Product dimension data loading (zipper table)
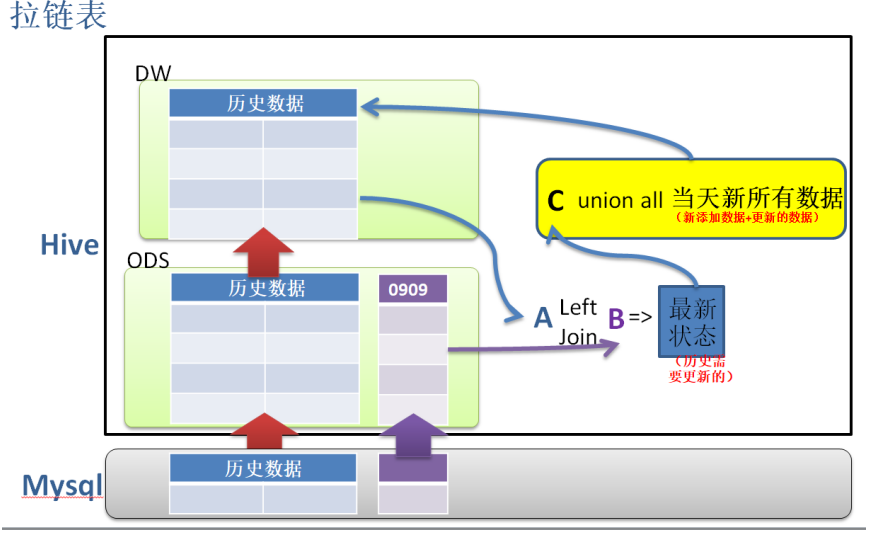
Zipper watch design:
1. Collect the full data of the day and store it in the ND (current day) table.
2. You can take out yesterday's full data from the history table and store it in the OD (last day's data) table.
3. ND-OD is the data added and changed on the day (i.e. daily incremental data).
Compare the two tables in full fields, and record the results to the tabel_ In table I.
4. Use OD-ND as the status to end the data to be chained. (end needs to be modified_ DATE);
Compare the two tables in full fields, and record the results to the tabel_U table.
5. HIS table has two more fields (start) than ND table and OD table_ DATE,END_DATE)
6. Put tabel_ The contents of the I table are all insert ed into the HIS table.
START_DATE = day, END_DATE can be set to '9999-12-31';
7. Update end of chain sealing record_ DATE.
History table (HIS) and tabel_U table comparison, START_DATE,END_ Except for date, use tabel_ The u table shall prevail, and the intersection of the two sets its end_ The date is changed to the current day, indicating that the record is invalid.
8. Select the date condition when fetching the data, for example: take the data of 20100101 as
(where START_DATE<='20100101' and END_DATE>'20100101' ).
Function of zipper Watch:
- The amount of data is large.
- Some fields in the table will be updated, such as user's address, bank interest rate, order status, etc.
- You need to view the historical snapshot information of a certain time point or period, for example, to view the status of interest rate at a certain time point in history.
- The proportion and frequency of changes are not very large. For example, there are 10 million members in total, and about 100000 members are added and changed every day.
- If you keep a copy of the total quantity of the table here every day, a lot of unchanging information will be saved in each full quantity, which is a great waste of storage;
Zipper history table can not only satisfy the historical state of reaction data, but also save storage to the greatest extent.
Using zipper table to solve SCD problem
5.1 dw layer construction table
-- dw Floor construction table DROP TABLE IF EXISTS `itcast_dw`.`dim_goods`; CREATE TABLE `itcast_dw`.`dim_goods`( goodsId bigint, goodsSn string, productNo string, goodsName string, goodsImg string, shopId bigint, goodsType bigint, marketPrice double, shopPrice double, warnStock bigint, goodsStock bigint, goodsUnit string, goodsTips string, isSale bigint, isBest bigint, isHot bigint, isNew bigint, isRecom bigint, goodsCatIdPath string, goodsCatId bigint, shopCatId1 bigint, shopCatId2 bigint, brandId bigint, goodsDesc string, goodsStatus bigint, saleNum bigint, saleTime string, visitNum bigint, appraiseNum bigint, isSpec bigint, gallery string, goodsSeoKeywords string, illegalRemarks string, dataFlag bigint, createTime string, isFreeShipping bigint, goodsSerachKeywords string, modifyTime string, dw_start_date string, dw_end_date string ) STORED AS PARQUET;
What does the above code mean?
