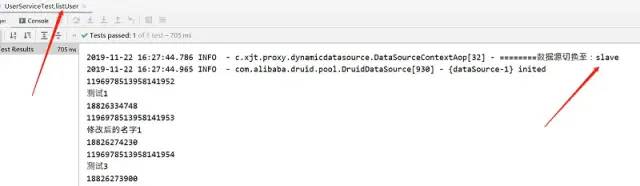
Test results:
1. Reading methods
2. Update Method
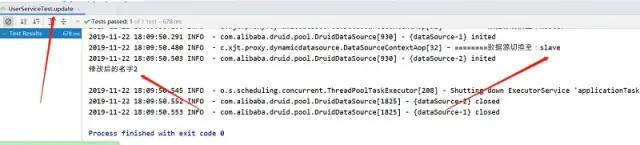
After execution, we can compare the databases and find that both master and slave libraries have modified the data, indicating that our read-write separation was successful.Of course, update methods can point to slave libraries so that only the data from the slave libraries will be modified, not the primary libraries.
Be careful
The example tested above is simple, but it also conforms to the general read-write separation configuration.It is worth mentioning that the role of read-write separation is to alleviate the pressure on the write libraries, that is, the master libraries, but it must be based on the principle of data consistency, that is, to ensure data consistency between the master and slave libraries.If a method involves write logic, all database operations in the method will be in the primary library.
Assuming that the data may not have been synchronized from the library after the write operation has been executed, and then the read operation begins to execute, if the program still reads from the library, data inconsistency will occur, which is not allowed by us.
Finally, send the github address of the project. Interested students can see:
https://github.com/Taoxj/mysql-proxy
Reference:
https://www.cnblogs.com/cjsblog/p/9712457.html
Author: Despicable Xue Mou
Link: juejin.im/post/5ddcd93af265da7dce3271de