In the era of big data, data has become the most important foundation. Whether it is data mining, data analysis, machine learning or deep learning in artificial intelligence, data is the foundation. Without data, there will be no later development.
The following is the position data of 51job network for data analysis.
Environmental Science:
- python3.7.3
- windows10
- Google driver
- selenium
- csv
1 simulate login
The first step is to configure Google and Google driver. Here we need to load pictures, because we need to manually check the consent terms during login verification
def main():
option = webdriver.ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(executable_path=r'D:\chromedriver.exe',options=option)
driver.set_page_load_timeout(15)
login(driver)
Here, after the driver is turned on, we locate the password login, account input box, password input box and login box
After he automatically fills in the password, we need to manually check the I agree terms contract, and then we need to wait for him to automatically click to log in. If there is sliding verification here, it is the same. We need to drag it manually. It is also difficult to write the pull of the sliding block here, because it sometimes does not have the step of verification~~~~
driver.delete_all_cookies()
url = "https://login.51job.com/login.php?lang=c"
driver.get(url)
time.sleep(5)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/div[1]/span[3]/a').click()
time.sleep(1)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[1]/div/input[1]').send_keys('51job account number')
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div/input[1]').send_keys('51job password')
time.sleep(10)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[4]/button').click() # Click login
2 get URL
After successful login, it is divided into two steps
(1) Get company specific URL
Here, you need to provide the url of the position of the keyword you want to climb in advance, and change the page change number in it,
Save the URL obtained on the first page for later detailed information crawling.
url = ["https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{0}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(i) for i in range(1, 822)]
for k in url:
driver.get(k)
time.sleep(10)
url_3 = []
for id in range(1,50):
x = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div[{}]/a'.format(id))
url_3.append(x.get_attribute("href"))
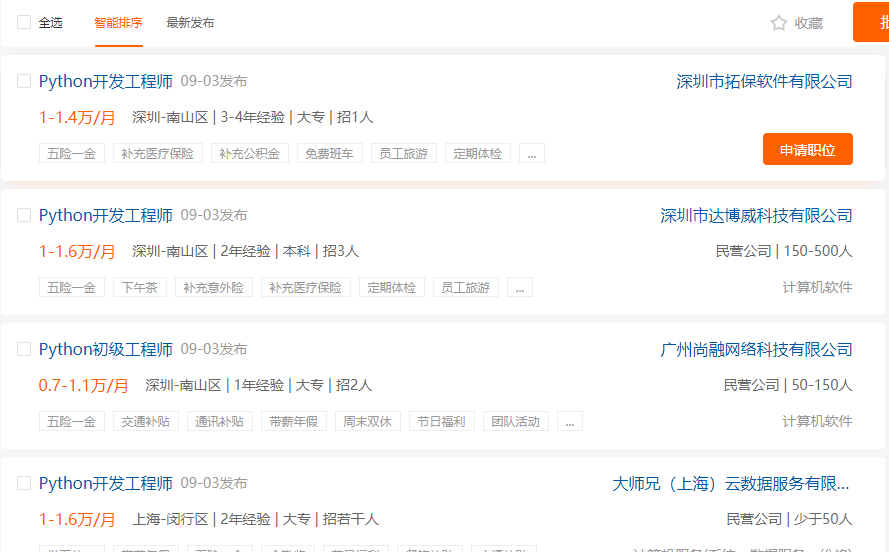
(2) Get the details of the specific position
Here is to crawl the details according to the url obtained earlier,
Attention attention attention attention attention attention attention
Here we need to judge
-
Judge whether the page is loaded ------------ if it is not loaded, it needs to be reloaded
