Source network, only for learning, if there is infringement, please contact delete.
Before Redis 3.0, sentinel mechanism was used to monitor the status of each node.
Redis Cluster is redis's distributed solution, which was officially launched in version 3.0, effectively solving redis's distributed requirements. When encountering single machine memory, concurrency, traffic and other bottlenecks, the Cluster architecture scheme can be used to achieve the purpose of load balancing.
This paper will introduce Redis Cluster from the aspects of cluster scheme, data distribution, cluster building, node communication, cluster scaling, request routing, failover, cluster operation and maintenance.
Redis cluster scheme
Redis Cluster mode usually has the characteristics of high availability, scalability, distribution, fault tolerance and so on. There are generally two redis distributed schemes:
1. Client partition scheme
The client has decided which redis node the data will be stored in or read from. The main idea is to hash the key of redis data using hash algorithm. Through hash function, a specific key will be mapped to a specific redis node.
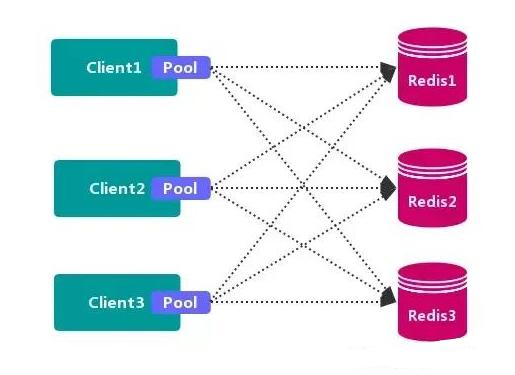
The representative of the client partition scheme is Redis Sharding, which is the Redis multi instance cluster method widely used in the industry before Redis Cluster came out. Java's Redis client driver library, Jedis, supports Redis Sharding function, namely ShardedJedis and ShardedJedisPool combined with cache pool.
advantage
Without the use of third-party middleware, the partition logic is controllable, the configuration is simple, there is no correlation between nodes, it is easy to expand linearly, and it is flexible.
shortcoming
The client cannot dynamically add or delete service nodes. The client needs to maintain its own distribution logic. There is no connection sharing between clients, which will cause connection waste.
2. Agent partition scheme
The client sends the request to a proxy component, the proxy parses the client's data, forwards the request to the correct node, and finally replies the result to the client.
- Advantages: simplify the distributed logic of client, transparent access of client, low switching cost, separation of forwarding and storage of agent.
- Disadvantages: an additional agent layer increases the complexity and performance loss of architecture deployment.
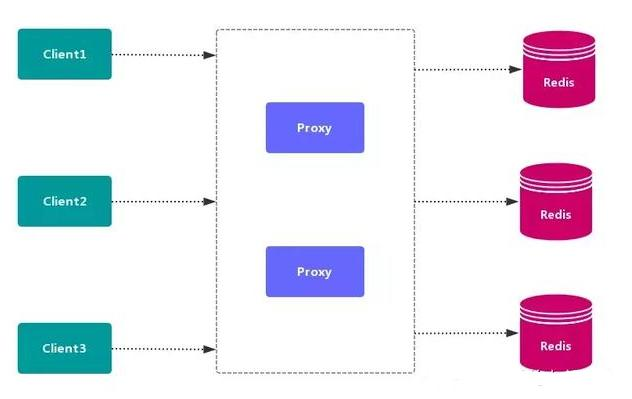
The main implementation schemes of proxy partition are tweemproxy and Codis.
2.1. Twemproxy
Tweetproxy, also known as nutcrawler, is an open-source intermediate proxy for redis and memcache. As a proxy, tweetproxy can accept access from multiple programs, forward it to various redis servers in the background according to routing rules, and then return in the original way. There is a single point of failure in the tweetproxy, so it needs to combine Lvs and preserved to make a highly available solution.
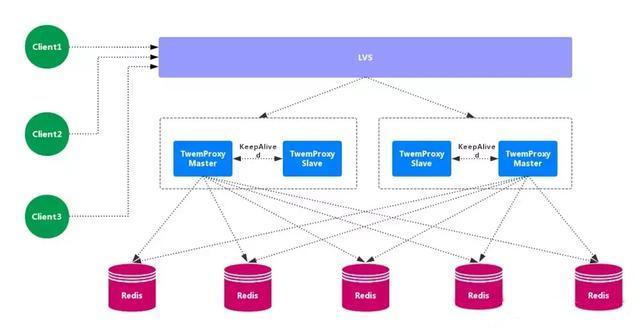
Advantages: wide application range, high stability, high availability of intermediate agent layer. Disadvantages: unable to smoothly expand / shrink capacity horizontally, no visual management interface, unfriendly operation and maintenance, failure, unable to transfer automatically.
