1. The theoretical explanation is clear and easy to understand:
2. Code implementation set:
GitHub - eriklindernoren/Keras-GAN: Keras implementations of Generative Adversarial Networks.
3. Here is a brief introduction
The popular understanding of GNN is based on the mutual game between two opponents and common progress. Similar to: suppose a city is in chaos, soon there will be countless thieves in the city. Among these thieves, some may be expert thieves, and some may have no technology at all. If the city begins to straighten out its law and order and suddenly launch a "campaign" to combat crime, the police begin to resume patrols in the city. Soon, a group of "unskilled" thieves will be caught. The reason why we caught those thieves without technical content is that the police's technology is no longer good. After catching a group of low-end thieves, it's hard to say how the public security level of the city has become, but it's obvious that the average level of thieves in the city has been greatly improved.
In terms of image processing, it can be understood as follows: you train the Discriminator with real pictures and false pictures generated by the generator, so that it can distinguish true from false. The generator uses the numbers you randomly input to generate pictures corresponding to real pictures, and trains repeatedly so that it can generate more and more realistic pictures.
The pictures are as follows:
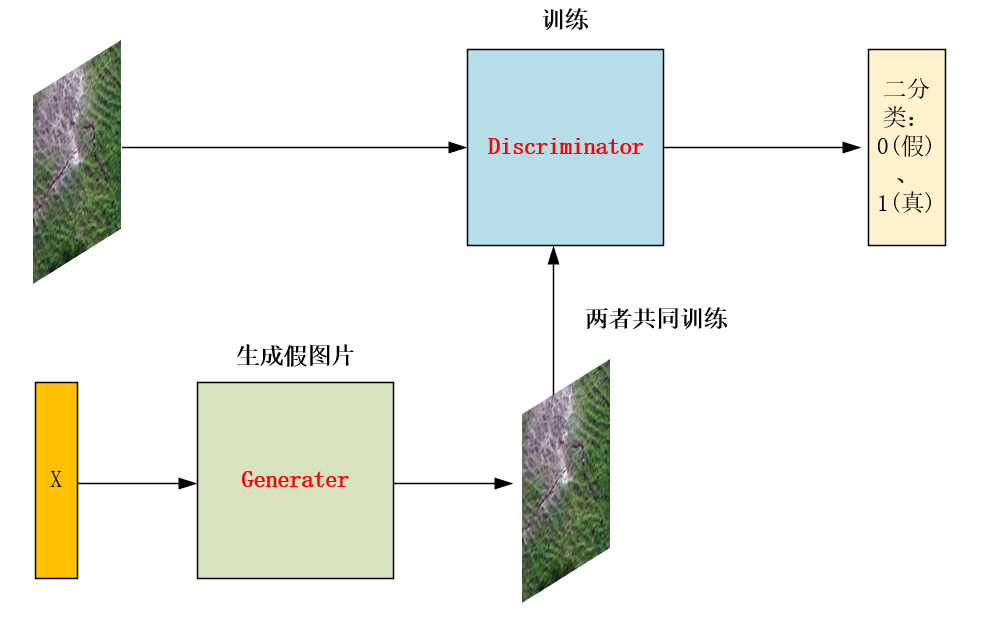
Convolution is used to generate pictures and training code.
4. Its loss function
In fact, the loss functions of the two can be considered separately. For the Discriminator, it is the sum of the real picture loss function and the manufactured false picture loss function. valid and fake correspond to their false tags; imgs,gen_imgs are real pictures and false pictures respectively.
d_loss_real = self.discriminator.train_on_batch(imgs, valid) d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
For the generator, it first sets the Discriminator to the prediction state, then X will pass it into the generator and input the generated false picture into the Discriminator for discrimination, so as to update the parameters of the generator. Here, 0 (true) and 1 (false) are mainly when the Discriminator recognition effect is very good, indicating that the generator needs to study hard to continue to muddle through, so its loss value is large; vice versa.
