Today's daily question is
Word Search 2
At first you want to try how much deep search you can do, and the result is over.
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
#Try it with a deep search first
wordSet = set(words)
direction= [(0,1),(0,-1),(1,0),(-1,0)]
m,n = len(board),len(board[0])
vistied=[[False]* n for _ in range(m)]
def dfs(word,res,x,y):
if len(word)>10:
return
if word in wordSet:
res.append(word)
wordSet.remove(word)
for d in direction:
nx,ny=x+d[0],y+d[1]
if nx<0 or nx>=m or ny<0 or ny>=n:
continue
if vistied[nx][ny]:
continue
vistied[nx][ny]=True
dfs(word+board[nx][ny],res,nx,ny)
vistied[nx][ny]=False
return
res=[]
for i in range(m):
for j in range(n):
vistied[i][j]=True
dfs(board[i][j],res,i,j)
vistied[i][j]=False
return res
The python depth search here takes care of the input values, especially the boundary conditions, but there should be no major problems.
Then the most formal solution to the problem is actually to use a dictionary tree.
Just a review of the dictionary tree:
Dictionary Tree
Also known as word search tree, Trie tree, is a tree structure and a variant of hash tree. Typical applications are for statistics, sorting and saving large numbers of strings (but not just strings)So it is often used in text word frequency statistics by search engine systems. Its advantages are: using common prefixes of strings to reduce query time, minimizing unnecessary string comparisons, querying efficiency is higher than hash tree (referencing Baidu Encyclopedia) tree exactly one character on each edge, each vertex represents the string corresponding to the path from the root to the node.Sometimes we also refer to edges on Trie as transitions and vertices as states.
As follows:
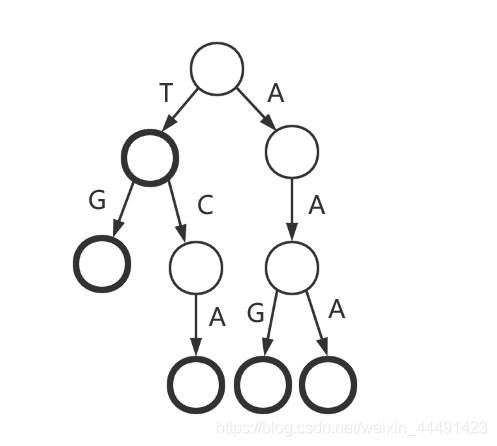
Additional information can also be stored on vertices, for example, a string of letters along the edge from the root to the bold circle in the figure above is an element in the actual string collection. This node can also be referred to as a word node, which can be recorded in actual code using a bool-type array. In fact, the string represented by any line node is the actual string collection.The prefix of some strings in. In particular, the root node represents an empty string.
We can see that for any node, the characters from it to its subnodes are different. Trie makes good use of the common prefix of the string and saves storage space.
If you think of a character set as lowercase letters, Trie can also think of it as a 26-fork tree, and when you insert a query string, just like a tree, find the corresponding edge and go down.
My own understanding is that he is a variant of prefix sum
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = [None]*26
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
node=self
for ch in word:
ch = ord(ch)-ord('a')
if not node.children[ch]:
node.children[ch] = Trie()
node = node.children[ch]
node.isEnd=True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
node=self
for ch in word:
ch = ord(ch)-ord('a')
if not node.children[ch]:
return False
node = node.children[ch]
if node.isEnd:
return True
return False
def startsWith(self, prefix: str) -> bool:
"""
Returns if there is any word in the trie that starts with the given prefix.
"""
node=self
for ch in prefix:
ch = ord(ch)-ord('a')
if not node.children[ch]:
return False
node = node.children[ch]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
Then take ten minutes tomorrow to do a deep search of that prefix tree version to deepen your memory.