2.2. Codis
Codis is a distributed Redis solution. For upper level applications, there is no difference between connecting to the Codis proxy and directly connecting to the native Redis server. The bottom layer of Codis will process the request forwarding and data migration without stopping. Codis adopts a stateless agent layer, which is transparent to clients.
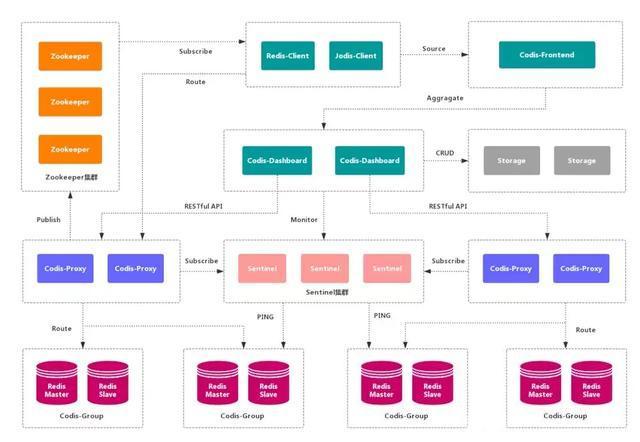
advantage
It realizes high availability of upper Proxy and lower Redis, data fragmentation and automatic balance, provides command-line interface and RESTful API, provides monitoring and management interface, and can dynamically add and delete Redis nodes.
shortcoming
The deployment architecture and configuration are complex, do not support cross room and multi tenant, and do not support authentication management.
3. Query routing scheme
The client randomly requests any redis instance, and redis forwards the request to the correct redis node. Redis Cluster implements a mixed form of query routing, but it does not directly forward requests from one redis node to another, but directly redirects (redirected) to the correct redis node with the help of the client.
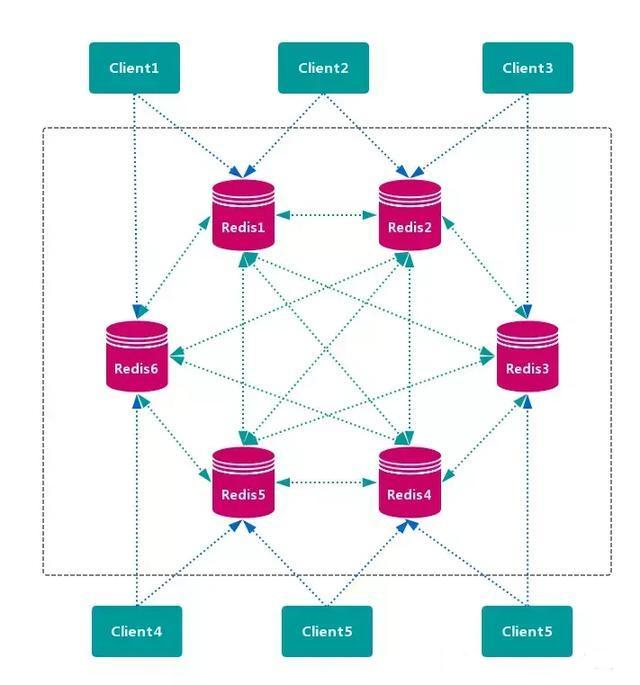
advantage
There is no central node, and the data is distributed on multiple Redis instances according to the slot storage. It can smoothly expand / shrink nodes, support high availability and automatic failover, and reduce operation and maintenance costs.
shortcoming
It relies heavily on redis trib tools and lacks monitoring management. It needs to rely on Smart Client (to maintain connection, cache routing table, multipop and Pipeline support). The detection of the Failover node is too slow, which is not as timely as the central node ZooKeeper. The Gossip message has some overhead. Cold and hot data cannot be distinguished according to statistics.
data distribution
1. Data distribution theory
First of all, the distributed database should map the whole data set to multiple nodes according to the partition rules, that is, to divide the data set into multiple nodes, each node is responsible for a subset of the whole data.
