First question
subject
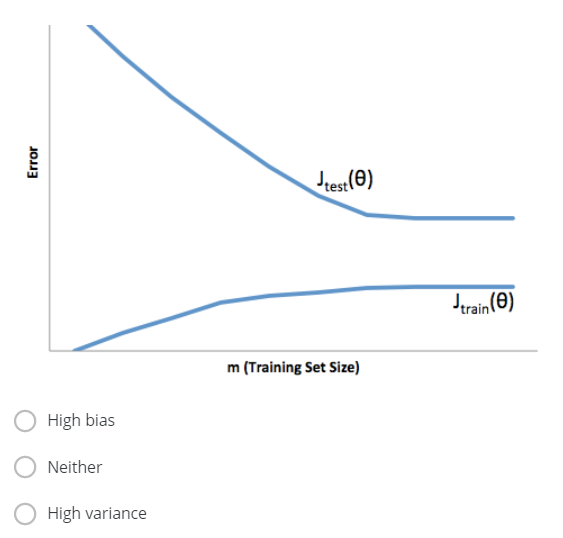
1 You train a learning algorithm, and find that it has unacceptably high error on the test set. You plot the learning curve, and obtain the figure below. Is the algorithm suffering from high bias, high variance, or neither?
answer:
C
Resolution:
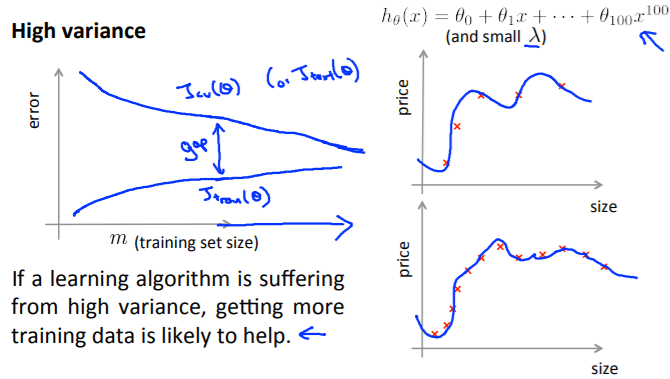
It's obvious from this figure that no amount of data is useful. This is the high square difference
Second question
subject
2 Suppose you have implemented regularized logistic regression
to classify what object is in an image (i.e., to do object
recognition). However, when you test your hypothesis on a new
set of images, you find that it makes unacceptably large
errors with its predictions on the new images. However, your
hypothesis performs well (has low error) on the
training set. Which of the following are promising steps to
take? Check all that apply.

answer
AD
analysis
Obviously it belongs in the training set and performs well
But the performance in the new test set is very bad.
It can be determined that it belongs to over fitting problem. It should belong to high variance
A option – fewer features – > completely correct and can reduce the symptoms of high variance
B. try to add polynomial features - > it has been fitted and will make things worse. Error
C said that he used fewer training sets, made mistakes, needed more training sets to perform well in the test set, and has performed poorly in the test set. Training with fewer samples will be worse
D obtain more training samples, which is completely correct for the above reasons
Question 3
Question 3
Suppose you have implemented regularized logistic regression
to predict what items customers will purchase on a web
shopping site. However, when you test your hypothesis on a new
set of customers, you find that it makes unacceptably large
errors in its predictions. Furthermore, the hypothesis
performs poorly on the training set. Which of the
following might be promising steps to take? Check all that
apply.

answer
BC
analysis
The performance on the training set is also poor and under fitting. There may be some problems with the high bias model itself
Look at the options at this time
A says with fewer training samples
B try more features that are completely correct. Maybe it is because you haven't learned the features that the error rate is very high, so you should learn more
C correctly reduces the weight of regularization items with less lamda, and can fix high bias
D attempts to evaluate hypotheses through cross validation sets rather than test sets, and does not select
Question 4
subject
Which of the following statements are true? Check all that apply.
subject

answer
BD
analysis
Choose the right one
A not necessarily. The error rate during training is low. What about the test set
B usually; General; typically; The training set must perform better than the test set
C low test set error rate does not mean that the training set error rate is also low
D cross validation error is low, that is correct
Question 5
subject
Which of the following statements are true? Check all that apply.

answer
ACD
analysis
Still choose the right one
A adding a learning algorithm is high bias. Only adding training samples will not improve the test error. It is completely correct. It may be the model itself or feature extraction. Therefore correct
B said that the error of the training set of the neural network model is much lower than that of the test set. It shows that over fitting and increasing the number of layers will only aggravate the phenomenon, so the error is not selected
The more C model parameters, the easier it is to over fit or have higher variance and correct
D said when adjusting the learning algorithm. Drawing a learning curve is helpful to understand the correctness of the high bias or variance problem of the model. After drawing, it's very intuitive. Isn't the first question
result