This article can help and understand the principle of Kafka stream, which is convenient for us to use it better. It contains an example of building Kafka stream, which is convenient for us to master and use it better
1, Introduction to Kafka Stream
1. Overview
Kafka Streams is a client program library used to process and analyze the data stored in Kafka, and write the obtained data back to Kafka or send it to external systems. Kafka Stream is based on an important stream processing concept. Such as the correct distinction between event time and processing time, window support, and simple and effective application state management. The entry threshold of Kafka Streams is very low: you can quickly write and run a small-scale proof of concept on a single machine; You only need to run your application and deploy it to multiple machines to expand the high-capacity production load. Kafka Stream uses Kafka's parallel model to transparently handle the same applications for load balancing.
Highlights of Kafka Stream:
- Design a simple and lightweight client library, which can be easily embedded in any java application and encapsulated and integrated with any existing application.
- As an internal message layer, Apache Kafka does not depend on external systems. In addition, it uses kafka's partition model to expand processing horizontally and ensure order at the same time.
- Support local state fault tolerance and very fast and efficient state operations (such as join and window aggregation).
- One recored at a time (one message at a time) processing is adopted to achieve low latency, and event time based window operation is supported.
- Provide the necessary primitives for stream processing, as well as a high-level stereo DSL and a low-level Processor API.
2. Core concept
We first summarize the key concepts of Kafka Streams.
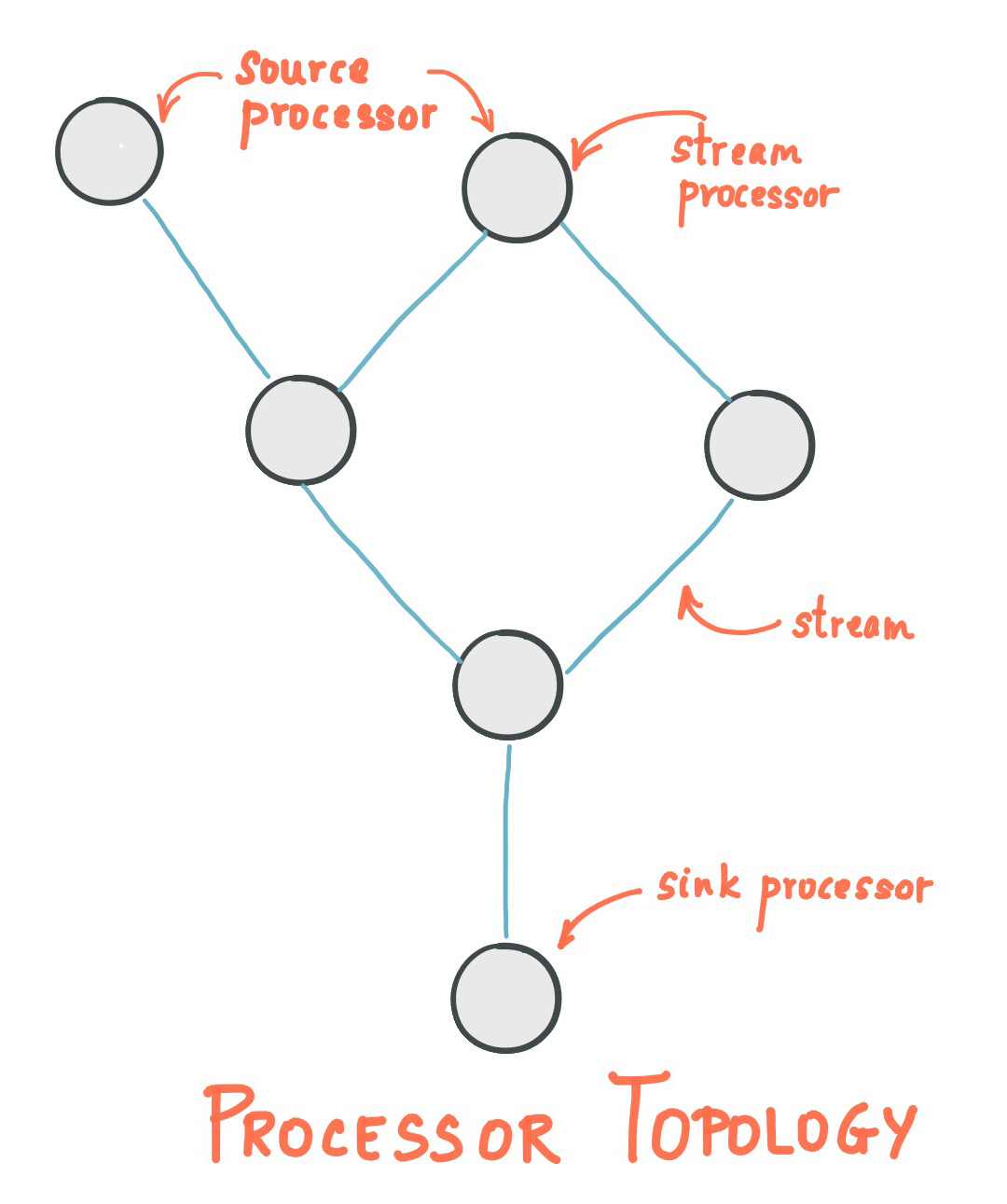
Stream processing topology
- Stream is the most important abstract concept proposed by Kafka Stream: it represents an infinite and constantly updated data set. A stream is an ordered, reproducible (repeated use), immutable fault-tolerant sequence. The format of data record is key value pair.