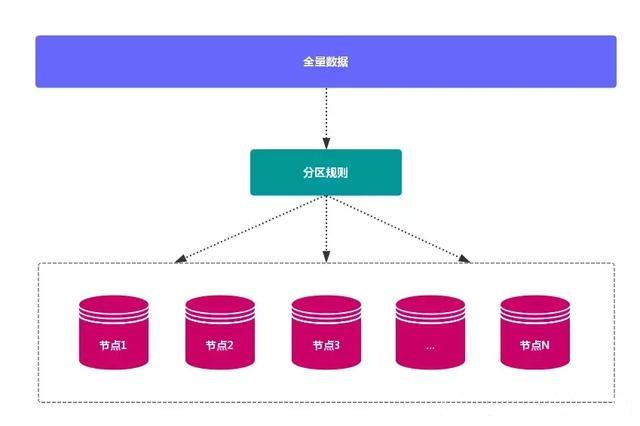
There are two ways of data distribution: hash partition and sequential partition. The comparison is as follows:
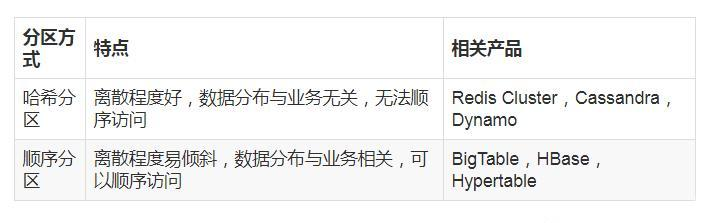
Because Redis Cluster adopts hash partition rules, this paper focuses on Hash partition. The common hash partition rules are as follows:
1.1 node redundancy partition
Use specific data, such as Redis key or user ID, and then use the formula: hash (key)% N to calculate the hash value according to the number of nodes N, which is used to determine which node the data is mapped to.
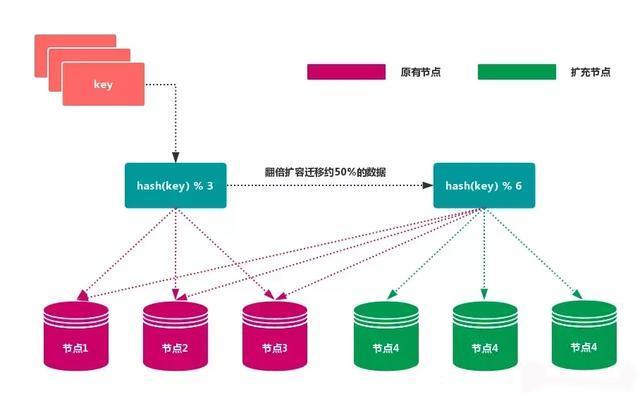
advantage
The outstanding advantage of this method is its simplicity, which is often used in the database sub database sub table rules. Generally, the pre partition method is adopted, and the number of partitions is planned according to the data amount in advance.
For example, it can be divided into 512 or 1024 tables to guarantee the data capacity in the future, and then the tables can be migrated to other databases according to the load. In the process of capacity expansion, it is usually used to double the capacity, so as to avoid data mapping being disrupted, leading to full migration.
shortcoming
When the number of nodes changes, such as expanding or shrinking nodes, the mapping relationship of data nodes needs to be recalculated, which will lead to data re migration.
1.2. Consistent hash partition
The consistency Hash can solve the stability problem well. All storage nodes can be arranged on the ending Hash ring. Each key will find the adjacent storage nodes clockwise after calculating the Hash. When a node is added or exited, it only affects the subsequent nodes that are adjacent to each other clockwise on the Hash ring.