-
Judge whether the page is 405 / 443 ----------------- if there is an error, you need to judge whether it is a blocked IP
-
Judge whether the open page meets the requirements - error page. You need to change the URL and reopen it
for j in url_3:
po = 1
driver.get(j) # Detail crawling
kl = 0
time.sleep(5)
while True:
try:
kl += 1
gangwei = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]').text.split('\n')
break
except:
if kl == 10:
print('--------*****************----------')
time.sleep(5)
print('-----------*************************************************-------')
po = 0
break
else:
time.sleep(5)
continue
if po == 0:
continue


be careful
After opening the URL link, we should set the waiting time, otherwise it is very easy to be blocked
Complete code
import time
import pandas as pd
from selenium import webdriver
import csv
from selenium.webdriver import ActionChains
f = open('./51116.csv','w',newline='')
writer = csv.writer(f)
a = []
def login(driver):
global gangwei, zhiweixin, gsxinxi
li = []
driver.delete_all_cookies()
url = "https://login.51job.com/login.php?lang=c" #https://www.qcc.com/weblogin?back=%2F
driver.get(url)
time.sleep(5)
# Click password to log in
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/div[1]/span[3]/a').click()
time.sleep(1)
# Enter account password
#driver.find_element_by_id('nameNormal').send_keys(username) # /html/body/div[1]/div[3]/div/div[2]/div[3]/form/div[1]/input