Create dim in dw layer_ There are two more fields in the goods table, one is the status start time: dw_start_date string, one is state end time: dw_end_date string
What's he doing?
This table is used to save itcast_ Historical data, updated data and new data of goods
5.2 specific steps
Zipper watch design is divided into the following steps:
1. First full import
All ODS data are imported into the zipper history table
2. Incremental import (one day, for example: 2018-09-09) incremental import data of one day to ODS partition merge historical data
Update through connection query
1 full import
import all the products created before September 8, 2019 and the modified data into the zipper history table
Operation steps:
1. Using Kettle to extract data before 20190908 to ods
SELECT *
FROM itcast_ods.itcast_goods
WHERE DATE_FORMAT(createtime, '%Y%m%d') <= '20190908' OR DATE_FORMAT(modifyTime, '%Y%m%d') <= '20190908';
Find the date data including 20190908 and before in the table input component of kettle
What's he doing?
Input the data of 20190908 and before into itcast as full data_ ods.itcast_ goods

2. Use spark sql to import full data into dimension table of dw layer
set spark.sql.shuffle.partitions=1; --shuffle The default is200individual -- use spark sql Import full data to dw Layer dimension table insert overwrite table `itcast_dw`.`dim_goods` select goodsId, goodsSn, productNo, goodsName, goodsImg, shopId, goodsType, marketPrice, shopPrice, warnStock, goodsStock, goodsUnit, goodsTips, isSale, isBest, isHot, isNew, isRecom, goodsCatIdPath, goodsCatId, shopCatId1, shopCatId2, brandId, goodsDesc, goodsStatus, saleNum, saleTime, visitNum, appraiseNum, isSpec, gallery, goodsSeoKeywords, illegalRemarks, dataFlag, createTime, isFreeShipping, goodsSerachKeywords, modifyTime, case when modifyTime is not null then from_unixtime(unix_timestamp(modifyTime, 'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd') else from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') end as dw_start_date, '9999-12-31' as dw_end_date from `itcast_ods`.`itcast_goods` t where dt='20190908';
What does the above code mean?
Import 20190908 partition full data to itcast_ Dim of DW Library_ Goods table
What's he doing?
Put itcast_ Itcast of ODS Library_ The goods table imports the data partitioned as 20190908 into the dim of dw layer as full data_ In the goods table, because there are two more date fields in the first import, the default start time for each data is the modification time of each data, and the end time is 9999-12-31 to represent the latest data

2 incremental import
import all the modified data created on September 9, 2019 into the historical zipper table
Operation steps:
1. Using Kettle to extract the data created or modified in 20190909 to ods
SELECT *
FROM itcast_goods
WHERE DATE_FORMAT(createtime, '%Y%m%d') = 'dt′ORDATEFORMAT(modifyTime,′{dt}' OR DATE_FORMAT(modifyTime, '%Y%m%d') = 'dt′ORDATEFORMAT(modifyTime,′{dt}';
What does the above code mean?
Find the date data including 20190909 and before in the table input component of kettle
What's he doing?
==Input the data of 20190909 as new data into itcast_ods.itcast_goods ==
2. Write spark SQL to update historical data
-- Update historical data select dw.goodsId, dw.goodsSn, dw.productNo, dw.goodsName, dw.goodsImg, dw.shopId, dw.goodsType, dw.marketPrice, dw.shopPrice, dw.warnStock, dw.goodsStock, dw.goodsUnit, dw.goodsTips, dw.isSale, dw.isBest, dw.isHot, dw.isNew, dw.isRecom, dw.goodsCatIdPath, dw.goodsCatId, dw.shopCatId1, dw.shopCatId2, dw.brandId, dw.goodsDesc, dw.goodsStatus, dw.saleNum, dw.saleTime, dw.visitNum, dw.appraiseNum, dw.isSpec, dw.gallery, dw.goodsSeoKeywords, dw.illegalRemarks, dw.dataFlag, dw.createTime, dw.isFreeShipping, dw.goodsSerachKeywords, dw.modifyTime, dw.dw_start_date, case when dw.dw_end_date = '9999-12-31' and ods.goodsId is not null then '2019-09-08' else dw.dw_end_date end as dw_end_date from `itcast_dw`.`dim_goods` dw left join (select * from `itcast_ods`.`itcast_goods` where dt='20190909') ods on dw.goodsId = ods.goodsId;
What does the above code mean?