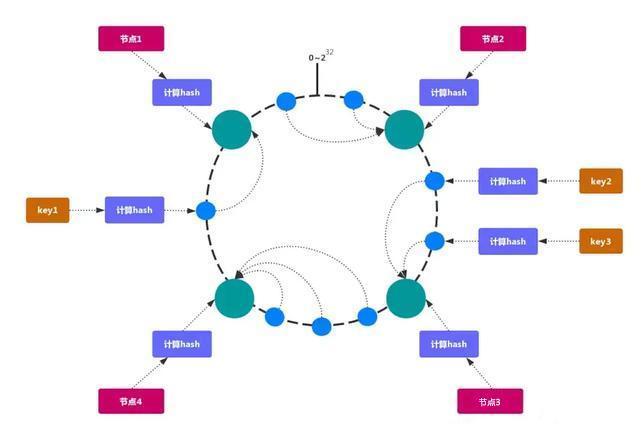
advantage
Adding and deleting nodes only affect the adjacent nodes in the clockwise direction of the hash ring, but not the other nodes.
shortcoming
Adding and subtracting nodes will cause some data in the hash ring to fail to hit. When a small number of nodes are used, the change of nodes will affect the data mapping in the hash ring in a large range, which is not suitable for the distributed scheme of a small number of data nodes. In order to balance data and load, a common consistent hash partition needs to double or subtract half of nodes when increasing or decreasing nodes.
Note: because of these shortcomings of consistent hash partition, some distributed systems use virtual slots to improve consistent hash, such as Dynamo system.
1.3. Virtual slot partition
Virtual slot partition cleverly uses hash space, and uses hash function with good dispersion to map all data to a fixed range of integers, which are defined as slots.
This range is generally much larger than the number of nodes. For example, the Redis Cluster slot range is 0 ~ 16383. Slot is the basic unit of data management and migration in a cluster. The main purpose of using large-scale slots is to facilitate data splitting and cluster expansion. Each node will be responsible for a certain number of slots, as shown in the figure:
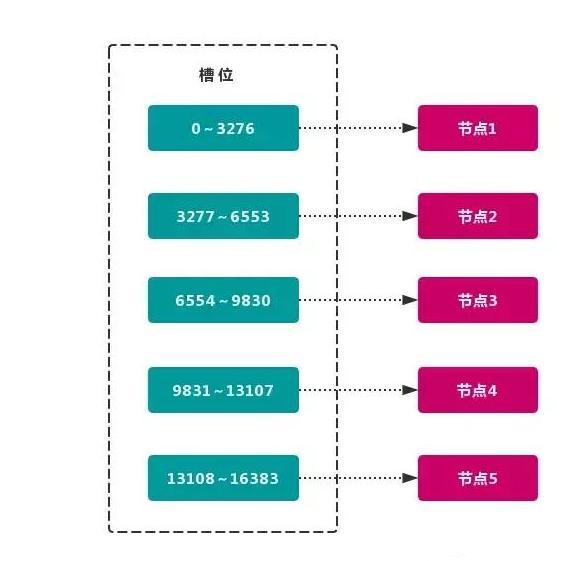
Currently, there are five nodes in the cluster, each node is responsible for about 3276 slots on average. Due to the use of high-quality hash algorithm, the data mapped by each slot is usually relatively uniform, and the data is divided into five nodes for data partition. Redis Cluster uses virtual slot partition.
- Node 1: contains hash slots 0 through 3276.
- Node 2: contains hash slots 3277 through 6553.
- Node 3: contains hash slots 6554 to 9830.
- Node 4: contains hash slots 9831 to 13107.
- Node 5: contains hash slots 13108 to 16383.
This structure makes it easy to add or remove nodes. If you add a node 6, you need to get some slots from nodes 1 to 5 to allocate to node 6. If you want to remove node 1, you need to move the slot in node 1 to nodes 2 to 5, and then remove node 1 without any slot from the cluster.
Since moving a hash slot from one node to another does not stop the service, adding or deleting or changing the number of hash slots for one node will not cause the cluster to be unavailable.
2. Redis data partition
Redis Cluster uses virtual slot partition, and all keys are mapped to 0 ~ 16383 integer slots according to the hash function. Calculation formula: slot = CRC16 (key) & 16383. Each node is responsible for maintaining a part of the slot and the key value data mapped by the slot, as shown in the figure:
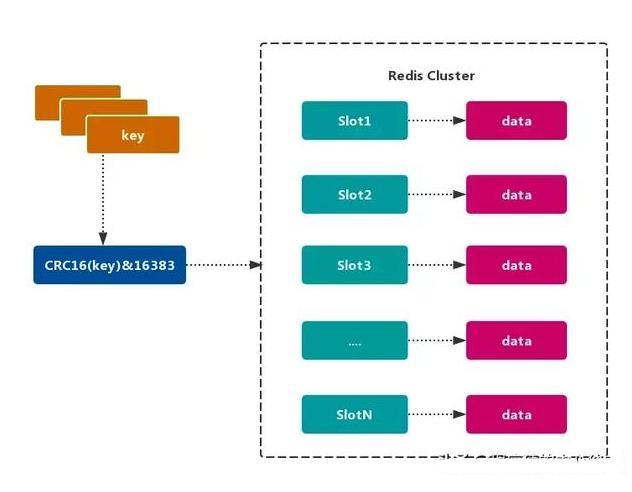
Characteristics of Redis virtual slot partition
Decoupling the relationship between data and nodes simplifies the difficulty of node expansion and contraction.