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[1]/div/input[1]').send_keys('account number')
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div/input[1]').send_keys('password')
time.sleep(10)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[4]/button').click() # Click login
time.sleep(5)
url = ["https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{0}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(i) for i in range(1, 822)]
for k in url:
driver.get(k)
time.sleep(10)
url_3 = []
for id in range(1,50):
x = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div[{}]/a'.format(id))
url_3.append(x.get_attribute("href"))
for j in url_3:
po = 1
driver.get(j) # Detail crawling
kl = 0
time.sleep(5)
while True:
try:
kl += 1
gangwei = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]').text.split('\n')
break
except:
if kl == 10:
print('--------*****************----------')
time.sleep(5)
print('-----------*************************************************-------')
po = 0
break
else:
time.sleep(5)
continue
if po == 0:
continue
print(gangwei)
li.extend(gangwei)
t1 = 0
while True:
try:
t1 += 1
zhiweixin=driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div').text
gsxinxi = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[3]/div[3]/div').text
break
except:
time.sleep(5)
if t1==3:
break
if t1==3:
continue
li.extend([j,zhiweixin,gsxinxi])
try:
writer.writerow(li)
except:
pass
time.sleep(5)
time.sleep(60)
def main():
# while True:
"""
chromeOptions Is a configuration chrome Startup is a class of properties,Is initialization
"""
option = webdriver.ChromeOptions()
"""
add_experimental_option Add experimental setting parameters
"""
option.add_experimental_option('excludeSwitches', ['enable-automation']) # webdriver anti detection
'''
add_argument Add startup parameters
'''
# option.add_argument("--disable-blink-features=AutomationControlled")
# option.add_argument("--no-sandbox")
# option.add_argument("--disable-dev-usage")
# option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
"""
Chrome Configuration driver
"""
driver = webdriver.Chrome(executable_path=r'D:\chromedriver.exe',options=option)#You need to download the chrome driver corresponding to your Google version
driver.set_page_load_timeout(15)
login(driver)
# jugesd(driver)
if __name__ == '__main__':
username = '51job account number'
password = '51job password'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'}
main()
f.close()
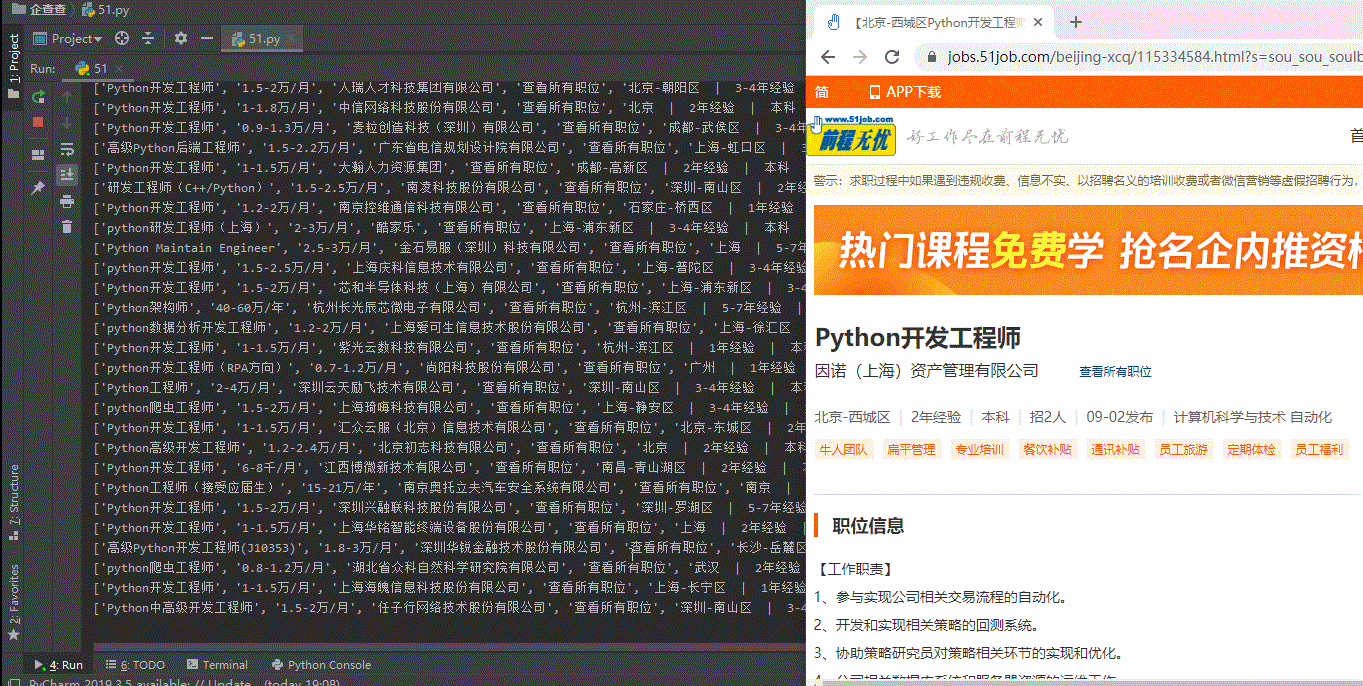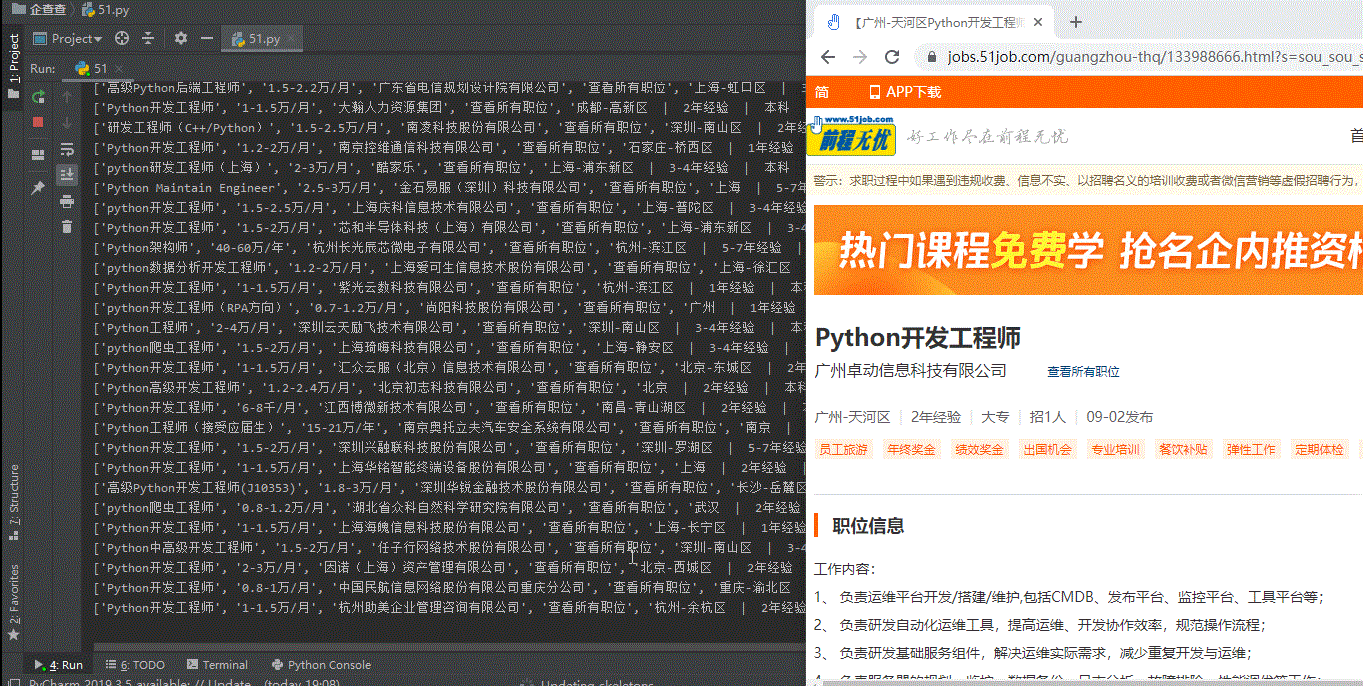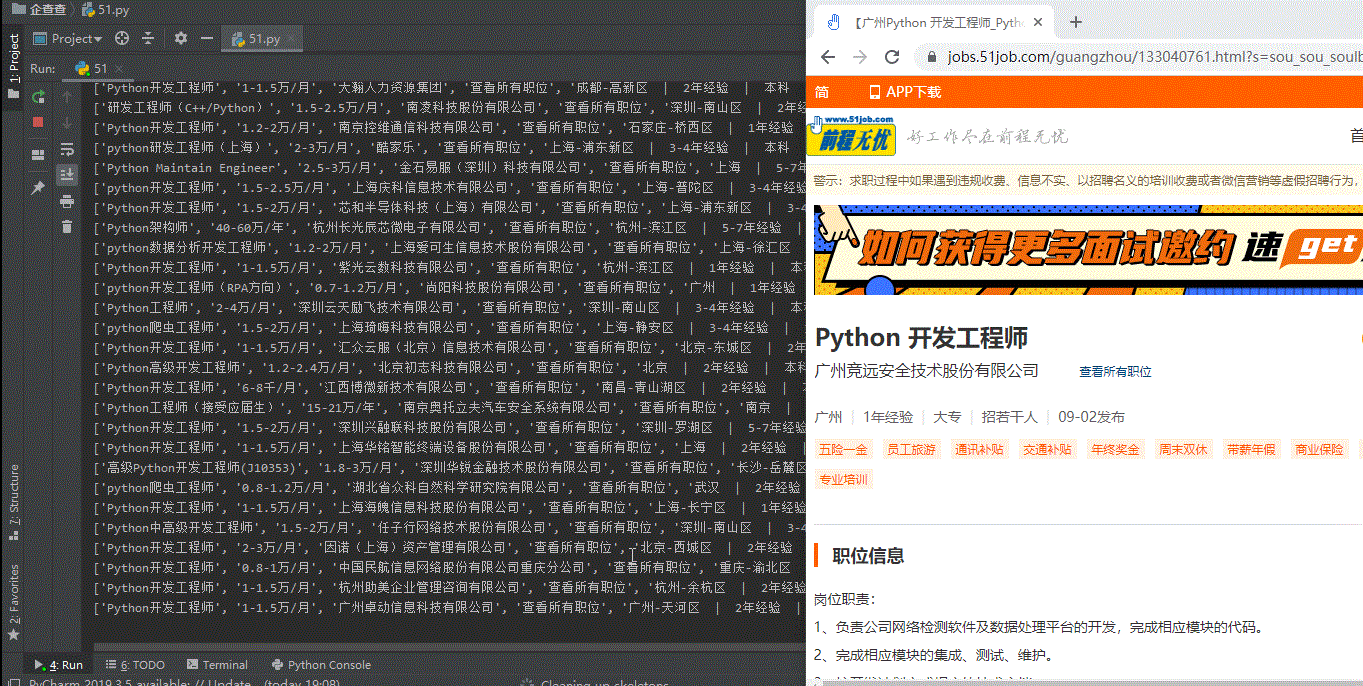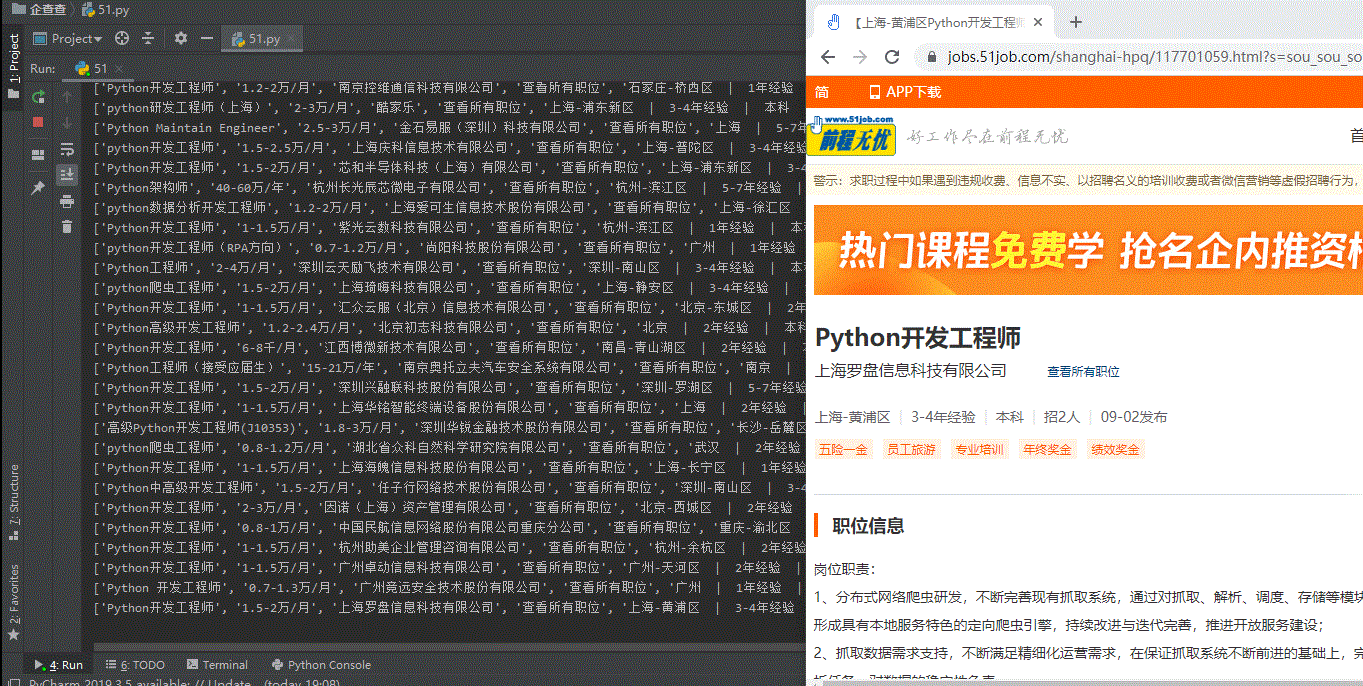
Result display
I hope this blog is useful to you!
Thank you for your comments!