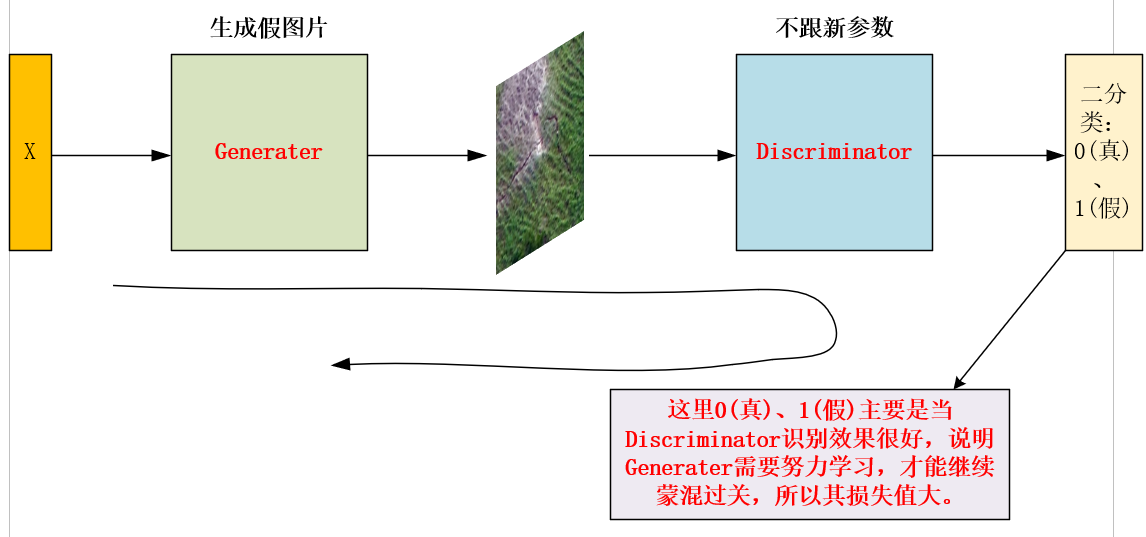
When the code is implemented, its label is directly transmitted to 1 (real picture):

5. Its code implementation:
The code is implemented relative to Mnist by generating Mnist image blur Discriminator.
from __future__ import print_function, division
import tensorflow as tf
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto(allow_soft_placement = True)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.5)
config.gpu_options.allow_growth = True
sess0 = tf.InteractiveSession(config = config)
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import sys
import numpy as np
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
validity = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(z, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, sample_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Generate a batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Train the generator (to have the discriminator label samples as valid)
g_loss = self.combined.train_on_batch(noise, valid)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % sample_interval == 0:
self.sample_images(epoch)
def sample_images(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=1, sample_interval=200)The results are as follows (the training time will not be long, you can try if you are interested):
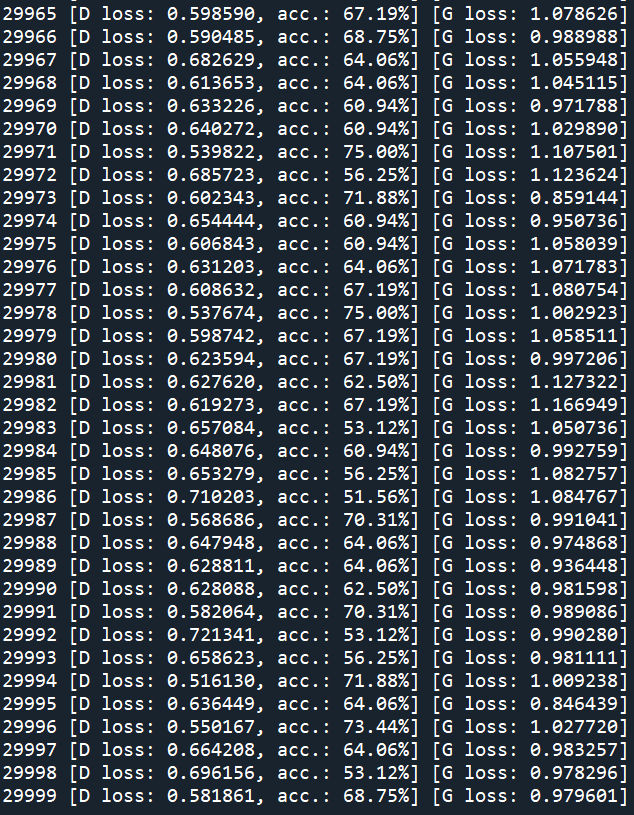


The results show that with the increase of training steps, the generated images can be more and more confused with the real.