The node itself maintains the mapping relationship of the slot. No client or agent service is required to maintain the metadata of the slot partition.
It supports mapping query among nodes, slots and keys, and is used in data routing, online scaling and other scenarios.
3. Function limitation of Redis cluster
Redis cluster has some limitations on the function of a single machine, which need to be understood by developers in advance and avoided when using.
key batch operation support is limited.
Similar to mset and mget operations, currently only batch operations are supported for keys with the same slot value. key mapped to different slot values is not supported because operations such as mget and mget may exist on multiple nodes.
key transaction operation support is limited.
Only the transaction operation of multiple keys on the same node is supported. When multiple keys are distributed on different nodes, the transaction function cannot be used.
key as the minimum granularity of data partition
You cannot map a large key value object such as hash, list, etc. to different nodes.
Multiple database spaces are not supported
Redis on a single machine can support 16 databases (db0 ~ db15), and only one database space, db0, can be used in cluster mode.
Replication structure only supports one layer
Only the master node can be copied from the slave node, and nested tree replication structure is not supported.
Redis cluster building
Redis Cluster is an official high availability solution of redis. There are 2 ^ 14 (16384) slots in redis Cluster. After the Cluster is created, the slots are evenly allocated to each redis node.
Here's how to start the cluster service of six Redis and use redis-trib.rb Create a cluster of 3 master and 3 slave. The following three steps are needed to build a cluster:
1. Prepare node
Redis cluster is generally composed of multiple nodes, and the number of nodes is at least 6, to ensure the formation of a complete and highly available cluster. Each node needs to enable cluster enabled yes to enable redis to run in cluster mode.
The nodes of Redis cluster are planned as follows:
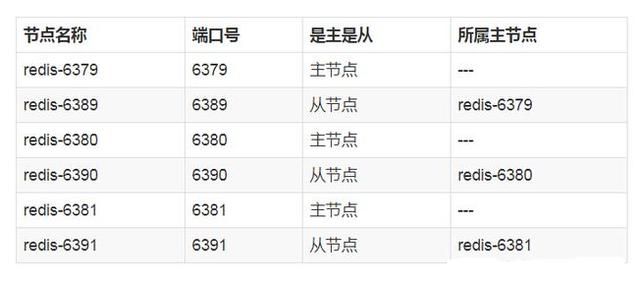
Note: it is recommended to unify the directories for all nodes in the cluster. Generally, there are three directories: conf, data, and log, which respectively store configuration, data, and log related files. Put the six node configurations in the conf directory.
1.1. Create the redis instance directory
$ sudo mkdir -p /usr/local/redis-cluster $ cd /usr/local/redis-cluster $ sudo mkdir conf data log $ sudo mkdir -p data/redis-6379 data/redis-6389 data/redis-6380 data/redis-6390 data/redis-6381 data/redis-6391
1.2 redis profile management
Configure the redis.conf , the following is only the basic configuration needed to build the cluster, which may need to be modified according to the actual situation.