Update dim_ Historical data in the goods table
What's he doing?
Using dim_goods table and itcast_ left join and dim the data of 20190909 partition in the goods table_ The goods table shows all, itcast_ The goods table is displayed only if there is an association, and the dim of the same goods ID is displayed_ The end date of the goods table is 9999-12-31. Change the end time to 2019-09-08

3. Write spark SQL to get the data of the day
-- Today's data
select
goodsId,
goodsSn,
productNo,
goodsName,
goodsImg,
shopId,
goodsType,
marketPrice,
shopPrice,
warnStock,
goodsStock,
goodsUnit,
goodsTips,
isSale,
isBest,
isHot,
isNew,
isRecom,
goodsCatIdPath,
goodsCatId,
shopCatId1,
shopCatId2,
brandId,
goodsDesc,
goodsStatus,
saleNum,
saleTime,
visitNum,
appraiseNum,
isSpec,
gallery,
goodsSeoKeywords,
illegalRemarks,
dataFlag,
createTime,
isFreeShipping,
goodsSerachKeywords,
modifyTime,
case when modifyTime is not null
then from_unixtime(unix_timestamp(modifyTime, 'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd')
else from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd')
end as dw_start_date,
'9999-12-31' as dw_end_date
from
`itcast_ods`.`itcast_goods`
where dt = '20190909';
What does the above code mean?
View itcast_ Data of 2019090 partition in the goods table
What's he doing?
View itcast_ Data of 2019090 partition in the goods table

4. Load historical data and current day data into temporary table
-- Load historical data and current day data into temporary table drop table if exists `itcast_dw`.`tmp_dim_goods_history`; create table `itcast_dw`.`tmp_dim_goods_history` as select dw.goodsId, dw.goodsSn, dw.productNo, dw.goodsName, dw.goodsImg, dw.shopId, dw.goodsType, dw.marketPrice, dw.shopPrice, dw.warnStock, dw.goodsStock, dw.goodsUnit, dw.goodsTips, dw.isSale, dw.isBest, dw.isHot, dw.isNew, dw.isRecom, dw.goodsCatIdPath, dw.goodsCatId, dw.shopCatId1, dw.shopCatId2, dw.brandId, dw.goodsDesc, dw.goodsStatus, dw.saleNum, dw.saleTime, dw.visitNum, dw.appraiseNum, dw.isSpec, dw.gallery, dw.goodsSeoKeywords, dw.illegalRemarks, dw.dataFlag, dw.createTime, dw.isFreeShipping, dw.goodsSerachKeywords, dw.modifyTime, dw.dw_start_date, case when dw.dw_end_date >= '2019-09-09' and ods.goodsId is not null then '2019-09-08' else dw.dw_end_date end as dw_end_date from `itcast_dw`.`dim_goods` dw left join (select * from `itcast_ods`.`itcast_goods` where dt='20190909') ods on dw.goodsId = ods.goodsId union all select goodsId, goodsSn, productNo, goodsName, goodsImg, shopId, goodsType, marketPrice, shopPrice, warnStock, goodsStock, goodsUnit, goodsTips, isSale, isBest, isHot, isNew, isRecom, goodsCatIdPath, goodsCatId, shopCatId1, shopCatId2, brandId, goodsDesc, goodsStatus, saleNum, saleTime, visitNum, appraiseNum, isSpec, gallery, goodsSeoKeywords, illegalRemarks, dataFlag, createTime, isFreeShipping, goodsSerachKeywords, modifyTime, case when modifyTime is not null then from_unixtime(unix_timestamp(modifyTime, 'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd') else from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') end as dw_start_date, '9999-12-31' as dw_end_date from `itcast_ods`.`itcast_goods` where dt = '20190909';
What does the above code mean?