- A processor topology that writes one or more computational logic through Kafka Streams. The processor topology is a graph of stream processing (nodes) connected by streams (edges).
- Stream processor is a node in the processor topology; It represents a processing step used to transform the data in the stream (accept one input message at a time from the upstream processor in the topology and then generate one or more output messages to its downstream processor).
There are two special processors in the topology:
- Source Processor: a Source Processor is a special type of stream processor without any upstream processor. It generates input streams from one or more kafka topics. By consuming messages from these topics and forwarding them to downstream processors.
- Sink processor: sink processor is a special type of stream processor without downstream stream processor. It receives messages from the upstream stream processor and sends them to a specified Kafka topic.
Kafka streams provides two ways to define the stream processor topology: Kafka Streams DSL provides more common data conversion operations, such as map and filter; The low-level Processor API allows developers to define and connect custom processors and interact with the state repository.
Processor topology is just a logical abstraction of stream processing code.
3. Use example
Note: if you are building a cluster, you need to start all broker s
3.1 start related configuration
Start each zooker, broker and producer
Create the required topic
3.2 introducing project dependencies
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com</groupId>
<artifactId>KafkaTest02</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>KafkaTest02</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>3.3 create a test class
This class is used to sort out the fields entered into a topic and then enter them into another topic
package com.kafkatest02;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class StreamSample {
//Define the topic of data source and output to
//Note that these two topics need to be created in advance
public static final String INPUT_TOPIC = "countin";
public static final String OUTPUT_TOPIC = "countout";
//Create a configuration object
static Properties getStreamsConfig() {
final Properties props = new Properties();
//Create a new Kafka consumer group
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
//Listen for the port address of the broker
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// setting offset reset to earliest so that we can re-run the demo code with the same pre-loaded data
// Note: To re-run the demo, you need to use the offset reset tool:
// https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams+Application+Reset+Tool
//Get the oldest message in topic
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
static void createWordCountStream(final StreamsBuilder builder) {
final KStream<String, String> source = builder.stream(INPUT_TOPIC);
final KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" ")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
}
public static void main(final String[] args) {
final Properties props = getStreamsConfig();
final StreamsBuilder builder = new StreamsBuilder();
createWordCountStream(builder);
final KafkaStreams streams = new KafkaStreams(builder.build(), props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}3.4 compiling consumer
Used to output the field data input into the topic after sorting
package com.kafkatest02;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.springframework.kafka.annotation.KafkaListener;
import java.util.Arrays;
import java.util.Properties;
public class UserLogConsumer {
@KafkaListener(topics = {"countout"})
public void consumer(){
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9091");
props.setProperty("group.id", "group01"); //Note that this is to recreate a group. If it already exists, an error will be reported
props.setProperty("enable.auto.commit", "false");
props.setProperty("auto.commit.interval.ms", "3000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.assign(Arrays.asList(new TopicPartition("countout", 0)));
consumer.seek(new TopicPartition("countout", 0), 0);//Do not change the current offset
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
System.out.println(record.value()+"~~~~~~~~~~~~~~~~~~~~~~~~~~~"+record.key());
}
consumer.commitAsync();
}
}
public static void main(String[] args) {
UserLogConsumer userLogConsumer=new UserLogConsumer();
userLogConsumer.consumer();
}
}3.5 writing message producer classes
package com.kafkatest02.kafka_Stream;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import java.util.Properties;
import java.util.Scanner;
@Component
public class UserLogProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
/**
* send data
* @param topic
*/
public void sendLog(String topic,String msg){
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<String, String>(topic, msg));
producer.close();
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
UserLogProducer producer=new UserLogProducer();
String s="";
do {
s=sc.nextLine();
producer.sendLog("countin",s);
}while(s!="n"||"n".equals(s));
}
}3.6 start three classes and start Kafka management tool to view the effect
Enter the message in the console of UserLogProducer and view the effect on Kafka management tool