# redis running in the background daemonize yes # Bound host port bind 127.0.0.1 # Data storage directory dir /usr/local/redis-cluster/data/redis-6379 # Process file pidfile /var/run/redis-cluster/${custom}.pid # log file logfile /usr/local/redis-cluster/log/${custom}.log # Port number port 6379 # Turn on the cluster mode and comment#Remove cluster-enabled yes # Configuration of the cluster. The configuration file is automatically generated for the first time cluster-config-file /usr/local/redis-cluster/conf/${custom}.conf # Request timeout, set 10 seconds cluster-node-timeout 10000 # aof log is enabled when necessary. It records a log for each write operation appendonly yes
redis-6379.conf
daemonize yes bind 127.0.0.1 dir /usr/local/redis-cluster/data/redis-6379 pidfile /var/run/redis-cluster/redis-6379.pid logfile /usr/local/redis-cluster/log/redis-6379.log port 6379 cluster-enabled yes cluster-config-file /usr/local/redis-cluster/conf/node-6379.conf cluster-node-timeout 10000 appendonly yes
redis-6389.conf
daemonize yes bind 127.0.0.1 dir /usr/local/redis-cluster/data/redis-6389 pidfile /var/run/redis-cluster/redis-6389.pid logfile /usr/local/redis-cluster/log/redis-6389.log port 6389 cluster-enabled yes cluster-config-file /usr/local/redis-cluster/conf/node-6389.conf cluster-node-timeout 10000 appendonly yes
redis-6380.conf
daemonize yes bind 127.0.0.1 dir /usr/local/redis-cluster/data/redis-6380 pidfile /var/run/redis-cluster/redis-6380.pid logfile /usr/local/redis-cluster/log/redis-6380.log port 6380 cluster-enabled yes cluster-config-file /usr/local/redis-cluster/conf/node-6380.conf cluster-node-timeout 10000 appendonly yes
redis-6390.conf
daemonize yes bind 127.0.0.1 dir /usr/local/redis-cluster/data/redis-6390 pidfile /var/run/redis-cluster/redis-6390.pid logfile /usr/local/redis-cluster/log/redis-6390.log port 6390 cluster-enabled yes cluster-config-file /usr/local/redis-cluster/conf/node-6390.conf cluster-node-timeout 10000 appendonly yes
redis-6381.conf
daemonize yes bind 127.0.0.1 dir /usr/local/redis-cluster/data/redis-6381 pidfile /var/run/redis-cluster/redis-6381.pid logfile /usr/local/redis-cluster/log/redis-6381.log port 6381 cluster-enabled yes cluster-config-file /usr/local/redis-cluster/conf/node-6381.conf cluster-node-timeout 10000 appendonly yes
redis-6391.conf
daemonize yes bind 127.0.0.1 dir /usr/local/redis-cluster/data/redis-6391 pidfile /var/run/redis-cluster/redis-6391.pid logfile /usr/local/redis-cluster/log/redis-6391.log port 6391 cluster-enabled yes cluster-config-file /usr/local/redis-cluster/conf/node-6391.conf cluster-node-timeout 10000 appendonly yes
2. Environmental preparation
2.1 install Ruby environment
$ sudo brew install ruby
2.2. Prepare rubygem redis dependency
$ sudo gem install redis Password: Fetching: redis-4.0.2.gem (100%) Successfully installed redis-4.0.2 Parsing documentation for redis-4.0.2 Installing ri documentation for redis-4.0.2 Done installing documentation for redis after 1 seconds 1 gem installed
2.3. Copy redis-trib.rb To cluster root
redis-trib.rb It is an official redis cluster management tool. It is integrated in the source src directory of redis. It encapsulates the cluster commands based on redis into a simple, convenient and practical operation tool.