Create tmp_dim_goods_history temporary table and add data to the table
What's he doing?
Create TMP_ dim_goods_ The history table is used to store historical data, updated data and new data. Through dim_goods table and itcast_ The data left join of the 20190909 partition of the goods table updates the end time result of the historical data as a table, and then uses it with itcast_ By merging the data of goods partition 20190909, you can update the historical data and add new data to this temporary table

5. Import historical data and current day data into historical zipper table
– import historical data and current day data into historical zipper table
insert overwrite table
itcast_dw.dim_goodsselect * fromitcast_dw.tmp_dim_goods_history;
What does the above code mean?
Put TMP_ dim_goods_ All data of history temporary table is inserted into dim_ Final table of goods
What's he doing?
TMP_ dim_goods_ Data stored in history table is inserted and overwritten to dim_ In the goods table
– get commodity data on September 9, 2019
select * from
itcast_dw.dim_goodswhere dw_start_date <= '2019-09-09' and dw_end_date >= '2019-09-09' limit 10;
What does the above code mean?
Find ten pieces of data whose start time is no more than 2019-09-09 and end time is no less than 2019-09-09
What's he doing?
Check whether the result of data is correct

3 test
Operation steps:
1. Change the modification date of a piece of data in mysql to 2019-09-10
2. Set the kettle naming parameter to extract the data again to the 20190910 partition
3. Re execute spark SQL script to load data to temporary table
-- Import2019-09-10Historical zipper data of -- Load historical data and current day data into temporary table drop table if exists `itcast_dw`.`tmp_dim_goods_history`; create table `itcast_dw`.`tmp_dim_goods_history` as select dw.goodsId, dw.goodsSn, dw.productNo, dw.goodsName, dw.goodsImg, dw.shopId, dw.goodsType, dw.marketPrice, dw.shopPrice, dw.warnStock, dw.goodsStock, dw.goodsUnit, dw.goodsTips, dw.isSale, dw.isBest, dw.isHot, dw.isNew, dw.isRecom, dw.goodsCatIdPath, dw.goodsCatId, dw.shopCatId1, dw.shopCatId2, dw.brandId, dw.goodsDesc, dw.goodsStatus, dw.saleNum, dw.saleTime, dw.visitNum, dw.appraiseNum, dw.isSpec, dw.gallery, dw.goodsSeoKeywords, dw.illegalRemarks, dw.dataFlag, dw.createTime, dw.isFreeShipping, dw.goodsSerachKeywords, dw.modifyTime, dw.dw_start_date, case when dw.dw_end_date >= '2019-09-10' and ods.goodsId is not null then '2019-09-09' else dw.dw_end_date end as dw_end_date from `itcast_dw`.`dim_goods` dw left join (select * from `itcast_ods`.`itcast_goods` where dt='20190910') ods on dw.goodsId = ods.goodsId union select goodsId, goodsSn, productNo, goodsName, goodsImg, shopId, goodsType, marketPrice, shopPrice, warnStock, goodsStock, goodsUnit, goodsTips, isSale, isBest, isHot, isNew, isRecom, goodsCatIdPath, goodsCatId, shopCatId1, shopCatId2, brandId, goodsDesc, goodsStatus, saleNum, saleTime, visitNum, appraiseNum, isSpec, gallery, goodsSeoKeywords, illegalRemarks, dataFlag, createTime, isFreeShipping, goodsSerachKeywords, modifyTime, case when modifyTime is not null then from_unixtime(unix_timestamp(modifyTime, 'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd') else from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') end as dw_start_date, '9999-12-31' as dw_end_date from `itcast_ods`.`itcast_goods` where dt = '20190910';
4. Re import data to historical zipper table
– import historical data and current day data into historical zipper table
insert overwrite table
itcast_dw.dim_goods
select * fromitcast_dw.tmp_dim_goods_history;
5. View the historical zipper data of the corresponding product id
select * from
itcast_dw.dim_goodswhere goodsId = 100134;
Find out the updated data and the data before the update
Historical data - the end time is not 9999-12-31, but 2019-09-10
Latest status - beam time is 9999-12-31