$ sudo cp /usr/local/redis-4.0.11/src/redis-trib.rb /usr/local/redis-cluster
View redis-trib.rb Whether the command environment is correct, the output is as follows:
$ ./redis-trib.rb Usage: redis-trib <command> <options> <arguments ...> create host1:port1 ... hostN:portN --replicas <arg> check host:port info host:port fix host:port --timeout <arg> reshard host:port --from <arg> --to <arg> --slots <arg> --yes --timeout <arg> --pipeline <arg> rebalance host:port --weight <arg> --auto-weights --use-empty-masters --timeout <arg> --simulate --pipeline <arg> --threshold <arg> add-node new_host:new_port existing_host:existing_port --slave --master-id <arg> del-node host:port node_id set-timeout host:port milliseconds call host:port command arg arg .. arg import host:port --from <arg> --copy --replace help (show this help) For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
redis-trib.rb It's done by redis author in ruby. redis-trib.rb The specific functions of the command line tool are as follows:
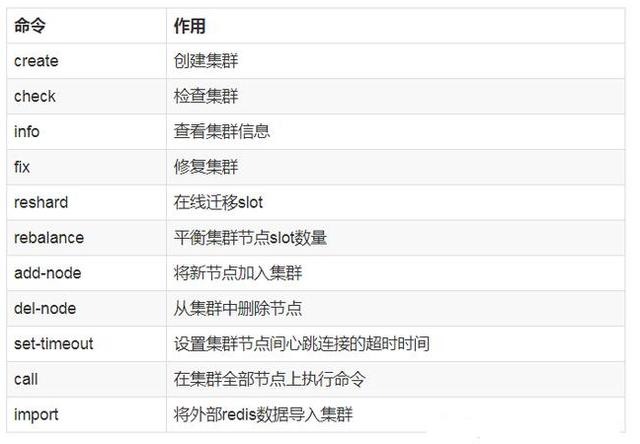
3. Install cluster
3.1 start redis service node
Run the following command to start six redis nodes:
sudo redis-server conf/redis-6379.conf sudo redis-server conf/redis-6389.conf sudo redis-server conf/redis-6380.conf sudo redis-server conf/redis-6390.conf sudo redis-server conf/redis-6381.conf sudo redis-server conf/redis-6391.conf
After the startup is completed, redis starts in cluster mode to view the process status of each redis node:
$ ps -ef | grep redis-server 0 1908 1 0 4:59 afternoon ?? 0:00.01 redis-server *:6379 [cluster] 0 1911 1 0 4:59 afternoon ?? 0:00.01 redis-server *:6389 [cluster] 0 1914 1 0 4:59 afternoon ?? 0:00.01 redis-server *:6380 [cluster] 0 1917 1 0 4:59 afternoon ?? 0:00.01 redis-server *:6390 [cluster] 0 1920 1 0 4:59 afternoon ?? 0:00.01 redis-server *:6381 [cluster] 0 1923 1 0 4:59 afternoon ?? 0:00.01 redis-server *:6391 [cluster]
In each redis node redis.conf In the file, we have configured the file path of cluster config file. When the cluster is started, the conf directory will generate a new cluster node configuration file. View the file list as follows:
$ tree -L 3 . . ├── appendonly.aof ├── conf │ ├── node-6379.conf │ ├── node-6380.conf │ ├── node-6381.conf │ ├── node-6389.conf │ ├── node-6390.conf │ ├── node-6391.conf │ ├── redis-6379.conf │ ├── redis-6380.conf │ ├── redis-6381.conf │ ├── redis-6389.conf │ ├── redis-6390.conf │ └── redis-6391.conf ├── data │ ├── redis-6379 │ ├── redis-6380 │ ├── redis-6381 │ ├── redis-6389 │ ├── redis-6390 │ └── redis-6391 ├── log │ ├── redis-6379.log │ ├── redis-6380.log │ ├── redis-6381.log │ ├── redis-6389.log │ ├── redis-6390.log │ └── redis-6391.log └── redis-trib.rb 9 directories, 20 files
3.2 redis trib associated cluster node
The six redis nodes are arranged from left to right in order from master to slave.
$ sudo ./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6389 127.0.0.1:6390 127.0.0.1:6391
After the cluster is created, redis trib will first allocate 16384 hash slots to three primary nodes, namely redis-6379, redis-6380 and redis-6381. Then point each slave node to the master node for data synchronization.
>>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 Adding replica 127.0.0.1:6390 to 127.0.0.1:6379 Adding replica 127.0.0.1:6391 to 127.0.0.1:6380 Adding replica 127.0.0.1:6389 to 127.0.0.1:6381 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: ad4b9ffceba062492ed67ab336657426f55874b7 127.0.0.1:6379 slots:0-5460 (5461 slots) master M: df23c6cad0654ba83f0422e352a81ecee822702e 127.0.0.1:6380 slots:5461-10922 (5462 slots) master M: ab9da92d37125f24fe60f1f33688b4f8644612ee 127.0.0.1:6381 slots:10923-16383 (5461 slots) master S: 25cfa11a2b4666021da5380ff332b80dbda97208 127.0.0.1:6389 replicates ad4b9ffceba062492ed67ab336657426f55874b7 S: 48e0a4b539867e01c66172415d94d748933be173 127.0.0.1:6390 replicates df23c6cad0654ba83f0422e352a81ecee822702e S: d881142a8307f89ba51835734b27cb309a0fe855 127.0.0.1:6391 replicates ab9da92d37125f24fe60f1f33688b4f8644612ee
Then type yes, redis-trib.rb The node handshake and slot allocation operation are started, and the output is as follows:
Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.... >>> Performing Cluster Check (using node 127.0.0.1:6379) M: ad4b9ffceba062492ed67ab336657426f55874b7 127.0.0.1:6379 slots:0-5460 (5461 slots) master 1 additional replica(s) M: ab9da92d37125f24fe60f1f33688b4f8644612ee 127.0.0.1:6381 slots:10923-16383 (5461 slots) master 1 additional replica(s) S: 48e0a4b539867e01c66172415d94d748933be173 127.0.0.1:6390 slots: (0 slots) slave replicates df23c6cad0654ba83f0422e352a81ecee822702e S: d881142a8307f89ba51835734b27cb309a0fe855 127.0.0.1:6391 slots: (0 slots) slave replicates ab9da92d37125f24fe60f1f33688b4f8644612ee M: df23c6cad0654ba83f0422e352a81ecee822702e 127.0.0.1:6380 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 25cfa11a2b4666021da5380ff332b80dbda97208 127.0.0.1:6389 slots: (0 slots) slave replicates ad4b9ffceba062492ed67ab336657426f55874b7 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
Perform cluster check to check the number of slots occupied by each redis node and the slot coverage. Among 16384 slots, the primary nodes redis-6379, redis-6380 and redis-6381 occupy 5461, 5461 and 5462 slots respectively.
3.3. Logs of the redis primary node
It can be found that through the BGSAVE command, the slave node redis-6389 asynchronously synchronizes data from the master node redis-6379 in the background.
$ cat log/redis-6379.log 1907:C 05 Sep 16:59:52.960 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 1907:C 05 Sep 16:59:52.961 # Redis version=4.0.11, bits=64, commit=00000000, modified=0, pid=1907, just started 1907:C 05 Sep 16:59:52.961 # Configuration loaded 1908:M 05 Sep 16:59:52.964 * Increased maximum number of open files to 10032 (it was originally set to 256). 1908:M 05 Sep 16:59:52.965 * No cluster configuration found, I'm ad4b9ffceba062492ed67ab336657426f55874b7 1908:M 05 Sep 16:59:52.967 * Running mode=cluster, port=6379. 1908:M 05 Sep 16:59:52.967 # Server initialized 1908:M 05 Sep 16:59:52.967 * Ready to accept connections 1908:M 05 Sep 17:01:17.782 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH 1908:M 05 Sep 17:01:17.812 # IP address for this node updated to 127.0.0.1 1908:M 05 Sep 17:01:22.740 # Cluster state changed: ok 1908:M 05 Sep 17:01:23.681 * Slave 127.0.0.1:6389 asks for synchronization 1908:M 05 Sep 17:01:23.681 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '4c5afe96cac51cde56039f96383ea7217ef2af41', my replication IDs are '037b661bf48c80c577d1fa937ba55367a3692921' and '0000000000000000000000000000000000000000') 1908:M 05 Sep 17:01:23.681 * Starting BGSAVE for SYNC with target: disk 1908:M 05 Sep 17:01:23.682 * Background saving started by pid 1952 1952:C 05 Sep 17:01:23.683 * DB saved on disk 1908:M 05 Sep 17:01:23.749 * Background saving terminated with success 1908:M 05 Sep 17:01:23.752 * Synchronization with slave 127.0.0.1:6389 succeeded
3.4 integrity detection of redis cluster
Use redis- trib.rb The check command checks whether the two clusters created before are successful. The check command only needs to give the address of any node in the cluster to complete the check of the whole cluster. The command is as follows:
$ ./redis-trib.rb check 127.0.0.1:6379
When the following information is finally output, it indicates that all the slots in the cluster have been allocated to the node:
[OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
This paper introduces the Redis cluster solution, data distribution and cluster construction.
The cluster scheme includes client partition scheme, agent partition scheme and query route scheme. In the data distribution part, the redundant partition, consistent hash partition and virtual slot partition are simply described and compared.
Finally, an example of a virtual slot cluster with three primary and three secondary is built by using redis trib.
I have compiled the interview questions and answers into PDF documents, as well as a set of learning materials, including Java virtual machine, spring framework, java thread, data structure, design pattern, etc., but not limited to this.
Focus on the official account [java circle] for information, as well as daily delivery of quality articles.
